Learn more about Search Results Scipy - Page 8

- You may be interested
- AGI(人工汎用知能)にどれくらい近づいて...
- Google DeepMindによる新たなブレイクスル...
- LLMとデータ分析:ビジネスの洞察を得るた...
- シリコンボレー:デザイナーがチップ支援...
- 犬にインスパイアされたバーコアでロボッ...
- AIの時代のコーディング:ChatGPTの役割と...
- コースを安定させる:LLMベースのアプリケ...
- MeLoDyとは:音楽合成のための効率的なテ...
- 車両ルーティング問題 正確な解法とヒュー...
- 「汗をかくロボットが、人々が高温による...
- Falcon LLM:オープンソースLLMの新しい王者
- いつでもどんな人にでもメッセージを明確...
- “妊娠中の睡眠不足と活動量が早産のリスク...
- 「夢の彫刻:DreamTimeは、テキストから3D...
- AIによるテキストメッセージングの変革:...

データサイエンスにおける正規分布の適用と使用
データサイエンスを始める際に非常に困難なことの一つは、その旅がどこから始まり、どこで終わるのかを正確に把握することですデータサイエンスの旅の終わりに関して言えば、それは...

Falcon-7Bの本番環境への展開
これまでに、ChatGPTの能力と提供するものを見てきましたしかし、企業利用においては、ChatGPTのようなクローズドソースモデルは、企業がデータを制御できないというリスクがあるかもしれません...
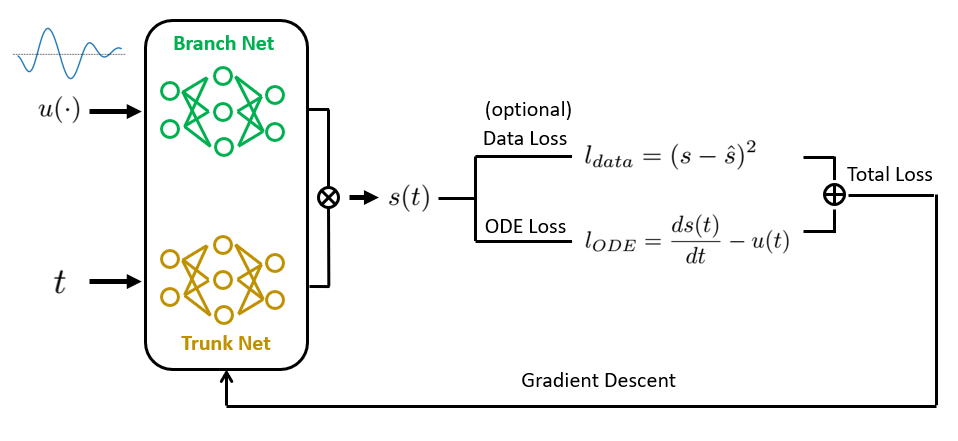
物理情報を組み込んだDeepONetによるオペレータ学習 ゼロから実装しましょう
普通微分方程式と偏微分方程式(ODEs / PDEs)は、物理学や生物学から経済学や気候科学まで、科学と工学の多くの分野の基礎ですそれらは...
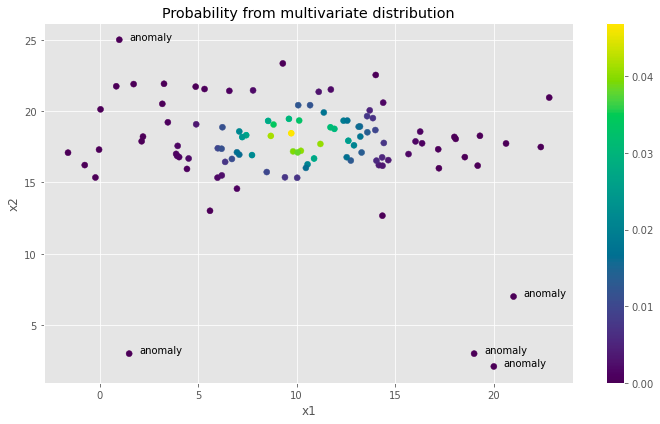
多変量ガウス分布による異常検知の基本
私たちの生まれつきのパターン認識能力によって、私たちはこのスキルを使って抜け落ちた部分を埋めたり、次に何が起こるかを予測したりすることができますしかし時折、私たちの予測に合わないことが起こります...

