Learn more about Search Results スペイン語 - Page 8

- You may be interested
- ディープラーニング実験の十のパターンと...
- RT-2 新しいモデルは、ビジョンと言語をア...
- 「LangChainエージェントを使用してLLMを...
- UN支援チームがウクライナの歴史的な場所...
- 「接続から知能へ:ブロックチェーンとAI...
- 「従来のAI vs 生成的AI」
- 「脳と体をモニターするイヤホン」
- データを持っていますか?SMOTEとGANが合...
- 情報抽出の始まり:キーワードを強調し、...
- 「Googleとトロント大学の研究者が、ライ...
- 「AIを活用してPodcastを要約する:ChatGP...
- 機械学習を用いたサッカータッチダウンの予測
- 「12か国がソーシャルメディア巨人に違法...
- エンドツーエンドのMLパイプラインの構築方法
- ロボットが太陽エネルギー研究を推進

ハギングフェイスフェローシッププログラムの発表
フェローシップは、さまざまなバックグラウンドを持つ優れた人々のネットワークであり、機械学習のオープンソースエコシステムに貢献しています🚀。このプログラムの目標は、主要な貢献者に力を与え、彼らの影響力をスケールさせると同時に、他の人々にも貢献を促すことです。 フェローシップの仕組み 🙌🏻 これはHugging Faceが貢献者の素晴らしい仕事をサポートしています!フェローであることは、すべての人にとって異なる方法で機能します。重要な質問は次のとおりです: ❓ 貢献者がより大きな影響を持つためには何が必要ですか? Hugging Faceは彼らが常にやりたかったプロジェクトを実現できるようにどのようにサポートできますか? あらゆるバックグラウンドのフェローを歓迎します!機械学習の進歩は草の根の貢献に依存しています。それぞれの人には、さまざまな方法でこの分野を民主化するために使用できる独自のスキルと知識があります。それぞれのフェローは異なる方法で影響を与え、それは完璧です🌈。 Hugging Faceは彼らが最も必要とする方法で創造し、共有し続けることをサポートします。 フェローシップに参加することの利点は何ですか? 🤩 利点は個々の興味に基づきます。Hugging Faceがフェローをサポートする例をいくつか紹介します: 💾 コンピューティングとリソース 🎁 マーチャンダイズと資産。 ✨ Hugging Faceからの公式な認知。 フェローになるには…

Twitterでの感情分析を始める
センチメント分析は、テキストデータをその極性(ポジティブ、ネガティブ、ニュートラルなど)に基づいて自動的に分類するプロセスです。企業は、ツイートのセンチメント分析を活用して、顧客が自社製品やサービスについてどのように話しているかを把握し、ビジネスの意思決定に洞察を得ること、製品の問題や潜在的なPR危機を早期に特定することができます。 このガイドでは、Twitterでのセンチメント分析を始めるために必要なすべてをカバーします。コーダーと非コーダーの両方向けに、ステップバイステップのプロセスを共有します。コーダーの場合、Inference APIを使用してツイートのセンチメント分析を簡単なコード数行でスケールして行う方法を学びます。コーディング方法を知らない場合でも心配ありません!Zapierを使用してセンチメント分析を行う方法もカバーします。Zapierはツイートを収集し、Inference APIで分析し、最終的に結果をGoogle Sheetsに送信するためのノーコードツールです⚡️ 一緒に読んで興味があるセクションにジャンプしてください🌟: センチメント分析とは何ですか? コーディングを使用したTwitterセンチメント分析の方法は? コーディングを使用せずにTwitterセンチメント分析を行う方法は? 準備ができたら、楽しんでください!🤗 センチメント分析とは何ですか? センチメント分析は、機械学習を使用して人々が特定のトピックについてどのように話しているかを自動的に識別する方法です。センチメント分析の最も一般的な用途は、テキストデータの極性(つまり、ツイートや製品レビュー、サポートチケットが何かについてポジティブ、ネガティブ、またはニュートラルに話しているかを自動的に識別すること)の検出です。 例として、@Salesforceをメンションしたいくつかのツイートをチェックして、センチメント分析モデルによってどのようにタグ付けされるかを確認してみましょう: “The more I use @salesforce the more I dislike it. It’s…

