Learn more about Search Results Meg - Page 8

- You may be interested
- 『AWS SageMaker Data Wranglerの新機能で...
- 「AIを活用したポッドキャストの始め方と...
- 手首に装着するモバイルアルコールセンサ...
- 「Google Chromeは、努力を要さずに読むこ...
- 「PyTorchモデルのパフォーマンス分析と最...
- スタンフォード大学とMilaの研究者は、多...
- CMUの研究者がFROMAGeを紹介:凍結された...
- 「MosaicMLは、AIユーザーが精度を向上し...
- 「NTUシンガポールの研究者たちは、テキス...
- 学習率のチューニングにうんざりしていま...
- 暗号学のゴシップ パート1と2
- LMSYS ORG プレゼント チャットボット・ア...
- バイオメディカルインサイトのための生成AI
- 「3D-GPT(3D-指示駆動型モデリングのため...
- 時間系列予測における適合性予測

Hugging Face Spacesでタンパク質を可視化する
この投稿では、Hugging Face Spacesでタンパク質を可視化する方法について見ていきます。 動機 🤗 タンパク質は、医薬品から洗剤まで私たちの生活に大きな影響を与えています。タンパク質の機械学習は、新しい興味深いタンパク質の設計を支援するための急速に成長している分野です。タンパク質は、主にアミノ酸と呼ばれる一連の構成要素を3D空間に配列して、タンパク質の機能を与える複雑な3Dオブジェクトです。機械学習の目的で、タンパク質は、例えば座標、グラフ、またはタンパク質言語モデルで使用するための1次元の文字列として表現することができます。 タンパク質の有名な機械学習モデルの一つにAlphaFold2があります。AlphaFold2は、類似のタンパク質の多重配列と構造モジュールを使用してタンパク質配列の構造を予測します。 AlphaFold2が登場して以来、OmegaFold、OpenFoldなど、さまざまなモデルが登場しました(詳細はこのリストやこのリストを参照)。 見ることは信じること タンパク質の構造は、タンパク質の機能を理解する上で重要な要素です。現在、mol*や3dmol.jsなどのブラウザで直接タンパク質を可視化するためのツールがいくつか利用可能です。この投稿では、3Dmol.jsとHTMLブロックを使用して、Hugging Face Spaceに構造可視化を統合する方法を学びます。 必要条件 すでにgradio Pythonパッケージがインストールされていること、およびJavascript / JQueryの基本的な知識を持っていることを確認してください。 コードの概要 3Dmol.jsのセットアップ方法に入る前に、インターフェースの最小機能デモを作成する方法を見てみましょう。 以下のコードは、4桁のPDBコードまたはPDBファイルを受け入れる簡単なデモアプリを作成します。アプリは、RCSB Protein Databankからpdbファイルを取得して表示するか、アップロードされたファイルを使用して表示します。 import gradio…

倫理と社会のニュースレター#1
Hello, world! オープンソース企業として創業したHugging Faceは、技術におけるいくつかの重要な倫理的価値、すなわち協力、責任、透明性に基づいて設立されました。オープンな環境でコードを記述することは、自分のコードとその選択肢が世界に公開され、他の人が批判や追加を行うために利用可能であることを意味します。Hugging Face Hubをホストとしてモデルやデータを提供するようになると、リサーチコミュニティは再現性を直接統合し、それを会社の基本的な価値としました。そして、Hugging Faceに存在するデータセットやモデルの数が増えるにつれ、Hugging Faceのメンバーは、リサーチコミュニティによって定義された新たな価値に対応するために、ドキュメントの要件や無料の指導コースを導入しました。