Learn more about Search Results プロファイリング - Page 8

- You may be interested
- YOLOv7 最も先進的な物体検出アルゴリズム?
- AIを活用した「ディープフェイク」詐欺:...
- NumpyとPandasを超えて:知られざるPython...
- AudioLDM 2, でも速くなりました ⚡️
- vLLMについて HuggingFace Transformersの...
- Google研究者がAudioPaLMを導入:音声技術...
- 「クロード2の探索:アントロピックの次世...
- エネルギー省が新興技術を加速させます
- 「ゼロからの実験オーケストレーション」
- 「ABBYYインテリジェントオートメーション...
- 「アイデアからAIを活用したビジネスへ:A...
- ChatGPT コードインタプリターを使用でき...
- 🤗 Transformersにおけるネイティブサポー...
- AIがオンエア中:世界初のRJボット、アシ...
- 「InstagramがAIによって生成されたコンテ...

北京大学の研究者は、FastServeを紹介しました:大規模な言語モデルLLMsのための分散推論サービスシステム
大規模言語モデル(LLM)の改善により、さまざまな分野での機会が生まれ、新しい波の対話型AIアプリケーションがインスピレーションを与えています。最も注目すべきものの1つはChatGPTで、ソフトウェアエンジニアリングから言語翻訳までの問題を解決するために、人々がAIエージェントと非公式にコミュニケーションを取ることを可能にします。 ChatGPTは、その驚異的な能力のために、史上最も急成長しているプログラムの1つです。MicrosoftのNew Bing、GoogleのBard、MetaのLLaMa、StanfordのAlpaca、DatabricksのDolly、UC BerkeleyのVicunaなど、多くの企業がLLMやChatGPTのような製品をリリースするトレンドに追従しています。 LLMの推論は、ResNetなどの他の深層ニューラルネットワーク(DNN)モデルの推論とは異なる特徴を持っています。LLM上に構築された対話型AIアプリケーションは、機能するために推論を提供する必要があります。これらのアプリの対話的なデザインは、LLM推論のジョブ完了時間(JCT)を迅速に行う必要があり、ユーザーエクスペリエンスを魅力的にするためです。たとえば、データをChatGPTに送信した場合、消費者は即座の応答を期待しています。ただし、LLMの数と複雑さのため、推論サービングインフラは大きな負荷を受けています。企業は、LLM推論操作を処理するために、GPUやTPUなどのアクセラレータを備えた高価なクラスタを設置しています。 DNNの推論ジョブは通常、確定的で非常に予測可能です。つまり、モデルとハードウェアが推論ジョブの実行時間を大部分に決定します。たとえば、同じResNetモデルを特定のGPU上で使用しても、さまざまな入力写真の実行時間はわずかに異なります。一方、LLMの推論位置はユニークな自己回帰パターンを持っています。LLMの推論作業は複数のラウンドを経ます。各イテレーションは1つの出力トークンを生成し、それが次のイテレーションでの次のトークンに追加されます。初めには不明な出力の長さは、実行時間と入力の長さの両方に影響を与えます。ResNetなどの決定論的モデル推論タスクの大部分は、ClockworkやShepherdのような既存の推論サービングシステムによって対応されています。 これらのシステムは、正確な実行時間のプロファイリングに基づいてスケジューリングの決定を行いますが、実行時間が可変のLLM推論には効果的ではありません。LLM推論の最も先進的な方法はOrcaです。Orcaはイテレーションレベルのスケジューリングを提案し、各イテレーション後に現在の処理バッチに新しいジョブを追加するか、完了したジョブを削除することができます。ただし、Orcaは先入れ先出し(FCFS)を使用して推論ジョブを処理します。