Learn more about Search Results 勾配降下法 - Page 8

- You may be interested
- 『EMQX MQTT Brokerクラスタリングの基礎...
- 「最適化によるAIトレーニングにおける二...
- 「個人データへのアクセス」
- スタンフォード大学とDeepMindの研究者が...
- 「GROOTに会おう:オブジェクト中心の3D先...
- CO2排出量と🤗ハブ:リーディング・ザ・チ...
- 「このGSAi中国のAI論文は、LLMベースの自...
- 「F1スコア:視覚的ガイド – そして...
- 「SuperDuperDBを活用して簡単にシンプル...
- ルノー主導のコンセプトカーがサイバー攻...
- Gradio 3.0 がリリースされました!
- 検索で創発的AIにインスピレーションを受...
- 『今日、企業が実装できる5つのジェネレ...
- Hugging FaceとGraphcoreがIPU最適化され...
- 大規模な言語モデルによるレッドチーミング
データの壁を破る:ゼロショット、ワンショット、およびフューショットラーニングが機械学習を変革している
「ゼロショット、ワンショット、そしてフューショット学習の概念を発見しましょうこれらは、機械学習モデルが限られた数の例を用いてオブジェクトやパターンを分類・認識することを可能にします」

SEER:セルフスーパーバイズドコンピュータビジョンモデルの突破口?
過去10年間、人工知能(AI)と機械学習(ML)は著しい進歩を遂げてきました現在では、これまで以上に正確で効率的で、かつ能力が高まっています最新のAIとMLモデルは、画像やビデオファイル内のオブジェクトをシームレスに正確に認識することができますさらに、人間の知性に匹敵するテキストや音声を生成することも可能です[…]

DeepMindの研究者たちは、正確な数学的定義を用いて、連続した強化学習を再定義しました
深層強化学習(RL)の最近の進展により、人工知能(AI)エージェントがさまざまな印象的なタスクで超人的なパフォーマンスを発揮しています。これらの結果を達成するための現在のアプローチは、主に興味のある狭いタスクをマスターする方法を学習するエージェントを開発することに従っています。未訓練のエージェントはこれらのタスクを頻繁に実行する必要があり、単純なRLモデルでも新しいバリエーションに一般化する保証はありません。それに対して、人間は生涯を通じて知識を獲得し、新しいシナリオに適応するために一般化します。これを連続的な強化学習(CRL)と呼びます。 RLにおける学習の視点は、エージェントがマルコフ環境と対話して最適な行動を効率的に特定することです。最適な行動の探索は学習の一点で停止します。たとえば、よく定義されたゲームをプレイしていると想像してください。ゲームをマスターしたら、タスクは完了し、新しいゲームシナリオについて学習することはありません。学習を解決策の発見ではなく、終わりのない適応として見る必要があります。 連続的な強化学習(CRL)はそのような研究を含みます。これは監督された終わりのない継続的な学習です。DeepMindの研究者は、エージェントを2つのステップで明示的に理解します。1つは、すべてのエージェントを行動の集合上で暗黙的に検索していると理解し、もう1つはすべてのエージェントが検索を続けるか、最終的に行動の選択肢で停止するという考え方です。研究者は、エージェントに関連する2つの生成子を生成到達演算子として定義します。この形式主義を使用して、彼らはCRLをすべてのエージェントが検索を停止しないRL問題として定義します。 ニューラルネットワークの構築には、要素の重みの任意の割り当てと、基盤のアクティブな要素の更新のための学習メカニズムが必要です。研究者は、CRLではネットワークのパラメータ数は構築できるものに制約され、学習メカニズムは基盤の無制約な検索方法ではなく確率的勾配降下法と考えることができます。ここで、基盤は任意ではありません。 研究者は、振る舞いの表現として機能する関数のクラスを選択し、経験に応じて望ましい方法で反応するための特定の学習ルールを利用します。関数のクラスの選択は、利用可能なリソースやメモリに依存します。確率的勾配降下法は、現在の基盤の選択肢を更新してパフォーマンスを向上させます。基盤の選択は任意ではありませんが、これにはエージェントの設計および環境によって課せられる制約も含まれます。 研究者は、学習ルールのさらなる研究が新しい学習アルゴリズムの設計を直接変更することができると主張しています。継続的な学習ルールの特徴付けにより、継続的な学習エージェントの収穫が保証され、基本的な継続的な学習エージェントの設計をガイドするためにさらに利用できます。彼らはまた、可塑性損失、インコンテキスト学習、および壊滅的な忘却などのさらなる手法の調査を意図しています。

