Learn more about Search Results Transformer - Page 88

- You may be interested
- 「共通の悪いデータの10つのケースとその...
- 「LLMガイド、パート1:BERT」 LLMガイド...
- 完全に自動化されたデータドリフト検出パ...
- 新しいAIメソッド、StyleAvatar3Dによるス...
- マイクロソフトリサーチと清華大学の研究...
- 合成データ生成のマスタリング:応用とベ...
- 「エンタープライズAIの処理のための表現...
- 「トップの音声からテキストへのAIツール...
- コンセプト2ボックスに出会ってください:...
- 人間のフィードバックからの強化学習(RLHF)
- 「先延ばしハック:ChatGPTを使ってプロジ...
- このAI研究は、「Atom」という低ビット量...
- UCサンタクルーズとSamsungの研究者が、ナ...
- 「月光スタジオのAIパワード受付アバター...
- 高度なグラフニューラルネットワークを使...

Hugging FaceとAMDは、CPUおよびGPUプラットフォーム向けの最先端モデルの高速化に関するパートナーシップを結んでいます
言語モデル、大規模な言語モデル、または基盤モデル、トランスフォーマーは、事前学習、微調整、および推論において大量の計算を必要とします。Hugging Faceは、開発者や組織が最大のパフォーマンスを得るために、ハードウェア企業と協力して、各チップのアクセラレーション機能を活用してきました。 本日、私たちはAMDが正式に私たちのハードウェアパートナープログラムに参加したことをお知らせいたします。私たちのCEOであるClement Delangueが、サンフランシスコで行われたAMDのデータセンターおよびAIテクノロジープレミアで基調講演を行い、このエキサイティングな新しい協力関係を発表しました。 AMDとHugging Faceは、AMDのCPUおよびGPU上で最先端のトランスフォーマーパフォーマンスを提供するために協力しています。このパートナーシップは、Hugging Faceコミュニティ全体にとって非常に良いニュースであり、近々、最新のAMDプラットフォームをトレーニングおよび推論に活用することができるようになります。 長年にわたり、ディープラーニングハードウェアの選択肢は限られており、価格と供給は懸念事項となっています。この新しいパートナーシップは、競争に対抗するだけでなく、市場の動向を緩和するのに役立ちます。さらに、新しいコストパフォーマンスの基準を設定することも期待されます。 サポートされるハードウェアプラットフォーム GPU側では、AMDとHugging Faceはまず、エンタープライズグレードのInstinct MI2xxおよびMI3xxファミリー、次に、カスタマーグレードのRadeon Navi3xファミリーで協力します。AMDの最近のテストでは、MI250が直接競合他社よりもBERT-Largeを1.2倍、GPT2-Largeを1.4倍高速にトレーニングすることを報告しています。 CPU側では、両社はクライアントRyzenおよびサーバーEPYC CPUの推論の最適化に取り組みます。いくつかの以前の投稿で議論したように、CPUはトランスフォーマーの推論において優れたオプションになり得ます。特に、量子化などのモデル圧縮技術と組み合わせた場合です。 最後に、この協力関係には、低い電力要件で驚異的なパフォーマンスを発揮するAlveo V70 AIアクセラレータも含まれます。 サポートされるモデルアーキテクチャとフレームワーク 私たちは、自然言語処理、コンピュータビジョン、音声などの最先端のトランスフォーマーアーキテクチャ(BERT、DistilBERT、ROBERTA、Vision Transformer、CLIP、Wav2Vec2など)をサポートする予定です。もちろん、生成型AIモデル(GPT2、GPT-NeoX、T5、OPT、LLaMAなど)、私たち自身のBLOOMおよびStarCoderモデルも利用可能です。最後に、ResNetやResNextのようなより伝統的なコンピュータビジョンモデル、そして深層学習の推薦モデルにも初めて対応します。 これらのモデルをPyTorch、TensorFlow、およびONNX Runtime向けに上記のプラットフォームでテストおよび検証するために最善を尽くします。すべてのモデルが、すべてのフレームワークまたはすべてのハードウェアプラットフォームでトレーニングおよび推論に利用可能であるわけではないことを覚えておいてください。 今後の展望…

