Learn more about Search Results LSTM - Page 8

- You may be interested
- 大規模言語モデルを使用した要約のための...
- PythonにおけるTwitterの感情分析- Sklear...
- 「イデオグラムはテキストから画像への変...
- NVIDIAの研究者が「Retro 48B」を導入:前...
- 「データを素早く可視化するための7つのパ...
- ペンシルバニア大学の研究者が、軽量で柔...
- このAI論文は、自律言語エージェントのた...
- AIをトレーニングするために雇われた人々...
- GPT-4の詳細がリークされました!
- 「最も強力な機械学習モデルの解説(トラ...
- 「InVideoレビュー:2023年11月の最高のAI...
- チャーン予測とチャーンアップリフトを超えて
- 「Ego-Exo4Dを紹介:ビデオ学習とマルチモ...
- 適切なウェブサイト最適化でコンピュータ...
- FastAPIとDockerを使用してPyTorchモデル...

「人工知能による在庫管理の革命:包括的なガイド」
「AIが在庫管理をどのように向上させるかを、業務を効率化したいマネージャーやビジネスオーナー向けに案内するガイドで発見してください」

魅力的な生成型AIの進化
イントロダクション 人工知能の広がり続ける領域において、研究者、技術者、愛好家の想像力を捉えているのは、ジェネラティブAIという魅力的な分野です。これらの巧妙なアルゴリズムは、ロボットが日々できることや理解できる範囲の限界を em>押し広げ、新たな発明と創造性の時代を迎えています。このエッセイでは、ジェネラティブAIの進化の航海に乗り出し、その謙虚な起源、重要な転換点、そしてその進路に影響を与えた画期的な展開について探求します。 ジェネラティブAIが芸術や音楽、医療や金融などさまざまな分野を革新した方法について調べ、単純なパターンを作成しようとする初期の試みから、現在の息をのむような傑作まで進化してきたことを見ていきます。ジェネラティブAIの将来の可能性について深い洞察を得るためには、その誕生につながった歴史的な背景と革新を理解する必要があります。機械が創造、発明、想像力の能力を持つようになった経緯を探求しながら、人工知能と人間の創造性の分野を永遠に変えた過程をご一緒に見ていきましょう。 ジェネラティブAIの進化のタイムライン 人工知能の絶え間なく進化する景色の中で、ジェネラティブAIという分野は、他のどの分野よりも多くの魅力と好奇心を引き起こしました。初期の概念から最近の驚異的な業績まで、ジェネラティブAIの旅は非常に特異なものでした。 このセクションでは、時間をかけて魅力的な旅に乗り出し、ジェネラティブAIの発展を形作ったマイルストーンを解明していきます。我々は、重要なブレイクスルー、研究論文、進歩を探求し、その成長と進化を包括的に描写します。 革新的な概念の誕生、影響力のある人物の出現、ジェネラティブAIの産業への浸透を見ながら、我々と一緒に歴史の旅に出かけ、生活を豊かにし、私たちが知っているAIを革新するジェネラティブAIの誕生を目撃しましょう。 1805年:最初のニューラルネットワーク(NN)/ 線形回帰 1805年、アドリアン=マリー・ルジャンドルは、入力層と単一の出力ユニットを持つ線形ニューラルネットワーク(NN)を導入しました。ネットワークは、重み付け入力の合計として出力を計算します。これは、現代の線形NNの基礎となる最小二乗法を用いた重みの調整を行い、浅い学習とその後の複雑なアーキテクチャの基礎となりました。 1925年:最初のRNNアーキテクチャ 1920年代、物理学者のエルンスト・イージングとヴィルヘルム・レンツによって、最初の非学習RNNアーキテクチャ(イージングまたはレンツ・イージングモデル)が導入され、分析されました。これは、入力条件に応じて平衡状態に収束し、最初の学習RNNの基盤となりました。 1943年:ニューラルネットワークの導入 1943年、ウォーレン・マクカロックとウォルター・ピッツによって、ニューラルネットワークの概念が初めて紹介されました。生物のニューロンの働きがそのインスピレーションとなっています。ニューラルネットワークは、電気回路を用いてモデル化されました。 1958年:MLP(ディープラーニングなし) 1958年、フランク・ローゼンブラットが最初のMLPを導入しました。最初の層は学習しない非学習層であり、重みはランダムに設定され、適応的な出力層がありました。これはまだディープラーニングではありませんでしたが、最後の層のみが学習されるため、ローゼンブラットは正当な帰属なしに後にエクストリームラーニングマシン(ELM)として再ブランドされるものを基本的に持っていました。 1965年:最初のディープラーニング 1965年、アレクセイ・イヴァハネンコとヴァレンティン・ラパによって、複数の隠れ層を持つディープMLPのための最初の成功した学習アルゴリズムが紹介されました。 1967年:SGDによるディープラーニング 1967年、甘利俊一は、スクラッチから確率的勾配降下法(SGD)を用いて複数の層を持つマルチレイヤーパーセプトロン(MLP)を訓練する方法を提案しました。彼らは、高い計算コストにもかかわらず、非線形パターンを分類するために2つの変更可能な層を持つ5層のMLPを訓練しました。 1972年:人工RNNの発表 1972年、阿弥俊一はレンツ・イジング再帰型アーキテクチャを適応的に変更し、接続重みを変えることで入力パターンと出力パターンを関連付ける学習を可能にしました。10年後、阿弥ネットワークはホプフィールドネットワークとして再発表されました。 1979年:ディープコンボリューショナルNN…

