Learn more about Search Results これ - Page 8

- You may be interested
- ファルコン:オープンソースLLMの頂点
- 「プライバシーの懸念と激化する競争の中...
- 「CLAMPに会ってください:推論時に新しい...
- LLMsにおけるブラックボックスの問題:課...
- WAYVE社がGAIA-1を発表:ビデオ、テキスト...
- 事前訓練された視覚表現は、長期的なマニ...
- 「Azure Machine Learningによる機械学習...
- 「AWSに基づいたカスケーディングデータパ...
- 「FourCastNet(フォーキャストネット)と...
- 「TikTokがAI生成コンテンツのためのAIラ...
- 「Amazon SageMaker JumpStart、Llama 2、...
- 「NeurIPS 2023のハイライトと貢献」
- dtreevizを使用して、信じられないほどの...
- バイトダンスとUCSDの研究者は、与えられ...
- 「コンテナ化されたモデルとワークロード...

メタAIは、「Code Llama」という最先端の大規模言語モデルをリリースしましたこれはコーディングのためのものです
ソフトウェア開発の絶えず進化する景色において、効率的で生産的なコーディングツールの必要性はこれまでになく大きくなっています。開発者は、堅牢でよく文書化されたコードを書きながら、デバッグやコード補完の複雑さを乗り越えるという課題に直面しています。コードベースがより複雑になるにつれて、これらの課題に対する革新的な解決策を見つけることが重要となります。伝統的なコーディングツールや手法は有用ですが、現代のソフトウェア開発の要求に対して時には不十分な場合があります。 既存のコーディングツールやフレームワークは、コードの提案や補完を提供する統合開発環境(IDE)から、プロンプトに基づいてコードスニペットを生成できるコード固有の言語モデル(LM)まで、プログラマに貴重なサポートを提供してきました。しかし、これらのツールは、精度、効率、包括性の面で制約があることがしばしばあります。現代のコーディングタスクの複雑さは、自然言語の指示と複雑なコードロジックの両方を理解できるより高度なアプローチを必要とします。 Meta AIによるコーディングのための生成AIの画期的な進歩であるCode Llamaに出会ってください。Code Llamaは、最新のLlama 2モデルをコード固有のデータセットでさらにトレーニングすることで開発され、自然言語の指示と複雑なコード生成とのギャップを埋めます。生産性を向上させ、コーディングの支援を提供する潜在能力を持つCode Llamaは、あらゆるスキルレベルの開発者にとって画期的な存在となります。 Code Llamaは、さまざまなコーディングニーズに対応する多機能なツールです。コードスニペットを生成したり、コードに関する自然言語の説明をしたり、コード補完をサポートしたり、デバッグタスクを支援したりすることができます。Python、C++、Javaなどの人気のあるプログラミング言語をサポートするCode Llamaは、幅広いコーディングシナリオに対応しています。 Code Llamaの注目すべき特徴の1つは、より長い入力シーケンスで動作する能力です。これにより、開発者はコードベースからより多くのコンテキストを提供することができます。これにより、関連性の高い正確なコード生成が可能となり、特に大規模なコードベース内の複雑な問題のデバッグに価値があります。 Code Llamaの効果を評価するために、人気のあるコーディングチャレンジを使用した広範なベンチマークテストが行われました。Code Llamaのパフォーマンスは、オープンソースのコード固有の言語モデルとその前身であるLlama 2と比較されました。その結果、Code Llamaの34Bバリアントは、HumanEvalやMostly Basic Python Programming(MBPP)などのコーディングベンチマークで高いスコアを獲得しました。これらのスコアは既存のソリューションを上回り、広く認識されているAIモデルに対する競争力を示しました。 コーディングツールの景色において、Code Llamaはタスクへのアプローチの仕方を変える可能性を持つ画期的なツールとして際立っています。オープンかつコミュニティ主導のアプローチを提供することで、Code Llamaは革新を促進し、責任ある安全なAI開発プラクティスを奨励します。…

