Learn more about Search Results アダプタ - Page 8

- You may be interested
- グリーンAI:AIの持続可能性を向上させる...
- 「Cheetorと会ってください:幅広い種類の...
- NexusRaven-V2をご紹介します:13B LLMは...
- 「2023年のACM-IEEE CSジョージ・マイケル...
- 「Google の CEO Sundar Pichai は AI を...
- 「GPT4の8つの小さなモデルはどのように機...
- 「Azureプロジェクト管理のナビゲーション...
- 経験がなくてもデータアナリストになる方法
- デジタルワーカーやAIエージェントのレベ...
- 「ゼロから効果的なデータ品質戦略を構築...
- 「Rust拡張機能でPythonコードを強化する」
- トヨタのAIにより、電気自動車の設計がよ...
- 「GPUのマスタリング:PythonでのGPUアク...
- 「国々がAIの悪影響に対処する世界的な競...
- 「データクリーニングと前処理の技術をマ...

「LLMのパラメータ効率的なファインチューニング(PEFT):包括的な紹介」
「パラメータ効率の高いファインチューニングガイドLoRa、LLaMA-Adapter、P-Tuning、プロンプト調整、プレフィックス調整、AdaLoRa、IA3、アダプター、ソフトプロンプトなどをカバーしています」

Pythonコード生成のためのLlama-2 7Bモデルのファインチューニング
約2週間前、生成AIの世界はMeta社が新しいLlama-2 AIモデルをリリースしたことによって驚かされましたその前身であるLlama-1は、LLM産業において画期的な存在であり、…
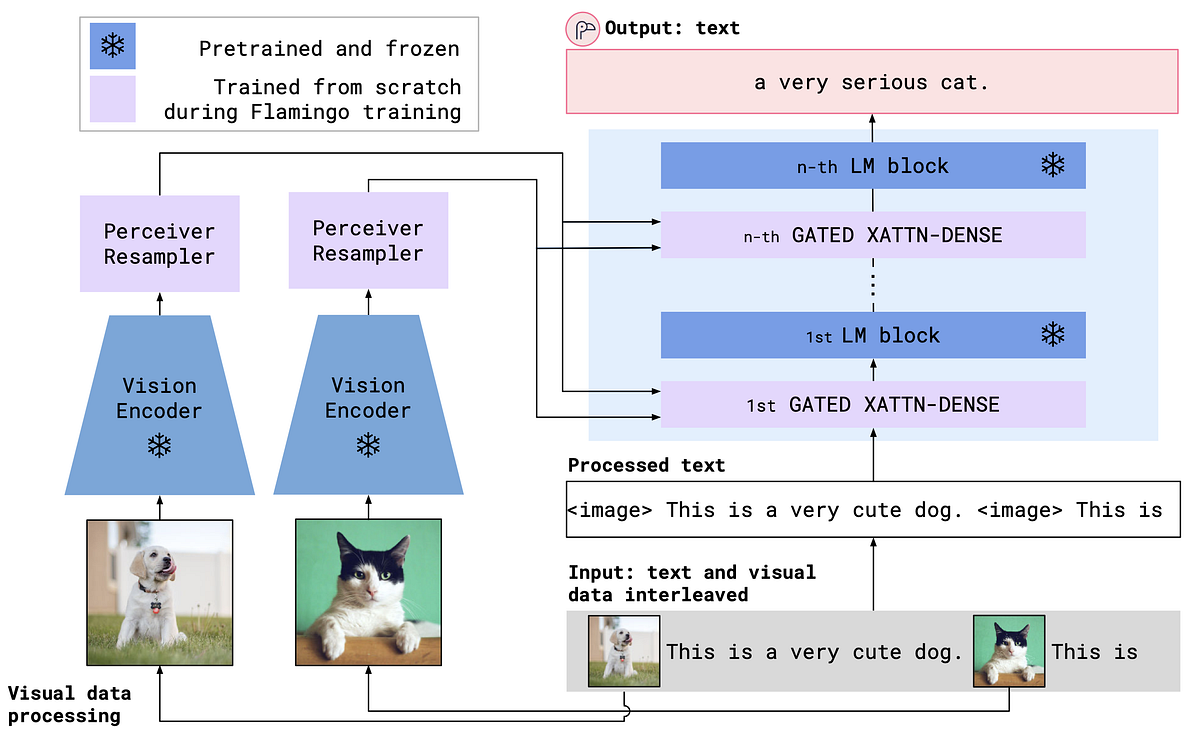
マルチモーダル言語モデルの解説:ビジュアル指示の調整
「LLMは、多くの自然言語タスクでゼロショット学習とフューショット学習の両方で有望な結果を示していますしかし、LLMは視覚的な推論を必要とするタスクにおいては不利です...」

マルチモーダル医療AI
Google ResearchのHealth AI部門の責任者であるGreg Corradoと、Engineering and ResearchのVPであるYossi Matiasによって投稿されました。 医学は本質的に多様なモダリティを持つ分野です。医療を提供する際、臨床医は医学画像、臨床ノート、検査結果、電子保健記録、ゲノミクスなど、さまざまなモダリティのデータを解釈することが日常的に行われます。過去10年ほどで、AIシステムは特定のタスクや特定のモダリティにおいて専門家レベルのパフォーマンスを達成してきました。CTスキャンを処理するAIシステム、高倍率の病理スライドを分析するAIシステム、希少な遺伝子の変異を探すAIシステムなどがあります。これらのシステムの入力は画像などの複雑なデータであり、通常は離散的なグレードや密な画像セグメンテーションマスクの形で構造化された出力を提供します。同時に、大規模言語モデル(LLM)の能力と機能は非常に高度になり、医学の知識を理解し、明瞭な言語で解釈および応答することを示しています。しかし、これらの能力を組み合わせてこれらの情報源から情報を利用する医療AIシステムを構築するにはどうすれば良いのでしょうか? 本日のブログ投稿では、LLMに多様なモダリティの能力をもたらすアプローチの範囲を概説し、最近の研究論文で示されている多様なモダリティの医療LLMの構築の実現可能性についての興味深い結果を共有します。これらの論文は、LLMに新たなモダリティを導入する方法、最先端の医学画像基盤モデルを会話型LLMに組み込む方法、そして真の汎用的な多様なモダリティの医療AIシステムの構築への初歩的な取り組みについて説明しています。成功すれば、多様なモダリティの医療LLMは、専門医療、医学研究、消費者向けアプリケーションを横断する新しい支援技術の基盤となる可能性があります。私たちの以前の研究と同様に、これらの技術を医療コミュニティや医療エコシステムとの協力による慎重な評価の必要性を強調します。 アプローチの範囲 最近の数ヶ月間には、多様なモダリティのLLMの構築に関するいくつかの手法が提案されています[1, 2, 3]。