「ニューラルネットワークとディープラーニングの基礎の理解」
この記事は、ニューラルネットワークとディープラーニングの基礎について詳細な概要を提供することを目的としています
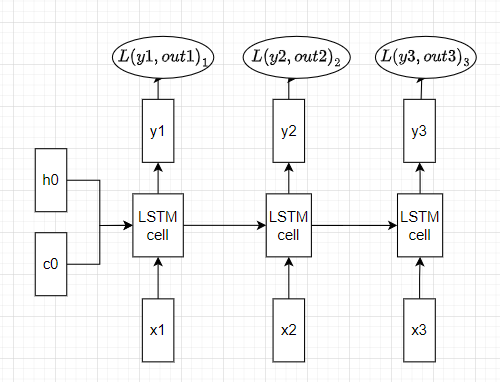
「RNNにおける誤差逆伝播法と勾配消失問題(パート2)」
このシリーズの第1部では、RNNモデルのバックプロパゲーションを解説し、数式と数値を用いてRNNにおける勾配消失問題を説明しましたこの記事では、次のことを行います...

現代の自然言語処理(NLP):詳細な概要パート1:トランスフォーマー
最近の半年間で、私たちはBERTやGPTなどのアイデアの導入により、自然言語処理の領域で大きな成果を見てきましたこの記事では、…について詳しく掘り下げることを目指します

「テキスト要約の革新:GPT-2とXLNetトランスフォーマーの探索」
イントロダクション すべてを読んで理解するためには時間が足りません。そこでテキスト要約が登場します。テキスト要約は、テキスト全体を短くすることで、私たちが理解するのを助けます。詳細をすべて読まずに、必要な情報を得るようなものです。テキスト要約は、さまざまな状況で本当に役立ちます。たとえば、明日試験があるけれどもまだ読み始めていない学生の場合を想像してみてください。試験のために3章を勉強しなければならず、今日しか勉強する時間がありません。心配しないでください。テキスト要約を使ってください。それは明日の試験に合格するのに役立ちます。興味深いですね?この記事では、GPT-2とXLNetトランスフォーマーモデルを使用したテキスト要約について探求します。 学習目標 この記事では、以下のことを学びます。 テキスト要約とその種類について トランスフォーマーモデルの登場とそのアーキテクチャの仕組みについて GPT-2やXLNetなどのトランスフォーマー要約モデルについて 最後に、それぞれの異なるバリアントを使用した実装について この記事は、データサイエンスブログマラソンの一環として公開されました。 テキスト要約とは何ですか? 本のいくつかのページを読まなければならない状況に直面したことはありますか?しかし、怠け者のためにそれができなかったこともありますよね。テキスト要約のおかげで、私たちは本のすべての行やページを実際に読まずに、テキスト全体の要約を理解することができます。 テキスト要約は、重要な情報を保ちながら長いテキストを短く変換することです。まるでテキストの要約を作成するかのようなものです。テキスト要約は、自然言語処理(NLP)の魅力的な分野です。それは元のテキストの主要なアイデアと重要な情報を保持します。簡単に言えば、テキスト要約の目標は、元のテキストの重要なポイントを捉え、実際には読まずにテキストの内容を素早く把握できるようにすることです。 出典: Microsoft 要約の種類 テキスト要約のアプローチには、主に2つのタイプがあります。それらは以下の通りです。 抽出型 抽象型 それぞれ詳しく理解しましょう。 抽出型要約 これは、元のテキストから重要な文を選択し組み合わせて要約を形成することを含みます。このタイプの要約は、最も関連性の高い情報を抽出します。これらの文は、元のテキストの主要なアイデアや文脈を表すものでなければなりません。選択された文は、修正なしで要約を形成します。抽出型要約で使用される一部の標準的な手法には、次のものがあります。 文のスコアリング: これはスコアに基づくアプローチです。システムは、単語の頻度、文の位置、キーワードの重要性に基づいて要約のための文を選択します。スコアが高い文を要約に含めるために、スコアが高い文を選択します。この方法で、すべての高スコアの文が元のテキスト全体の要約となります。 グラフベース:…
「Transformerモデルの実践的な導入 BERT」
ハンズオンチュートリアルでBERTを探索してください:トランスフォーマーを理解し、プレトレーニングとファインチューニングをマスターし、PythonとHugging Faceを使用して感情分析を実行します
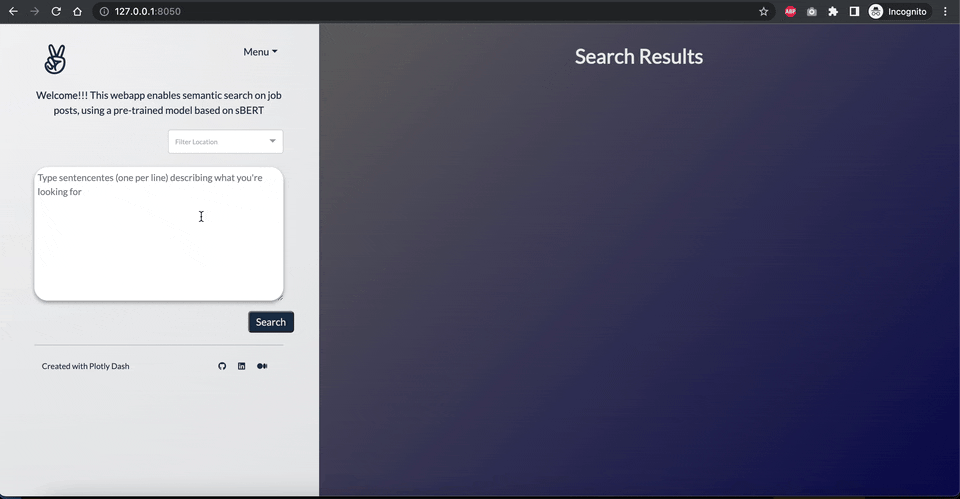
NLP で仕事検索を強化しましょう
最も一般的な求人プラットフォームでは、検索機能はいくつかの入力単語といくつかのフィルタ(場所など)に基づいて求人を絞り込むことで構成されていますこれらの単語は一般的にはドメインや…