世界最大のオープンマルチリンガル言語モデル「BLOOM」をご紹介します
大規模言語モデル(LLM)は、AI研究に大きな影響を与えています。これらの強力な汎用モデルは、ユーザーの指示に基づいてさまざまな言語タスクを遂行することができます。しかし、学術界、非営利団体、および中小企業の研究所は、それらを作成、研究、または使用することが困難であり、必要なリソースと独占的な権利を持つわずかな産業研究所だけが完全にアクセスできます。今日、私たちは初めて完全な透明性で訓練された最初の多言語LLMであるBLOOMを公開し、この現状を変えます。これは、AI研究者が単一の研究プロジェクトに関与した最大の共同研究の成果です。 BLOOMは1760億のパラメータを持ち、46の自然言語と13のプログラミング言語でテキストを生成することができます。スペイン語、フランス語、アラビア語などのほとんどすべての言語において、BLOOMはこれまでに作成された1000億以上のパラメータを持つ最初の言語モデルとなります。これは、70以上の国と250以上の機関から1000人以上の研究者が関与した1年の作業の集大成であり、フランスのパリ南部にあるJean ZayスーパーコンピュータでのBLOOMモデルのトレーニングは、フランスの研究機関CNRSとGENCIからの推定300万ユーロ相当の計算助成金によって可能になりました。 研究者は今やBLOOMをダウンロードして実行し、最新の大規模言語モデルの性能と動作を、最も深い内部操作まで調査することができます。また、ビッグサイエンスプロジェクト自体で開発されたモデルの責任あるAIライセンスの条件に同意する個人や機関は、ローカルマシンやクラウドプロバイダ上でモデルを使用し、拡張することができます。この協力と継続的な改善の精神のもと、トレーニングの中間チェックポイントと最適化器の状態も初めて公開します。8つのA100を使って遊ぶ余裕がありませんか?現在はGoogleのTPUクラウドにバックアップされた推論APIとモデルのFLAXバージョンも提供されており、迅速なテスト、プロトタイピング、および小規模な使用が可能です。Hugging Face Hubで既に試すことができます。 これはまだ始まりに過ぎません。BLOOMの機能は、ワークショップがモデルを実験し、調整し続けることでさらに向上していきます。私たちは、以前の努力であるT0++と同様にBLOOMを指示可能にするための作業を開始し、さらに言語を追加し、モデルをより使いやすいバージョンに圧縮し、より複雑なアーキテクチャの出発点として使用する予定です… 1000億以上のパラメータモデルの力を持つ実験のすべてが、現在は可能です。BLOOMは、成長するモデルの種であり、一度きりのモデルではありません。私たちは、それを拡大するためのコミュニティの取り組みをサポートする準備ができています。
SetFit プロンプトなしで効率的なフューショット学習
SetFitは、通常のファインチューニングよりもサンプル効率が高く、ノイズに強いです。 事前学習済みの言語モデルを用いたフューショット学習は、データサイエンティストの悪夢であるほとんどラベルのないデータを扱うための有望な解決策として浮上しています 😱。 Intel LabsとUKP Labとの共同研究を通じて、Hugging FaceはSetFitを紹介できることを嬉しく思っています。SetFitは、Sentence Transformersのフューショットファインチューニングの効率的なフレームワークです。SetFitは少量のラベル付きデータで高い精度を達成します – 例えば、顧客レビュー(CR)感情データセットでクラスごとにわずか8つのラベル付きの例を使用すると、SetFitはフルトレーニングセットの3,000の例でRoBERTa Largeのファインチューニングと競争力を持ちます 🤯! 他のフューショット学習手法と比較して、SetFitにはいくつかの特徴があります: 🗣 プロンプトや口述者不要:フューショットファインチューニングの現在の技術は、例を基に言語モデルに適した形式に変換するための手作りのプロンプトや口述者が必要です。SetFitはプロンプトを一切必要とせず、わずかな数のラベル付きテキスト例から直接豊かな埋め込みを生成します。 🏎 高速トレーニング:SetFitは、高い精度を実現するためにT0やGPT-3のような大規模なモデルを必要としません。そのため、トレーニングと推論の速度は通常1桁以上速くなります。 🌎 多言語対応:SetFitはHubの任意のSentence Transformerと組み合わせて使用できるため、マルチリンガルなチェックポイントをファインチューニングするだけで、複数の言語でテキストを分類することができます。 詳細については、私たちの論文、データ、コードをご覧ください。このブログ投稿では、SetFitの動作方法と独自のモデルをトレーニングする方法について説明します。さあ、始めましょう! どのように動作するのか? SetFitは効率とシンプルさを考慮して設計されています。SetFitはまず、少数のラベル付き例(通常はクラスごとに8または16個)でSentence Transformerモデルをファインチューニングします。次に、ファインチューニングされたSentence…

