Learn more about Search Results Transformer - Page 92

- You may be interested
- このAI研究は、パーソン再識別に適したデ...
- 「AI企業は、彼らが引き起こす損害につい...
- JavaScriptを使用した仮想試着メガネ
- 「最も強力な機械学習モデルの解説(トラ...
- ディープラーニングを使用した自動音楽生成
- 「Apple M1とM2のパフォーマンス- SSLモデ...
- 倫理と社会のニュースレター#3:Hugging ...
- RAGアプリケーションデザインにおける実用...
- Hugging FaceのTensorFlowの哲学
- バードが強化された機能を発表:Gmail、Dr...
- このAI研究は、近くの電話によって記録さ...
- 「マシンに思いやりを持たせる:NYU教授が...
- 「Pythonを使用したアンダーサンプリング...
- AIを使ってYouTubeショートを作成する
- 「MicrosoftがExcelにPythonを導入:分析...

ロボティクスシミュレーションとは何ですか?
ロボットは倉庫内で商品を運搬し、食品を包装し、車両の組み立てを助けています。バーガーをひっくり返したり、ラテを提供することもあります。 彼らはなぜそんなに早くスキルを身につけたのでしょうか?それはロボティクスシミュレーションのおかげです。 進歩を飛躍的に遂げ、私たちの周りの産業を変革しています。 ロボティクスシミュレーションの概要 ロボティクスシミュレータは、物理的なロボットを必要とせずに、仮想環境に仮想ロボットを配置して、ロボットのソフトウェアをテストするものです。また、最新のシミュレータは、物理的なロボット上で実行される機械学習モデルのトレーニングに使用されるデータセットを生成することもできます。 この仮想世界では、開発者はロボットや環境、その他のロボットが遭遇する可能性のある要素のデジタルバージョンを作成します。これらの環境は、物理法則に従い、現実の重力、摩擦、材料、照明条件を模倣することができます。 ロボティクスシミュレーションを使用する人々 ロボットは今日、大規模なスケールで業務を支援しています。最も大きく革新的なロボット企業のいくつかは、ロボティクスシミュレーションに頼っています。 シミュレーションによって明らかにされた運用効率により、フルフィルメントセンターは1日に数千万個のパッケージを処理することができます。 Amazon Roboticsはフルフィルメントセンターを支援するためにそれを使用しています。BMWグループは自動車組立工場の計画を加速するためにそれを活用しています。Soft Roboticsは食品のパッケージングのためのグリッピングを完璧にするためにそれを適用しています。 自動車メーカーは世界中でロボティクスを活用しています。 「自動車メーカーは約1400万人を雇用しています。デジタル化により、産業の効率、生産性、スピードが向上します」とNVIDIAのCEOジェンセン・ファンは最新のGTC基調講演で述べています。 ロボティクスシミュレーションの動作原理 高度なロボティクスシミュレータは、物理の基本方程式を適用することから始まります。例えば、オブジェクトが時間の小さい増分またはタイムステップでどのように移動するかを決定するために、ニュートンの運動の法則を使用することができます。また、ロボットが蝶番のような関節で構成されているか、他のオブジェクトを通過できない制約を組み込むこともできます。 シミュレータは、オブジェクト間の潜在的な衝突を検出し、衝突するオブジェクト間の接点を特定し、オブジェクトが互いに通過するのを防ぐための力や衝撃を計算するためのさまざまな方法を使用します。シミュレータは、ユーザーが求めるセンサーシグナル(例:ロボットの関節でのトルクやロボットのグリッパーとオブジェクトとの間の力)も計算することができます。 シミュレータは、ユーザーが要求するだけのタイムステップ数でこのプロセスを繰り返します。 NVIDIA Isaac Simなどの一部のシミュレータは、各タイムステップでシミュレータの出力を物理的に正確な可視化も提供することができます。 ロボティクスシミュレータの利用方法 ロボティクスシミュレータのユーザーは、通常、ロボットのコンピュータ支援設計モデルをインポートし、仮想シーンを構築するために興味のあるオブジェクトをインポートまたは生成します。開発者は、タスクプランニングやモーションプランニングを実行するためのアルゴリズムのセットを使用し、それらの計画を実行するための制御信号を指定することができます。これにより、ロボットはオブジェクトを拾って目標位置に配置するなど、特定の方法でタスクを実行し移動することができます。 開発者は、計画と制御信号の結果を観察し、必要に応じて修正して成功を確保することができます。最近では、機械学習ベースの手法へのシフトが見られています。つまり、制御信号を直接指定する代わりに、ユーザーは衝突しないように指定された動作(例:特定の場所に移動する)を指定します。この状況では、データ駆動型のアルゴリズムが、ロボットのシミュレートされたセンサーシグナルに基づいて制御信号を生成します。…
デノイザーの夜明け:表形式のデータ補完のためのマルチ出力MLモデル
表形式のデータにおける欠損値の扱いは、データサイエンスにおける基本的な問題ですこの記事では、デノイジングに関する文献から着想を得た洗練された手法を紹介し、表形式のデータ補完においてマルチアウトプットの機械学習モデルを活用する方法を提案します