RAPIDS:簡単にMLモデルを加速するためにGPUを使用する
はじめに 人工知能(AI)がますます成長するにつれて、より高速かつ効率的な計算能力の需要が高まっています。機械学習(ML)モデルは計算量が多く、モデルのトレーニングには時間がかかることがあります。しかし、GPUの並列処理能力を使用することで、トレーニングプロセスを大幅に加速することができます。データサイエンティストはより速く反復し、より多くのモデルで実験し、より短い時間でより良い性能のモデルを構築することができます。 使用できるライブラリはいくつかあります。今日は、GPUの知識がなくてもMLモデルの加速化にGPUを使用する簡単な解決策であるRAPIDSについて学びます。 学習目標 この記事では、以下のことについて学びます: RAPIDS.aiの概要 RAPIDS.aiに含まれるライブラリ これらのライブラリの使用方法 インストールとシステム要件 この記事は、Data Science Blogathonの一部として公開されました。 RAPIDS.AI RAPIDSは、GPU上で完全にデータサイエンスパイプラインを実行するためのオープンソースのソフトウェアライブラリとAPIのスイートです。RAPIDSは、最も人気のあるPyDataライブラリと一致する使い慣れたAPIを持ちながら、優れたパフォーマンスと速度を提供します。これは、NVIDIA CUDAとApache Arrowで開発されており、その非凡なパフォーマンスの理由です。 RAPIDS.AIはどのように動作するのですか? RAPIDSは、GPUを使用した機械学習を利用してデータサイエンスおよび分析ワークフローのスピードを向上させます。GPU最適化されたコアデータフレームを持っており、データベースと機械学習アプリケーションの構築を支援し、Pythonに似た設計となっています。RAPIDSは、データサイエンスパイプラインを完全にGPU上で実行するためのライブラリのコレクションを提供します。これは、2017年にGPU Open Analytics Initiative(GoAI)と機械学習コミュニティのパートナーによって作成され、Apache Arrowのカラムメモリプラットフォームに基づいたGPUデータフレームを使用して、エンドツーエンドのデータサイエンスおよび分析ワークフローをGPU上で加速するためのものです。RAPIDSには、機械学習アルゴリズムと統合されるDataframe APIも含まれています。 データの移動量を減らした高速データアクセス…

NumpyとPandasを超えて:知られざるPythonライブラリの潜在能力の解放
Pythonでのデータ操作と計算について話すとき、一般的にはPandasとNumpyを思い浮かべます他にも3つの強力なライブラリを見つけましょう
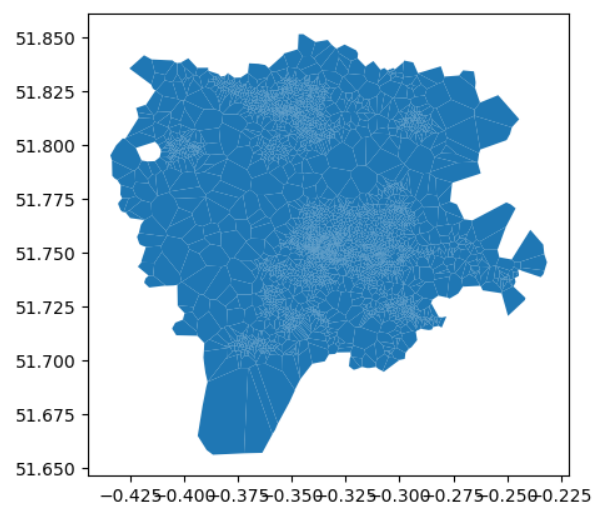
郵便番号レベルでの地理空間データの操作
一部の国では、郵便番号は地域ではなく、ポイントやルートで表されます例えば、カナダの郵便番号の最後の3桁は、地域配送ユニットに対応していて、それは一つの家に対応するかもしれません...

データアナリストからデータサイエンティストへのキャリアチェンジの方法は?
人々は常にデータを扱っており、データアナリストは専門知識を身につけた後、よりチャレンジングな役割を求めています。データサイエンティストは、最も収益性の高いキャリアオプションの1つとされています。スキルセットの拡大が必要ですが、いくつかの教育プラットフォームが変化に有益な洞察を提供しています。多くのデータアナリストが成功して転身していますし、あなたも次の転身者になることができます! 以下のステップは、データサイエンティストとしてのキャリアをスタートさせる際に、企業の成長に貢献し、専門知識を増やすのに役立ちます: スキルギャップの評価 データサイエンティストの役割に必要な基本的なスキルと知識 データサイエンティストはデータを実験する必要があるため、新しいアイデアや研究を開発するマインドセットが重要です。過去の実験のミスを分析する能力も同様に重要です。これに加えて、以下のような技術スキルと知識が求められます: 技術スキル: PythonやRなどのプログラミング言語やデータ言語 線形回帰やロジスティック回帰、ランダムフォレスト、決定木、SVM、KNNなどの機械学習アルゴリズム SAP HANA、MySQL、Microsoft SQL Server、Oracle Databaseなどのリレーショナルデータベース Natural Language Processing(NLP)、Optical Character Recognition(OCR)、Neural networks、computer vision、deep learningなどの特殊なスキル RShiny、ggplot、Plotly、Matplotlitなどのデータ可視化能力 Hadoop、MapReduce、Sparkなどの分散コンピューティング 分析スキル:…
科学ソフトウェアの開発
この記事では、このシリーズの最初の記事で示されたように、科学ソフトウェアの開発においてTDDの原則に従って、Sobelフィルタとして知られるエッジ検出フィルタを開発します
技術的なバックグラウンドがなくてもデータサイエンティストになる方法:ヒントと戦略
通常投稿している内容とは少し異なるストーリーになります具体的なツールや技術の紹介でもなく、チュートリアルや実践例でもありません今回は、私がいつも考えていた質問に答えたいと思います...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.