Hugging Face SpacesでLivebookノートブックをアプリとしてデプロイする
エリクサーのコミュニティは、機械学習に向けて大きな進歩を遂げており、Hugging Faceはそれを実現するために重要な役割を果たしています。今日のエリクサーと機械学習で既に達成できることを示すために、私たちはLivebookを使用してWhisperベースのチャットアプリを構築し、それをHugging Face Spacesにデプロイしています。15分以内にすべて完了しますので、ぜひご覧ください: このチャットアプリでは、ユーザーはオーディオメッセージの送信のみでコミュニケーションを行い、Whisper機械学習モデルによって自動的にテキストに変換されます。 このアプリは、Livebookとエリクサーの機械学習エコシステムのいくつかの興味深い機能を紹介しています: Hugging Faceモデルとの統合 マルチプレイヤーの機械学習アプリ 並行して機械学習モデルを提供する(ボーナスポイント:モデルの提供をクラスタ上で簡単に分散させることもできます) Livebookがまだ知らない場合は、それはエリクサーでインタラクティブなコードノートブックを書くためのオープンソースツールであり、数値計算、データサイエンス、機械学習のエリクサーツールの成長するコレクションの一部です。 Hugging Faceとエリクサー エリクサーコミュニティは、機械学習の領域でHugging Faceプラットフォームとそのオープンソースプロジェクトを活用しています。以下にいくつかの例を示します。 Hugging Faceの事前学習済みニューラルネットワークモデルをエリクサーコミュニティにもたらした最初のポジティブな影響は、Bumblebeeライブラリでした。このライブラリはHugging Face Transformersからインスピレーションを受け、Hugging Face Hubを使用してモデルのパラメータをダウンロードしています。 もう1つの例は、tokenizersライブラリで、これはHugging Face Tokenizersのエリクサーバインディングです。…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…

ビジョン言語モデルの高速化:Habana Gaudi2上のBridgeTower
Optimum Habana v1.6 on Habana Gaudi2 では、最新のビジョン言語モデルである BridgeTower のファインチューニングにおいて、A100 と比較してほぼ3倍の高速化を実現しています。ハードウェアアクセラレーションによるデータの読み込みと高速な DDP 実装の2つの新機能がパフォーマンス向上に寄与しています。 これらの技術は、データの読み込みに制約がある他のワークロードにも適用できます。これは、さまざまなタイプのビジョンモデルに頻繁に起こるケースです。この投稿では、BridgeTower のファインチューニングを Habana Gaudi2 と Nvidia A100 80GB で比較するために使用したプロセスとベンチマークを紹介します。また、トランスフォーマーベースのモデルでこれらの機能を簡単に活用する方法も示します。 BridgeTower 最近のビジョン言語(VL)モデルは、さまざまなVLタスクで非常に重要であり、優位性を示しています。最も一般的なアプローチは、それぞれのモダリティから表現を抽出するためにユニモーダルエンコーダを利用することです。その後、これらの表現は融合されるか、クロスモーダルエンコーダに供給されます。VL表現学習のパフォーマンス制約と制限を効果的に扱うために、BridgeTower は複数のブリッジ層を導入し、ユニモーダルエンコーダのトップ層とクロスモーダルエンコーダの各層との間に接続を構築します。これにより、クロスモーダルエンコーダ内の異なる意味レベルで視覚とテキストの表現の効果的なボトムアップのクロスモーダルの整合性と融合が可能になります。…
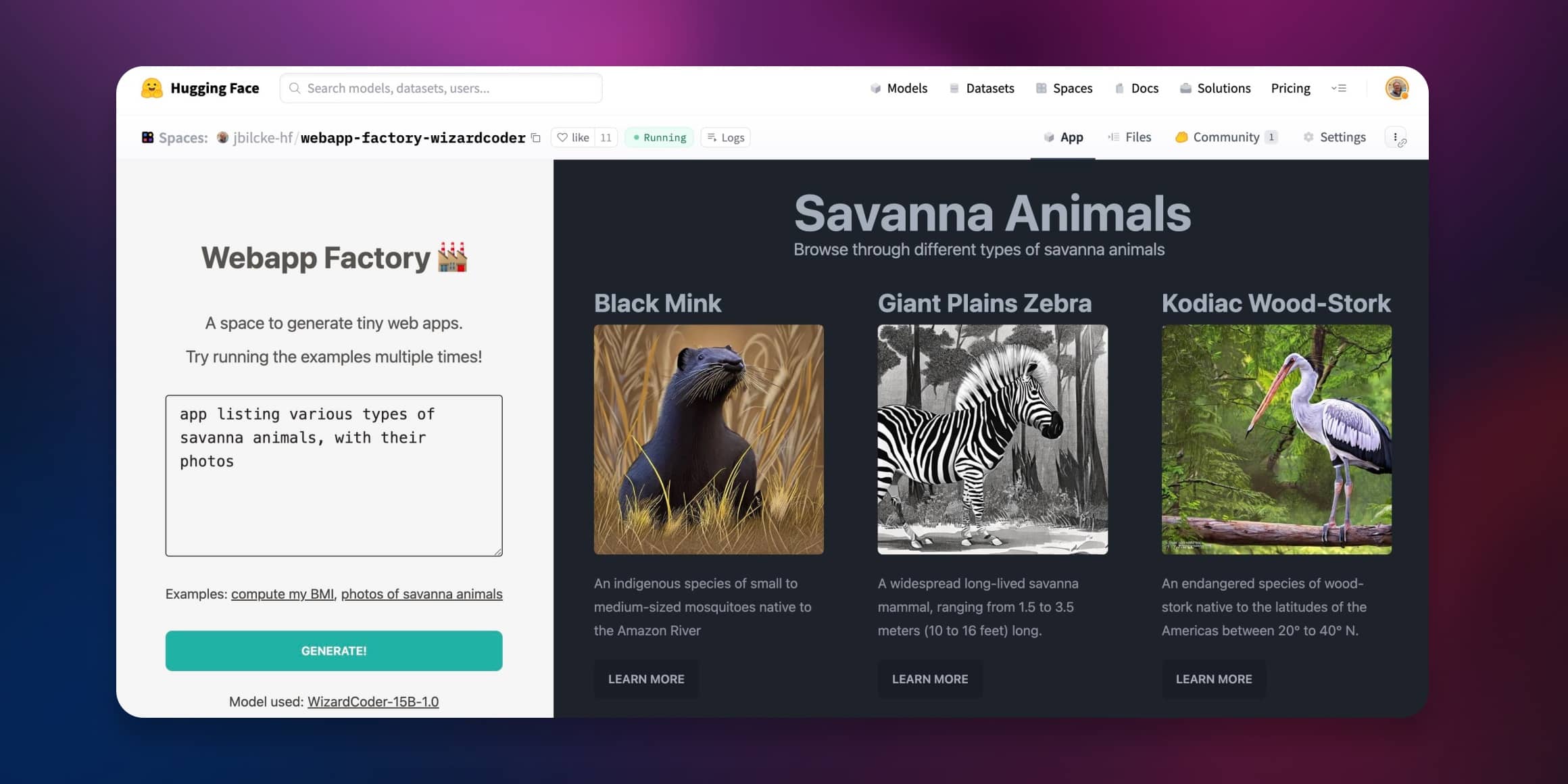
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…

