Learn more about Search Results リーダーボード - Page 8

- You may be interested
- 「LLMアプリを作成するための5つのツール」
- 「Amazon SageMaker Pipelines、GitHub、...
- 弁護士には、ChatGPTを使用したことについ...
- オートジェン(AutoGen)は驚くべきもので...
- トレンディングAI GitHubリポジトリ:2023...
- 「AIおよびARはデータ需要を推進しており...
- J-WAFS創設大会は、改良された作物品種を...
- AIが宇宙へ!NASAがChatGPTのようなチャッ...
- 「埋め込みモデルでコーパス内の意味関係...
- 「5つのステップでPyTorchを始めましょう」
- Hugging Face TransformersとAWS Inferent...
- MLモデルのトレーニングパイプラインの構...
- 「30+ AI ツールスタートアップのための(...
- 「対話型知能の創造 機械学習が個別化され...
- 「Amazon Personalizeと生成AIでマーケテ...
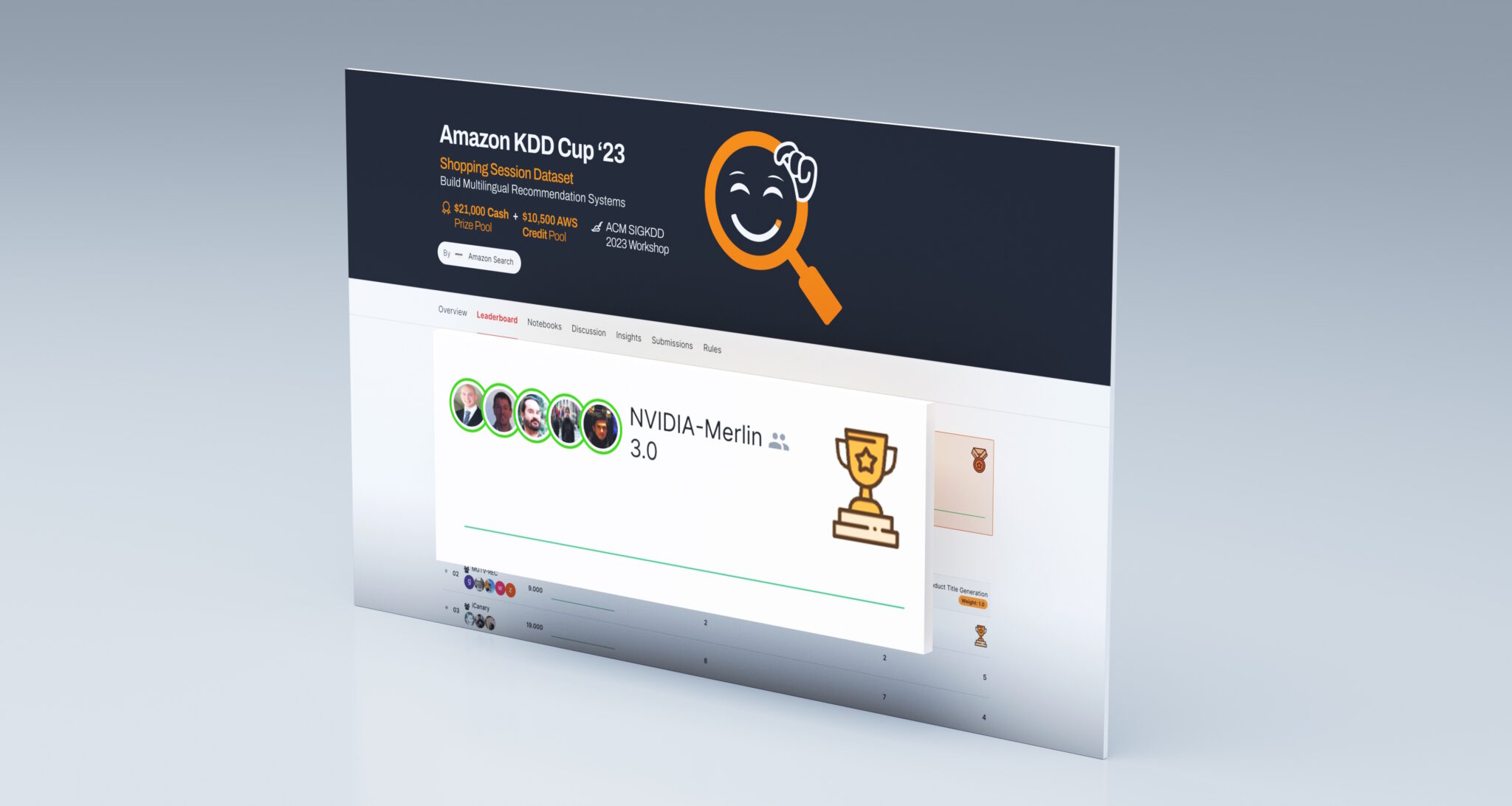
「スコア!チームNVIDIAが推薦システムでトロフィーを獲得」
4つの大陸に広がる5人の機械学習のエキスパートで構成されるクラックチームが、最先端の推薦システムを構築するための激しい競争で、全ての3つのタスクに勝利しました。 その結果は、このデジタル経済のエンジンにおいて、NVIDIAのAIプラットフォームを実世界の課題に効果的に適用するグループの知識を反映しています。推薦システムは、毎日数十億人に対して兆個の検索結果、広告、製品、音楽、ニュースストーリーを提供しています。 Amazon KDD Cup ’23では、450以上のデータサイエンティストチームが競い合いました。この3ヶ月間のチャレンジには多くの曲折と緊迫したフィニッシュがありました。 高速ギアへの切り替え 競争の最初の10週間では、チームはリードを築きました。しかし、最終フェーズでは、主催者が新しいテストデータセットに切り替え、他のチームが追い上げました。 NVIDIANsは夜間や週末にも働き、追いつくために最高のギアに切り替えました。彼らはベルリンから東京までの都市に住むチームメンバーからの24時間対応のSlackメッセージの軌跡を残しました。 サンディエゴのチームメンバーであるクリス・デオットは、「私たちは絶えず働いていました。とてもエキサイティングでした」と語りました。 別の名前の製品 3つ目のタスクは最も難しかったです。 参加者は、ユーザーのブラウジングセッションのデータに基づいて、ユーザーがどの製品を購入するかを予測しなければなりませんでした。しかし、トレーニングデータには多くの選択肢のブランド名が含まれていませんでした。 「最初から、これは非常に非常に困難なテストになると分かっていました」と、ギルベルト・”ギバ”・ティテリックスは述べました。 KGMONの救出 ブラジルのクリチバを拠点とするティテリックスは、Kaggleコンペティションのグランドマスターにランクされる4人のチームメンバーの一人で、データサイエンスのオンラインオリンピックであるKaggleのチャンピオンです。彼らは何十ものコンペティションに勝利した機械学習のニンジャのチームの一部です。NVIDIAの創設者兼CEOであるジェンセン・ファンは、彼らをKGMON(Kaggle Grandmasters of NVIDIA)と呼んでいます。 ティテリックスは、大量の言語モデル(LLM)を使用して生成型AIを構築し、製品名を予測しようとしましたが、どれもうまくいきませんでした。 チームはクリエイティブな方法を見つけました。新しいハイブリッドランキング/分類モデルを使用した予測結果は的確でした。 ギリギリの戦い 競争の最後の数時間、チームは最後の提出のためにすべてのモデルをまとめるために競走しました。彼らは最大40台のコンピュータで一晩中の実験を実施していました。 東京のKGMONである小野寺一樹は、緊張していました。「実際のスコアが私たちの推定値と一致するかどうか本当に分かりませんでした」と彼は語りました。…