「ICML 2023でのGoogle」
Cat Armatoさんによる投稿、Googleのプログラムマネージャー Googleは、言語、音楽、視覚処理、アルゴリズム開発などの領域で、機械学習(ML)の研究に積極的に取り組んでいます。私たちはMLシステムを構築し、言語、音楽、視覚処理、アルゴリズム開発など、さまざまな分野の深い科学的および技術的な課題を解決しています。私たちは、ツールやデータセットのオープンソース化、研究成果の公開、学会への積極的な参加を通じて、より協力的なエコシステムを広範なML研究コミュニティと構築することを目指しています。 Googleは、40回目の国際機械学習会議(ICML 2023)のダイヤモンドスポンサーとして誇りに思っています。この年次の一流学会は、この週にハワイのホノルルで開催されています。ML研究のリーダーであるGoogleは、今年の学会で120以上の採択論文を持ち、ワークショップやチュートリアルに積極的に参加しています。Googleは、LatinX in AIとWomen in Machine Learningの両ワークショップのプラチナスポンサーでもあることを誇りに思っています。私たちは、広範なML研究コミュニティとのパートナーシップを拡大し、私たちの幅広いML研究の一部を共有することを楽しみにしています。 ICML 2023に登録しましたか? 私たちは、Googleブースを訪れて、この分野で最も興味深い課題の一部を解決するために行われるエキサイティングな取り組み、創造性、楽しさについてさらに詳しく知ることを願っています。 GoogleAIのTwitterアカウントを訪れて、Googleブースの活動(デモやQ&Aセッションなど)について詳しく知ることができます。Google DeepMindのブログでは、ICML 2023での技術的な活動について学ぶことができます。 以下をご覧いただき、ICML 2023で発表されるGoogleの研究についてさらに詳しくお知りください(Googleの関連性は太字で表示されます)。 理事会および組織委員会 理事会メンバーには、Corinna Cortes、Hugo Larochelleが含まれます。チュートリアルの議長には、Hanie Sedghiが含まれます。 Google…