オーディオデータセットの完全ガイド
イントロダクション 🤗 Datasetsは、あらゆるドメインのデータセットをダウンロードして準備するためのオープンソースライブラリです。そのミニマリスティックなAPIにより、ユーザーはたった1行のPythonコードでデータセットをダウンロードして準備することができます。効率的な前処理を可能にするための一連の関数も提供されています。利用可能なデータセットの数は類を見ないものであり、ダウンロードできる最も人気のある機械学習データセットがすべて揃っています。 さらに、🤗 Datasetsにはオーディオ特化の機能も備わっており、研究者や実践者にとってもオーディオデータセットの取り扱いを容易にするものです。このブログでは、これらの機能をデモンストレーションし、なぜ🤗 Datasetsがオーディオデータセットのダウンロードと準備のためのベストな場所なのかをご紹介します。 目次 The Hub オーディオデータセットのロード ロードが簡単、処理も簡単 ストリーミングモード:銀の弾丸 The Hubのオーディオデータセットのツアー まとめ The Hub The Hugging Face Hubは、モデル、データセット、デモをホストするプラットフォームであり、すべてがオープンソースで公開されています。さまざまなドメイン、タスク、言語にわたるオーディオデータセットの成長するコレクションがあります。🤗 Datasetsとの緊密な統合により、Hubのすべてのデータセットを1行のコードでダウンロードすることができます。 Hubに移動して、タスクでデータセットをフィルタリングしましょう: Hubの音声認識データセット…

ロボキャット:自己改善型ロボティックエージェント
ロボットは私たちの日常生活の一部として急速になっていますが、彼らはしばしば特定のタスクをうまく実行するためにのみプログラムされています最近のAIの進歩を活用することで、より多くの方法で助けることができるロボットが可能になるかもしれませんが、一般的な用途のロボットの構築には、現実世界のトレーニングデータを収集するために必要な時間の制約があり、進展が遅れています私たちの最新の論文では、自己改善型のAIエージェントであるロボキャットを紹介していますロボキャットは、異なるアームでさまざまなタスクを実行する方法を学び、その後、新しいトレーニングデータを自己生成して技術を向上させるのです
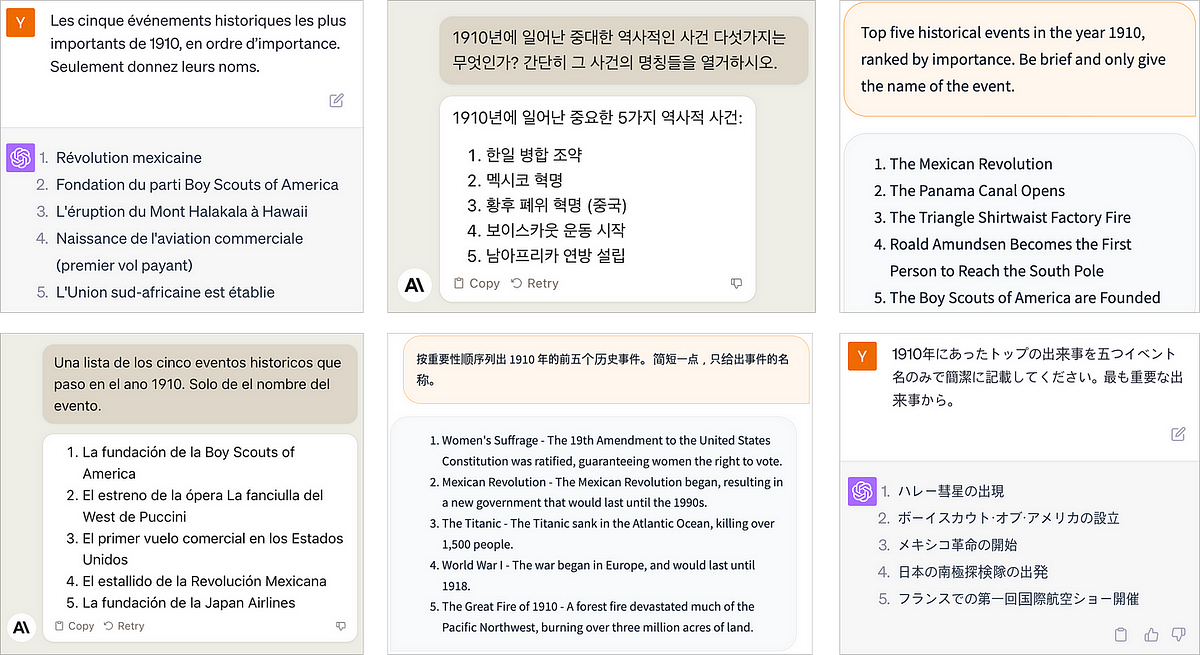
AIのレンズを通じた世界の歴史
人工知能の進歩、特に大規模な言語モデルにより、歴史研究や教育においては興奮すべき可能性が広がっていますしかし、その方法については慎重に検証することが重要です...