スケジュールされたタスクは完了するまで連続して実行されます。推論ジョブの制約されたGPUメモリ容量と低いJCT要件のため、処理バッチを任意の数の入力関数で拡張することはできません。完了まで実行されるまでのブロックの問題はよく知られています。 LLMはサイズが大きく、絶対的な意味で実行に時間がかかるため、LLM推論操作ではこの問題が特に深刻です。特に出力の長さが長い場合、大規模なLLM推論ジョブは完了に時間がかかり、後続の短いジョブを妨げます。北京大学の研究者たちは、FastServeと呼ばれるLLM向けの分散推論サービングソリューションを開発しました。FastServeは、LLM推論のイテレーションレベルのスケジューリングと自己回帰パターンを利用して、各出力トークンのレベルで事前処理を可能にします。FastServeは、キュー内の別のジョブによって予定されたタスクを続行するか、中断するかを選択できます。これにより、FastServeはJCTと先行ブロッキングを削減し、先制的なスケジューリングを介しています。 FastServeの基盤となるのは、ユニークなスキップジョインのマルチレベルフィードバックキュー(MLFQ)スケジューラです。MLFQは、情報がない環境で平均JCTを最小化するためのよく知られた手法です。各作業は最も高い優先度キューで開始され、一定の時間内に完了しない場合は次の優先度キューに降格されます。LLM推論は、セミ情報が無関係であり、出力の長さが事前にはわからないということを意味します。これがLLM推論と従来の状況の主な違いです。入力の長さは、初期の出力トークンを作成するための実行時間を決定し、LLM推論の自己回帰パターンのため、その実行時間は後続のトークンよりもはるかに長くかかる場合があります。 入力が長く、出力が短い場合、初期の出力トークンの実行時間が大部分を占めます。彼らは、この特性を伝統的なMLFQにスキップジョインを追加するために使用します。到着タスクは、最初の出力トークンの実行時間をラインの降格閾値と比較して、適切なキューに参加します。常に最も高い優先度キューに入るのではなく、参加したキューよりも優先度の高いキューはバイパスされ、降格が最小限に抑えられます。MLFQによる先制的なスケジューリングは、中断されたが完了していないジョブを一時的な状態で保持するため、追加のメモリオーバーヘッドを加えます。LLMは、各Transformerレイヤーごとにキー値キャッシュを保持し、中間状態を保存します。バッチサイズが超過しない限り、FCFSキャッシュにはスケジュールされたジョブの中間状態を保持する必要があります。ただし、MLFQで開始された追加のジョブは、優先度の低いキューに降格されます。MLFQの中断されたが完了していないすべてのジョブは、キャッシュによって保持される中間状態を持つ必要があります。LLMのサイズとGPUの制限されたメモリスペースを考慮すると、キャッシュがオーバーフローする可能性があります。キャッシュがいっぱいの場合、スケジューラは新しいジョブの開始を単純に遅延させることができますが、これにより再び先行ブロッキングが発生します。 代わりに、彼らは生産的なGPUメモリ管理システムを開発し、スケジュールされたときに低優先度のキュー内のプロセスの状態を前もってアップロードし、キャッシュがほぼいっぱいになったときに状態をオフロードします。効率を高めるために、パイプライン処理と非同期メモリ操作を使用しています。FastServeは、テンソルとパイプライン並列処理などの並列化技術を使用して、1つのGPUに収まらない巨大なモデルのために多数のGPUを使用した分散推論サービスを提供します。パイプラインのブロックを減らすために、スケジューラは同時に複数のジョブのバッチを実行します。キーと値のキャッシュは、キーと値のキャッシュマネージャによって組織化され、GPUとホストメモリの間のメモリスワッピングの管理も行います。彼らは、NVIDIA FasterTransformerをベースにしたFastServeシステムのプロトタイプを実際に実装しました。結果は、FastServeが最先端のOrcaソリューションと比較して、平均およびテールのジョブ完了時間をそれぞれ最大5.1と6.4向上させることを示しています。

