Learn more about Search Results huggingface.co - Page 8

- You may be interested
- 「見逃すな!2023年が終わる前に無料のコ...
- 私たちの早期警戒システムへのサポート
- このAIペーパーは、写真リアルな人物モデ...
- 「高次元のカテゴリ変数に対する混合効果...
- マイクロソフトは、エンタープライズ向け...
- 「Gensimを使ったWord2Vecのステップバイ...
- 「ストリーミングLLMの紹介 無限長の入力...
- BScの後に何をすべきか?トップ10のキャリ...
- 「KaggleのAIレポート2023で未来にダイブ...
- FastSAMとは、最小限の計算負荷で高性能の...
- 私の記事を読むと、あなた方は私がどれだ...
- コーネル大学の研究者たちは、言語モデル...
- 「オックスフォード大学と西安交通大学の...
- DENZAは、NVIDIA DRIVE Orinを搭載したN7...
- 新しい人工知能(AI)の研究アプローチは...

「T2Iアダプタを使用した効率的で制御可能なSDXL生成」
T2I-Adapterは、オリジナルの大規模なテキストから画像へのモデルを凍結しながら、事前学習されたテキストから画像へのモデルに追加のガイダンスを提供する効率的なプラグアンドプレイモデルです。T2I-Adapterは、T2Iモデル内部の知識を外部の制御信号と整合させます。さまざまな条件に応じてさまざまなアダプタをトレーニングし、豊富な制御と編集効果を実現することができます。 ControlNetは同様の機能を持ち、広く使用されている現代の作業です。しかし、実行するには計算コストが高い場合があります。これは、逆拡散プロセスの各ノイズ除去ステップで、ControlNetとUNetの両方を実行する必要があるためです。さらに、ControlNetは制御モデルとしてUNetエンコーダのコピーを重要視しており、パラメータ数が大きくなるため、生成はControlNetのサイズによって制約されます(サイズが大きければそれだけプロセスが遅くなります)。 T2I-Adapterは、この点でControlNetに比べて競争力のある利点を提供します。T2I-Adapterはサイズが小さく、ControlNetとは異なり、T2I-Adapterはノイズ除去プロセス全体の間ずっと一度だけ実行されます。 過去数週間、DiffusersチームとT2I-Adapterの著者は、diffusersでStable Diffusion XL(SDXL)のT2I-Adapterのサポートを提供するために協力してきました。このブログ記事では、SDXLにおけるT2I-Adapterのトレーニング結果、魅力的な結果、そしてもちろん、さまざまな条件(スケッチ、キャニー、ラインアート、深度、およびオープンポーズ)でのT2I-Adapterのチェックポイントを共有します。 以前のバージョンのT2I-Adapter(SD-1.4/1.5)と比較して、T2I-Adapter-SDXLはまだオリジナルのレシピを使用しており、79Mのアダプタで2.6BのSDXLを駆動しています!T2I-Adapter-SDXLは、強力な制御機能を維持しながら、SDXLの高品質な生成を受け継いでいます。 diffusersを使用してT2I-Adapter-SDXLをトレーニングする 私たちは、diffusersが提供する公式のサンプルを元に、トレーニングスクリプトを作成しました。 このブログ記事で言及するT2I-Adapterモデルのほとんどは、LAION-Aesthetics V2からの3Mの高解像度の画像テキストペアで、以下の設定でトレーニングされました: トレーニングステップ:20000-35000 バッチサイズ:データ並列、単一GPUバッチサイズ16、合計バッチサイズ128。 学習率:定数学習率1e-5。 混合精度:fp16 コミュニティには、スピード、メモリ、品質の間で競争力のあるトレードオフを打つために、私たちのスクリプトを使用してカスタムでパワフルなT2I-Adapterをトレーニングすることをお勧めします。 diffusersでT2I-Adapter-SDXLを使用する ここでは、ラインアートの状態を例にとって、T2I-Adapter-SDXLの使用方法を示します。まず、必要な依存関係をインストールします: pip install -U git+https://github.com/huggingface/diffusers.git pip install…