.jpg)
Google at ACL 2023′ ACL 2023におけるGoogle
Posted by Malaya Jules, Program Manager, Google 今週、自然言語処理と理解のリーダーであり、ACL 2023のダイヤモンドレベルスポンサーであるGoogleでは、50以上の研究発表と、さまざまなワークショップやチュートリアルへの積極的な参加を通じて、この広範な研究領域を紹介いたします。 ACL(Association for Computational Linguistics)は、自然言語に対する計算的手法に関連する幅広い研究分野をカバーする一流の会議であり、オンラインで開催されています。 ACL 2023に登録されている場合、Googleブースにお立ち寄りいただき、数十億人のために興味深い問題を解決するためにGoogleで行われているプロジェクトについて詳しくお知りください。以下でGoogleの参加についてもっと詳しく知ることもできます(Googleの関連情報は太字で表示されます)。 理事会および組織委員会 エリアチェアは、Dan Garrette、ワークショップチェアは、Annie Louis、パブリケーションチェアは、Lei Shu、プログラム委員会には、Vinodkumar Prabhakaran、Najoung Kim、Markus Freitagが含まれます。 注目論文…
「ACL 2023でのGoogle」
投稿者: Malaya Jules、プログラムマネージャー、Google 今週、自然言語処理に関する計算言語学の第61回年次総会(ACL)がオンラインで開催されます。ACLは、自然言語に対する計算的アプローチに関心のある広範な研究分野をカバーする主要な学会です。 自然言語処理と理解のリーダーであり、ACL 2023のダイヤモンドレベルのスポンサーであるGoogleは、50以上の研究発表とさまざまなワークショップやチュートリアルへの積極的な参加とともに、この分野の最新の研究を紹介します。 ACL 2023に登録されている場合、Googleブースにぜひお立ち寄りいただき、何十億もの人々のために興味深い問題を解決するためのGoogleのプロジェクトについて詳しく学んでいただければと思います。以下でGoogleの参加についてもっと詳しく知ることもできます(Googleの関連情報は太字で表示されます)。 ボードと組織委員会 エリアチェアには、Dan Garrette、ワークショップチェアには、Annie Louis、発表チェアには、Lei Shu、プログラム委員には、Vinodkumar Prabhakaran、Najoung Kim、Markus Freitagが含まれています。 注目論文 NusaCrowd: インドネシアNLPリソースのオープンソースイニシアチブ Samuel Cahyawijaya, Holy Lovenia, Alham…
GoogleがACL 2023に参加します
