Learn more about Search Results こちら - Page 89

- You may be interested
- 「Amazon SageMaker Canvasによるデータ処...
- 「トグルスイッチ」は、量子コンピュータ...
- MIT研究者が高度なニューラルネットワーク...
- ソルボンヌ大学の研究者は、画像、ビデオ...
- 「LangChain、Google Maps API、およびGra...
- 「尤度」と「確率」の違いは何ですか?」
- RAGのNLPにおける検索と生成の統一的な革...
- アマゾンのSageMakerジオスペーシャル機能...
- AIを利用して、科学者たちは、抗薬剤耐性...
- 「ジェンAI愛好家が読むべき5冊の本」
- AI増強ソフトウェアエンジニアリング:知...
- 人工知能における最良優先探索
- 制御ネット(ControlNet)は、🧨ディフュ...
- 「機械学習を使ったイタリアンファンタジ...
- NVIDIA RTXビデオスーパーレゾリューショ...

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…

UnityゲームをSpaceにホストする方法
UnityゲームをHugging Face Spaceでホストできることを知っていますか?いいえ?そうです、できます! Hugging Face Spacesは、デモを構築、ホスト、共有するための簡単な方法です。通常は機械学習のデモに使用されますが、プレイ可能なUnityゲームもホストできます。以下にいくつかの例を示します。 Huggy Farming Game Unity APIデモ 次に、Spaceで独自のUnityゲームをホストする方法を説明します。 ステップ1:静的HTMLテンプレートを使用してSpaceを作成する まず、Hugging Face Spacesに移動してスペースを作成します。 “Static HTML”テンプレートを選択し、スペースに名前を付けて作成します。 ステップ2:Gitを使用してスペースをクローンする Gitを使用して、新しく作成したスペースをローカルマシンにクローンします。ターミナルまたはコマンドプロンプトで次のコマンドを実行することでこれを行うことができます。 git clone https://huggingface.co/spaces/{your-username}/{your-space-name} ステップ3:Unityプロジェクトを開く…
BERTopicとHugging Face Hubの統合をご紹介します
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。 トピックモデリングとは何ですか? トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。 各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。 BERTopicとは何ですか? BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。 BERTopicライブラリの概要 BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。 BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。 Hugging Face Hubを使用したBERTopicモデルの管理 最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。 BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます from bertopic import BERTopic topic_model…

カカオブレインからの新しいViTとALIGNモデル
Kakao BrainとHugging Faceは、新しいオープンソースの画像テキストデータセットCOYO(700億ペア)と、それに基づいてトレーニングされた2つの新しいビジュアル言語モデル、ViTとALIGNをリリースすることを発表しました。ALIGNモデルが無料かつオープンソースで公開されるのは初めてであり、ViTとALIGNモデルのリリースにトレーニングデータセットが付属するのも初めてです。 Kakao BrainのViTとALIGNモデルは、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータに従っていますが、オープンソースのCOYOデータセットでトレーニングされています。GoogleのViTとALIGNモデルは、巨大なデータセット(ViTは3億枚の画像、ALIGNは18億の画像テキストペア)でトレーニングされていますが、データセットが公開されていないため、複製することはできません。この貢献は、データへのアクセスも含めて、視覚言語モデリングを再現したい研究者にとって特に価値があります。Kakao ViTとALIGNモデルの詳細な情報は、こちらで確認できます。 このブログでは、新しいCOYOデータセット、Kakao BrainのViTとALIGNモデル、およびそれらの使用方法について紹介します!以下が主なポイントです: 史上初のオープンソースのALIGNモデル! オープンソースのデータセットCOYOでトレーニングされた初のViTとALIGNモデル Kakao BrainのViTとALIGNモデルは、Googleのバージョンと同等のパフォーマンスを示します ViTとALIGNのデモはHFで利用可能です!選んだ画像サンプルでオンラインでViTとALIGNのデモを試すことができます! パフォーマンスの比較 Kakao BrainのリリースされたViTとALIGNモデルは、Googleが報告した内容と同等またはそれ以上のパフォーマンスを示します。Kakao BrainのALIGN-B7-Baseモデルは、トレーニングペアが少ない(700億ペア対18億ペア)にもかかわらず、Image KNN分類タスクではGoogleのALIGN-B7-Baseと同等のパフォーマンスを発揮し、MS-COCO検索の画像からテキスト、テキストから画像へのタスクではより優れた結果を示します。Kakao BrainのViT-L/16は、モデル解像度384および512でImageNetとImageNet-ReaLで評価された場合、GoogleのViT-L/16と同様のパフォーマンスを発揮します。つまり、コミュニティはKakao BrainのViTとALIGNモデルを使用して、特にトレーニングデータへのアクセスが必要な場合に、GoogleのViTとALIGNリリースを再現することができます。最先端の性能を発揮しつつ、オープンソースで透明性のあるこれらのモデルのリリースを見ることができるのはとても興奮します! COYOデータセット これらのモデルのリリースの特徴は、モデルが無料かつアクセス可能なCOYOデータセットでトレーニングされていることです。COYOは、GoogleのALIGN 1.8B画像テキストデータセットに似た700億ペアの画像テキストデータセットであり、ウェブページから取得した「ノイズのある」代替テキストと画像のペアのコレクションですが、オープンソースです。COYO-700MとALIGN 1.8Bは「ノイズのある」データセットですが、最小限のフィルタリングが適用されています。COYOは、他のオープンソースの画像テキストデータセットであるLAIONとは異なり、以下の点が異なります。…

