Learn more about Search Results Loom - Page 8

- You may be interested
- マウス用のVRゴーグル:ネズミの世界の秘...
- ジェミニに会いましょう:Googleの最大か...
- 『自分のデータでChatGPTを訓練する方法:...
- 「夢を先に見て、後で学ぶ:DECKARDは強化...
- Google AIは、オーディオ、ビデオ、テキス...
- 「タンパク質設計の革命:ディープラーニ...
- あなたのRAGベースのLLMシステムの成功を...
- 「自己学習型プログラマー」というものは...
- 「2023年の最高のAI文法チェッカーツール」
- 清華大学の研究者たちは、メタラーニング...
- 「勾配降下法アルゴリズムとその直感的な...
- 「4つの方法で、生成AIがフィールドサービ...
- このAI論文では、既知のカメラパラメータ...
- Twitter用の15の最高のChatGPTプロンプト...
- Rによるディープラーニング

「AIはどれくらい環境に優しいのか?人間の作業と人工知能の二酸化炭素排出量を比較する」
近年、人工知能(AI)は驚異的な進展を遂げ、その応用は医療、銀行業、交通、環境保護などさまざまな産業に広がっています。しかし、AIの利用が広がるにつれて、環境への影響に関する懸念が浮上しています。特に、AIモデルの稼働と訓練に必要なエネルギーとそれによる温室効果ガスの排出についての懸念です。例えば、現在使用されている最も強力なAIシステムの1つであるGPT-3は、トレーニング中において、その寿命の間に5台の車によって生成される排出物と同等の排出物を生成します。 最近の研究では、多数のAIシステムの環境への影響が調査されており、特に文章の作成や絵画制作などのタスクを実行する能力に焦点が当てられています。研究チームは、ChatGPT、BLOOM、DALL-E2、MidjourneyといったさまざまなAIシステムによって生成される排出物と、同じタスクを人間が実行した場合に生じる排出物とを比較しました。文章の作成と画像の制作という2つの一般的なタスクが特に注目されました。 この研究の目的は、人間がこれらのタスクを実行する場合とAIが実行する場合の環境への影響を対比することです。研究チームは、AIに関連する環境費用にもかかわらず、これらのコストが通常人間が同様の活動を行う場合よりも低いことを示すことで、人間とAIの交換可能性を強調しました。結果は、言葉を生成する場合に驚くほどの差があることを示しています。 テキストを作成する際、AIシステムは人間が生成する二酸化炭素換算量(CO2e)の130倍から1500倍少なくなります。