これにより、技術の進歩につながる数学、コード、プロセス、人々の理解を含む、監査可能性の価値が追加されました。 AIにおける倫理をどのように実施するかは、オープンな研究領域です。応用倫理と人工知能に関する学問や理論は数十年前から存在していましたが、AI開発における倫理の実践とテストされた手法は、過去10年間にわずかに現れ始めたに過ぎません。これは、AIシステムの構築ブロックである機械学習モデルが、それらの進歩を測定するために使用されてきた基準を超えたため、機械学習システムが日常生活に影響を与える実用的なアプリケーションの範囲で広範に採用されたためです。倫理に基づくAIの進歩に興味を持つ私たちのうちの何人かは、倫理的な原則に基づいて設立された機械学習企業に参加することは、成長が始まり、世界中の人々が倫理的なAIの問題に取り組み始めるときに、将来のAIがどのようになるかを根本的に形作る機会です。これは、倫理を念頭に置いて最初から設立されたテクノロジー企業がどのように見えるのかという、新しい形の現代のAIの実験です。機械学習に倫理の視点を当てるとは、良い機械学習を民主化するとはどういうことでしょうか。 このため、私たちは新しいHugging Face Ethics and Societyニュースレターで最近の考え方と取り組みを共有しています。このニュースレターは、春分点と夏至点に毎シーズン発行されます。これは、私たちHugging Faceの「倫理と社会の専門家」というオープンなグループが一緒になって機械学習の広範な社会的文脈やHugging Faceの役割に取り組むために作成されました。私たちは、会社全体が価値に基づいた意思決定を行うためには、専門チームではなく、共有の責任とコミットメントが必要であると考えています。私たちの仕事の倫理的なリスクを認識し、学ぶために、すべての関係者が責任を共有することが重要です。 私たちは、現在のところ「良い」機械学習の意味について継続的に研究しており、それを定義するための基準を提供しようとしています。これは進行中のプロセスであり、現在の日常生活に影響を与える機械学習コミュニティの異なる価値観と調和する点に到達するために、現在の日常生活で可能な限り何ができるかを見据えています。私たちは、Hugging Faceの創業の原則に基づいてこのアプローチを展開しています。 私たちはオープンソースコミュニティと協力することを目指しています。これには、ドキュメンテーションと評価のための現代化されたツール、コミュニティディスカッション、Discord、さらには異なる価値観に基づいて自分の作業を共有するための貢献者への個別サポートが含まれます。 私たちは、自分たちの考え方やプロセスを透明にすることを目指しています。プロジェクトの開始時に特定のプロジェクト価値についての執筆を共有し、AIポリシーについての考え方も共有しています。また、この作業に対するコミュニティからのフィードバックも学ぶためのリソースとして得ています。 私たちは、現在と将来の影響に対する責任を負いながら、これらのツールとアーティファクトの作成を基盤としています。この優先順位付けにより、機械学習システムをより監査可能で理解可能にするプロジェクト設計が実現しました。これには、ML以外の専門知識を持つ人々にも適した教育プロジェクトやコーディング不要のMLデータ分析ツールなどが含まれます。 これらの基本から出発し、私たちは、プロジェクトごとの特定の文脈と予測される影響に重点を置いた価値観の実施方法を取っています。したがって、ここではグローバルな価値観や原則の一覧を提供することはありません。その代わり、このニュースレターなど、プロジェクトごとの考え方を引き続き共有し、理解が進むにつれてさらに共有する予定です。異なる価値観と影響を受ける人々を特定するために、コミュニティのディスカッションが重要であると考えているため、Hugging Face Hubにオンラインで接続できる人は誰でも直接モデル、データ、およびスペースに関するフィードバックを提供できる機会を最近提供しました。オープンなディスカッションのツールと並行して、包括的なコミュニティスペースのための行動規範とコンテンツガイドラインを作成しました。セキュアなML開発のためのプライベートHub、モデルを厳密に評価するための評価ライブラリ、スキューとバイアスを分析するためのデータ解析のためのコード、モデルのトレーニング時の炭素排出量を追跡するためのツールを開発しています。また、倫理的および法的な問題について報告するためにモデルとスペースのリポジトリを「フラグ」とすることも可能にしました。…