Posted by Malaya Jules, Program Manager, Google 今週、計算言語学協会(ACL)の第61回年次総会がオンラインで開催されています。ACLは、自然言語に関する計算手法に関連する広範な研究分野をカバーする一流のカンファレンスです。 自然言語処理と理解のリーダーであり、ACL 2023のダイヤモンドレベルスポンサーであるGoogleは、50以上の論文を発表し、様々なワークショップやチュートリアルに積極的に参加することで、この分野での最新の研究を紹介します。 ACL 2023に登録されている場合、Googleブースにぜひ訪れ、数十億人の人々のために興味深い問題を解決するためにGoogleで行われているプロジェクトについて詳しく学んでください。以下でGoogleの参加についてもっと詳しく学ぶこともできます(Googleの関連組織は太字で示されています)。 理事会および組織委員会 エリアチェアには:Dan Garrette、ワークショップチェアには:Annie Louis、出版チェアには:Lei Shu、プログラム委員会には:Vinodkumar Prabhakaran、Najoung Kim、Markus Freitagが含まれます。 注目論文 NusaCrowd:Indonesian NLPリソースのオープンソースイニシアティブ Samuel…
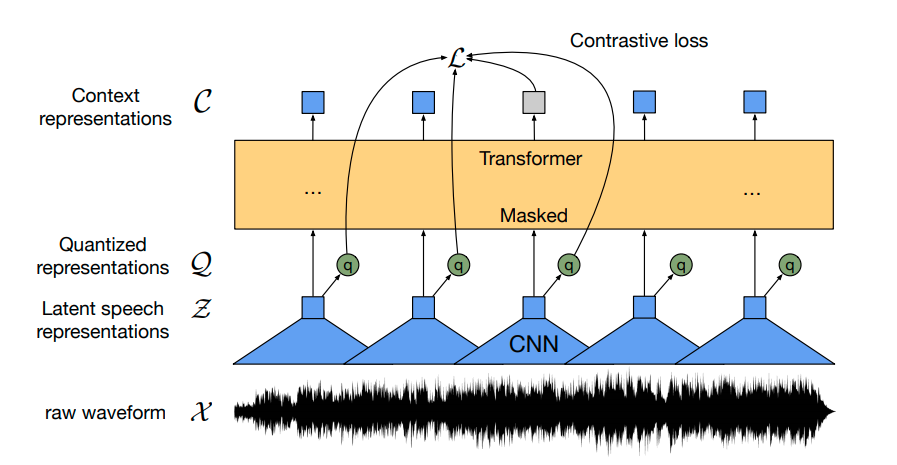
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…

機械学習でパワーアップした顧客サービス
このブログ投稿では、実際の顧客サービスのユースケースをシミュレートし、Hugging Faceエコシステムの機械学習ツールを使用してそれに対処します。 強くお勧めするのは、このノートブックをテンプレート/例として使用して、あなた自身の実世界のユースケースを解決することです。 タスク、データセット、モデルの定義 実際のコーディングに取り掛かる前に、自動化または一部自動化したいユースケースの明確な定義を持つことが重要です。ユースケースの明確な定義は、最適なタスク、使用するデータセット、および適用するモデルを特定するのに役立ちます。 NLPタスクの定義 では、自然言語処理モデルを使用して解決したい仮想的な問題について考えてみましょう。私たちは製品を販売しており、顧客サポートチームはフィードバック、クレーム、質問を含む数千のメッセージを受け取っています。理想的には、これらのメッセージにすべて返答する必要があります。 すぐに明らかになるのは、顧客サポートがすべてのメッセージに返信することは不可能であるということです。したがって、私たちは最も不満な顧客にのみ返信し、これらのメッセージに100%回答することを決定します。それらは中立的なメッセージや肯定的なメッセージと比べて最も緊急性があると考えられるためです。 非常に不満な顧客のメッセージが全メッセージの一部であると仮定し、不満なメッセージを自動的にフィルタリングできるとすると、顧客サポートはこの目標を達成できるはずです。 不満なメッセージを自動的にフィルタリングするために、自然言語処理技術を適用する予定です。 最初のステップは、私たちのユースケース(不満なメッセージのフィルタリング)を機械学習タスクにマッピングすることです。 Hugging Face Hubのタスクページは、与えられたシナリオに最も適したタスクを確認するための素晴らしい場所です。各タスクには詳細な説明と潜在的な使用例があります。 最も不満な顧客のメッセージを見つけるタスクは、テキスト分類のタスクとしてモデル化できます。メッセージを次の5つのカテゴリのいずれかに分類します:非常に不満、不満、中立、満足、または非常に満足。 適切なデータセットの見つけ方 タスクを決定したら、次にモデルをトレーニングするためのデータを見つける必要があります。