Learn more about Search Results - Page 8

- You may be interested
- 不均衡データに対する回帰のための機械学習
- アラウカナXAI:医療における意思決定木を...
- 「NVIDIAスタジオ」で美しく写実的なフー...
- 「2023年におけるトレーニング・テスト・...
- 「SUSTech VIP研究室が、高性能なインタラ...
- 「アラン・チューリングとネガティブ思考...
- 「メールの生産性を革新する:SaneBoxのAI...
- Amazon SageMakerで@remoteデコレータを使...
- ZenMLとStreamlitを使用した従業員離職率予測
- H1Bビザはデータ分析の洞察に基づいて承認...
- 「PepCNNという名のディープラーニングツ...
- 大規模な言語モデルについて企業が知って...
- 「開発者向けのAIツール15個(2023年8月)」
- DPT(Depth Prediction Transformers)を...
- このAIニュースレターはあなたが必要なす...

「AIを活用してより良い世界を実現する」
AIを誤った方法で使用する例はたくさんあり、考えさせられる書籍『Weapons of Math Destruction』でも強調されていますまた、AIのリスクは過小評価してはなりませんAIの倫理と…

「TRLを介してDDPOを使用して、安定したディフュージョンモデルを微調整する」
導入 拡散モデル(例:DALL-E 2、Stable Diffusion)は、特に写真のような写真のリアルな画像を生成することで広く成功している生成モデルの一種です。ただし、これらのモデルによって生成される画像は常に人間の好みや意図と一致しているわけではありません。これが整合性の問題が生じます。つまり、「品質」といった人間の好みやプロンプトを介しては表現しにくい意図との整合性がモデルの出力と一致していることを確認する方法は何でしょうか?そこで、強化学習が登場します。 大規模言語モデル(LLM)の世界では、強化学習(RL)はモデルを人間の好みに合わせるための非常に効果的なツールとして証明されています。それはChatGPTのようなシステムが優れたパフォーマンスを発揮するための主要なレシピの一つです。より具体的には、ChatGPTが人間のようにチャットするためのReinforcement Learning from Human Feedback(RLHF)の重要な要素です。 Blackらは、「Training Diffusion Models with Reinforcement Learning, Black」という論文で、拡散モデルをRLを活用して目的関数に対して微調整する方法を示しています。これはDenoising Diffusion Policy Optimization(DDPO)と呼ばれる手法を使用します。 このブログ記事では、DDPOが生まれた経緯、その動作方法の簡単な説明、およびRLHFワークフローにDDPOを組み込んで人間の美意識により整合したモデルの出力を達成する方法について説明します。そして、新たに統合されたDDPOTrainerとtrlライブラリを使用してモデルにDDPOを適用する方法について、Stable Diffusionでの実行結果を検討します。 DDPOの利点 DDPOは、RLを使用して拡散モデルを微調整する方法に関する唯一の有効な回答ではありません。 入る前に、他のRLソリューションとの利点の理解に関して覚えておくべき2つの重要なポイントがあります。…

シナプスCoR:革命的なアレンジでのChatGPT
新しいシステムプロンプトについて学び、カスタムの指示と併用して使用することで、ChatGPTをAutoGPTに変える方法を学びましょう

多種多様なロボットタイプ間での学習のスケーリングアップ
私たちは、様々なロボットタイプや具現化における総合ロボット学習のための新しいリソースセットをリリースします34の学術研究所のパートナーと共に、22種類の異なるロボットタイプのデータをまとめ集め、オープンなX-具現化データセットを作成しましたまた、RT-1から派生したロボティクストランスフォーマー(RT)モデルであるRT-1-Xもリリースしますこのモデルは、私たちのデータセットで訓練され、多くのロボット具現化間でスキルの移転を示します

実験、モデルのトレーニングおよび評価:AWS SageMakerを使用して6つの主要なMLOpsの質問を探求する
今回の記事は、'31の質問がフォーチュン500のML戦略を形作る' AWS SageMakerシリーズの一部です以前のブログ投稿「データの入手と調査」と「データ...」

「OpenAIキーなしでPDFおよび記事のための強力なチャットアシスタントを作成する」
イントロダクション 自然言語処理の世界は、特に大規模な言語モデルの登場により、膨大な拡大を遂げています。これらのモデルは、この分野を革新し、誰でも利用できるようにしました。この記事では、オープンソースライブラリを使用して、与えられた記事(またはPDF)を基に質問に応答できる強力なチャットアシスタントを作成するためのNLP(自然言語処理)のテクニックを探求し、実装していきます。OpenAIのAPIキーは必要ありません。 この記事は、データサイエンスブログマラソンの一環として公開されています。 ワークフロー このアプリケーションのワークフローは以下の通りです: ユーザーは、PDFファイルまたは記事のURLを提供し、質問を行います。このアプリケーションは、提供されたソースに基づいて質問に答えることを試みます。 私たちは、PYPDF2ライブラリ(PDFファイルの場合)またはBeautifulSoup(記事のURLの場合)を使用してコンテンツを抽出します。次に、langchainライブラリのCharacterTextSplitterを使用して、それをチャンクに分割します。 各チャンクに対して、all-MiniLM-L6-v2モデルを使用して、対応する単語埋め込みベクトルを計算します。このモデルは、文章や段落を384次元の密なベクトル空間にマッピングするためのものです(単語埋め込みは、単語/文章をベクトルとして表現する技術の一つです)。同じ技術がユーザーの質問にも適用されます。 これらのベクトルは、sentence_transformersというPythonのフレームワークが提供する意味的検索関数に入力されます。sentence_transformersは、最先端の文、テキスト、画像埋め込みを行うためのフレームワークです。 この関数は、答えを含む可能性があるテキストチャンクを返し、質問応答モデルは、semantic_searchとユーザーの質問の出力に基づいて最終的な答えを生成します。 注意 すべてのモデルは、HTTPリクエストのみを使用してAPI経由でアクセス可能です。 コードはPythonを使用して書かれます。 FAQ-QNは、より詳細な情報についてはFAQセクションを参照することを示すキーワードです。 実装 このセクションでは、実装についてのみに焦点を当て、詳細はFAQセクションで提供されます。 依存関係 依存関係をダウンロードし、それらをインポートすることから始めます。 pip install -r requirements.txt numpytorchsentence-transformersrequestslangchainbeautifulsoup4PyPDF2 import…