メタAIは、SeamlessM4Tを発表しましたこれは、音声とテキストの両方でシームレスに翻訳と転写を行うための基盤となる多言語・マルチタスクモデルです
相互作用がますますグローバル化する世界において、多言語を話すことは隔たりを埋め、理解を促進し、様々な機会の扉を開くことができます。複数の言語を学ぶことは、言語の構造や言語学に対する洞察を提供し、コミュニケーションと思考のメカニズムに対する理解を深めることができます。これは特に、異文化間の相互作用が一般的な今日のグローバル化された世界で特に貴重です。人間とAIの間でもこの橋が埋まる必要があると思いませんか? MetaAIとUC Berkleyの研究者たちは、音声とテキストの間でシームレスに翻訳と転写を行う基礎的な多言語およびマルチタスクモデルを提案しています。彼らはそれを「SeamlessM4T」と呼んでいます。名前のM4Tは、Massively Multilingual and Multimodal Machine Translationを表しています。これは、100言語までの音声からテキスト、音声から音声、テキストから音声、テキストからテキストへの翻訳、および自動音声認識を備えたAIモデルです。 Babel Fish(オンライン翻訳サービス)を知らない人はいませんよね?それにはどんな問題があるのでしょうか?Babel Fishは音声から音声への翻訳システムです。このような種類のさまざまな既存のシステムは、英語、スペイン語、フランス語など、高リソースの言語に焦点を当てる傾向があり、多くの低リソースの言語を後回しにしています。彼らのサービスは主に英語から他の言語への翻訳であり、逆の場合はほとんどありません。これらのシステムは、複数のサブシステムから構成されるカスケードシステムに依存しているため、性能がカスケードと比較して追いついていないのです。 これらの制限を解消するために、研究者たちは100万時間以上のオープンスピーチオーディオデータを使用してセルフスーパーバイズドスピーチを学習しました。彼らは470,000時間以上の自動的に整列した音声翻訳のマルチモーダルコーパスを作成しました!背景ノイズと話者に対するモデルの堅牢性を評価するために、彼らは堅牢性のベンチマークを作成し、それぞれ38%と49%の改善を見つけました。 研究者たちは、安全で堅牢なパフォーマンスを確保するために、ワークフロー全体でシステムの体系的な評価を維持しました。彼らはクローズドデータの使用に代わる並行データマイニングを使用しました。この方法は、さまざまな言語の文を固定サイズの埋め込み空間にエンコードし、類似度メトリックに基づいて並行インスタンスを見つけることを含みます。 テキストと音声の翻訳に関わるすべてのタスクを処理できる統一された大規模モデルを作成することは、次世代のデバイス内およびオンデマンドのマルチモーダル翻訳の重要な基盤を築きます。彼らは、この理念を主に念頭に置いて言語技術が開発されると、世界の半数の人々のニーズが解決され、高リソースと低リソースの言語を話す人々の間のギャップを埋めるために世界をリードする方向に進むと述べています。 研究者たちは、SeamlessM4Tのパフォーマンスがスラングや固有名詞の翻訳において高リソースと低リソースの言語間でより一貫性が必要かもしれないと述べています。彼らの将来の仕事は、母国語とスラングに基づいたより友好的で穏やかな会話を実現するために、この制限を解消することです。

コーネル大学の研究者たちは、不連続処理を伴う量子化(QuIP)を導入しましたこれは、量子化が不連続な重みとヘシアン行列から利益を得るという洞察に基づく新しいAIの手法です
大規模言語モデル(LLM)によって、テキスト作成、フューショット学習、推論、タンパク質配列モデリングなどの領域で改善が可能になりました。これらのモデルは数百億のパラメータを持つことがあり、複雑な展開戦略が必要となり、効率的な推論技術の研究を促しています。 コーネル大学の新しい研究では、LLMのパラメータをトレーニング後に量子化して実世界のシナリオでのパフォーマンスを向上させています。彼らの重要な洞察は、重みとプロキシヘシアン行列が非整合的な場合に、重みを有限の圧縮された値のセットに適応的に丸めることが容易であるということです。直感的には、重み自体と良好な丸めの精度を持つことが重要な方向は、どの座標でもあまり大きくないためです。 この洞察を利用して、研究者たちは理論的に妥当でありLLMサイズのモデルにも拡張可能な2ビットの量子化技術を作成しました。この洞察に基づいて、彼らは量子化と非整合処理(QuIP)と呼ばれる新しい技術を提供しています。 