言語モデルの構築:ステップバイステップのBERTの実装ガイド
イントロダクション 言語処理を行う機械学習モデルの進歩は、ここ数年で急速に進んでいます。この進歩は、研究室を出て、いくつかの主要なデジタル製品の動力となり始めています。良い例として、BERTモデルがGoogle検索の重要な要素となったことが発表されたことがあります。Googleは、この進化(自然言語理解の進歩が検索に応用されること)は、「過去5年間で最大の進歩であり、検索の歴史上でも最大の進歩の1つ」と考えています。では、BERTとは何かについて理解しましょう。 BERTは、Bidirectional Encoder Representations from Transformersの略です。その設計では、未ラベルのテキストから左右の文脈の両方に依存して事前学習された深層双方向表現を作成します。我々は、追加の出力層を追加するだけで、事前学習されたBERTモデルを異なるNLPタスクに適用することができます。 学習目標 BERTのアーキテクチャとコンポーネントを理解する。 BERTの入力に必要な前処理ステップと、異なる入力シーケンスの長さを扱う方法を学ぶ。 TensorFlowやPyTorchなどの人気のある機械学習フレームワークを使用してBERTを実装するための実践的な知識を得る。 テキスト分類や固有表現認識などの特定の下流タスクにBERTを微調整する方法を学ぶ。 次に、「なぜそれが必要なのか?」という別の質問が出てきます。それを説明しましょう。 この記事は、データサイエンスブログマラソンの一環として公開されました。 なぜBERTが必要なのか? 適切な言語表現とは、機械が一般的な言語を理解する能力です。word2VecやGloveのような文脈非依存モデルは、語彙中の各単語に対して単一の単語埋め込み表現を生成します。例えば、”crane”という用語は、”crane in the sky”や”crane to lift heavy objects”といった文脈で厳密に同じ表現を持ちます。文脈モデルは、文内の他の単語に基づいて各単語を表現します。つまり、BERTはこれらの関係を双方向に捉える文脈モデルです。 BERTは、Semi-supervised…
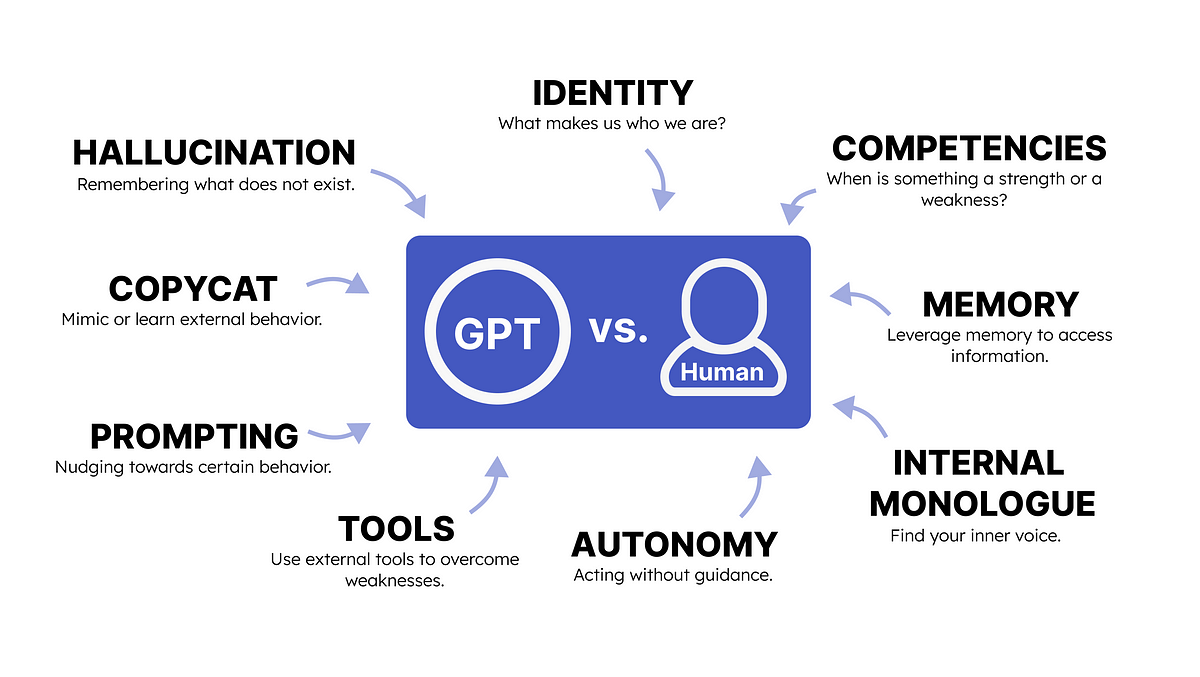
GPTと人間の心理学
GPTと人間の心理学との類推を行うことで、私たちは生成型AIの出力を促進する方法を理解することができます