「翼を広げよう:Falcon 180Bがここにあります」
はじめに 本日は、TIIのFalcon 180BをHuggingFaceに歓迎します! Falcon 180Bは、オープンモデルの最新技術を提供します。1800億のパラメータを持つ最大の公開言語モデルであり、TIIのRefinedWebデータセットを使用して3.5兆トークンを使用してトレーニングされました。これはオープンモデルにおける最長の単一エポックの事前トレーニングを表しています。 Hugging Face Hub(ベースモデルとチャットモデル)でモデルを見つけることができ、Falcon Chat Demo Spaceでモデルと対話することができます。 Falcon 180Bは、自然言語タスク全体で最先端の結果を実現しています。これは(事前トレーニング済みの)オープンアクセスモデルのリーダーボードをトップし、PaLM-2のようなプロプライエタリモデルと競合しています。まだ明確にランク付けすることは難しいですが、PaLM-2 Largeと同等の性能を持ち、Falcon 180Bは公に知られている最も能力のあるLLMの一つです。 このブログ投稿では、いくつかの評価結果を見ながらFalcon 180Bがなぜ優れているのかを探求し、モデルの使用方法を紹介します。 Falcon-180Bとは何ですか? Falcon 180Bはどれくらい優れていますか? Falcon 180Bの使用方法は? デモ ハードウェア要件…
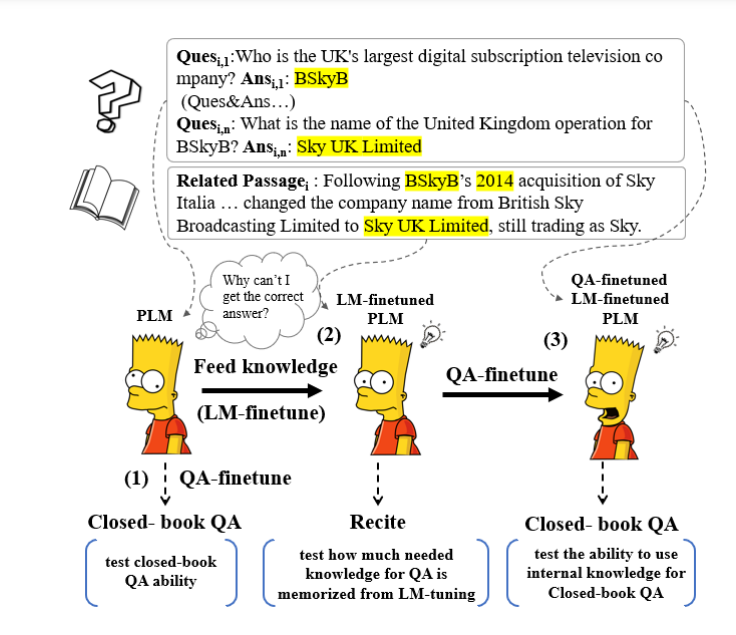
「大規模な言語モデルの探索-パート3」
「この記事は主に自己学習のために書かれていますしたがって、広く深く展開されています興味のあるセクションをスキップしたり、自分が興味を持っている分野を探求するために、自由に進めてください以下にはいくつかの...」

GGMLとllama.cppを使用してLlamaモデルを量子化する
この記事では、私たちはGGMLとllama.cppを使用してファインチューニングされたLlama 2モデルを量子化しますその後、GGMLモデルをローカルで実行し、NF4、GPTQ、およびGGMLのパフォーマンスを比較します

「セマンティックカーネルへのPythonistaのイントロ」
ChatGPTのリリース以来、大規模言語モデル(LLM)は産業界とメディアの両方で非常に注目されており、これによりLLMを活用しようとする前例のない需要が生まれました...