QuIPには2つのフェーズがあります: 効率的な事前処理と事後処理により、ヘシアン行列がランダムな直交行列のクロネッカー積によって非整合的になることを保証します。 推定ヘシアンを使用して、元の重みと量子化された重みの間の誤差の二次プロキシ目的関数を最小化する適応的な丸め手順です。 “非整合処理”は、提案手法の初期処理フェーズと最終処理フェーズの両方を指します。 実装の実用性に加えて、彼らはLLMサイズのモデルにスケーリングする量子化アルゴリズムのための初めての理論的研究を提供し、非整合性の影響を調査し、量子化手法が広範な丸め技術よりも優れていることを示しています。この研究では、QuIPによる非整合処理を行わない場合にOPTQという以前の技術のより効率的な実装が得られることも示しています。 実験結果は、非整合処理が大規模モデルの量子化を有意に向上させ、特に高い圧縮率で優れた結果をもたらし、重みごとに2ビットのみを使用するLLM量子化手法の実現を示しています。大規模なLLMサイズ(>2Bパラメータ)では2ビットと4ビットの圧縮間に小さなギャップが観察され、モデルサイズが大きくなるにつれてこれらのギャップはさらに縮小され、LLMで正確な2ビットの推論が可能性があることを示唆しています。 プロキシ目的関数では、トランスフォーマーブロック間、またはブロック内のレイヤー間の相互作用は考慮されていません。チームは、このスケールでこのような相互作用を含める利点と、それにかかる計算量の価値が現在わかっていないと述べています。

「忙しい?これが拡散モデルのブラックボックスを開くためのクイックガイドです」
DALL-E、Midjourney、Stability AI安定した拡散モデル:その動作方法、新しい画像の生成、トレーニング方法、および与えられたコンテキスト(テキスト)による制御方法

「Tabnine」は、ベータ版のエンタープライズグレードのコード中心のチャットアプリケーション「Tabnine Chat」を導入しましたこれにより、開発者は自然言語を使用してTabnineのAIモデルと対話することができます
I had trouble accessing your link so I’m going to try to continue without it. Tabnineは、そのベータ版であるTabnineチャットを含む、AIパワードのコード補完ツールに新機能を発表しました。これは、開発者の統合開発環境(IDE)とシームレスに統合できるエンタープライズグレードのコード中心のアプリケーションです。このアプリケーションは、説明可能な既存のコードの使用、コードリポジトリの検索、自然言語の仕様に基づいた新しいコードの生成などの機能を拡張します。Tabnineチャットの主なハイライトの1つは、セキュリティとコンプライアンスへの強い焦点です。 この機能は、さまざまなエンタープライズの要件に対応し、プライベートなコードベース、許可されたオープンソースコード、およびスタックオーバーフローのクエリを保護します。モデルは許可されたライセンスのオープンソースコードのみでトレーニングされており、コードベース情報に関する懸念が排除されています。Tabnineチャットのフロントエンドは、Reactアプリケーションであり、現在はVSコードとJetBrains IDEで利用可能であり、すべてのプログラミング言語をサポートしています。 いくつかの特徴がその重要性を強調しています: セキュリティとコンプライアンス:Tabnine環境は、コードのプライバシーとセキュリティを確保します。仮想プライベートクラウドまたはオンプレミスのセットアップを使用した分離された展開環境を容易にし、安全性と機密性を優先します。 コンテキストの統合:TabnineチャットはIDE内で動作するため、開発者の進行中のコードと統合します。 リポジトリの統合:Tabnineエンタープライズユーザーは、このアプリケーションにリポジトリをリンクすることができます。内部API、ライブラリ、およびサービスの大規模なセットを持つ組織は、内部リポジトリをTabnineチャットに接続することで生産性を向上させることができます。 Tabnineチャットのベータフェーズの到来により、開発者はコーディングの変革の最中にいます。開発者とコードの間でシームレスな会話を実現するパイオニアとして、Tabnineチャットが際立っています。近い将来、Tabnineエンタープライズおよびプロユーザーへのさらなる拡大により、高度なコーディングインタラクションに対する興奮が生まれます。

AI生成コンテンツ:クリエイターにとってこれは何を意味するのか?