最適化ストーリー:ブルーム推論
この記事では、bloomをパワーアップする効率的な推論サーバーの裏側について説明します。 数週間にわたり、レイテンシーを5倍削減し(スループットを50倍に増やしました)、このような速度向上を達成するために私たちが経験した苦労やエピックな勝利を共有したかったです。 さまざまな人々が多くの段階で関与していたため、ここではすべてをカバーすることはできません。また、最新のハードウェア機能やコンテンツが定期的に登場するため、一部の内容は古くなっているか、まったく間違っている可能性があることをご了承ください。 もし、お好みの最適化手法が議論されていなかったり、正しく表現されていなかったりした場合は、お詫び申し上げます。新しいことを試してみたり、間違いを修正するために、ぜひお知らせください。 言うまでもなく、まず大きなモデルが最初にアクセス可能でなければ、それを最適化する理由はありません。これは、多くの異なる人々によってリードされた信じられないほどの取り組みでした。 トレーニング中にGPUを最大限に活用するために、いくつかの解決策が検討され、結果としてMegatron-Deepspeedが最終的なモデルのトレーニングに選ばれました。これは、コードがそのままではtransformersライブラリと互換性がない可能性があることを意味します。 元のトレーニングコードのため、通常行っていることの1つである既存のモデルをtransformersに移植することに取り組みました。目標は、トレーニングコードから関連する部分を抽出し、transformers内に実装することでした。この取り組みには「Younes」が取り組みました。これは、1ヶ月近くかかり、200のコミットが必要でした。 後で戻ってくるいくつかの注意点があります: 小さなモデルbigscience/bigscience-small-testingとbigscience/bloom-560mを用意する必要があります。これは非常に重要です。なぜなら、それらと一緒に作業するとすべてが高速化されるからです。 まず、最後のログがバイトまで完全に同じになることを望むことをあきらめる必要があります。PyTorchのバージョンがカーネルを変更し、微妙な違いを導入する可能性があり、異なるハードウェアでは異なるアーキテクチャのため異なる結果が得られる場合があります(コストの理由から常にA100 GPUで開発したくはないでしょう)。 すべてのモデルにとって、良い厳格なテストスイートを作ることは非常に重要です 私たちが見つけた最高のテストは、固定された一連のプロンプトを持つことでした。プロンプトを知っており、決定論的な結果が得られる必要があります。2つの生成物が同じであれば、小さなログの違いは無視できます。ドリフトが見られるたびに調査する必要があります。それは、あなたのコードがやるべきことをしていないか、または実際にそのモデルがドメイン外であるためにノイズに対してより敏感であるかのいずれかです。いくつかのプロンプトと十分に長いプロンプトがあれば、すべてのプロンプトを誤ってトリガーする可能性は低くなります。プロンプトが多ければ多いほど良く、プロンプトが長ければ長いほど良いです。 最初のモデル(small-testing)は、bloomと同じようにbfloat16であり、すべてが非常に似ているはずですが、それほどトレーニングされていないか、うまく機能しないため、出力が大きく変動します。そのため、これらの生成テストに問題がありました。2番目のモデルはより安定していましたが、bfloat16ではなくfloat16でトレーニングおよび保存されていました。そのため、2つの間にはエラーの余地があります。 完全に公平を期すために言えば、bfloat16→float16への変換は推論モードでは問題なさそうです(bfloat16は主に大きな勾配を扱うために存在しません)。 このステップでは、重要なトレードオフが発見され、実装されました。