AIの生成体験を向上させる Amazon SageMakerホスティングでのストリーミングサポートの導入
「Amazon SageMakerリアルタイム推論を通じたレスポンスストリーミングの提供を発表し、大変興奮していますこれにより、チャットボット、仮想アシスタント、音楽ジェネレータなどの生成型AIアプリケーションのインタラクティブな体験を構築する際に、SageMakerリアルタイム推論を使用してクライアントに連続的に推論レスポンスをストリーミングできるようになりましたこの新機能により、レスポンス全体が生成されるのを待つのではなく、利用可能な場合にすぐにレスポンスをストリーミング開始できますこれにより、生成型AIアプリケーションの最初のバイトまでの時間を短縮できますこの記事では、インタラクティブなチャットのユースケースに対して、新しいレスポンスストリーミング機能を使用したSageMakerリアルタイムエンドポイントを使用してストリーミングWebアプリケーションを構築する方法を紹介しますサンプルデモアプリケーションのUIにはStreamlitを使用しています」

AudioLDM 2, でも速くなりました ⚡️
AudioLDM 2は、Haohe Liuらによる「AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining」で提案されました。AudioLDM 2は、テキストプロンプトを入力として受け取り、対応するオーディオを予測します。リアルな音効、人の声、音楽を生成することができます。 生成されるオーディオは高品質ですが、元の実装での推論の実行は非常に遅いです。10秒のオーディオサンプルを生成するのに30秒以上かかります。これは、深いマルチステージのモデリングアプローチ、大きなチェックポイントサイズ、最適化されていないコードなど、複数の要素の組み合わせによるものです。 このブログ記事では、Hugging Faceの🧨 Diffusersライブラリを使用してAudioLDM 2を使用する方法を紹介し、半精度、フラッシュアテンション、コンパイルなどのコードの最適化、スケジューラの選択、ネガティブプロンプティングなどのモデルの最適化を探求します。その結果、推論時間を10倍以上短縮でき、出力オーディオの品質の低下は最小限です。ブログ記事には、コードはすべて含まれていますが、説明は少なめです。 最後まで読んでください。わずか1秒で10秒のオーディオサンプルを生成する方法がわかります! モデルの概要 Stable Diffusionに触発され、AudioLDM 2はテキストからオーディオへの潜在的な拡散モデル(LDM)であり、テキストの埋め込みから連続的なオーディオ表現を学習します。 全体の生成プロセスは以下のように要約されます: テキスト入力x\boldsymbol{x}xを与えると、2つのテキストエンコーダーモデルが使用され、テキストの埋め込みが計算されます:CLAPのテキストブランチとFlan-T5のテキストエンコーダー…

「Llama 2がコーディングを学ぶ」
イントロダクション Code Llamaは、コードタスクに特化した最新のオープンアクセスバージョンであり、Hugging Faceエコシステムでの統合をリリースすることに興奮しています! Code Llamaは、Llama 2と同じ許容されるコミュニティライセンスでリリースされ、商業利用が可能です。 今日、私たちは以下をリリースすることに興奮しています: モデルカードとライセンスを備えたHub上のモデル Transformersの統合 高速かつ効率的な本番用推論のためのテキスト生成推論との統合 推論エンドポイントとの統合 コードのベンチマーク Code LLMは、ソフトウェアエンジニアにとってのエキサイティングな開発です。IDEでのコード補完により生産性を向上させることができ、ドックストリングの記述などの繰り返しや面倒なタスクを処理することができ、ユニットテストを作成することもできます。 目次 イントロダクション 目次 Code Llamaとは? Code Llamaの使い方 デモ Transformers…