これはユースケースのパフォーマンスにとって通常はモデルアーキテクチャを選ぶよりも重要です。モデルはトレーニングされたデータの質によってのみ優れた性能を発揮します。したがって、データセットの選択と作成には非常に注意が必要です。 不満なメッセージのフィルタリングという仮想的なユースケースを考えると、使用可能なデータセットを見てみましょう。 実際のユースケースでは、おそらくNLPシステムが処理する実際のデータを最もよく表す内部データがあるでしょう。したがって、そのような内部データをNLPシステムのトレーニングに使用するべきです。ただし、モデルの汎用性を向上させるために公開されているデータも含めることは役立ちます。 Hugging Face Hubの利用可能なデータセットをすべて見てみましょう。左側にはタスクカテゴリやより具体的なタスクに基づいてデータセットをフィルタリングできます。私たちのユースケースはテキスト分類 -> 感情分析に対応しているので、これらのフィルタを選択しましょう。このノートブックの執筆時点では、約80のデータセットが残ります。データセットを選ぶ際には、次の2つの側面を評価する必要があります:…
Q-Learningの紹介 パート2/2
ディープ強化学習クラスのユニット2、パート2(Hugging Faceと共に) ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 このユニットの第1部では、価値ベースの手法とモンテカルロ法と時差学習の違いについて学びました。 したがって、第2部では、Q-Learningを学び、スクラッチから最初のRLエージェントであるQ-Learningエージェントを実装し、2つの環境でトレーニングします: 凍った湖 v1 ❄️:エージェントは凍ったタイル(F)の上を歩き、穴(H)を避けて、開始状態(S)からゴール状態(G)に移動する必要があります。 自律運転タクシー 🚕:エージェントは都市をナビゲートし、乗客を地点Aから地点Bに輸送する必要があります。 このユニットは、ディープQ-Learning(ユニット3)で作業を行うためには基礎となるものです。 では、始めましょう! 🚀 Q-Learningの紹介 Q-Learningとは?…

スペースインベーダーとの深層Q学習
ハギングフェイスとのディープ強化学習クラスのユニット3 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 前のユニットでは、最初の強化学習アルゴリズムであるQ-Learningを学び、それをゼロから実装し、FrozenLake-v1 ☃️とTaxi-v3 🚕の2つの環境でトレーニングしました。 このシンプルなアルゴリズムで優れた結果を得ました。ただし、これらの環境は比較的単純であり、状態空間が離散的で小さかったため(FrozenLake-v1では14の異なる状態、Taxi-v3では500の状態)。 しかし、大きな状態空間の環境では、Qテーブルの作成と更新が効率的でなくなる可能性があることを後で見ていきます。 今日は、最初のディープ強化学習エージェントであるDeep Q-Learningを学びます。Qテーブルの代わりに、Deep Q-Learningは、状態を受け取り、その状態に基づいて各アクションのQ値を近似するニューラルネットワークを使用します。 そして、RL-Zooを使用して、Space Invadersやその他のAtari環境をプレイするためにトレーニングします。RL-Zooは、トレーニング、エージェントの評価、ハイパーパラメータの調整、結果のプロット、ビデオの記録など、RLのためのトレーニングフレームワークであるStable-Baselinesを使用しています。 では、始めましょう! 🚀 このユニットを理解するためには、まずQ-Learningを理解する必要があります。…