最適化ストーリー:ブルーム推論
この記事では、bloomをパワーアップする効率的な推論サーバーの裏側について説明します。 数週間にわたり、レイテンシーを5倍削減し(スループットを50倍に増やしました)、このような速度向上を達成するために私たちが経験した苦労やエピックな勝利を共有したかったです。 さまざまな人々が多くの段階で関与していたため、ここではすべてをカバーすることはできません。また、最新のハードウェア機能やコンテンツが定期的に登場するため、一部の内容は古くなっているか、まったく間違っている可能性があることをご了承ください。 もし、お好みの最適化手法が議論されていなかったり、正しく表現されていなかったりした場合は、お詫び申し上げます。新しいことを試してみたり、間違いを修正するために、ぜひお知らせください。 言うまでもなく、まず大きなモデルが最初にアクセス可能でなければ、それを最適化する理由はありません。これは、多くの異なる人々によってリードされた信じられないほどの取り組みでした。 トレーニング中にGPUを最大限に活用するために、いくつかの解決策が検討され、結果としてMegatron-Deepspeedが最終的なモデルのトレーニングに選ばれました。これは、コードがそのままではtransformersライブラリと互換性がない可能性があることを意味します。 元のトレーニングコードのため、通常行っていることの1つである既存のモデルをtransformersに移植することに取り組みました。目標は、トレーニングコードから関連する部分を抽出し、transformers内に実装することでした。この取り組みには「Younes」が取り組みました。これは、1ヶ月近くかかり、200のコミットが必要でした。 後で戻ってくるいくつかの注意点があります: 小さなモデルbigscience/bigscience-small-testingとbigscience/bloom-560mを用意する必要があります。これは非常に重要です。なぜなら、それらと一緒に作業するとすべてが高速化されるからです。 まず、最後のログがバイトまで完全に同じになることを望むことをあきらめる必要があります。PyTorchのバージョンがカーネルを変更し、微妙な違いを導入する可能性があり、異なるハードウェアでは異なるアーキテクチャのため異なる結果が得られる場合があります(コストの理由から常にA100 GPUで開発したくはないでしょう)。 すべてのモデルにとって、良い厳格なテストスイートを作ることは非常に重要です 私たちが見つけた最高のテストは、固定された一連のプロンプトを持つことでした。プロンプトを知っており、決定論的な結果が得られる必要があります。2つの生成物が同じであれば、小さなログの違いは無視できます。ドリフトが見られるたびに調査する必要があります。それは、あなたのコードがやるべきことをしていないか、または実際にそのモデルがドメイン外であるためにノイズに対してより敏感であるかのいずれかです。いくつかのプロンプトと十分に長いプロンプトがあれば、すべてのプロンプトを誤ってトリガーする可能性は低くなります。プロンプトが多ければ多いほど良く、プロンプトが長ければ長いほど良いです。 最初のモデル(small-testing)は、bloomと同じようにbfloat16であり、すべてが非常に似ているはずですが、それほどトレーニングされていないか、うまく機能しないため、出力が大きく変動します。そのため、これらの生成テストに問題がありました。2番目のモデルはより安定していましたが、bfloat16ではなくfloat16でトレーニングおよび保存されていました。