さらに新しい手法がしばらくの間続々と登場することでしょう。医療AIシステムに新しいモダリティをもたらす機会を理解するために、3つの広義に定義されたアプローチを考えてみましょう:ツールの利用、モデルの組み込み、汎用システム。 多様なモダリティのLLMを構築するアプローチの範囲は、LLMが既存のツールやモデルを使用することから、ドメイン固有のコンポーネントをアダプタとして利用すること、多様なモダリティのモデルを共同モデリングすることまで広がっています。 ツールの利用 ツールの利用のアプローチでは、中央の医療LLMは各タスクに最適化されたソフトウェアサブシステム(ツール)によるさまざまなモダリティのデータの解析を外部に委託します。ツールの利用の一般的な例は、LLMに計算を自身で行うのではなく、電卓を使用することを教えることです。医療の場合、胸部X線を処理する医療LLMは、その画像を放射線学AIシステムに転送し、その応答を統合することができます。これは、サブシステムが提供するアプリケーションプログラミングインターフェース(API)を介して行うこともできますし、より幻想的には、異なる専門分野を持つ2つの医療AIシステムが会話をすることもできます。 このアプローチにはいくつかの重要な利点があります。サブシステム間の最大の柔軟性と独立性が実現され、ヘルスシステムはサブシステムの検証されたパフォーマンス特性に基づいてテックプロバイダ間で製品を組み合わせることができます。さらに、サブシステム間の人間が読めるコミュニケーションチャネルは、監査可能性とデバッグ可能性を最大化します。ただし、独立したサブシステム間のコミュニケーションをうまく行うことは難しい場合があり、情報の伝達が狭まったり、誤ったコミュニケーションや情報の損失のリスクが発生する可能性があります。 モデルの組み込み より統合されたアプローチとして、各関連する領域に特化したニューラルネットワークを取り、それをLLMに直接組み込むことが考えられます。つまり、ビジュアルモデルを核となる推論エージェントに組み込むことです。ツールの利用とは異なり、モデルの組み込みでは、研究者は開発中に特定のモデルを使用、改良、または開発することができます。Google Researchの最近の2つの論文では、これが実現可能であることを示しています。ニューラルLLMは通常、テキストを最初に単語のベクトル埋め込み空間にマッピングすることでテキストを処理します。両論文は、新しいモダリティのデータを既にLLMに馴染みのある入力単語埋め込み空間にマッピングするというアイデアに基づいています。最初の論文「個別データに基づく健康な多様なモダリティのLLM」では、イギリスバイオバンクでの喘息リスク予測が改善されることを示しています。このために、まず、スパイログラム(呼吸能力を評価するために使用されるモダリティ)を解釈するためのニューラルネットワーク分類器を訓練し、そのネットワークの出力をLLMへの入力として適応させることで実現します。 2つ目の論文、「ELIXR: Towards a general…

「DPOを使用してLlama 2を微調整する」
はじめに 人間のフィードバックからの強化学習(RLHF)は、GPT-4やクロードなどのLLMの最終トレーニングステップとして採用され、言語モデルの出力が人間の期待に合致するようにするために使われます。しかし、これによってRLの複雑さがNLPにもたらされます。良い報酬関数を構築し、モデルに状態の価値を推定するように訓練し、同時に元のモデルからあまり逸脱せずに意味のあるテキストを生成するように注意する必要があります。このようなプロセスは非常に複雑で、正しく行うのは常に簡単ではありません。 最近の論文「Direct Preference Optimization」(Rafailov、Sharma、Mitchell他)では、既存の方法で使用されるRLベースの目的を、シンプルなバイナリクロスエントロピー損失を直接最適化できる目的に変換することを提案しており、これによりLLMの改善プロセスが大幅に簡素化されます。 このブログ記事では、TRLライブラリで利用可能なDirect Preference Optimization(DPO)メソッドを紹介し、さまざまなスタックエクスチェンジポータルの質問に対するランク付けされた回答を含むスタックエクスチェンジのデータセットで最近のLlama v2 7Bパラメータモデルを微調整する方法を示します。 