「ジェネレーティブAIはコンテンツクリエイターにどのような影響を与えるのか?AIによる生成コンテンツの限界、課題、および法律について調査してください」

PlayHTチームは、感情の概念を持つAIモデルをGenerative Voice AIに導入しますこれにより、特定の感情で話しの生成を制御し、指示することができるようになります
I had trouble accessing your link so I’m going to try to continue without it. 音声認識は、自然言語処理(NLP)の領域で最近開発された技術の一つです。研究者たちは、テキストから音声を生成するための大規模な言語モデルも開発しました。AIは、声の品質、表現、人間の行動など、さまざまな面で人間と同等の結果を達成できることが非常に明確になりました。しかし、これらのモデルにはいくつかの問題がありました。これらのモデルは言語の多様性が少なかったです。音声認識、感情などにも問題がありました。多くの研究者がこれらの問題に気付き、これらはモデルに使用された小さなデータセットに起因することがわかりました。 改善が始まり、PlayHTチームはこのケーススタディの解決策としてPlayHT2.0を導入しました。このモデルの主な利点は、複数の言語を使用し、大量のデータセットを処理することでした。また、このモデルを使用することでモデルのサイズも増加しました。NLPのトランスフォーマーもこのモデルの実装に重要な役割を果たしました。モデルは与えられたトランスクリプトを処理し、音を予測します。これはトークン化と呼ばれるテキストから音声への変換プロセスを経ます。これにより、簡略化されたコードが音波に変換され、人間の音声が生成されます。 このモデルは非常に高い会話能力を持ち、いくつかの感情を持った通常の人間との会話ができます。AIチャットボットを介したこれらの技術は、多くの多国籍企業がオンライン通話やセミナーで使用しています。PlayHT2.0モデルは、それに使用される最適化技術により音声の品質も向上させました。また、元の声を再現することもできます。モデルに使用されるデータセットが非常に大きいため、モデルは元の言語を保持しながら他の言語も話すことができます。モデルのトレーニングプロセスは、多数のエポックとさまざまなハイパーパラメータを使用して行われました。これにより、モデルは音声認識技術においてさまざまな感情を表現するようになりました。 このモデルはまだ進行中であり、さらなる改善が行われる予定です。研究者たちはまだ感情の改善に取り組んでいます。プロンプトエンジニアや多くの研究者も、モデルが今後の数週間で速度、正確性、良いF1スコアの面で更新される可能性があることを発見しました。

「これまでに見たことのない新しいコンセプトをどのように生成できるのか?テルアビブ大学の研究者たちは、ConceptLabという名前の新しいアイデア生成手法を提案していますこれは拡散事前制約を用いた創造的な生成手法です」