Hugging Faceの推論エンドポイントを使用してLLMをデプロイする
オープンソースのLLMであるFalcon、(オープン-)LLaMA、X-Gen、StarCoder、またはRedPajamaは、ここ数ヶ月で大きく進化し、ChatGPTやGPT4などのクローズドソースのモデルと特定のユースケースで競合することができるようになりました。しかし、これらのモデルを効率的かつ最適化された方法で展開することはまだ課題です。 このブログ投稿では、モデルの展開を容易にするマネージドSaaSソリューションであるHugging Face Inference EndpointsにオープンソースのLLMを展開する方法と、応答のストリーミングとエンドポイントのパフォーマンステストの方法を紹介します。さあ、始めましょう! Falcon 40Bの展開方法 LLMエンドポイントのテスト JavaScriptとPythonでの応答のストリーミング 始める前に、Inference Endpointsについての知識をおさらいしましょう。 Hugging Face Inference Endpointsとは何ですか Hugging Face Inference Endpointsは、本番環境での機械学習モデルの展開を簡単かつ安全な方法で提供します。Inference Endpointsを使用することで、開発者やデータサイエンティストはインフラストラクチャの管理をせずにAIアプリケーションを作成できます。展開プロセスは数回のクリックで簡略化され、オートスケーリングによる大量のリクエストの処理、ゼロスケールへのスケールダウンによるインフラストラクチャのコスト削減、高度なセキュリティの提供などが可能となります。 LLM展開における最も重要な機能のいくつかは以下の通りです: 簡単な展開: インフラストラクチャやMLOpsの管理を必要とせず、本番用のAPIとしてモデルを展開できます。 コスト効率:…

ドレスコードの解読👗 自動ファッションアイテム検出のためのディープラーニング
電子商取引の活気ある世界では、ファッション業界は独自のランウェイですしかし、もし我々がこのランウェイのドレスコードを、デザイナーの目ではなく、ディープラーニングの精度で解読できるとしたら...

MPT-30B:モザイクMLは新しいLLMを使用して、NLPの限界を em>GPT-3を凌駕します
MosaicMLのLLMにおける画期的な進歩について、MPTシリーズで学びましょうMPT-30Bおよびその微調整された派生モデル、MPT-30B-InstructとMPT-30B-Chatが他のモデルを凌駕する方法を探索してください

GPT-3がMLOpsの将来に与える意味とは?デビッド・ハーシーと共に
この記事は元々MLOps Liveのエピソードであり、ML実践者が他のML実践者からの質問に答えるインタラクティブなQ&Aセッションです各エピソードは特定のMLトピックに焦点を当てており、このエピソードではGPT-3とMLOpsの特徴についてDavid Hersheyと話しましたYouTubeで視聴することができます Or...

MLモデルのトレーニングパイプラインの構築方法
手を挙げてください、もしもあなたがごちゃ混ぜのスクリプトをほどくのに時間を無駄にしたことがあるか、またはそう難解なバグを修正しようとしている間に幽霊を追いかけているような気持ちになったことがあるかそしてその間にモデルの訓練が永遠にかかっているという状況も経験したことがあるかもしれません私たちは皆、そんな経験をしたことがあるはずですよね?でも今、別のシナリオを思い浮かべてくださいきれいなコード効率的なワークフロー効率的なモデルの訓練信じられないほど素晴らしい光景ですよね…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.