変分オートエンコーダーの概要
はじめに 変分オートエンコーダ(VAE)は、特定のデータセットの基になる確率分布を捉え、新たなサンプルを生成するために明示的に設計された生成モデルです。VAEはエンコーダ-デコーダ構造を持つアーキテクチャを使用します。エンコーダは入力データを潜在形式に変換し、デコーダはこの潜在表現に基づいて元のデータを再構成することを目指します。VAEは元のデータと再構成データの相違を最小化するようにプログラムされており、基になるデータ分布を理解し、同じ分布に従う新たなサンプルを生成することができます。 VAEの注目すべき利点の一つは、トレーニングデータに似た新しいデータサンプルを生成する能力です。VAEの潜在空間は連続的であるため、デコーダはトレーニングデータポイントの間を滑らかに補完する新しいデータ点を生成することができます。VAEは密度推定やテキスト生成など、さまざまなドメインで応用されています。 この記事はData Science Blogathonの一環として公開されました。 変分オートエンコーダのアーキテクチャ VAEは通常、エンコーダ接続とデコーダ接続の2つの主要なコンポーネントから構成されています。エンコーダネットワークは入力データを低次元の「秘密のコード」と呼ばれる空間に変換します。 エンコーダネットワークの実装には、完全に接続されたネットワークや畳み込みニューラルネットワークなど、さまざまなニューラルネットワークのトポロジーが検討されることがあります。選択するアーキテクチャはデータの特性に基づいています。エンコーダネットワークは、サンプリングと潜在コードの生成に必要なガウス分布の平均値や分散などの重要なパラメータを生成します。 同様に、研究者はさまざまなタイプのニューラルネットワークを使用してデコーダネットワークを構築し、その目的は提供された潜在コードから元のデータを再構成することです。 VAEのアーキテクチャの例:fen VAEは、入力データを潜在コードにマッピングするエンコーダネットワークと、潜在コードを再構成データに戻す逆操作を行うデコーダネットワークから構成されています。このトレーニングプロセスを経て、VAEはデータの基本的な特性を捉えた最適化された潜在表現を学習し、正確な再構成を可能にします。 正則化に関する直感 アーキテクチャの側面に加えて、研究者は潜在コードに正則化を適用し、VAEの重要な要素にします。この正則化により、トレーニングデータを単に記憶するのではなく、潜在コードのスムーズな分布を促進し、過学習を防ぎます。 正則化は、トレーニングデータポイント間を滑らかに補完する新しいデータサンプルの生成に役立つだけでなく、トレーニングデータに似た新しいデータを生成するVAEの能力にも貢献します。さらに、この正則化はデコーダネットワークが入力データを完璧に再構成することを防ぎ、多様なデータサンプルを生成するためのより一般的なデータ表現の学習を促進します。 数学的には、VAEでは正則化を損失関数にクロスエントロピー項を組み込むことで表現します。エンコーダネットワークは、ガウス分布のパラメータ(平均や対数分散など)を生成し、潜在コードのサンプリングに使用します。VAEの損失関数には、学習された潜在変数の分布と事前分布(正規分布)のKLダイバージェンスの計算が含まれます。研究者はKLダイバージェンス項を組み込んで、潜在変数が事前分布に類似した分布を持つように促します。 KLダイバージェンスの式は次の通りです: KL(q(z∣x)∣∣p(z)) = E[log q(z∣x) − log p(z)]…

「完璧な機械学習アルゴリズムを選ぶための秘訣を解き放て!」
「データサイエンスの問題に取り組む際、最も重要な選択の一つは適切な機械学習アルゴリズムを選ぶことです」