人工知能の分野における最近の進展は、さまざまなユースケースに対する解決策をもたらしています。異なるテキストから画像を生成するモデルは、書かれた言葉を鮮やかで没入感のある視覚的表現に変換する新しい興味深い分野を築き上げています。新しい状況で独自のアイデアを概念化する能力は、パーソナライゼーション技術の爆発的な進化によってさらに拡大されています。創造的な行動をシミュレートするアルゴリズムや人間の創造的プロセスを向上・拡張することを目指すアルゴリズムがいくつか開発されています。 研究者たちはこれらの技術を使用して、完全に独自かつ革新的な概念をどのように創造できるかを調査しています。そのために、最近の研究論文では、研究チームが創造的なテキストから画像を生成する分野においてConcept Labを紹介しました。この分野における基本的な目標は、広範なカテゴリに属する新鮮な例を提供することです。私たちが慣れ親しんだすべての品種とは根本的に異なる新しいペットの品種を開発するという課題を考えると、Diffusion Priorモデルの領域がこの研究の主要なツールです。 このアプローチは、トークンベースのパーソナライゼーションからインスピレーションを得ています。トークンを使用してユニークな概念を表現するために、事前にトレーニングされた生成モデルのテキストエンコーダを使用します。意図した対象の以前の写真が存在しないため、新しい概念を作成するのは従来の逆像技術を使用するよりも困難です。このために、CLIPビジョン言語モデルが最適化プロセスを指示するために使用されています。制約にはプラス面とマイナス面があります。マイナスの制約は、生成が逸脱すべきカテゴリの既存のメンバーをカバーし、プラスの制約は広範なカテゴリに合致する画像の開発を促進します。 著者たちは、本当に独自のコンテンツを作成する難しさを拡散優先の出力空間上で効果的に表現できることを示しています。最適化プロセスは、彼らが「プライオリ制約」と呼ぶものによって結果を生み出します。研究者たちは、既存のカテゴリのメンバーに収束するだけではないように生成された概念が進化することを保証するために、質問応答モデルをフレームワークに組み込んでいます。この適応モデルは、繰り返し新しい制約を追加することによって最適化プロセスに重要な役割を果たします。 これらの追加の制約は、最適化プロセスを導き、ますますユニークで特異な発明を見つけるように促します。このシステムの適応性の高さにより、モデルは創造的な限界に挑戦するように推進されるため、想像力の未知の領域を徐々に探索します。著者たちは、提案された以前の制約の適応可能性にも重点を置いています。これらは、単独で独自の概念を作成しやすくするだけでなく、強力なミキシングメカニズムとして機能します。概念をミックスする能力により、生成された概念の創造的な融合であるハイブリッドを作成することができます。この追加の適応性の度合いは、創造的なプロセスを向上させ、より興味深く多様な結果を生み出します。 結論として、この研究の主な目標は、現代のテキストから画像を生成するモデルと、研究が不足しているDiffusion Priorモデル、および質問応答モデルによって駆動される適応的な制約拡張メカニズムを組み合わせて、独自で目を引くコンテンツを生成し、創造的な空間の柔軟な探索を促進する徹底的な戦略を開発することです。

OpenAIは、GPTBotを導入しましたこれは、インターネット全体からデータを自動的にスクレイピングするために設計されたウェブクローラです