そのため、2つの間にはエラーの余地があります。 完全に公平を期すために言えば、bfloat16→float16への変換は推論モードでは問題なさそうです(bfloat16は主に大きな勾配を扱うために存在しません)。 このステップでは、重要なトレードオフが発見され、実装されました。bloomは分散環境でトレーニングされたため、一部のコードはLinearレイヤー上でテンソル並列処理を行っており、単一のGPU上で同じ操作を実行すると異なる結果が得られていました。これを特定するのにかなりの時間がかかり、100%の準拠を選択した場合、モデルの速度が遅くなりましたが、少しの差がある場合は実行が速く、コードがシンプルになりました。設定可能なフラグを選択しました。 注:この文脈でのパイプライン並列処理(PP)は、各GPUがいくつかのレイヤーを所有し、各GPUがデータの一部を処理してから次のGPUに渡すことを意味します。 これで、動作可能なtransformersのクリーンなバージョンがあり、これに取り組むことができます。 Bloomは352GB(176Bパラメーターのbf16)のモデルであり、それに合わせるために少なくともそれだけのGPU RAMが必要です。一時的に小さなマシンでCPUにオフロードすることを検討しましたが、推論速度が桁違いに遅くなるため、それを取り下げました。 次に、基本的にはパイプラインを使用したかったのです。つまり、ドッグフーディングであり、これがAPIが常に裏で使用しているものです。 ただし、pipelinesは分散意識がありません(それがその目的ではありません)。オプションを簡単に話し合った後、新しく作成されたdevice_map="auto"を使用してモデルのシャーディングを管理するためにaccelerateを使用することにしました。いくつかのバグを修正し、transformersのコードを修正してaccelerateが正しい仕事をするのを助ける必要がありました。 これは、transformersのさまざまなレイヤーを分割し、各GPUにモデルの一部を与えて動作させることで機能します。つまり、GPU0が作業を行い、次にGPU1に引き渡し、それ以降同様に行います。 最終的には、上に小さなHTTPサーバーを置くことで、bloom(大規模なモデル)を提供できるようになりました!…

🤗評価による言語モデルのバイアスの評価
大規模な言語モデルのサイズと能力は過去数年間で大幅に向上していますが、これらのモデルとそのトレーニングデータに刻み込まれたバイアスへの懸念も同様に高まっています。実際、多くの人気のある言語モデルは特定の宗教や性別に対してバイアスがあることが判明しており、これによって差別的な考えの促進やマージナライズドグループへの害の持続が引き起こされる可能性があります。 コミュニティがこのようなバイアスを探索し、言語モデルがエンコードする社会的な問題に対する理解を強化するために、私たちはバイアスのメトリクスと測定値を🤗 Evaluate ライブラリに追加する作業を行ってきました。このブログ投稿では、新しい機能のいくつかの例とその使用方法について紹介します。GPT-2 や BLOOM のような因果言語モデル (CLMs) の評価に重点を置き、プロンプトに基づいた自由なテキストの生成能力を活かします。 実際に作業を見るには、作成した Jupyter ノートブックをチェックしてください! ワークフローには次の2つの主要なステップがあります: あらかじめ定義された一連のプロンプトを言語モデルに提示する(🤗 データセットでホストされている) メトリクスや測定値を使用して生成物を評価する(🤗 Evaluate を使用) 有害な言語に焦点を当てた3つのプロンプトベースのタスクでバイアスの評価を進めましょう:有害性、極性、および害悪性。ここで紹介する作業は、Hugging Face ライブラリを使用してバイアスの分析にどのように活用するかを示すものであり、使用される特定のプロンプトベースのデータセットには依存しません。重要なことは、最近導入されたバイアスの評価用データセットがモデルが生み出す様々なバイアスを捉えていない初歩的なステップであるということです(詳細については以下の議論セクションを参照してください)。 有害性 実世界のコンテキストで CLM…