マイクロソフトの研究者がKOSMOS-2を紹介:視覚世界に根付くことができるマルチモーダルな大規模言語モデル
マルチモーダル大規模言語モデル(MLLMs)は、言語、ビジョン、ビジョン言語のタスクを含むさまざまな活動で一般的なインターフェースとしての成功を示しています。ゼロショットおよびフューショットの条件下では、MLLMsはテキスト、画像、音声などの一般的なモダリティを知覚し、自由な形式のテキストを使用して回答を生成することができます。本研究では、マルチモーダルな大規模言語モデルに自己を基礎付ける能力を付与します。ビジョン言語の活動では、基礎付け能力はより実用的かつ効果的な人間-AIインターフェースを提供することができます。モデルは、地理座標と一緒にその画像領域を解釈することができ、ユーザーが長いテキストの説明を入力する代わりに、アイテムや領域を画像上で直接指すことができます。 図1:KOSMOS-2を使用して生成された選択されたサンプルが表示されます。ビジュアル基礎付け、基礎付け質問応答、バウンディングボックスを使用したマルチモーダル参照、基礎付け画像キャプション、ビジュアル基礎付けなどがあります。 モデルの基礎付け機能は、視覚的な応答(つまり、バウンディングボックス)の提供も可能にし、参照表現の理解などの他のビジョン言語のタスクを支援することができます。テキストベースの応答と比較して、視覚的な応答はより正確で、共参照の曖昧さを解消します。結果として得られる自由形式のテキスト応答の基礎付け能力は、名詞句や参照表現などを画像領域に関連付けて、より正確で情報量のある応答を生成します。Microsoft Researchの研究者は、基礎付け機能を備えたKOSMOS-1をベースにしたマルチモーダルな大規模言語モデルKOSMOS-2を紹介しています。次単語予測タスクを使用して、Transformerに基づく因果的言語モデルKOSMOS-2をトレーニングします。 彼らは、基礎付けの潜在能力を十分に活用するために、基礎付けられた画像テキストのペアデータセットをウェブスケールで構築し、KOSMOS-1のマルチモーダルコーパスに統合します。LAION-2BおよびCOYO-700Mからの画像テキストの一部のペアリングが、基礎付けられた画像テキストのペアの基盤となります。彼らは、キャプションから名詞句や参照表現などのテキストスパンを抽出し、それらのオブジェクトや領域のバウンディングボックスなどの空間的な位置に接続するためのパイプラインを提供します。バウンディングボックスの地理座標を位置トークンの文字列に変換し、それらを対応するテキストスパンの後に追加します。データ形式は、画像の要素をキャプションにリンクする「ハイパーリンク」として機能します。 実験の結果、KOSMOS-2は、基盤タスク(フレーズの基盤と参照表現の理解)および参照タスク(参照表現の生成)だけでなく、KOSMOS-1で評価された言語およびビジョン言語のタスクでも競争力を持っています。図1は、基礎付け機能を含めることで、KOSMOS-2を基盤とする画像キャプションとビジュアル質問応答をはじめとする追加のダウンストリームタスクに利用する方法を示しています。GitHubでオンラインデモが利用可能です。

TaatikNet(ターティクネット):ヘブライ語の翻字のためのシーケンス・トゥ・シーケンス学習
この記事では、TaatikNetとseq2seqモデルの簡単な実装方法について説明していますコードとドキュメントについては、TaatikNetのGitHubリポジトリを参照してくださいインタラクティブなデモについては、HF Spaces上のTaatikNetをご覧ください多くのタスク...