この人工知能論文は、画像認識における差分プライバシーの高度な手法を提案し、より高い精度をもたらします
機械学習は、近年のパフォーマンスにより、さまざまな領域で大幅に増加しました。現代のコンピュータの計算能力とグラフィックスカードのおかげで、ディープラーニングによって、専門家が与える結果を上回ることもあります。しかし、医療や金融などの機密性の高い領域での使用は、機械学習モデルへのアクセス権を持つ攻撃者が特定のトレーニングポイントのデータを取得することを禁止する形式的なプライバシーガラントである差分プライバシー(DP)による機密性の問題を引き起こします。画像認識における差分プライバシーの最も一般的なトレーニングアプローチは、差分プライベート確率的勾配降下法(DPSGD)ですが、現在のDPSGDシステムによって引き起こされるパフォーマンスの低下により、差分プライバシーの展開は制限されています。 差分プライバシーを持つディープラーニングの既存の方法は、目的関数の値が改善されない場合でも、すべてのモデルの更新を許可するため、さらなる改善が必要です。いくつかのモデルの更新では、勾配にノイズを追加することが目的関数の値を悪化させることがありますが、特に収束が迫っている場合には、その影響により結果としてモデルが悪化します。最適化の対象が劣化し、プライバシー予算が無駄になります。この問題に対処するため、中国の上海大学の研究チームは、候補更新がアップデートの品質とイテレーションの数に依存する確率で受け入れられるシミュレーテッドアニーリングベースの差分プライバシーアプローチ(SA-DPSGD)を提案しています。 具体的には、モデルの更新が目的関数の値を改善する場合は受け入れられます。それ以外の場合、更新は一定の確率で拒否されます。局所的な最適解に収束するのを防ぐために、著者らは確定的な拒否ではなく確率的な拒否を使用し、連続した拒否の数を制限することを提案しています。そのため、シミュレーテッドアニーリングアルゴリズムは、確率的勾配降下法のプロセス中に確率でモデルの更新を選択するために使用されます。 以下に、提案されたアプローチの高レベルな説明を示します。 1- DPSGDはイテレーションごとにアップデートを生成し、その後、目的関数の値が計算されます。前回のイテレーションから現在のイテレーションへのエネルギーシフトと承認されたソリューションの総数を使用して、現在のソリューションの受け入れ確率を計算します。 2- エネルギー変化が負の場合、受け入れ確率は常に1のままです。つまり、正しい方向に進むアップデートは受け入れられます。ただし、モデルのアップデートがノイズを含んでいる場合でも、トレーニングが収束する方向に主に移動することが保証されます。実際のエネルギーは非常に小さい確率で正になる可能性もあります。 3- エネルギー変化が正の場合、受け入れ確率は承認されたソリューションの数が増えるにつれて指数関数的に減少します。この状況では、ソリューションを受け入れるとエネルギーが悪化します。ただし、決定的な拒否は最終的なソリューションが局所的な最適解になる可能性があります。したがって、著者らは、確率的な拒否を使用してエネルギー変化が正のアップデートを小さく、減少する確率で受け入れることを提案しました。 4- 連続した拒否が多すぎる場合、アップデートはまだ許可されます。連続した拒否の数が制限されているため、受け入れ確率は非常に低くなり、収束に近づくにつれて正のエネルギー変化を持つほとんどのソリューションを拒否する可能性があり、局所的な最大値に達する可能性さえあります。拒否の数を制限することで、必要な場合にはソリューションを受け入れることでこの問題を防止します。 提案手法の性能を評価するために、SA-DPSGDは3つのデータセット、MNIST、FashionMNIST、およびCIFAR10で評価されます。実験の結果、SA-DPSGDは、プライバシーコストまたはテスト精度の観点で、最先端の手法DPSGD、DPSGD(tanh)、およびDPSGD(AUTO-S)を大幅に上回ることが示されました。 著者によれば、SA-DPSGDは、プライベートおよび非プライベートの画像の分類精度のギャップを大幅に埋めることができます。ランダムなアップデートスクリーニングを使用することで、差分プライベート勾配降下法は各イテレーションで正しい方向に進み、得られる結果がより正確になります。同じハイパーパラメータでの実験では、SA-DPSGDはMNIST、FashionMNIST、CI-FAR10のデータセットで高い精度を達成し、最先端の結果と比較しても高い精度を実現します。自由に調整可能なハイパーパラメータの場合、提案手法はさらに高い精度を達成します。
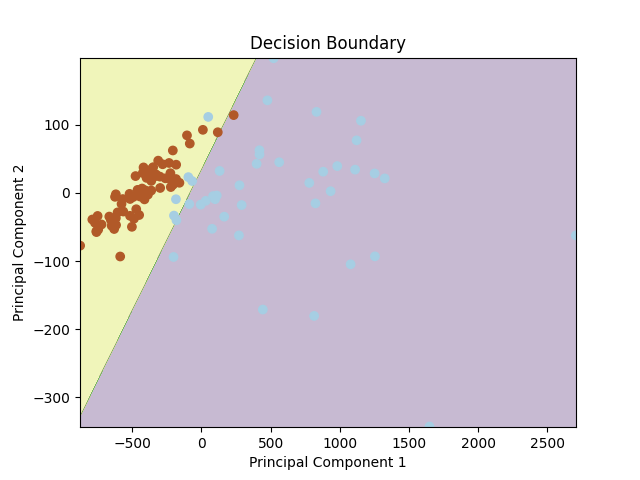
「ロジスティック回帰:直感と実装」
ロジスティック回帰は、2つの異なるデータ属性の間の決定境界を学習できる基本的な二値分類アルゴリズムですこの記事では、理論的な理解を深めるために、...