この大きな違いは、この状況でのAIの環境上の利点を強調しています。同様に、画像を作成する際、AIシステムは人間が生成するCO2eの310倍から2900倍少なくなります。これらの数字は、AIを使用して画像を作成する際にどれだけ少ない排出物が生成されるかを明確に示しています。 研究チームは、排出物の研究だけでは完全な情報を提供することができないことを理解することが重要であり、以下の重要な社会的な影響や要素が考慮される必要があることを共有しました。 職業的な置き換え:一部の産業では、AIが従来人間が担当してきた仕事を引き受けることによって、雇用の置き換えが生じる可能性があります。この置き換えの潜在的な経済的および社会的影響を適切に対処することが重要です。 合法性:AIシステムが道徳的および法的な原則に従って開発・利用されることが重要です。AIによって生成されるコンテンツの合法性とその潜在的な悪用に対処する必要があります。 リバウンド効果:AIがさまざまな産業に導入されると、予期せぬ影響が生じる場合があります。これらの結果は、使用量や生産量の増加として現れる可能性があります。 AIによっては代替できない人間の機能もあることを理解することが重要です。AIは、人間の創造性、共感性、意思決定を必要とする一部のタスクやポジションを行うことはできません。ただし、現在の研究は、さまざまなタスクにおいて人間と比較してAIが排出物を劇的に削減する可能性があることを示しています。これらの結果は環境の観点からは励みとなりますが、AIの統合が共有された目標と価値観に一致するように、より広範な倫理的、経済的、社会的要素の文脈で考慮される必要があります。排出物を大幅に減らすためにAIを使用するというアプローチは、現在の環境問題を解決するための有効な手段です。
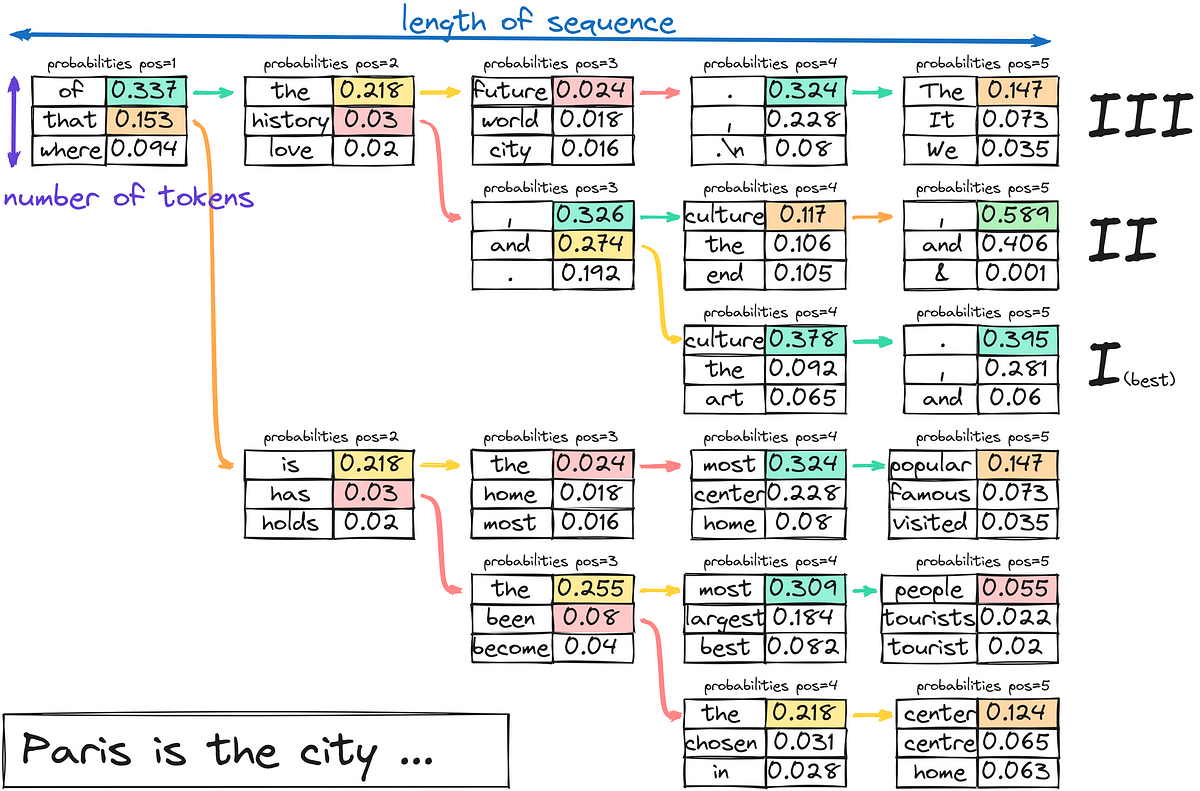
「LLMはどのようにテキストを生成するのか?」
今日は、3つ目のステップに集中します-テキストのデコードと生成最初の2つのステップに興味がある場合は、以下にコメントしてくださいそれらのトピックもカバーすることを検討しますさあ、少し潜りましょう...
「ゼロからLLMを構築する方法」
「これは、大規模言語モデル(LLM)を実践的に使用するシリーズの6番目の記事です以前の記事では、プロンプトエンジニアリングとファインチューニングを通じて事前学習済みのLLMを活用する方法について詳しく調査しましたこれらに対して…」

「MicrosoftのAI研究者が誤って大量のデータを公開」
クラウドセキュリティ企業Wizの科学者たちは、Microsoftの人工知能研究者が誤って大量の個人データを侵害していたことを発見しました