機械学習におけるバイアスについて話しましょう!倫理と社会に関するニュースレター #2
機械学習におけるバイアスは普遍的であり、また複雑です。実際には、単一の技術的介入では問題を意味のある形で解決することはできないほど複雑です。機械学習モデルは社会技術システムであり、その展開コンテキストに依存し、常に進化しながら、不平等や有害なバイアスを悪化させる社会的な傾向を増幅させます。 これは、慎重に機械学習システムを開発するためには警戒心が必要であり、展開コンテキストからのフィードバックに対応することが求められます。これには、コンテキスト間での教訓の共有や、機械学習開発のあらゆるレベルでバイアスの兆候を分析するためのツールの開発などが必要です。 このブログポストでは、Ethics and Societyのメンバーが学んだ教訓と、機械学習におけるバイアスに対処するために開発したツールを共有しています。最初の部分では、バイアスとそのコンテキストについて幅広く考察しています。既に読んでいて、具体的にツールについて戻ってきた場合は、データセットやモデルのセクションに移動してください! 機械学習におけるバイアスに対処するために🤗のチームメンバーが開発したツールの一部を選択 目次: 機械バイアスについて 機械バイアス:機械学習システムからリスクへ バイアスをコンテキストに置く ツールと推奨事項 機械学習開発全体でのバイアスの対処 タスクの定義 データセットのキュレーション モデルのトレーニング 🤗のバイアスツールの概要 機械バイアス:機械学習システムから個人および社会的なリスクへ 機械学習システムは、さまざまなセクターやユースケースで展開されるため、以前に見たことのないスケールで複雑なタスクを自動化することができます。技術が最も効果的に機能する場合、人々と技術システムの間の相互作用をスムーズにし、高度に繰り返しの多い作業の必要性をなくしたり、研究をサポートするための情報処理の新しい方法を開放することができます。 しかし、同じシステムは、特にデータが人間の行動をエンコードする場合、差別的で虐待的な行動を再現する可能性があります。その結果、これらの問題は大幅に悪化する可能性があります。自動化とスケール展開は、次のようなことができます: 時間の経過とともに行動を固定化し、社会的な進歩が技術に反映されるのを妨げる オリジナルのトレーニングデータのコンテキストを超えて有害な行動を広める 予測を行う際にステレオタイプな関連性に過度に焦点を当てて不公平を増幅させる バイアスを「ブラックボックス」システム内に隠すことで救済の可能性を排除する これらのリスクをよりよく理解し対処するために、機械学習の研究者や開発者は、機械バイアスやアルゴリズムのバイアスなど、システムが展開コンテキストでさまざまな人口集団に対して負のステレオタイプや関連性をエンコードする可能性のあるメカニズムを研究し始めています。…

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…

コンピュート最適な大規模言語モデルトレーニングの経験的分析
私たちは次の問いに取り組みます「与えられた計算予算に対して、最適なモデルのサイズとトレーニングトークンの数は何か?」この質問に答えるために、私たちはさまざまなサイズのモデルをトレーニングし、さまざまなトークンの数で推定を行います私たちの主な結論は、現在の大規模言語モデルは、計算予算に対して非常に大きすぎる上に、十分なデータでトレーニングされていないということです
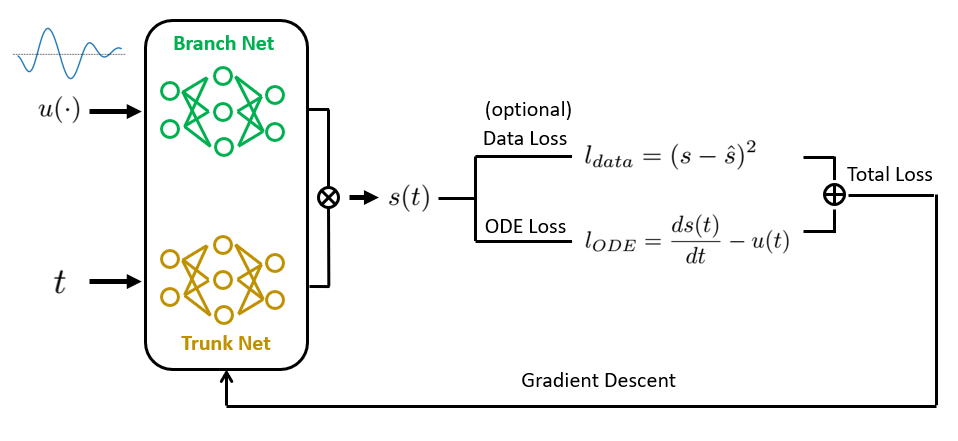
物理情報を組み込んだDeepONetによるオペレータ学習 ゼロから実装しましょう
普通微分方程式と偏微分方程式(ODEs / PDEs)は、物理学や生物学から経済学や気候科学まで、科学と工学の多くの分野の基礎ですそれらは...