DPO vs PPO 人間の派生した好みをRLを通じて最適化する従来のモデルでは、補助的な報酬モデルを使用し、興味のあるモデルを微調整して、この報酬をRLの仕組みを利用して最大化するようにします。直感的には、報酬モデルを使用して最適化するモデルにフィードバックを提供し、ハイリワードのサンプルをより頻繁に生成し、ローリワードのサンプルをより少なく生成するようにします。同時に、フリーズされた参照モデルを使用して、生成物があまり逸脱せずに生成の多様性を維持し続けるようにします。これは通常、参照モデルを介した全報酬最大化の目的にKLペナルティを追加することで行われ、モデルが報酬モデルをごまかしたり利用したりすることを防ぐ役割を果たします。 DPOの定式化は、報酬モデリングのステップをバイパスし、報酬関数から最適なRLポリシーへの解析的なマッピングを使用して、言語モデルを好みのデータに最適化します。このマッピングは、与えられた報酬関数が与えられた好みのデータとどれだけ合致するかを直感的に測定します。したがって、DPOはRLHFの損失の最適解から始まり、変数の変換を介して参照モデルに対する損失を導出することで、参照モデルのみに対する損失を得ることができます。 したがって、この直接的な尤度目的は、報酬モデルやポテンシャルに煩雑なRLベースの最適化を必要とせずに最適化することができます。 TRLのトレーニング方法 前述のように、通常、RLHFパイプラインは次の異なるパーツで構成されています: 教師あり微調整(SFT)ステップ データに好みのラベルを付けるプロセス 好みのデータで報酬モデルをトレーニングする そして、RL最適化ステップ TRLライブラリには、これらのパーツのためのヘルパーが付属していますが、DPOトレーニングでは報酬モデリングとRL(ステップ3と4)のタスクは必要ありません。代わりに、TRLのDPOTrainerにステップ2の好みのデータを提供する必要があります。このデータは非常に特定の形式を持ちます。具体的には、次の3つのキーを持つ辞書です: prompt:テキスト生成の際にモデルに与えられるコンテキストプロンプトです…

「GPTCacheとは:LLMクエリセマンティックキャッシュの開発に役立つライブラリを紹介します」
ChatGPTと大規模言語モデル(LLM)は非常に柔軟性があり、多くのプログラムの作成が可能です。ただし、LLM APIの呼び出しに関連するコストは、アプリケーションが人気を集め、トラフィック量が増加するときに重要になる可能性があります。多くのクエリを処理する場合、LLMサービスには長い待ち時間が生じることもあります。 この困難に立ち向かうために、研究者はGPTCacheというプロジェクトを開発しました。GPTCacheは、LLMの回答を格納するためのセマンティックキャッシュを作成することを目指しています。オープンソースのGPTCacheプログラムは、LLMの出力回答をキャッシュすることにより、LLMを高速化することができます。キャッシュにリクエストされた応答がすでに格納されている場合、それを取得する時間を大幅に短縮することができます。 GPTCacheは柔軟でシンプルであり、どのアプリケーションにも適しています。OpenAIのChatGPTなど、多くの言語学習機械(LLM)と互換性があります。 どのように動作するのか? GPTCacheは、LLMの最終的な応答をキャッシュします。キャッシュは、最近使用された情報を迅速に取得するために使用されるメモリバッファです。新しいリクエストがLLMに送信されるたびに、GPTCacheはまずキャッシュを調べて要求された応答が既にそこに格納されているかどうかを判断します。キャッシュ内で応答が見つかった場合、すぐに返されます。そうでない場合は、LLMが応答を生成してキャッシュに追加します。 GPTCacheのモジュラーアーキテクチャにより、カスタムのセマンティックキャッシュソリューションを簡単に実装することができます。ユーザーはさまざまな設定を選択することで、各モジュールとの経験をカスタマイズすることができます。 LLMアダプターは、さまざまなLLMモデルで使用されるAPIとリクエストプロトコルを統一し、それらをOpenAI APIで標準化します。LLMアダプターは、コードの書き直しや新しいAPIの理解を必要とせずにLLMモデル間を移動できるため、テストと実験を簡素化します。 