パスワードを使用したGit認証の非推奨化
私たちはサービスのセキュリティ向上に取り組んでいるため、Hugging Face Hubを介してGitを使用してやり取りする際の認証方法を変更しています。2023年10月1日以降、パスワードによるコマンドラインGit操作の認証は受け付けなくなります。代わりに、パーソナルアクセストークンやSSHキーなどのより安全な認証方法の使用をお勧めします。 背景 最近数ヶ月間、サインインアラートやGitでのSSHキーのサポートなど、さまざまなセキュリティ強化を実施してきました。しかし、ユーザーはまだユーザー名とパスワードでGit操作を認証することができました。セキュリティをさらに向上させるため、トークンベースまたはSSHキー認証に移行します。トークンベースおよびSSHキー認証は、セキュリティと制御を向上させるユニークな、取り消し可能な、ランダムな機能を提供します。 今日の必要なアクション 現在、HFアカウントのパスワードを使用してGitと認証している場合は、2023年10月1日までにパーソナルアクセストークンまたはSSHキーを使用するように切り替えてください。 パーソナルアクセストークンへの切り替え アカウントのアクセストークンを生成する必要があります。以下の手順に従って、トークンを生成できます: https://huggingface.co/docs/hub/security-tokens#user-access-tokens アクセストークンを生成した後、以下のコマンドを使用してGitリポジトリを更新できます: $: git remote set-url origin https://<user_name>:<token>@huggingface.co/<user_name>/<repo_name> $: git pull origin または新しいリポジトリをクローンする場合、Git認証情報を求められたときにパスワードの代わりにトークンを入力することもできます。 SSHキーへの切り替え SSHキーを生成し、アカウントに追加するためのガイドに従ってください:…
画像中のテーブルの行と列をトランスフォーマーを使用して検出する
はじめに 非構造化データを扱ったことがあり、ドキュメント内のテーブルの存在を検出する方法を考えたことはありますか?ドキュメントを迅速に処理するための方法を提供しますか?この記事では、トランスフォーマーを使用して、テーブルの存在だけでなく、テーブルの構造を画像から認識する方法を見ていきます。これは、2つの異なるモデルによって実現されます。1つはドキュメント内のテーブルの検出のためのもので、もう1つはテーブル内の個々の行と列を認識するためのものです。 学習目標 画像上のテーブルの行と列を検出する方法 Table TransformersとDetection Transformer(DETR)の概要 PubTables-1Mデータセットについて Table Transformerでの推論の実行方法 ドキュメント、記事、PDFファイルは、しばしば重要なデータを伝えるテーブルを含む貴重な情報源です。これらのテーブルから情報を効率的に抽出することは、異なるフォーマットや表現の間の課題により複雑になる場合があります。これらのテーブルを手動でコピーまたは再作成するのは時間がかかり、ストレスがかかることがあります。PubTables-1Mデータセットでトレーニングされたテーブルトランスフォーマーは、テーブルの検出、構造の認識、および機能分析の問題に対処します。 この記事はData Science Blogathonの一環として公開されました。 この方法はどのように実現されたのですか? これは、PubTables-1Mという名前の大規模な注釈付きデータセットを使用して、記事などのドキュメントや画像を検出するためのトランスフォーマーモデルであるTable Transformerによって実現されました。このデータセットには約100万のパラメータが含まれており、いくつかの手法を用いて実装されており、モデルに最先端の感触を与えています。効率性は、不完全な注釈、空間的な整列の問題、およびテーブルの構造の一貫性の課題に取り組むことで達成されました。モデルとともに公開された研究論文では、テーブルの構造認識(TSR)と機能分析(FA)のジョイントモデリングにDetection Transformer(DETR)モデルを活用しています。したがって、DETRモデルは、Microsoft Researchが開発したTable Transformerが実行されるバックボーンです。DETRについてもう少し詳しく見てみましょう。 DEtection TRansformer(DETR) 前述のように、DETRはDEtection TRansformerの略であり、エンコーダーデコーダートランスフォーマーを使用したResNetアーキテクチャなどの畳み込みバックボーンから構成されています。これにより、オブジェクト検出のタスクを実行する潜在能力を持っています。DETRは、領域提案、非最大値抑制、アンカー生成などの複雑なモデル(Faster…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.