オリジナルのPDFのフォーマットを保持し、Amazon Textract、Amazon Translate、およびPDFBoxで翻訳されたドキュメントを表示します
様々な業界の企業は、大量のPDF文書を作成し、スキャンし、保存しています多くの場合、その内容はテキスト中心であり、別の言語で書かれているため、翻訳が必要ですこの問題に対処するためには、PDF内のコンテンツを自動的に抽出し、迅速かつ効率的に翻訳する自動化ソリューションが必要です多くの企業は多様な[…]

AIを活用した言語学習アプリの構築:2つのAIチャットからの学習
新しい言語を学び始めるときは、私は「会話ダイアログ」の本を買うのが好きです私はそのような本が非常に役立つと思っていますそれらは、言語がどのように動作するかを理解するのに役立ちます単に…

AIがYouTubeの多言語吹替を開始します
世界最大の動画共有プラットフォームであるYouTubeは、AI技術の統合により、コンテンツクリエイターが世界中の観客と接触する方法を革新することができる大きな進展を発表しました。GoogleのArea 120インキュベーターによって開発された「Aloudダビングサービス」の導入により、YouTubeは言語の壁を打ち破り、コンテンツクリエイターのグローバルな視聴者への到達範囲を拡大する重要な一歩を踏み出しています。このエキサイティングな発表は、オンラインビデオコミュニティの創造性と革新を祝うイベントであるVidConで行われました。 また、MetaのVoicebox: あらゆる言語を話すAI AIパワードダビングによる言語障壁の打破 YouTubeのミッションは、人々をつなぎ、情報やアイデアを自由に流れさせることです。これにより、AIパワードダビングサービスが開発されました。多様な観客と情熱を共有する際にコンテンツクリエイターが直面する課題を認識し、言語の壁を解消するために、YouTubeは積極的なアプローチを取っています。Aloudダビングサービスにより、クリエイターは異なる言語にシームレスに翻訳してダビングすることができ、母国語を超えた視聴者に到達することができます。 また、OpenAIを使用した言語翻訳 時間とコストの制約の克服 動画の高品質のダビングを作成することは常に時間とコストのかかる作業でした。コンテンツクリエイターは、ビデオの多言語バージョンを作成することに重大な課題を抱えており、グローバルな観客とのつながりを妨げています。しかし、YouTubeでAloudを統合することで、ゲームチェンジングな解決策が提供されます。ビデオの転記を行い、編集可能な転記を提供し、シームレスな翻訳とダビングプロセスを促進することにより、Aloudは時間とコストの障壁を排除します。クリエイターは、AIパワードサービスにダビングの複雑さを任せながら、情熱を共有することに集中することができます。 また、次世代音声ソリューションでビジネスを強化するトップ5のAI音声ジェネレーター グローバルな視聴者数の拡大と観客の拡大 AIパワードダビングの導入により、コンテンツクリエイターは視聴者数を拡大し、到達範囲を拡大する画期的な機会を得ることができます。以前は、言語の壁がクリエイターのグローバルなコンテンツ共有の能力を制限していました。しかし、Aloudにより、コンテンツクリエイターは新しい市場に進出し、世界中の視聴者と接触することができます。多言語ダビングを提供することにより、クリエイターは多様な観客とつながり、文化交流を促進し、グローバルスケールでの影響力を拡大することができます。 テストと将来の開発 YouTubeは、すでに何百ものクリエイターでAloudダビングツールを広範囲にテストしています。この徹底的な評価プロセスにより、テクノロジーがYouTubeプラットフォームにシームレスに統合されるように洗練され最適化されます。現在、Aloudは英語、スペイン語、ポルトガル語など、限られた数の言語をサポートしていますが、YouTubeは野心的な拡大計画を持っています。YouTubeの広報担当者であるジェシカ・ギビーによると、将来的にはさらに多くの言語がサービスに追加され、コンテンツクリエイターの到達範囲がさらに広がることになるでしょう。 また、AI時代のディープフェイクの検出と処理方法 ユーザー体験の向上:クリエイターの声とリップシンク YouTubeは、Aloudダビングサービスを含め、常にユーザー体験を向上させることに取り組んでいます。YouTubeのアムジャド・ハニフ氏はThe Vergeに対して声明を出し、翻訳されたオーディオトラックを強化するための取り組みを進めていることを明らかにしました。YouTubeは、ダビングをクリエイターの声に似せ、表情やリップシンクを改善することを目指しています。これらのエキサイティングな進展は、2024年にリリース予定であり、グローバルな視聴体験をより本格的かつ没入型にすることができます。 私たちの意見 YouTubeがAloudサービスを介してAIパワードダビングを導入したことで、コンテンツクリエイターは言語の壁を克服し、世界中の観客と情熱を共有することができるようになりました。AloudをYouTubeプラットフォームにシームレスに統合することで、クリエイターは複数の言語に翻訳してダビングすることができ、グローバルな視聴者数を拡大することができます。YouTubeが技術を洗練し、向上させ続けることで、将来的には言語がプラットフォーム上のアイデアやクリエイティブな自由な流れの障壁であることを保証し、視聴体験をより没入型にすることができます。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.