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…

ディフューザを使用してControlNetをトレーニングしてください
イントロダクション ControlNetは、追加の条件を付加することで拡散モデルを細かく制御することができるニューラルネットワーク構造です。この技術は、「Adding Conditional Control to Text-to-Image Diffusion Models」という論文で登場し、すぐにオープンソースの拡散コミュニティで広まりました。著者はStable Diffusion v1-5を制御するための8つの異なる条件をリリースしました。これには、ポーズ推定、深度マップ、キャニーエッジ、スケッチなどが含まれます。 このブログ投稿では、3Dシンセティックフェイスに基づいた顔のポーズモデルであるUncanny Facesモデルのトレーニング手順を詳細に説明します(実際にはUncanny Facesは予期しない結果であり、それがどのように実現されたかについては後ほどご紹介します)。 安定した拡散のためのControlNetのトレーニングの始め方 独自のControlNetをトレーニングするには、3つのステップが必要です: 条件の計画:ControlNetはStable Diffusionをさまざまなタスクに対応できる柔軟性があります。事前にトレーニングされたモデルはさまざまな条件を示しており、コミュニティはピクセル化されたカラーパレットに基づいた他の条件を作成しています。 データセットの構築:条件が決まったら、データセットの構築の時間です。そのためには、データセットをゼロから構築するか、既存のデータセットの一部を使用することができます。モデルをトレーニングするためには、データセットには3つの列が必要です:正解のimage、conditioning_image、およびprompt。 モデルのトレーニング:データセットの準備ができたら、モデルのトレーニングの時間です。これは、ディフューザーのトレーニングスクリプトのおかげで最も簡単な部分です。少なくとも8GBのVRAMを持つGPUが必要です。 1. 条件の計画 条件を計画するために、次の2つの質問を考えると役立ちます: どのような条件を使用したいですか? 既存のモデルで「通常の」画像を私の条件に変換できるものはありますか?…