Meet ChatGLM2-6B:オープンソースのバイリンガル(中国語-英語)チャットモデルChatGLM-6Bの第2世代バージョンです
OpenAIの革命的なChatGPTの導入以来、自然言語対話エージェントの分野ではかなりの進歩が見られています。研究者たちは、チャットボットモデルの能力を向上させ、ユーザーとのより自然で魅力的な対話を作成できるようにするために、さまざまな技術と戦略を積極的に探求しています。その結果、ChatGPTの代替となるいくつかのオープンソースで軽量なモデルが市場に登場しています。その中の1つが、中国の清華大学の研究者によって開発されたChatGLMモデルシリーズです。このシリーズは、一般言語モデル(GLM)フレームワークをベースにしており、より一般的に見られるGenerative Pre-trained Transformer(GPT)グループのLLMとは異なります。このシリーズには、中国語と英語のバイリンガルモデルがいくつか含まれており、最もよく知られているのはChatGLM-6Bです。このモデルは62億のパラメータを持ち、1兆以上の英語と中国語のトークンで事前学習され、強化学習などの技術を用いて中国語の質問応答、要約、対話タスクにさらに微調整されています。 ChatGLM-6Bのもう1つの特徴は、その量子化技術により、ローカルで展開されることができ、非常に少ないリソースしか必要としないことです。モデルは、消費者向けのグラフィックスカードでもローカルに展開することができます。このモデルは特に中国で非常に人気があり、世界中で200万回以上ダウンロードされ、最も影響力のある大規模なオープンソースモデルの1つとなっています。その広範な採用の結果、清華大学の研究者はバイリンガルチャットモデルの第2世代バージョンであるChatGLM2-6Bをリリースしました。ChatGLM2-6Bは、第1世代モデルのすべての強みに加えて、パフォーマンスの向上、より長いコンテキストのサポート、より効率的な推論など、いくつかの新機能が追加されています。さらに、研究チームはモデルの重みの使用を学術目的に留まらず(以前に行われていたように)、商業利用にも利用できるように拡張しました。 研究者たちは、ChatGLM2-6Bのベースモデルを第1世代バージョンと比較して向上させることから始めました。ChatGLM2-6Bは、GLMのハイブリッド目的関数を使用し、1.4兆以上の英語と中国語のトークンで事前学習されました。研究者たちは、市場のほぼ同じサイズの他の競合モデルとのパフォーマンスを評価しました。その結果、ChatGLM2-6Bは、MMLU、CEval、BBHなどのさまざまなデータセットで顕著なパフォーマンスの向上を実現していることが明らかになりました。ChatGLM2-6Bが示したもう1つの印象的なアップグレードは、前バージョンの2Kから32Kまでのより長いコンテキストのサポートです。FlashAttentionアルゴリズムがこの点で重要な役割を果たし、より長いシーケンスに対してアテンションの高速化とメモリ使用量の削減を実現しました。さらに、モデルは対話のアライメント中に8Kのコンテキスト長でトレーニングされており、ユーザーにより多様な会話の深さを提供しています。ChatGLM2-6Bはまた、Multi-Query Attention技術を使用しており、KVキャッシュのGPUメモリ使用量が低下し、第1世代と比較して推論速度が約42%向上しています。 清華大学の研究者たちは、ChatGLM2-6Bをオープンソース化し、LLMの成長とイノベーションを促進し、そのモデルを基にしたさまざまな有用なアプリケーションの開発を世界中の開発者と研究者に呼びかけることを望んでいます。ただし、研究者たちは、モデルの規模が小さいため、その決定はしばしばランダムに影響を受ける可能性があること、その出力は正確性を慎重に確認する必要があることを強調しています。将来の作業に関しては、チームは一歩先を見越して、モデルの第3バージョンであるChatGLM3の開発を始めています。

なぜ無料のランチがあるのか
機械学習の領域における「無料の昼食はない」定理は、数学の世界におけるゲーデルの不完全性定理を思い起こさせますこれらの定理はよく引用されますが、めったに...

PyTorchを使った効率的な画像セグメンテーション:パート1
この4部作では、PyTorchを使用して深層学習技術を使った画像セグメンテーションをゼロから段階的に実装しますシリーズを開始するにあたり、必要な基本的なコンセプトとアイデアについて説明します

PyTorchを使った効率的な画像セグメンテーション:Part 2
これは、PyTorchを使用してディープラーニング技術を使ってゼロから画像セグメンテーションをステップバイステップで実装する4部作シリーズの第2部ですこの部分では、ベースライン画像の実装に焦点を当てます...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.