ハブでの評価の発表
TL;DR : 今日はAutoTrainでパワードされた新しいツール、Evaluation on the Hubを紹介します。このツールを使用すると、コードを1行も書かずにHub上の任意のモデルを任意のデータセットで評価することができます! 全てのモデルを評価しましょう🔥🔥🔥! AIの進歩は驚くべきものであり、一部の人々はAIモデルが特定のタスクにおいて人間よりも優れているかもしれないと真剣に議論しています。しかし、この進歩は均等ではありませんでした。数十年前の機械学習者にとって、現代のハードウェアやアルゴリズムは驚くべきものに見えるかもしれませんし、利用可能なデータと計算能力の量も同様ですが、モデルの評価方法はほぼ同じままでした。 しかし、現代のAIは評価の危機に直面していると言っても過言ではありません。適切な評価には、多くのモデルを多くのデータセットで、複数の指標で測定する必要があります。しかし、これを行うことは不必要に手間がかかります。特に再現性に重点を置く場合、自己報告された結果は、偶発的なバグ、実装の微妙な違い、またはそれ以上の問題によって影響を受けている可能性があります。 私たちは、より良い評価が可能であると信じています。それには、私たちコミュニティがより良いベストプラクティスを確立し、障壁を取り除こうとすることが必要です。過去数か月間、私たちはEvaluation on the Hubに取り組んできました:ボタンをクリックするだけで、任意のモデルを任意のデータセットで任意のメトリックを使用して評価することができます。始めるには、いくつかの主要なデータセットで何百ものモデルを評価し、Hub上のモデルカードに新しい素敵なPull Request機能を使用して、検証済みのパフォーマンスを表示するための多くのPRを公開しました。評価結果は、モデルカードのメタデータに直接エンコードされ、Hub上のすべてのモデルに対してフォーマットが適用されます。DistilBERTのモデルカードをチェックしてみてください! On the Hub Hub上の評価は、非常に興味深いユースケースを提供します。データサイエンティストやエグゼクティブがどのモデルを展開するかを決定する必要がある場合や、新しいデータセットで論文の結果を再現しようとする学者、展開のリスクをよりよく理解したい倫理学者などにとって、これは非常に役立ちます。最初の3つの主要なユースケースシナリオを挙げると、次のようなものがあります: タスクに最適なモデルを見つける 自分のタスクが明確であり、その仕事に適したモデルを見つけたいとします。タスクを代表するデータセットのリーダーボードをチェックできます。素晴らしいですね!もし興味のある新しいモデルが、そのデータセットのリーダーボードにまだ掲載されていない場合は、Hubを離れずに評価を実行することができます。 新しいデータセットでモデルを評価する 新しく作成したデータセットでベースラインを実行したい場合はどうでしょう?Hubにアップロードして、それに対して評価したいモデルを何個でも評価することができます。コードは不要です。さらに、自分のデータセットでこれらのモデルを評価する方法が、他のデータセットで評価された方法とまったく同じであることを確信することができます。 自分のモデルを他の関連する多くのデータセットで評価する また、SQuADでトレーニングされた全く新しい質問応答モデルがあるとしましょう。評価するためのさまざまな質問応答データセットが何百もあります…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.