Hugging FaceとFlowerを使用したフェデレーテッドラーニング
このチュートリアルでは、Hugging Faceを使用して、Flowerを介して複数のクライアント上で言語モデルのトレーニングをフェデレートする方法を紹介します。具体的には、IMDBの評価データセットを使用して、事前トレーニングされたTransformerモデル(distilBERT)をシーケンス分類のために微調整します。最終的な目標は、映画の評価がポジティブかネガティブかを検出することです。 ノートブックはこちらでご利用いただけますが、複数のクライアントで実行する代わりに、Google Colab内でフェデレーテッド環境をエミュレートするためにFlowerのシミュレーション機能(flwr['simulation'])を使用します(これはまた、start_serverを呼び出す代わりにstart_simulationを呼び出す必要があり、その他の変更が必要です)。 依存関係 このチュートリアルに従うためには、以下のパッケージをインストールする必要があります:datasets、evaluate、flwr、torch、およびtransformers。これはpipを使用して行うことができます: pip install datasets evaluate flwr torch transformers 標準的なHugging Faceのワークフロー データの処理 IMDBデータセットを取得するために、Hugging Faceのdatasetsライブラリを使用します。その後、データをトークン化し、PyTorchのデータローダーを作成する必要があります。これはすべてload_data関数で行われます: import random import torch from datasets…
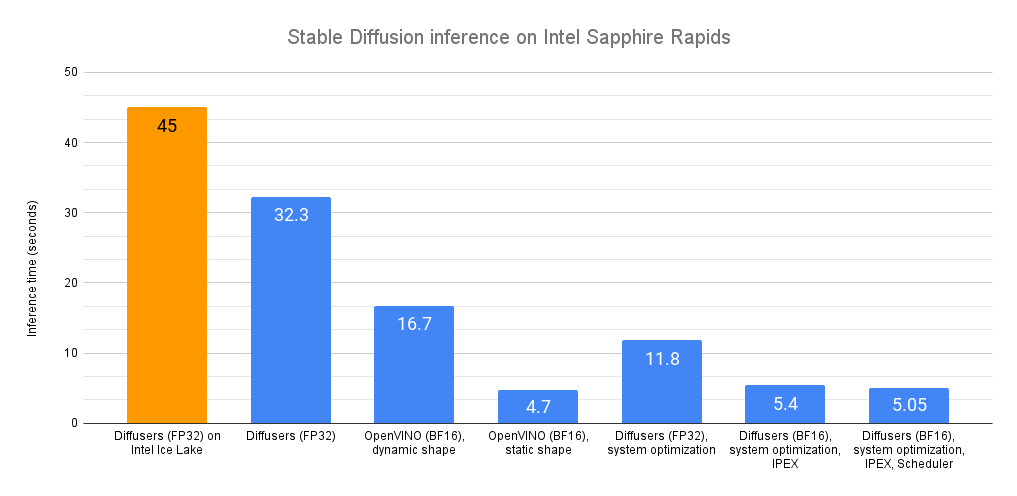
Intel CPU上での安定な拡散推論の高速化
最近、私たちは最新世代のIntel Xeon CPU(コードネームSapphire Rapids)を紹介しました。これには、ディープラーニングの高速化に対応した新しいハードウェア機能があります。また、これらを使用して自然言語処理のトランスフォーマーの分散微調整と推論を加速する方法も紹介しました。 この投稿では、Sapphire Rapids CPU上で安定拡散モデルを加速するための異なる技術を紹介します。次の投稿では、分散微調整について同様の内容を紹介します。 執筆時点では、Sapphire Rapidsサーバーにアクセスする最も簡単な方法は、Amazon EC2 R7izインスタンスファミリーを使用することです。まだプレビュー段階ですので、アクセスするためにはサインアップする必要があります。前の投稿と同様に、私はUbuntu 20.04 AMI(ami-07cd3e6c4915b2d18)を使用してr7iz.metal-16xlインスタンス(64 vCPU、512GB RAM)を使用しています。 さあ、始めましょう!コードサンプルはGitlabで利用できます。 Diffusersライブラリ Diffusersライブラリは、安定拡散モデルを使用して画像を生成するのが非常に簡単です。これらのモデルに詳しくない場合は、こちらの素晴らしいイラスト入りの紹介をご覧ください。 まず、必要なライブラリ(Transformers、Diffusers、Accelerate、PyTorch)を使用して仮想環境を作成しましょう。 virtualenv sd_inference source sd_inference/bin/activate pip…

