Learn more about Search Results 限定的 - Page 8

- You may be interested
- 「ターシャーに会ってください:GPT4のよ...
- 「LLMガイド、パート1:BERT」 LLMガイド...
- 「dbtモデルのユニットテストを実装するた...
- このAI研究では、全身ポーズ推定のための...
- 「SMARTは、AI、自動化、そして働き方の未...
- 「オープンソースツールを使用して、プロ...
- ChatGPTのバイアスを解消するバックパック...
- ルーターLangchain:Langchainを使用して...
- 「GPS ガウシアンと出会う:リアルタイム...
- 「超伝導デバイスは、コンピューティング...
- 変形者への鎮魂曲?
- LMSYS-Chat-1Mとは、25の最新のLLM(Large...
- Pythonを使用したビデオ内の深さに配慮し...
- プロンプトの旅:プロンプトエンジニアリ...
- 「プログラマーの生産性を10倍にするため...

「ステレオタイプやディスインフォメーションに対抗するAIヘイトスピーチ検出」
AIがどのようにヘイトスピーチやステレオタイプと戦い、AIベースの対話とヘイトスピーチ検出技術を使って安全なオンラインコミュニティを育成しているかを学びましょう
「AI規制に反対する理論は無意味である」
2022年末にOpenAIがChatGPTを広く公開して以来、世界は生成型人工知能とそれが創り出す未来についての話で持ちきりです資本主義の熱狂的な支持者たちは、...
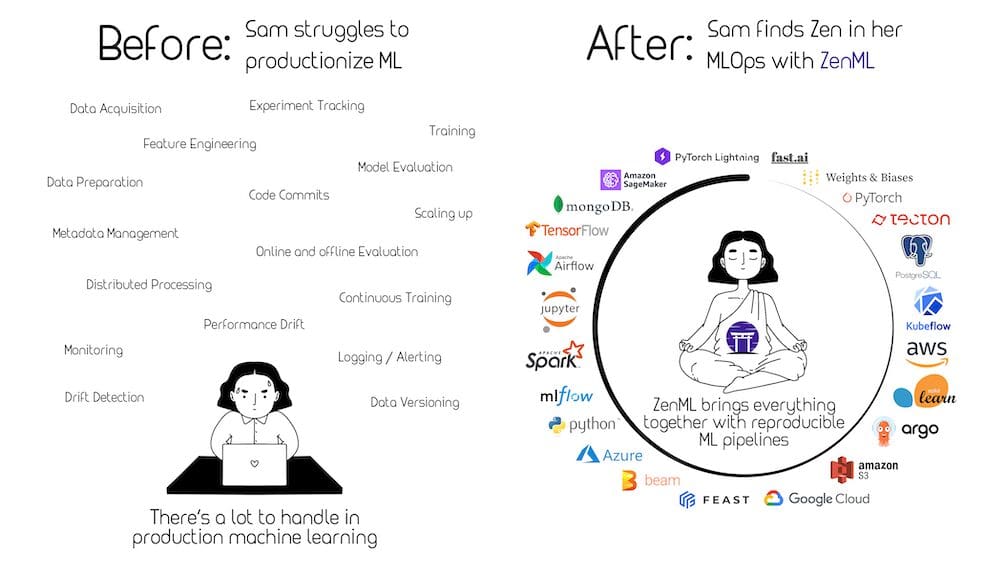
「MLOpsに関する包括的なガイド」
「Machine Learning Operations(MLOps)は、機械学習(ML)モデルが本番環境で繁栄するために必要な構造とサポートを提供する比較的新しい学問分野です」