「アマゾン、無人レジ技術を衣料品店に適用」
大手小売り企業AmazonのJust Walk Out無人レジショッピング技術の衣料品向け新バージョンは、アパレルを無線周波数識別(RFID)によって追跡します

「ベイチュアン2に会おう:7Bおよび13Bのパラメータを持つ大規模な多言語言語モデルのシリーズ、2.6Tトークンでゼロからトレーニングされました」
大規模言語モデルは近年、大きな進展を遂げています。GPT3、PaLM、Switch Transformersなどの言語モデルは、以前のELMoやGPT-1のようなモデルの数百万から、数十億、あるいは数兆のパラメータを持つようになりました。人間に似た流暢さを持ち、様々な自然言語の活動を行う能力は、モデルのサイズの成長により大幅に向上しました。OpenAIのChatGPTのリリースにより、これらのモデルが人間の話し言葉に似たテキストを生成する能力が大いに注目されました。ChatGPTは、カジュアルな会話から難しいアイデアの明確化まで、さまざまな文脈で優れた言語スキルを持っています。 この革新は、自然言語の生成と理解を必要とするプロセスを自動化するために、巨大な言語モデルがどのように使用されるかを示しています。LLMの革新的な開発と使用が進んでいるにもかかわらず、GPT-4、PaLM-2、ClaudeなどのトップのLLMのほとんどはまだクローズドソースです。モデルのパラメータについて開発者や研究者が部分的なアクセスしか持てないため、このコミュニティがこれらのシステムを徹底的に分析や最適化することは困難です。LLMの透明性とオープンさがさらに向上することで、この急速に発展している分野での研究と責任ある進歩が加速される可能性があります。Metaが作成した巨大な言語モデルのコレクションであるLLaMAは、完全にオープンソースであることにより、LLMの研究コミュニティに大いに役立っています。 OPT、Bloom、MPT、Falconなどの他のオープンソースLLMとともに、LLaMAのオープンな設計により、研究者はモデルに自由にアクセスし、分析、テスト、将来の開発を行うことができます。このアクセシビリティとオープンさにより、LLaMAは他のプライベートLLMとは一線を画しています。Alpaca、Vicunaなどの新しいモデルは、オープンソースLLMの研究と開発のスピードアップによって可能になりました。しかし、英語はほとんどのオープンソースの大規模言語モデルの主な焦点となっています。たとえば、LLaMAの主なデータソースであるCommon Crawl1は、67%の事前学習データを含んでいますが、英語の資料しか含むことが許可されていません。MPTやFalconなど、異なる言語の能力に制約のあるフリーソースLLMも主に英語に焦点を当てています。 そのため、中国語などの特定の言語でのLLMの開発と使用は困難です。Baichuan Inc.の研究者は、この技術的な研究で、広範な多言語言語モデルのグループであるBaichuan 2を紹介しています。Baichuan 2には、13兆パラメータを持つBaichuan 2-13Bと7兆パラメータを持つBaichuan 2-7Bの2つの異なるモデルがあります。両モデルは、Baichuan 1よりも2.6兆トークン以上のデータを使用してテストされました。Baichuan 2は、大量のトレーニングデータにより、Baichuan 1を大幅に上回るパフォーマンスを発揮します。Baichuan 2-7Bは、MMLU、CMMLU、C-Evalなどの一般的なベンチマークで、Baichuan 1-7Bよりも約30%優れたパフォーマンスを示します。Baichuan 2は特に数学とコーディングの問題のパフォーマンスを向上させるように最適化されています。 Baichuan 2は、GSM8KとHumanEvalのテストでBaichuan 1の結果をほぼ2倍に向上させます。また、Baichuan 2は医療および法律の領域の仕事でも優れた成績を収めています。MedQAやJEC-QAなどのベンチマークで他のオープンソースモデルを上回り、ドメイン特化の最適化のための良い基礎モデルとなっています。彼らはまた、人間の指示に従う2つのチャットモデル、Baichuan 2-7B-ChatとBaichuan 2-13B-Chatを作成しました。これらのモデルは、対話や文脈を理解するのに優れています。彼らはBaichuan 2の安全性を向上させるための戦略についてさらに詳しく説明します。これらのモデルをオープンソース化することで、大規模言語モデルのセキュリティをさらに向上させながら、LLMの責任ある作成に関する研究を促進することができます。…