埋め込み生成器は、要求されたモデルを使用して埋め込みを作成し、類似性検索を実行します。サポートされているモデルでは、OpenAIの埋め込みAPIを使用できます。これには、GPTCache/paraphrase-albert-onnxモデルを使用するONNX、Hugging Face埋め込みAPI、Cohere埋め込みAPI、fastText埋め込みAPI、SentenceTransformers埋め込みAPIが含まれます。 キャッシュストレージでは、ChatGPTなどのLLMからの応答が取得できるまで保持されます。2つのエンティティが意味的に類似しているかどうかを判断する際には、キャッシュされた応答が取得され、要求されたパーティーに送信されます。GPTCacheはさまざまなデータベース管理システムと互換性があります。ユーザーは、パフォーマンス、拡張性、および最も一般的にサポートされているデータベースのコストに関する要件を最も満たすデータベースを選択することができます。 ベクトルストアの選択肢:GPTCacheには、オリジナルのリクエストから派生した埋め込みを使用して、K個の最も類似したリクエストを特定するベクトルストアモジュールが含まれています。この機能を使用すると、2つのリクエストがどれだけ類似しているかを判断することができます。さらに、GPTCacheはMilvus、Zilliz Cloud、FAISSなどの複数のベクトルストアをサポートし、それらとの作業に対して簡単なインターフェースを提供します。ユーザーは、さまざまなベクトルストアオプションを選択できます。これらのオプションのいずれかが、GPTCacheの類似性検索のパフォーマンスに影響を与える可能性があります。さまざまなベクトルストアをサポートすることで、GPTCacheは適応性があり、さまざまなユースケースとユーザーの要件を満たすことができます。 GPTCacheキャッシュマネージャーは、キャッシュストレージとベクトルストアコンポーネントのエビクションポリシーを管理します。キャッシュが一杯になったときに新しいデータのためのスペースを作るために、置換ポリシーが古いデータを削除するかどうかを決定します。 類似性評価器の情報は、GPTCacheのキャッシュストレージとベクトルストアのセクションから取得されます。入力リクエストをベクトルストア内のリクエストと比較することで、類似度を測定します。リクエストがキャッシュから提供されるかどうかは、類似度の程度に依存します。GPTCacheは類似性アルゴリズムを使用してキャッシュの一致を判断する能力を持つため、さまざまなユースケースとユーザーの要件に適応することができます。 特徴と利点 GPTCacheによるLLMクエリの待ち時間の短縮により、応答性と速度が向上します。 トークンベースおよびリクエストベースの価格体系により、LLMサービスに共通のコスト削減が可能です。GPTCacheはAPIの呼び出し回数を制限することで、サービスのコストを削減することができます。 GPTCacheはLLMサービスからの作業をオフロードする能力を持つため、スケーラビリティが向上します。リクエスト数が増えるにつれて、ピークの効率で運営を続けるのに役立ちます。 GPTCacheの助けを借りて、LLMアプリケーションの作成に関連するコストを最小限に抑えることができます。LLMで生成されたデータをキャッシュしたり、模擬したりすることで、LLMサービスにAPIリクエストを行わずにアプリをテストすることができます。 GPTCacheは、選択したアプリケーション、LLM(ChatGPT)、キャッシュストア(SQLite、PostgreSQL、MySQL、MariaDB、SQL Server、またはOracle)、およびベクトルストア(FAISS、Milvus、Ziliz Cloud)と連携して使用することができます。GPTCacheプロジェクトの目標は、毎回ゼロから始めるのではなく、できる限り以前に生成された返信を再利用することによって、GPTベースのアプリケーションで言語モデルを最も効率的に活用することです。
「Amazon SageMakerを使用して、生成AIを使ってパーソナライズされたアバターを作成する」