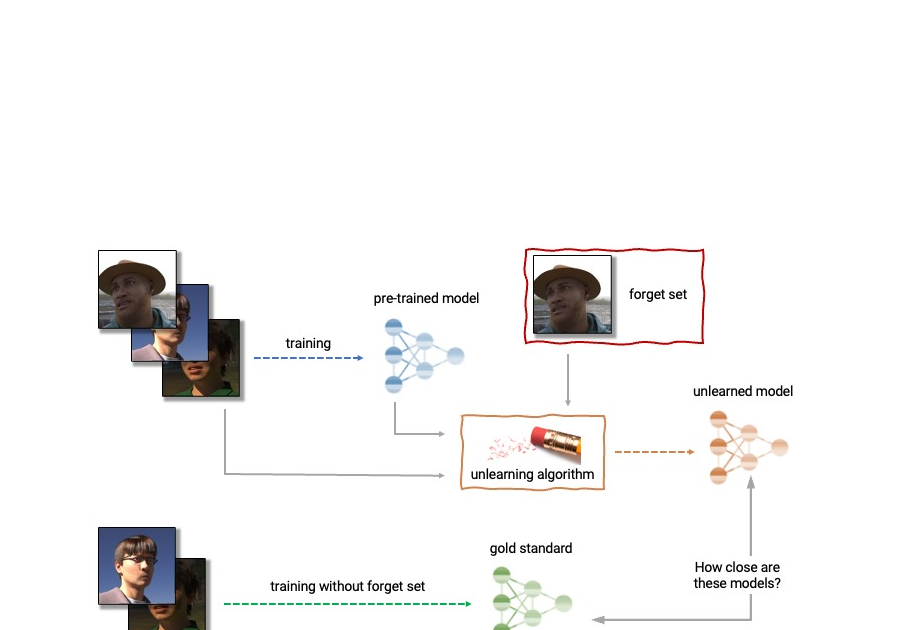
最初のマシンアンラーニングチャレンジを発表します
Googleの研究科学者であるFabian PedregosaとEleni Triantafillouによって投稿されました。 深層学習は最近、現実的な画像生成や印象的な検索システムから、人間のように会話をすることができる言語モデルまで、さまざまなアプリケーションで大きな進歩を遂げています。この進歩は非常に興味深いものですが、深層ニューラルネットワークモデルの広範な使用には注意が必要です。GoogleのAI原則に従って、私たちはフェアなバイアスの伝播と増幅、ユーザーのプライバシーの保護などの潜在的なリスクを理解し、軽減することにより、責任を持ってAI技術を開発することを目指しています。 削除されるデータの影響を完全に消去することは難しいです。データが保存されているデータベースから単純に削除するだけでなく、そのデータがトレーニングされた機械学習モデルに与える影響も消去する必要があります。さらに、最近の研究 [1, 2] は、メンバーシップ推論攻撃(MIA)を使用して、例が機械学習モデルのトレーニングに使用されたかどうかを非常に高い精度で推論することが可能であることを示しています。これはプライバシー上の懸念を引き起こす可能性があります。つまり、個人のデータがデータベースから削除されたとしても、その個人のデータがモデルのトレーニングに使用されたかどうかを推測することができる可能性があるということです。 上記の理由から、機械学習のサブフィールドである機械アンラーニングは、トレーニング例の特定のサブセットである「忘れるセット」の影響をトレーニング済みのモデルから除去することを目指しています。さらに、理想的なアンラーニングアルゴリズムは、特定の例の影響を除去する一方で、トレーニングセットの残りの部分における精度と保持例への一般化など、他の有益な特性を維持することができるようになっています。このアンラーニングされたモデルを生成するための直接的な方法は、忘れるセットのサンプルを除外した調整されたトレーニングセットでモデルを再トレーニングすることです。しかし、これは常に実行可能なオプションではありません。なぜなら、深層モデルの再トレーニングは計算コストが高いからです。理想的なアンラーニングアルゴリズムは、既にトレーニングされたモデルを出発点として使用し、要求されたデータの影響を効率的に除去するために調整を行うことができるでしょう。 今日、私たちは幅広い学術研究者と産業研究者のグループと協力して、初のマシンアンラーニングチャレンジを開催することを発表できて大変嬉しく思っています。このコンテストは、トレーニング後に特定のトレーニングイメージのサブセットを忘れる必要がある現実的なシナリオを考慮しています。コンテストはKaggleで開催され、忘れる品質とモデルの有用性の両方に関して自動的にスコアリングされます。このコンテストがマシンアンラーニングの最先端の技術の発展に貢献し、効率的で効果的かつ倫理的なアンラーニングアルゴリズムの開発を促進することを願っています。 マシンアンラーニングの応用 マシンアンラーニングは、ユーザーのプライバシー保護以外にも応用があります。