「ODSC West 2023に登場する10のトレンディングトピック」
ODSC Westまで残り1か月を切りました!ジェネラティブAI、LLMs、MLOps、機械学習、ディープラーニングなどに関する300時間以上の実践トレーニングセッション、ワークショップ、トークをお楽しみにしてくださいここではすべての素晴らしいセッションを紹介することはできませんが、以下は代表的なリストです...

「プロダクションでのあなたのLLMの最適化」
注意: このブログ投稿は、Transformersのドキュメンテーションページとしても利用可能です。 GPT3/4、Falcon、LLamaなどの大規模言語モデル(LLM)は、人間中心のタスクに取り組む能力を急速に向上させており、現代の知識ベース産業で不可欠なツールとして確立しています。しかし、これらのモデルを実世界のタスクに展開することは依然として課題が残っています: ほぼ人間のテキスト理解と生成能力を持つために、LLMは現在数十億のパラメータから構成される必要があります(Kaplanら、Weiら参照)。これにより、推論時のメモリ要件が増大します。 多くの実世界のタスクでは、LLMには豊富な文脈情報が必要です。これにより、推論中に非常に長い入力シーケンスを処理する能力が求められます。 これらの課題の核心は、特に広範な入力シーケンスを扱う場合に、LLMの計算およびメモリ能力を拡張することにあります。 このブログ投稿では、効率的なLLMの展開のために、現時点で最も効果的な技術について説明します: 低精度: 研究により、8ビットおよび4ビットの数値精度で動作することが、モデルのパフォーマンスに大幅な低下を伴わずに計算上の利点をもたらすことが示されています。 Flash Attention: Flash Attentionは、よりメモリ効率の高いアテンションアルゴリズムのバリエーションであり、最適化されたGPUメモリの利用により、高い効率を実現します。 アーキテクチャのイノベーション: LLMは常に同じ方法で展開されるため、つまり長い入力コンテキストを持つ自己回帰的なテキスト生成として、より効率的な推論を可能にする専用のモデルアーキテクチャが提案されています。モデルアーキテクチャの中で最も重要な進歩は、Alibi、Rotary embeddings、Multi-Query Attention(MQA)、Grouped-Query-Attention(GQA)です。 このノートブックでは、テンソルの視点から自己回帰的な生成の分析を提供し、低精度の採用の利点と欠点について包括的な探索を行い、最新のアテンションアルゴリズムの詳細な調査を行い、改良されたLLMアーキテクチャについて議論します。これを行う過程で、各機能の改善を示す実用的な例を実行します。 1. 低精度の活用 LLMのメモリ要件は、LLMを重み行列とベクトルのセット、およびテキスト入力をベクトルのシーケンスとして見ることで最も理解できます。以下では、重みの定義はすべてのモデルの重み行列とベクトルを意味するために使用されます。 この投稿の執筆時点では、LLMは少なくとも数十億のパラメータから構成されています。各パラメータは通常、float32、bfloat16、またはfloat16形式で保存される10進数の数値で構成されています。これにより、LLMをメモリにロードするためのメモリ要件を簡単に計算できます: X十億のパラメータを持つモデルの重みをロードするには、おおよそ4 *…

「宇宙で初めて人間由来の体の一部が3Dプリントされました」
アメリカの航空宇宙会社Redwireは、宇宙で初めて人体の一部を3Dプリントしたと発表しました

「HuggingFaceを使用したLlama 2 7B Fine-TunedモデルのGPTQ量子化」
前の記事では、Meta AIが最近リリースした新しいLlama 2モデルを使用して、わずか数行のコードでPythonコードジェネレータを構築する方法を紹介しました今回は、...と説明します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.