「企業がデータにアプローチする方法を変えるジェネラティブAIの5つの方法(そして変えない方法)」
生成AIは新しい概念ではありません数十年にわたって研究され、限られた範囲で応用されてきましたそれは、2022年後半にChatGPTが私たちの集合意識を衝撃と驚愕させるまでのことですそれでも…
数値計算のための二分法の使用方法
コンピュータ科学と数学のサブフィールドである数値計算は、コンピュータを用いた数値計算手法とアルゴリズムを用いて数学の問題を解決することに焦点を当てていますこれは…
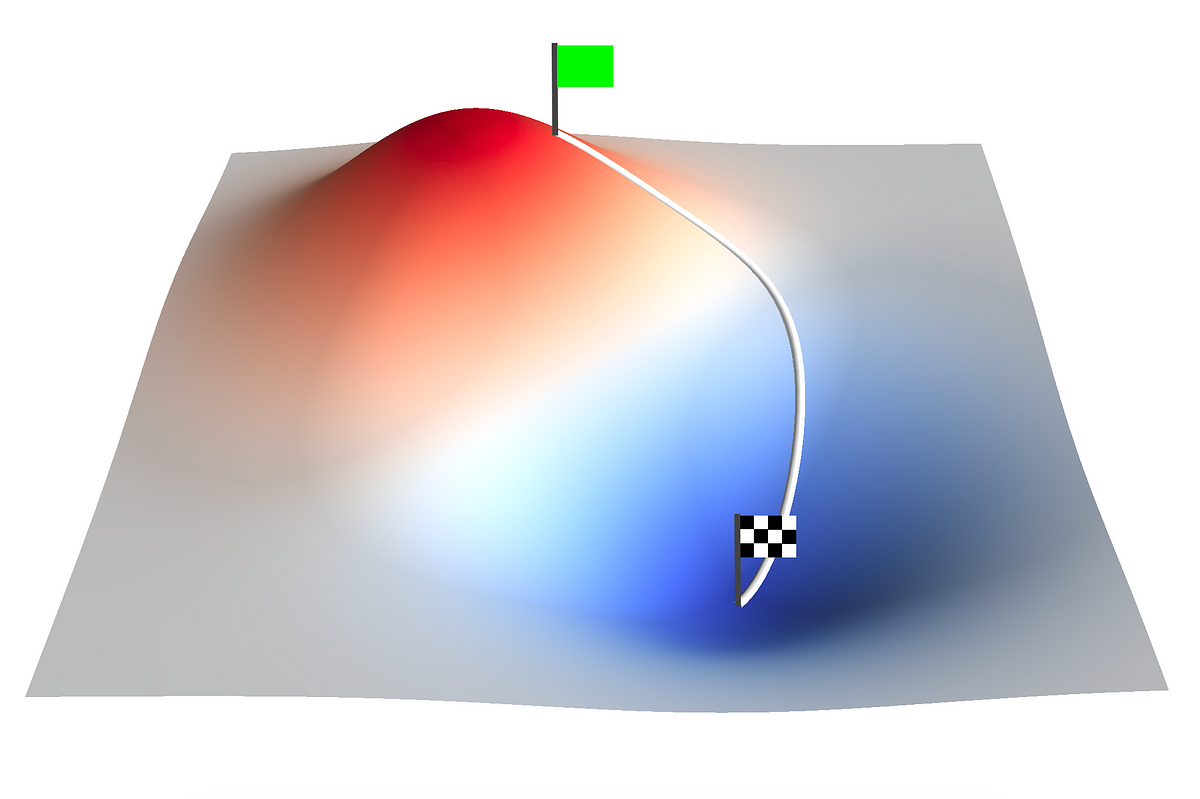
PIDコントローラの最適化:勾配降下法のアプローチ
「機械学習ディープラーニングAIこれらの技術を日々利用する人々がますます増えていますこれは、ChatGPTやBardなどによって展開された大規模言語モデルの台頭によって大いに推進されています...」

「ジェネレーティブAIの企業導入」
「こんにちは、私はマイケルです2018年からエンタープライズAIの導入に没頭しており、私たちはAi4というAIカンファレンスを開始しました数年間に渡り、私たちの年次カンファレンスは300人規模のイベントから...」

「会話型AIのLLM:よりスマートなチャットボットとアシスタントの構築」
イントロダクション 言語モデルは、技術と人間が自然な会話を行う魅力的なConversational AIの世界で中心的な役割を果たしています。最近、Large Language Models(LLMs)という注目すべきブレークスルーがありました。OpenAIの印象的なGPT-3のように、LLMsは人間のようなテキストを理解し生成するという非凡な能力を示しています。これらの素晴らしいモデルは、特によりスマートなチャットボットやバーチャルアシスタントの作成において、ゲームチェンジャーとなりました。 このブログでは、LLMsがConversational AIにどのように貢献しているかを探求し、その潜在能力を示すための理解しやすいコード例を提供します。さあ、LLMsが仮想的なインタラクションをより魅力的で直感的にする方法を見てみましょう。 学習目標 Large Language Models(LLMs)の概念と、Conversational AIの能力向上における重要性を理解する。 LLMsがチャットボットやバーチャルアシスタントが人間のようなテキストを理解し生成することを可能にする方法を学ぶ。 プロンプトエンジニアリングの役割を探求し、LLMベースのチャットボットの動作をガイドする。 伝統的な方法に比べてLLMsの優位性を認識し、チャットボットの応答を改善する。 LLMsを活用したConversational AIの実用的な応用を発見する。 この記事はData Science Blogathonの一部として公開されました。 Conversational AIの理解 Conversational AIは、人工知能の革新的な分野であり、自然で人間らしい方法で人間の言語を理解し応答する技術の開発に焦点を当てています。自然言語処理や機械学習などの高度な技術を使用して、Conversational…