例えば、トレーニングされたモデルから不正確な情報や古い情報を消去するためにアンラーニングを使用することができます(例えば、ラベリングのエラーや環境の変化によるもの)。また、有害な、操作された、または外れ値のデータを削除することもできます。 機械アンラーニングの分野は、ディファレンシャルプライバシーやライフロングラーニング、フェアネスなどの機械学習の他の分野と関連しています。ディファレンシャルプライバシーは、特定のトレーニング例がトレーニングされたモデルに与える影響が大きすぎないことを保証することを目指しています。これはアンラーニングの目標と比較して強い目標です。ライフロングラーニングの研究は、以前に習得したスキルを維持しながら連続的に学習できるモデルを設計することを目指しています。アンラーニングの研究が進展するにつれて、不公正なバイアスや異なるグループ(人口統計、年齢層など)のメンバーへの不公平な扱いを修正することによって、モデルのフェアネスを向上させる追加の方法も開かれるかもしれません。 アンラーニングの解剖学。アンラーニングアルゴリズムは、事前にトレーニングされたモデルとトレーニングセットから1つ以上のサンプル(「忘れるセット」)を入力として受け取ります。アンラーニングアルゴリズムは、モデル、忘れるセット、保持セットから更新されたモデルを生成します。理想的なアンラーニングアルゴリズムは、忘れるセットなしでトレーニングされたモデルと区別できないモデルを生成します。 機械のアンラーニングの課題 アンラーニングの問題は複雑で多面的であり、いくつかの相反する目標を含んでいます。要求されたデータを忘れること、モデルの有用性(保持および保留データの正確さ)を維持すること、効率性を維持することなどです。そのため、既存のアンラーニングのアルゴリズムは異なるトレードオフを行います。たとえば、完全な再学習はモデルの有用性を損なうことなく忘却を達成しますが、効率は低くなります。一方、重みにノイズを追加することで、有用性を犠牲にして忘却を達成します。 さらに、文献での忘却アルゴリズムの評価はこれまでに非常に一貫性がありませんでした。一部の研究では、忘れるサンプルの分類精度を報告しているものもありますが、他の研究では完全再学習モデルへの距離やメンバーシップ推論攻撃のエラーレートなど、忘却の品質を評価するための指標が異なります [4, 5, 6]。 私たちは、評価指標の一貫性の欠如と標準化されたプロトコルの欠如が、この分野の進歩に深刻な障害であると考えています。文献中の異なるアンラーニング手法を直接比較することができません。これにより、異なるアプローチの相対的な利点と欠点、および改良されたアルゴリズムの開発のためのオープンな課題と機会に対する狭い視野に取り残されます。このような評価の一貫性の問題に対処し、機械のアンラーニングの最先端を推進するために、私たちは広範な学術および産業の研究者グループと協力して、最初のアンラーニングチャレンジを開催することにしました。 最初のマシンアンラーニングチャレンジの発表 NeurIPS 2023…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.