大規模言語モデルの高速推論:Habana Gaudi2アクセラレータ上のBLOOMZ
この記事では、🤗 Optimum Habanaを使用してHabana® Gaudi®2上のBLOOMのような数千億のパラメータを持つ大規模な言語モデルを簡単に展開する方法を紹介します。これは、この記事で示されたベンチマークに示されているように、市場で現在利用可能などのどのGPUよりも高速な推論を実行することを可能にします。 モデルがますます大きくなるにつれて、プロダクション環境に展開して推論を実行することはますます困難になっています。ハードウェアとソフトウェアの両方には、これらの課題に対処するための多くのイノベーションが見られますので、効率的にこれらの課題を克服する方法を見てみましょう! BLOOMZ BLOOMは、テキストのシーケンスを完了するためにトレーニングされた1760億のパラメータの自己回帰モデルです。46の異なる言語と13のプログラミング言語を扱うことができます。BigScienceイニシアチブの一環として設計され、トレーニングされたBLOOMは、世界中の多くの研究者とエンジニアが関わったオープンサイエンスプロジェクトです。最近では、同じアーキテクチャの別のモデルがリリースされました:BLOOMZは、BLOOMのいくつかのタスクで微調整されたバージョンであり、より良い汎化およびゼロショット[^1]の機能を持っています。 このような大規模なモデルは、トレーニングおよび推論の両方においてメモリと速度の新たな課題を提起します。16ビット精度でも、1インスタンスには352 GBのメモリが必要です!現時点では、そのような多くのメモリを持つデバイスはおそらく見つけることが難しいでしょうが、Habana Gaudi2のような最先端のハードウェアを使用すると、BLOOMとBLOOMZモデルで低い待ち時間で推論を実行することができます。 Habana Gaudi2 Gaudi2は、Habana Labsによって設計された第2世代のAIハードウェアアクセラレータです。1つのサーバーには8つのアクセラレータデバイス(Habana Processing UnitsまたはHPUsと呼ばれる)があり、それぞれ96GBのメモリを提供し、非常に大きなモデルを収める余地があります。ただし、モデルをホストするだけでは非常に興味深くありません。幸いにも、Gaudi2はその点で優れています:そのアーキテクチャは、アクセラレータが並列で一般行列乗算(GeMM)およびその他の操作を実行できるようにするため、深層学習ワークフローを高速化します。これらの特徴により、Gaudi2はLLMのトレーニングおよび推論の優れた候補となります。 HabanaのSDKであるSynapseAI™は、LLMトレーニングおよび推論を高速化するためにPyTorchとDeepSpeedをサポートしています。SynapseAIグラフコンパイラは、グラフに蓄積された操作の実行を最適化します(例:オペレータの統合、データレイアウトの管理、並列化、パイプライニングとメモリ管理、およびグラフレベルの最適化)。 さらに、HPUグラフとDeepSpeed-inferenceのサポートは、最近SynapseAIに導入され、以下のベンチマークに示すようにレイテンシに敏感なアプリケーションに適しています。 これらの機能は、🤗 Optimum Habanaライブラリに統合されており、Gaudiにモデルを展開することは非常に簡単です。こちらのクイックスタートページをご覧ください。 Gaudi2にアクセスしたい場合は、Intel Developer Cloudにアクセスし、このガイドに従ってください。…