「Juliaプログラミング言語の探求 ユニットテスト」
エンドツーエンドの機械学習プロジェクトを開発するためのJuliaプログラミング言語の探索シリーズへようこそ👋今回はユニットテストについて詳しく見ていきますユニットテストは重要な役割を果たします...

プログラム合成 – コードが自己書きすることを実現する
「プログラム合成」という言葉を聞いたことはあるかもしれませんが、完全に理解していないかもしれませんこれは、しばしばAIがコードを作成するための試みとして捉えられますこの記事は、これを解明するために設計された3部作の最初の記事です...
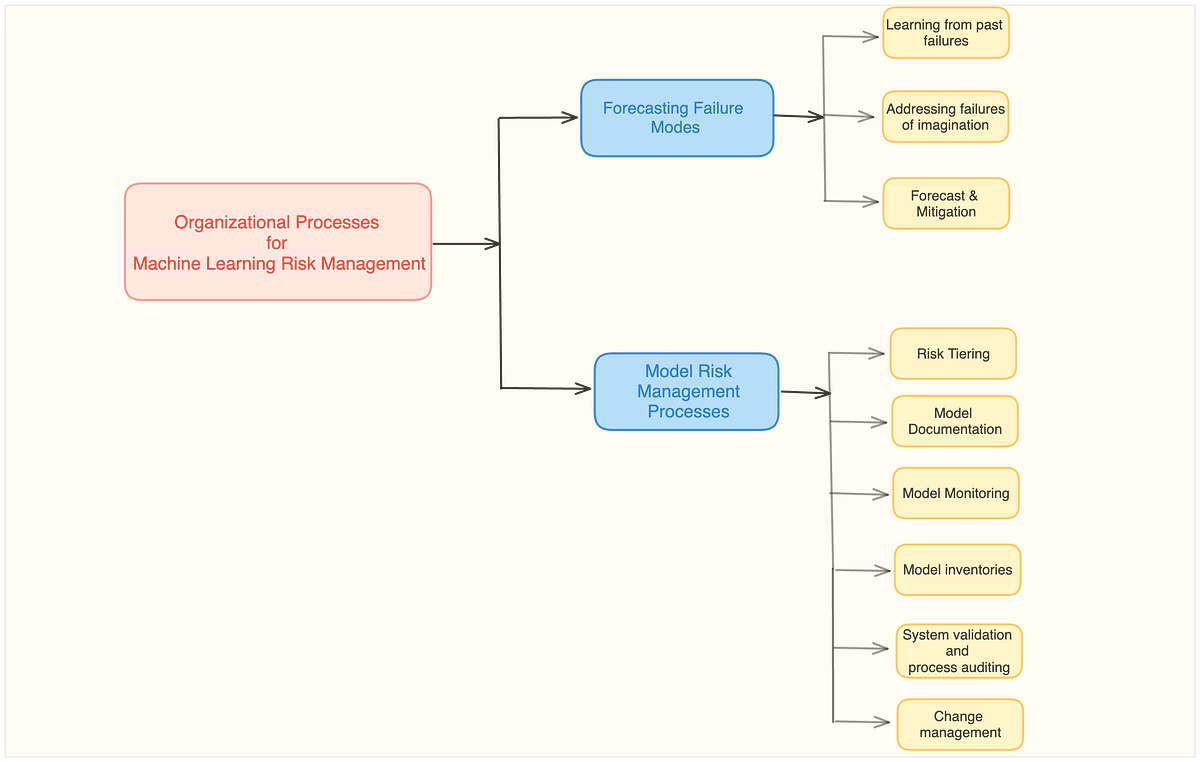
機械学習リスク管理の組織プロセス
「機械学習リスク管理シリーズでは、機械学習(ML)システムの信頼性を確保するための重要な要素を解明する旅に乗り出しました最初の...」
「ゼロからLLMを構築する方法」
「これは、大規模言語モデル(LLM)を実践的に使用するシリーズの6番目の記事です以前の記事では、プロンプトエンジニアリングとファインチューニングを通じて事前学習済みのLLMを活用する方法について詳しく調査しましたこれらに対して…」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.