ソースコード付きのトップ14のデータマイニングプロジェクト
現代では、データマイニングと機械学習の驚異的な進歩により、組織はデータに基づく意思決定を行うための先進的な技術を備えています。私たちが生きるデジタル時代は、急速な技術の発展によって特徴付けられ、よりデータに基づいた社会の道を切り開いています。ビッグデータと産業革命4.0の登場により、組織は貴重な洞察を抽出し、イノベーションを推進するために利用できる膨大な量のデータにアクセスできるようになりました。本記事では、スキルを磨くことができるトップ10のデータマイニングプロジェクトについて探っていきます。 データマイニングとは? データマイニングは、ユーザーから収集されるデータや企業の業務に重要なデータから隠れたパターンを見つけるプラクティスです。これはいくつかのデータ整形手順に従います。ビジネスは、この膨大な量のデータを収集するクリエイティブな方法を探して、有用な企業データを提供するためのデータマイニングがイノベーションのための最も重要な手法の1つとして浮上しています。データマイニングプロジェクトは、現在の科学のこの領域で働きたい場合には理想的な出発点かもしれません。 トップ14のデータマイニングプロジェクト 以下は、初心者、中級者、上級者向けのトップ14のデータマイニングプロジェクトです。 住宅価格予測 ナイーブベイズを用いたスマートヘルス疾患予測 オンラインフェイクロゴ検出システム 色検出 製品と価格の比較ツール 手書き数字認識 アニメ推奨システム キノコ分類プロジェクト グローバルテロリズムデータの評価と分析 画像キャプション生成プロジェクト 映画推奨システム 乳がん検出 太陽光発電予測 国勢調査データに基づく成人の収入予測 初心者向けデータマイニングプロジェクト 1. 住宅価格予測 このデータマイニングプロジェクトは、住宅データセットを利用して物件価格を予測することに焦点を当てています。初心者や中級レベルのデータマイナーに適しており、サイズ、場所、設備などの要素を考慮して家の販売価格を正確に予測するモデルを開発することを目指しています。 決定木や線形回帰などの回帰技術を利用して結果を得ます。このプロジェクトでは、様々なデータマイニングアルゴリズムを利用して物件価値を予測し、最も高い精度評価を持つ予測を選択します。過去のデータを活用することで、このプロジェクトは不動産業界内での物件価格の予測に関する洞察を提供します。…

「Microsoft Azureの新しいディープラーニングと自然言語処理のチュートリアルを発表します」
ODSCでは、Deep LearningとNLPに関するMicrosoft Azureのチュートリアルシリーズを発表できることを非常に喜んでいますこのコースシリーズは、Microsoftコミュニティの専門家チームによって作成され、彼らのAIとディープラーニングに関する知識と経験を活かしていますAi+で無料で利用できます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.