Substraを使用してプライバシーを保護するAIの作成
最近、生成技術の台頭により、機械学習はその歴史の中でも非常に興奮する時期にあります。この台頭を支えるモデルは、効果的な結果を生み出すためにさらに多くのデータを必要とします。そのため、データの倫理的な収集方法を探求することがますます重要になってきています。また、データのプライバシーとセキュリティを最優先にすることも重要です。 医療などの機密情報を扱う多くの領域では、データハングリーなモデルを訓練するために十分な高品質なデータにアクセスできることがしばしばありません。データセットは異なる学術センターや医療機関に分断され、患者情報や独自の情報のプライバシー上の懸念から、公開共有することが難しい状況にあります。HIPAAなどの患者データを保護する規制は、個人の健康情報を保護するために不可欠ですが、データサイエンティストがモデルを効果的に訓練するために必要なデータのボリュームにアクセスできないため、機械学習の研究の進展を制限することがあります。既存の規制と協調して患者データを積極的に保護する技術は、これらの分断を解除し、これらの領域での機械学習の研究と展開のスピードを加速するために重要となります。 ここでフェデレーテッドラーニングが登場します。Substraと共に作成したこのスペースをチェックして、詳細をご覧ください! フェデレーテッドラーニングとは何ですか? フェデレーテッドラーニング(FL)は、複数のデータプロバイダを使用してモデルを訓練できる分散型の機械学習技術です。すべてのソースからデータを単一のサーバーに収集するのではなく、データはローカルサーバーに残り、結果のモデルの重みのみがサーバー間を移動します。 データが元のソースから出ないため、フェデレーテッドラーニングは自然にプライバシーを最優先とするアプローチです。この技術はデータのセキュリティとプライバシーを向上させるだけでなく、データ科学者が異なるソースのデータを使用してより良いモデルを構築することも可能にします。これにより、データの量の増加だけでなく、データキャプチャ技術や装置によるわずかな違い、または患者集団の人口統計の違いなど、基になるデータセットのバリエーションによるバイアスのリスクを軽減することができます。複数のデータソースを持つことで、現実の世界でより優れた性能を発揮するより汎用性のあるモデルを構築することができます。フェデレーテッドラーニングについての詳細については、Googleの説明漫画をチェックすることをお勧めします。 Substraは、現実のプロダクション環境向けに構築されたオープンソースのフェデレーテッドラーニングフレームワークです。フェデレーテッドラーニングは比較的新しい分野であり、過去10年間にのみ確立されてきましたが、既に医学研究の進展を以前にも増して可能にしています。たとえば、10の競合するバイオファーマ企業が、通常は互いにデータを共有しないような状況で、MELLODDYプロジェクトで協力し、世界最大の既知の生化学的または細胞活性を持つ小分子のコレクションを共有しました。これにより、関係するすべての企業が薬剤探索のためのより正確な予測モデルを構築することができました。これは医学研究における重要なマイルストーンです。 Substra x HF フェデレーテッドラーニングの能力に関する研究は急速に進んでいますが、最近の作業の大部分はシミュレートされた環境に限定されています。実世界の例や実装は、フェデレーテッドネットワークの展開と設計の難しさのためにまだ限られています。フェデレーテッドラーニング展開のためのリーディングオープンソースプラットフォームとして、Substraは多くの複雑なセキュリティ環境とITインフラストラクチャで戦闘テストされ、乳がん研究での医学的なブレークスルーを実現しています。 Hugging Faceは、Substraを管理しているチームと協力して、このスペースを作成しました。これは、研究者や科学者が直面する現実の課題、つまり「AIに適した」集中化された高品質データの不足を理解するためのものです。これらのサンプルの分布を制御できるため、単純なモデルがデータの変化にどのように反応するかを確認することができます。その後、フェデレーテッドラーニングで訓練されたモデルが、単一のソースのデータから訓練されたモデルと比較して、ほとんど常に検証データで優れたパフォーマンスを発揮するかどうかを調べることができます。 結論 フェデレーテッドラーニングがリードをしているものの、セキュアなエンクレーブやマルチパーティ計算などのさまざまなプライバシー強化技術(PET)もあり、フェデレーションと組み合わせてマルチレイヤのプライバシー保護環境を作成することができます。これらが医療分野での協力を可能にしている方法に興味がある場合は、こちらをご覧ください。 使用される方法に関係なく、データプライバシーは私たち全員の権利であることに注意することが重要です。AIブームをプライバシーと倫理に念頭に置いて前進することが重要です。 もしSubstraを試してみて、プロジェクトでフェデレーテッドラーニングを実装したい場合は、こちらのドキュメントをご覧ください。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.