bloomは分散環境でトレーニングされたため、一部のコードはLinearレイヤー上でテンソル並列処理を行っており、単一のGPU上で同じ操作を実行すると異なる結果が得られていました。これを特定するのにかなりの時間がかかり、100%の準拠を選択した場合、モデルの速度が遅くなりましたが、少しの差がある場合は実行が速く、コードがシンプルになりました。設定可能なフラグを選択しました。 注:この文脈でのパイプライン並列処理(PP)は、各GPUがいくつかのレイヤーを所有し、各GPUがデータの一部を処理してから次のGPUに渡すことを意味します。 これで、動作可能なtransformersのクリーンなバージョンがあり、これに取り組むことができます。 Bloomは352GB(176Bパラメーターのbf16)のモデルであり、それに合わせるために少なくともそれだけのGPU RAMが必要です。一時的に小さなマシンでCPUにオフロードすることを検討しましたが、推論速度が桁違いに遅くなるため、それを取り下げました。 次に、基本的にはパイプラインを使用したかったのです。つまり、ドッグフーディングであり、これがAPIが常に裏で使用しているものです。 ただし、pipelinesは分散意識がありません(それがその目的ではありません)。オプションを簡単に話し合った後、新しく作成されたdevice_map="auto"を使用してモデルのシャーディングを管理するためにaccelerateを使用することにしました。いくつかのバグを修正し、transformersのコードを修正してaccelerateが正しい仕事をするのを助ける必要がありました。 これは、transformersのさまざまなレイヤーを分割し、各GPUにモデルの一部を与えて動作させることで機能します。つまり、GPU0が作業を行い、次にGPU1に引き渡し、それ以降同様に行います。 最終的には、上に小さなHTTPサーバーを置くことで、bloom(大規模なモデル)を提供できるようになりました!…

CVモデルの構築と展開:コンピュータビジョンエンジニアからの教訓
コンピュータビジョン(CV)モデルの設計、構築、展開の経験を3年以上積んできましたが、私は人々がこのような複雑なシステムの構築と展開において重要な側面に十分な注力をしていないことに気づきましたこのブログ投稿では、私自身の経験と、最先端のCVモデルの設計、構築、展開において得た貴重な知見を共有します...

MLにおけるETLデータパイプラインの構築方法
データ処理から迅速な洞察まで、頑強なパイプラインはどんなMLシステムにとっても必須ですデータチーム(データとMLエンジニアで構成される)はしばしばこのインフラを構築する必要があり、この経験は苦痛となることがありますしかし、MLでETLパイプラインを効率的に使用することで、彼らの生活をはるかに楽にすることができます本記事では、その重要性について探求します...

2023年のMLOpsの景色:トップのツールとプラットフォーム
2023年のMLOpsの領域に深く入り込むと、多くのツールやプラットフォームが存在し、モデルの開発、展開、監視の方法を形作っています総合的な概要を提供するため、この記事ではMLOpsおよびFMOps(またはLLMOps)エコシステムの主要なプレーヤーについて探求します...
科学ソフトウェアの開発
この記事では、このシリーズの最初の記事で示されたように、科学ソフトウェアの開発においてTDDの原則に従って、Sobelフィルタとして知られるエッジ検出フィルタを開発します

データのクレンジングを通じたデジタルトランスフォーメーションの向上ガイド
デジタル変革は、急速に進化するデジタルの風景に適応し、企業が成長するために重要な要素ですデジタル変革の恩恵を十分に活用するためには、組織は正確かつ信頼性のあるデータに依存する必要がありますしかし、多くの企業はデータ品質の問題に苦しんでおり、これはデジタル変革の取り組みを妨げる可能性がありますこれは…データクレンジングを通じたデジタル変革の向上ガイドです詳細はこちらをご覧ください

データ管理とは何か、そしてなぜ重要なのか?