学習率のチューニングにうんざりしていますか?DoGに会ってみてください:堅牢な理論的保証に裏打ちされたシンプルでパラメータフリーの最適化手法
テルアビブ大学の研究者は、学習率パラメータを必要とせず、経験的な量のみに依存する調整フリーの動的SGDステップサイズ公式である「Distance over Gradients(DoG)」を提案しています。彼らは理論的に、DoG公式のわずかな変動が局所的にバウンドした確率的勾配の収束をもたらすことを示しています。 確率的プロセスには最適化されたパラメータが必要であり、学習率は依然として困難です。従来の成功した手法には、先行研究から適切な学習率を選択する方法が含まれます。適応的勾配法のような手法では、学習率パラメータを調整する必要があります。パラメータフリーの最適化では、問題の事前知識なしにほぼ最適な収束率を達成するためにアルゴリズムが設計されています。 テルアビブ大学の研究者は、CarmonとHinderの重要な知見を取り入れ、パラメータフリーのステップサイズスケジュールを開発しました。彼らはDoGを反復することで、DoGが対数的な収束率を達成する確率が高いことを示しています。ただし、DoGは常に安定しているわけではありません。その反復は最適化から遠ざかることもあります。そこで、彼らはDoGの変種である「T-DoG」を使用し、ステップサイズを対数的な因子で小さくします。これにより、収束が保証される高い確率を得ます。 彼らの結果は、SGDと比較して、コサインステップサイズスケジュールとチューニングベースの学習を使用する場合、DoGは稀に相対誤差の改善率が5%を超えることはほとんどありませんが、凸問題の場合、誤差の相対差は1%以下であり、驚くべきことです。彼らの理論はまた、DoGが感度の広範な範囲で一貫して実行されることを予測しています。研究者はまた、近代的な自然言語理解(NLU)におけるDoGの効率をテストするために、調整されたトランスフォーマーランゲージモデルを使用しました。 研究者はまた、下流タスクとしてImageNetを使用した主なファインチューニングテストベッドで限定的な実験を行いました。これらはスケールが大きくなるにつれてチューニングがよりコストがかかります。彼らはCLIPモデルをファインチューニングし、それをDoGとL-DoGと比較しました。両方のアルゴリズムは著しく悪い結果を示しました。これは反復予算が不十分なためです。 研究者は、多項式平均化を使用してモデルをゼロからトレーニングする実験も行いました。DoGは、適応勾配法と比較して、運動量0.9と学習率0.1の条件で優れたパフォーマンスを発揮します。他のチューニングフリーメソッドと比較して、DoGとL-DoGはほとんどのタスクでより優れたパフォーマンスを提供します。 DoGの結果は有望ですが、これらのアルゴリズムにはさらなる追加作業が必要です。運動量、事前パラメータ学習率、学習率のアニーリングなど、確立された技術をDoGと組み合わせる必要があります。これは理論的にも実験的にも困難です。彼らの実験は、バッチ正規化との関連性を示唆しており、頑健なトレーニング方法にもつながる可能性があります。 最後に、彼らの理論と実験は、DoGが現在の学習率チューニングに費やされている膨大な計算を、ほぼパフォーマンスにコストをかけずに節約する可能性を示唆しています。

AI ポリシー @🤗 EU AI Act におけるオープンな機械学習の考慮事項
機械学習の皆様と同様に、Hugging FaceでもEU AI Actに注目しています。これは画期的な法律であり、民主的な要素がAI技術開発との相互作用をどのように形成するかを世界中に広めるものです。また、社会のさまざまな要素を代表する組織との広範な協議と作業の結果でもあります。私たちはコミュニティ主導の企業として、このプロセスに特に敏感に取り組んでいます。このポジションペーパーでは、Creative Commons、Eleuther AI、GitHub、LAION、Open Futureとの連携により、オープンなML開発の必要性が法律の目標をサポートする方法についての私たちの経験を共有し、逆に、規制がオープンでモジュラーで協力的なML開発のニーズをより適切に考慮するための具体的な方法を示すことを目指しています。 Hugging Faceは、開発者コミュニティのおかげで今日の地位にあります。そのため、オープンな開発がもたらす効果を直接目にしてきました。より堅牢なイノベーションをサポートし、より多様でコンテキストに応じたユースケースを可能にする場所です。開発者は革新的な新しい技術を簡単に共有し、自分のニーズに合わせてMLコンポーネントを組み合わせ、スタック全体について完全な可視性を持って信頼性のある作業ができます。また、技術の透明性がより責任ある取り組みと包括性をサポートする上での必要な役割にも痛感しており、MLアーティファクトの文書化とアクセシビリティの改善、教育活動、大規模な多学科のコラボレーションのホスティングなどを通じてこれを促進してきました。そのため、EU AI Actが最終段階に向かうにつれて、MLシステムのオープンかつオープンソースな開発の特定のニーズと強みを考慮することが、その長期的な目標をサポートする上で重要になると考えています。共同署名したパートナー組織と共に、以下の5つの推奨事項を提案します: AIコンポーネントを明確に定義すること オープンソースのAIコンポーネントの共同開発とパブリックリポジトリでの公開は、開発者をAI Actの要件の対象としないことを明確にすること(パーラメントの文章のRecitals 12a-cとArticle 2(5e)を基に改善すること) AIオフィスの調整と包括的なガバナンスをオープンソースエコシステムと連携させること(パーラメントの文章を基に改善すること) 研究開発の例外が実用的かつ効果的であることを確保すること。現実世界の条件での限定的なテストを許可し、理事会の取り組みの一部とパーラメントのArticle 2(5d)の改訂版を組み合わせること 「基礎モデル」に対して比例の要件を設定すること。異なる使用方法と開発モダリティを明確に区別し、オープンソースアプローチを含めること。パーラメントのArticle 28bを適用すること これらについての詳細と文脈は、こちらの全文をご覧ください!
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.