魅力的な生成型AIの進化
イントロダクション 人工知能の広がり続ける領域において、研究者、技術者、愛好家の想像力を捉えているのは、ジェネラティブAIという魅力的な分野です。これらの巧妙なアルゴリズムは、ロボットが日々できることや理解できる範囲の限界を em>押し広げ、新たな発明と創造性の時代を迎えています。このエッセイでは、ジェネラティブAIの進化の航海に乗り出し、その謙虚な起源、重要な転換点、そしてその進路に影響を与えた画期的な展開について探求します。 ジェネラティブAIが芸術や音楽、医療や金融などさまざまな分野を革新した方法について調べ、単純なパターンを作成しようとする初期の試みから、現在の息をのむような傑作まで進化してきたことを見ていきます。ジェネラティブAIの将来の可能性について深い洞察を得るためには、その誕生につながった歴史的な背景と革新を理解する必要があります。機械が創造、発明、想像力の能力を持つようになった経緯を探求しながら、人工知能と人間の創造性の分野を永遠に変えた過程をご一緒に見ていきましょう。 ジェネラティブAIの進化のタイムライン 人工知能の絶え間なく進化する景色の中で、ジェネラティブAIという分野は、他のどの分野よりも多くの魅力と好奇心を引き起こしました。初期の概念から最近の驚異的な業績まで、ジェネラティブAIの旅は非常に特異なものでした。 このセクションでは、時間をかけて魅力的な旅に乗り出し、ジェネラティブAIの発展を形作ったマイルストーンを解明していきます。我々は、重要なブレイクスルー、研究論文、進歩を探求し、その成長と進化を包括的に描写します。 革新的な概念の誕生、影響力のある人物の出現、ジェネラティブAIの産業への浸透を見ながら、我々と一緒に歴史の旅に出かけ、生活を豊かにし、私たちが知っているAIを革新するジェネラティブAIの誕生を目撃しましょう。 1805年:最初のニューラルネットワーク(NN)/ 線形回帰 1805年、アドリアン=マリー・ルジャンドルは、入力層と単一の出力ユニットを持つ線形ニューラルネットワーク(NN)を導入しました。ネットワークは、重み付け入力の合計として出力を計算します。これは、現代の線形NNの基礎となる最小二乗法を用いた重みの調整を行い、浅い学習とその後の複雑なアーキテクチャの基礎となりました。 1925年:最初のRNNアーキテクチャ 1920年代、物理学者のエルンスト・イージングとヴィルヘルム・レンツによって、最初の非学習RNNアーキテクチャ(イージングまたはレンツ・イージングモデル)が導入され、分析されました。これは、入力条件に応じて平衡状態に収束し、最初の学習RNNの基盤となりました。 1943年:ニューラルネットワークの導入 1943年、ウォーレン・マクカロックとウォルター・ピッツによって、ニューラルネットワークの概念が初めて紹介されました。生物のニューロンの働きがそのインスピレーションとなっています。ニューラルネットワークは、電気回路を用いてモデル化されました。 1958年:MLP(ディープラーニングなし) 1958年、フランク・ローゼンブラットが最初のMLPを導入しました。最初の層は学習しない非学習層であり、重みはランダムに設定され、適応的な出力層がありました。これはまだディープラーニングではありませんでしたが、最後の層のみが学習されるため、ローゼンブラットは正当な帰属なしに後にエクストリームラーニングマシン(ELM)として再ブランドされるものを基本的に持っていました。 1965年:最初のディープラーニング 1965年、アレクセイ・イヴァハネンコとヴァレンティン・ラパによって、複数の隠れ層を持つディープMLPのための最初の成功した学習アルゴリズムが紹介されました。 1967年:SGDによるディープラーニング 1967年、甘利俊一は、スクラッチから確率的勾配降下法(SGD)を用いて複数の層を持つマルチレイヤーパーセプトロン(MLP)を訓練する方法を提案しました。彼らは、高い計算コストにもかかわらず、非線形パターンを分類するために2つの変更可能な層を持つ5層のMLPを訓練しました。 1972年:人工RNNの発表 1972年、阿弥俊一はレンツ・イジング再帰型アーキテクチャを適応的に変更し、接続重みを変えることで入力パターンと出力パターンを関連付ける学習を可能にしました。10年後、阿弥ネットワークはホプフィールドネットワークとして再発表されました。 1979年:ディープコンボリューショナルNN…

「ニューラルネットワークとディープラーニングの基礎の理解」
この記事は、ニューラルネットワークとディープラーニングの基礎について詳細な概要を提供することを目的としています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.