イントロダクション データは、ある意味でビジネス界においてすべてです。少なくとも、データ分析、予測、そして適切に計画を立てることなしに世界を想像するのは難しいです!Cレベルのエグゼクティブの95%がビジネス戦略にデータが必要不可欠だと考えています。結局のところ、より深い知識が必要で、より大きな可能性を引き出し、意思決定を改善するためには、どの組織も知っておく必要があります。しかし、すべてを手に入れるには、この中でデータ管理の欠かせない役割を理解する必要があります。データ管理とは何か?それについてすべて知るために読み続けてください! 組織におけるデータ管理とは何ですか? データ管理とは、組織のデータ分析業務に必要なデータの収集、整理、変換、および保存です。このプロセスは、様々な目的、例えば洞察を得たり、マーケティングキャンペーンを計画するためのクリーンできちんと管理されたデータのみを保証します。データが見つけやすく、視覚化や微調整ができる場合、組織は具体的な洞察を得て、情報に基づいた意思決定を行うのに役立ちます。 主要なコンポーネントと目標 効果的なデータの取り扱いと制御は、データ管理のいくつかのコンポーネントと目標の結果です。各要因が特定の計画や次の行動を促進するようになっています。だから、あなたがそれが何であるかを知っているなら、次に、実践を導入するさまざまな側面と目標があります: データ品質 データの品質と正確性を保証することは、主要な目的の1つです。これには、データを検証しクレンジングするためのプロセスとコントロールを実装し、エラーを特定して修正し、一貫性のないレコードを排除することが含まれます。高いデータ品質基準は、正確な情報の信頼性を強化し、意思決定、報告、および分析を支援します。 データセキュリティ データ管理の目的について答えることができないのは、セキュリティについて言及しないことです。認可されていないアクセス、侵害、および損失からのデータ保護は、データ管理の重要な目的です。これには、暗号化、ユーザー認証、アクセス制御、およびデータバックアップ戦略などのセキュリティ対策が含まれます。データを保護することで、組織は顧客の信頼を維持し、データ保護規制に準拠し、潜在的なリスクに対処できます。 データガバナンス データガバナンスとは、組織内のデータ資産の総合的な管理と制御を意味します。データを管理するための役割、責任、およびプロセスを定義するためのポリシー、手順、およびフレームワークを確立することを目的としています。データガバナンスを実践している組織は、そうでない組織よりも42%自信があります。これには、データの所有権を定義し、データ基準を確立し、規制に準拠することが含まれます。 データアクセシビリティ データ管理では、認可されたユーザーがデータに簡単にアクセスできるようにすることに重点が置かれています。組織は、効率的なデータストレージと取得のメカニズムを確立し、データアーカイブとバックアップ戦略を実装し、データインフラストラクチャとシステムを最適化して、利用可能性とアクセシビリティを簡単にします。これにより、運用効率が向上し、意思決定が改善されます。 データ管理ライフサイクル データ管理ライフサイクルとは、異なる段階でデータを管理することです。データの最大の可能性を引き出すためのさまざまなプラクティスをカバーしています。ここでは、ライフサイクルの概要を示します: データ収集:基礎的な段階で、内部システム、外部パートナー、または公開リポジトリなどからデータを収集します。データの正確性と完全性を確保するために、データ品質チェックと検証プロセスを実行することがあります。 データストレージ:データが収集されたので、それを保存して整理する時が来ました。この段階では、適切なデータストレージツールと技術、データベース設計、データモデリング、およびインデックス戦略を決定することが含まれます。