生成AIは、エンターテイメント、広告、グラフィックデザインなど、さまざまな産業で創造プロセスを向上させ、加速させるための一般的なツールとなっていますそれにより、観客によりパーソナライズされた体験が可能となり、最終製品の全体的な品質も向上します生成AIの一つの重要な利点は、ユーザーに対してユニークでパーソナライズされた体験を作り出すことです例えば、[…]

「大規模言語モデルの微調整に関する包括的なガイド」
導入 過去数年間、自然言語処理(NLP)の領域は大きな変革を遂げてきました。それは大規模な言語モデルの登場によるものです。これらの高度なモデルにより、言語翻訳から感情分析、さらには知的なチャットボットの作成まで、幅広いアプリケーションの可能性が開かれました。 しかし、これらのモデルの特筆すべき点はその汎用性です。特定のタスクやドメインに対応するためにこれらを微調整することは、その真の可能性を引き出し、性能を向上させるための標準的な手法となりました。この包括的なガイドでは、基礎から高度な内容まで、大規模な言語モデルの微調整の世界について詳しく掘り下げます。 学習目標 大規模な言語モデルを特定のタスクに適応させるための微調整の概念と重要性を理解する。 マルチタスキング、指示微調整、パラメータ効率的な微調整など、高度な微調整技術を学ぶ。 微調整された言語モデルが産業界を革新する実際の応用例について実践的な知識を得る。 大規模な言語モデルの微調整のステップバイステップのプロセスを学ぶ。 効率的な微調整メカニズムの実装を行う。 標準的な微調整と指示微調整の違いを理解する。 この記事はData Science Blogathonの一部として公開されました。 事前学習済み言語モデルの理解 事前学習済み言語モデルは、通常インターネットから収集された膨大なテキストデータに対して訓練された大規模なニューラルネットワークです。訓練プロセスは、与えられた文やシーケンス内の欠損している単語やトークンを予測することで、モデルに文法、文脈、意味の深い理解を与えます。これらのモデルは数十億の文を処理することで、言語の微妙なニュアンスを把握することができます。 人気のある事前学習済み言語モデルの例には、BERT(Bidirectional Encoder Representations from Transformers)、GPT-3(Generative Pre-trained Transformer 3)、RoBERTa(A Robustly…

「QLORAとは:効率的なファインチューニング手法で、メモリ使用量を削減し、単一の48GB GPUで65Bパラメーターモデルをファインチューニングできるだけでなく、完全な16ビットのファインチューニングタスクのパフォーマンスも保持します」
大規模言語モデル(LLM)は、追加または削除したい振る舞いを設定することも可能にするファインチューニングによって改善することができます。しかし、大きなモデルのファインチューニングは非常に高コストです。例えば、LLaMA 65Bパラメータモデルを標準の16ビットモードでファインチューニングすると、780GB以上のGPU RAMを消費します。最新の量子化手法はLLMのメモリフットプリントを軽減することができますが、これらの手法は推論時にのみ機能し、トレーニング時には失敗します。ワシントン大学の研究者たちは、QLORAを開発しました。QLORAは、高精度なアルゴリズムを使用して事前学習モデルを4ビットの解像度に量子化し、量子化結果に対する勾配を逆伝播させることで変更した一連の学習可能な低ランクアダプターの重みを追加します。彼らは、量子化された4ビットモデルがパフォーマンスに影響を与えずに調整できることを初めて示しています。 QLORAによって、65Bパラメータモデルのファインチューニングの平均メモリ要件を、ランタイムや予測パフォーマンスを犠牲にすることなく、16ビットの完全にファインチューニングされたベースラインから780GB以上のGPU RAMから48GBに削減することができます。これにより、これまでに公開されている最大のモデルでも単一のGPUでファインチューニングすることが可能となり、LLMのファインチューニングのアクセシビリティに大きな変化がもたらされます。彼らはQLORAを使用してGuanacoモデルファミリーを訓練し、最大のモデルは単一のプロフェッショナルGPUで24時間以上かけて99.3%の成績を達成し、VicunaベンチマークでのChatGPTに迫る成果を上げました。