OpenAIは、公開ウェブサイトでのデータ収集に起因するプライバシーや知的財産権の懸念に対応するため、GPTBotと呼ばれる新しいウェブクローラーツールを導入しました。この技術は、公開ウェブデータを透明に収集し、OpenAIの規範の下でAIモデルのトレーニングに活用することを目指しています。 GPTBotのユーザーエージェントは、将来のAIモデルの精度向上に貢献するデータを集めることを目指しています。このプロセスでは、支払いが必要なソースは除外されます。ただし、収集されたデータには誤って識別可能な情報やテキストが含まれる場合があり、OpenAIのポリシーに違反する可能性があることに注意が必要です。 OpenAIは、GPTBotのプラットフォームアクセスに関するウェブサイト管理者への選択肢を提供する必要性を認識しています。アクセスの許可は、AIモデルの精度向上における協力と見なされ、最終的にはその能力を向上させ、セキュリティ対策を強化します。一方で、GPTBotのデータ収集の対象としたくないウェブサイトを含めない選択肢を望む人々のために、OpenAIはGPTBotのディレクティブをウェブサイトのrobots.txtファイルに組み込み、特定のコンテンツセグメントへのアクセスを設定する手順を示しています。 OpenAIは、透明性を高めるためにGPTBotの活動に関連するIPアドレス範囲を公開しました。この公開は、ボットのアクションを特定するだけでなく、必要な場合にはアクセスをブロックする手段も提供します。 これらの透明性の取り組みは、明示的な同意なしにデータを収集すると非難されたAIモデルの運営者に対するOpenAIの対応を強調しています。業界の実践が公開ウェブサイトからのコンテンツを適切な承認なしに収集することで、知的財産権やプライバシー保護に対する侵害の可能性があるとする一般的な感情が広がり、AIエンティティにより包括的なオプトインおよびオプトアウトのメカニズムを提供するよう求める声が上がっています。 関連の進展として、クラウドファンディングプラットフォームのKickstarterは最近、AIプロジェクトに関する規制を導入しました。これらの規制の中で、外部データソースを活用するプロジェクトは、適切なライセンス契約とソースウェブサイトからの同意の証拠を提供することを義務付けられています。この義務を果たさないプロジェクトは、Kickstarterのリストに掲載される資格がありません。 今週中に、OpenAIは重要な改革を行う予定であり、基盤となるChatGPTレイヤーをGPT-4に移行することが予想されています。さらに、Code Interpreterプラグインの改良では、複数のファイルをプロンプトにアップロードするサポートが追加され、OpenAIの持続的な改善とイノベーションへの取り組みが反映されます。
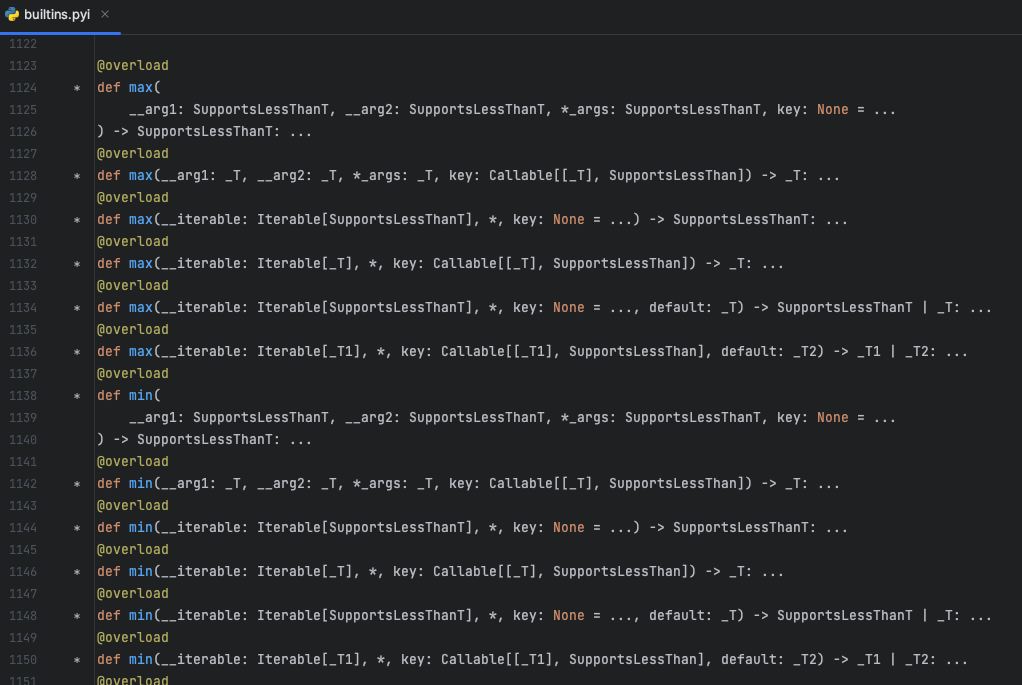
「Pythonデコレーターは開発者のエクスペリエンスをスーパーチャージします🚀」
Pythonの@overloadデコレータは、Pythonの組み込みモジュールであるtypingで見つけることができますこのデコレータは、開発者が関数やメソッドに複数のタイプ固有のシグネチャを指定することを可能にしますこれにより、…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.