この段階では、アクセス制御や暗号化などのデータセキュリティ対策も実装されます。 データ変換:データは、適切な分析のために包括的な形式に統合および変換する必要があることが多いです。このDMLCの段階には、データクレンジング、データ統合、データ変換、およびデータエンリッチメントのプロセスが含まれます。 データアーカイブ:データが主目的を果たした後、将来の使用またはコンプライアンス要件のためにアーカイブまたは保持するのが最善です。このプロセスには、データ保持ポリシーを確立し、ストレージ中のデータのセキュリティを確保し、長期的なデータ保存のためのさまざまな戦略を実装することが含まれます。 データ廃棄:データがもはや必要ではありませんか?目的に到達しましたか?はいなら、廃棄する時間です。最後の段階で、組織は関係のないデータを廃棄します。これは主にプライバシーを保護し、データ保護規制に準拠するためのものです。 主要なコンセプト データ管理では、データの整理、処理、利用を効果的にするために必要なさまざまな重要なコンセプトが結集しています。以下に、4つの基本的なコンセプトを示します: データ・ガバナンス…

Mr. Pavan氏のデータエンジニアリングの道は、ビジネスの成功を導く
はじめに 私たちは、Pavanさんから学ぶ素晴らしい機会を得ました。彼は問題解決に情熱を持ち、持続的な成長を追求する経験豊富なデータエンジニアです。会話を通じて、Pavanさんは自身の経験、インスピレーション、課題、そして成し遂げたことを共有しています。そのため、データエンジニアリングの分野における貴重な知見を提供してくれます。 Pavanさんの実績を探索する中で、再利用可能なコンポーネントの開発、効率化されたデータパイプラインの作成、グローバルハッカソンの優勝などに誇りを持っていることがわかります。彼は、データエンジニアリングを通じてクライアントのビジネス成長を支援することに情熱を注いでおり、彼の仕事が彼らの成功に与える影響について共有してくれます。さあ、Pavanさんの経験と知恵から学んで、データエンジニアリングの世界に没頭しましょう。 インタビューを始めましょう! AV:自己紹介と経歴について教えてください。 Pavanさん:私は情報技術の学生として学問の道を歩み始めました。当時、この分野での有望な求人が私を駆り立てていました。しかし、私のプログラミングに対する見方はMSハッカソン「Yappon!」に参加した時に変わりました。その経験が私に深い情熱をもたらしました。それは私の人生の転機となり、プログラミングの世界をより深く探求するスパークを生み出しました。 それ以来、私は4つのハッカソンに積極的に参加し、うち3つを優勝するという刺激的な結果を残しました。これらの経験は私の技術的なスキルを磨き、タスクの自動化や効率的な解決策の探求に執念を燃やすようになりました。私はプロセスの効率化や繰り返しタスクの削減に挑戦することで成長しています。 個人的には、私は内向的と外向的のバランスを取るambivertだと考えています。しかし、私は常に自分の快適ゾーンから踏み出して、成長と発展のための新しい機会を受け入れるように自分自身を鼓舞しています。プログラミング以外の私の情熱の1つはトレッキングです。大自然を探索し、自然の美しさに浸ることには魅力的な何かがあります。 私のコンピュータサイエンス愛好家としての旅は、仕事の見通しに対する実用的な見方から始まりました。しかし、ハッカソンに参加することで、プログラミングに対する揺るぎない情熱に変わっていきました。成功したプロジェクトの実績を持ち、自動化の才能を持っていることから、私はスキルを拡大し、コンピュータサイエンス分野での積極的な貢献を続けることを熱望しています。 