2番目に優れたモデルは、単一のコンシューマGPUで12時間未満の時間で、VicunaベンチマークでChatGPTのパフォーマンスレベルの97.8%に達します。 QLORAの以下の技術は、パフォーマンスを損なうことなくメモリ使用量を低減することを目的としています:(1) 4ビットNormalFloat、正規分布データのための量子化データ型であり、情報理論的に最適であり、4ビットの整数と4ビットの浮動小数点よりも優れた経験的な結果を生み出します。(2) ダブル量子化は、平均してパラメータごとに0.37ビット(または65Bモデルの約3GB)を節約し、量子化定数を量子化します。(3) ページドオプティマイザは、長いシーケンスを処理する際に勾配チェックポイントによるメモリスパイクを防ぐために、NVIDIA統一メモリを使用します。使用すると、最小のGuanacoモデル(7Bパラメータ)は、Vicunaテストで26GBのAlpacaモデルを20パーセント以上上回る性能を発揮しながら、5GB未満のメモリを使用します。 彼らはこれらの貢献をより洗練されたLoRA戦略に組み込み、以前の研究で特定された精度のトレードオフをほぼなくすようにしました。QLORAの効率性により、メモリコストのために従来のファインチューニングではできなかったモデルサイズに関する指示ファインチューニングとチャットボットのパフォーマンスをより詳細に分析することができます。その結果、彼らは80Mから65Bまでの様々な指示チューニングデータセット、モデルトポロジ、パラメータ値を使用して、1000以上のモデルをトレーニングしました。QLORAは16ビットのパフォーマンスを回復し、Guanacoという高度なチャットボットをトレーニングし、学習されたモデルのパターンを調査しました。 まず、両方が汎化後の指示を提供することを目的としているにもかかわらず、チャットボットのパフォーマンスでは、データの品質がデータセットのサイズよりもはるかに重要であることを発見しました。9kサンプルのデータセット(OASST1)は、チャットボットのパフォーマンスで450kサンプルのデータセット(FLAN v2、サブサンプリング)を上回ります。第二に、優れたMassive Multitask Language Understanding(MMLU)ベンチマークのパフォーマンスが必ずしも優れたVicunaチャットボットベンチマークのパフォーマンスにつながるわけではないこと、そしてその逆もまた同様であることを示しています。言い換えれば、特定のタスクにおいては、データセットの適切さがスケールよりも重要です。彼らはまた、人間の評価者とGPT-4を使用してチャットボットのパフォーマンスを詳細に評価しています。 モデルは、与えられた刺激に対する最適な応答を決定するために、トーナメント形式のベンチマークマッチで互いに競い合います。GPT-4または人間の注釈者がゲームの勝者を決定します。トーナメントの中でのモデルのパフォーマンスのランク付けには、GPT-4と人間の判断がほぼ一致することがわかりましたが、明確な相違点もあります。そのため、彼らはモデルベースの評価が不確実性を持つ一方で、人間の注釈よりも費用が抑えられるという事実に注意を喚起しています。 彼らはチャットボットのベンチマーク調査結果にグアナコモデルの質的分析を追加します。彼らの研究では、定量的な基準では考慮されなかった成功と失敗のインスタンスを特定します。彼らはGPT-4および人間のコメントを含むすべてのモデル世代を公開し、将来の研究を支援します。彼らは自分たちの技術をHugging Face transformersスタックに組み込み、ソフトウェアおよびCUDAカーネルをオープンソース化し、広く利用可能にします。32の異なるオープンソース化された改良モデルについて、サイズ7/13/33/65Bのモデルに8つの異なる命令従属データセットでトレーニングを行ったアダプターのコレクションを提供します。コードリポジトリは公開され、Colabでホストできるデモも提供されます。

「Keras 3.0 すべてを知るために必要なこと」
「Keras 3.0でAIの協力力を解放しましょう!TensorFlow、JAX、PyTorchの間をシームレスに切り替え、深層学習プロジェクトを革新しましょう今すぐ読んで、AIの世界で先を行きましょう」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.