AV:あなたのキャリアに影響を与えた人物を数名挙げて、どのように影響を受けたか教えてください。 Pavanさん:まず、私は母親と祖母に感謝しています。彼女たちはサンスクリットの格言「Shatkarma Manushya yatnanam, saptakam daiva chintanam.」に象徴される価値観を私に教えてくれました。人間の努力と精神的な瞑想の重要性を強調したこの哲学は、私のキャリアを通じて指導原理となっています。彼女たちの揺るぎないサポートと信念は、私の常に刺激となっています。 また、私のB.Tech時代に教授だったSmriti Agrawal博士にも大きな成長を感じています。彼女はオートマトンとコンパイラ設計を教えながら、その科目についての深い理解を伝え、キャリア開発の重要性を強調しました。「6ヶ月で履歴書に1行も追加できない場合は、成長していない」という彼女の有益なアドバイスは、私のマインドセットを変えるきっかけになりました。このアドバイスは、私に目標を設定し、挑戦的なプロジェクトに取り組み、定期的にスキルセットを更新するよう駆り立て、私を常に成長と学びの機会に導いてくれました。 さらに、私にとって支援的な友人のネットワークを持っていることは幸運なことです。彼らは私のキャリアの旅において重要な役割を果たしています。彼らは、複雑なプログラミングの概念を理解するのを手伝ってくれたり、私をハッカソンに参加させてスキルを磨いたりすることで、私を引っ張り出し、最高の自分を引き出すのに欠かせない存在となっています。彼らの指導と励ましは、私を常に限界を超えて、最高の自分を引き出すのに不可欠であり、私の今までの進歩に欠かせません。 AV:なぜデータと一緒に働くことに興味を持ち、データエンジニアとしての役割の中で最もエキサイティングなことは何ですか? Pavanさん:私がデータと一緒に働くことに惹かれたのは、データが今日の世界であらゆるものを動かしていることを認識したからです。データは、意思決定の基盤であり、戦略の策定、革新の源泉です。データを生のままから意味のある洞察に変換し、それらの洞察を顧客やビジネスの成功につなげることが、私がデータと一緒に働くことに情熱を持つようになった原動力となりました。 データエンジニアとして私が最も興奮するのは、データ革命の最前線に立つ機会です。膨大な量の情報を効率的に収集、処理、分析するデータシステムを設計・実装する複雑なプロセスに魅了されています。データの膨大な量と複雑さは、創造的な問題解決と継続的な学習を必要とする刺激的な課題を提供します。 データエンジニアとして最もエキサイティングな側面の1つは、データの潜在的な可能性を引き出すことができることです。堅牢なパイプラインを構築し、高度な分析を実装し、最新技術を活用することで、情報を収集し、意思決定を支援し、変革につながる貴重な洞察を明らかにすることができます。データ駆動型のソリューションが直接顧客体験を改善し、業務効率を向上させ、ビジネス成長を促進する様子を見ることは、非常にやりがいを感じます。 また、この分野のダイナミックな性質は私を引っ張っていきます。データエンジニアリング技術と技法の急速な進歩は、常に新しいイノベーションの機会を提供してくれます。これらの進歩の最前線に立ち、継続的に学習し、スキルを磨き、複雑なデータ課題を解決するために適用することは、知的好奇心を刺激し、専門的にもやりがいを感じさせます。…
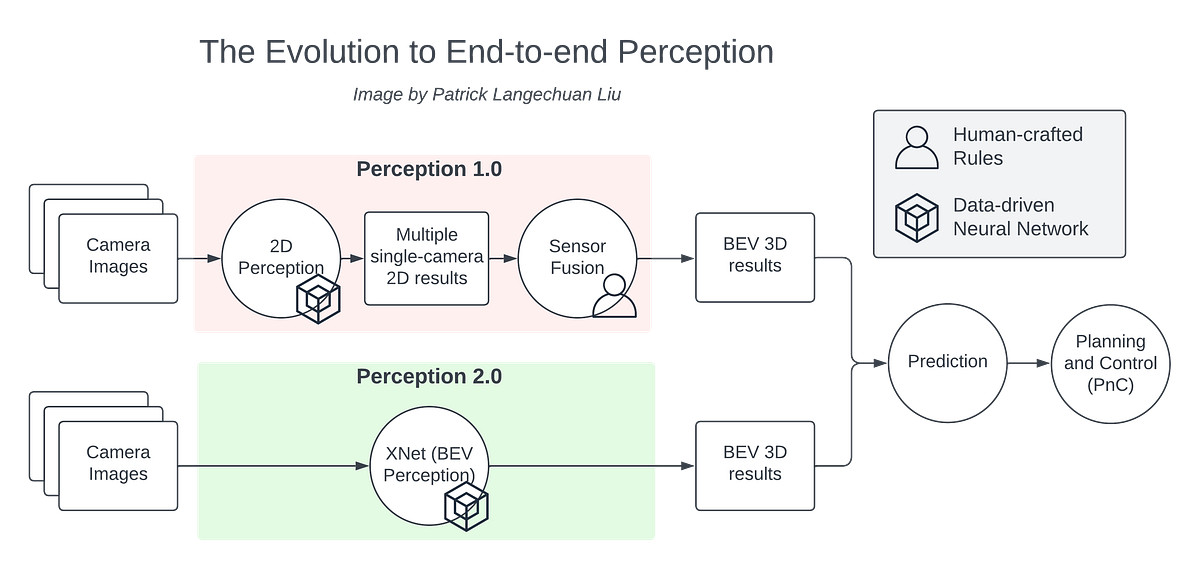
量産自動運転におけるBEVパーセプション
BEVの認識技術は、ここ数年で非常に進歩しました自動運転車の周りの環境を直接認識することができますBEVの認識技術はエンド・トゥ・エンドと考えることができます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.