Learn more about Search Results link - Page 87

- You may be interested
- 「トランスフォーマーと位置埋め込み:マ...
- FHEを用いた暗号化された大規模言語モデル...
- 『Amazon Search M5がAWS Trainiumを使用...
- 「Pantsを使用してMachine LearningのMono...
- NVIDIA AIがSteerLMを発表:大規模言語モ...
- 「ChatGPTを使用してAI幻覚を回避する方法」
- テキストによる画像および3Dシーン編集の...
- 「Java ZGCアルゴリズムのチューニング」
- ブレイブがLeoを紹介:ウェブページやビデ...
- Intelのテクノロジーを使用して、PyTorch...
- 「GPU インスタンスに裏打ちされた SageMa...
- ヘッドショットプロのレビュー:2時間で12...
- AVCLabsフォトエンハンサーAIのレビュー:...
- 「ノーコードアプリビルダーのトップ10(2...
- 「タコ」の複雑な細胞は彼らの高い知能の...

GPTとBERT:どちらが優れているのか?
生成AIの人気の高まりに伴い、大規模言語モデルの数も増加していますこの記事では、GPTとBERTの2つのモデルを比較しますGPT(Generative...

Netflix株の時系列分析(Pandasによる)
はじめに データの時系列分析は、この場合はNetflixの株式などの数字の集まりだけではありません。Pandasと組み合わさることで、複雑な世界の物語を魅力的に紡ぐ織物のようなものです。神秘的な糸のように、出来事の起伏や流れ、トレンドの上昇や下降、そしてパターンの出現を捉えます。それは、私たちの現実を形作る隠されたつながりや相関関係を明らかにし、過去の生き生きとした描写を提供し、未来の一端を垣間見るものです。 時系列分析は単なるツール以上のものです。それは知識と洞察を得るためのゲートウェイであります。時間に関するデータの秘密を解き明かし、生の情報を貴重な洞察に変える力を与え、情報をもとに妥当な決定を下し、リスクを軽減し、新しい機会を活用する手助けをします。 このエキサイティングな冒険に一緒に乗り出し、時系列分析の魅力的な領域に飛び込んでみましょう! 学習目標 時系列分析の概念を紹介し、そのさまざまな分野での重要性を強調し、実際の例を示して、時系列分析の実用的な応用を紹介します。 Pythonとyfinanceライブラリを使用してNetflixの株式データをインポートする方法を実演することで、時系列データを取得し、分析のために準備するための必要な手順を学びます。 最後に、シフト、ローリング、およびリサンプリングなどの時系列分析で使用される重要なPandas関数に焦点を当て、時系列データを効果的に操作および分析するための方法を示します。 この記事は、Data Science Blogathonの一環として公開されました。 時系列分析とは何ですか? 時系列とは、連続的かつ等間隔の時間間隔で収集または記録されたデータのシーケンスです。 時系列分析は、時間によって収集されたデータポイントを分析する統計的技術です。 これには、データの視覚化、統計モデリング、予測方法などの技術が含まれます。 順次データのパターン、トレンド、依存関係を研究し、洞察を抽出し、予測を行うことが含まれます。 時系列データの例 株式市場データ:歴史的な株価を分析してトレンドを特定し、将来の価格を予測する。 天気データ:時間の経過に伴って温度、降水量、その他の変数を研究して、気候パターンを理解する。 経済指標:GDP、インフレ率、失業率を分析して、経済のパフォーマンスを評価する。 売上データ:時間の経過に伴って売上高を調べ、パターンを特定し、将来の売上高を予測する。 ウェブトラフィック:ウェブトラフィックメトリックを分析して、ユーザーの行動を理解し、ウェブサイトのパフォーマンスを最適化する。 時系列の構成要素 時系列の4つの構成要素があります。それらは次のとおりです。…

データサイエンティストとは具体的に何をする人なのでしょうか?
この様々な職務記述の羅列からも明らかなように、データサイエンティストの役割が実際に日々何を含むのかを明確に把握するのは非常に困難であることがあります既存の多くの記事は、...

ChatGPTを使った効率的なデバッグ
大規模言語モデルの力を借りて、デバッグ体験を向上させ、より速く学習する

医薬品探索の革新:機械学習モデルによる可能性のある老化防止化合物の特定と、将来の複雑な疾患治療のための道筋を開拓する
老化やがん、2型糖尿病、骨関節炎、ウイルス感染などの他の病気は、細胞老化をストレス反応として含んでいます。老化細胞のターゲット化された除去は人気を博していますが、その分子標的がよりよく理解される必要があるため、senolyticsはほとんど知られていません。ここでは、科学者たちは、以前に発表されたデータのみで教育された比較的安価な機械学習アルゴリズムを使用して、3つのsenolyticを発見することを説明しています。さまざまなタイプの細胞老化を経験する人間の細胞株で、彼らは複数の化学ライブラリの計算スクリーニングを使用して、ginkgetin、periplocin、およびoleandrinのsenolytic作用を確認しました。これらの化学物質は、よく確立された分析法と同様に効果的であり、oleandrinは、そのターゲットに対して現在のゴールドスタンダードよりも効果的であることを示しています。この方法により、数百倍の薬剤スクリーニング費用が削減され、AIが限られた種類の薬剤スクリーニングデータを最大限に活用できることが示されています。これにより、薬剤探索の初期段階において、新しいデータ駆動型の方法が可能になりました。 senolyticsは、マウスの多くの疾患の症状を緩和することが示されていますが、その除去は、傷口治癒や肝臓機能などのプロセスの障害を引き起こすことも関連しています。有望な発見があるにもかかわらず、senolytic作用を持つ2つの薬剤しか臨床研究で有効性が示されていません。 過去には優れた分析法が開発されていますが、一般的に健康な細胞に有害です。現在、スコットランドのエディンバラ大学の研究者たちは、健康な細胞を傷つけることなく、これらの不良細胞を除去できる化学化合物を特定する革新的なアプローチを開発しました。 彼らは、senolyticの特性を持つ化合物を特定するための機械学習モデルを構築し、それを教育する方法を開発しました。広範囲に承認された薬剤または臨床段階の薬剤を含む2つの既存の化学ライブラリからの化学物質は、学習モデルのトレーニングに使用された各種のソースからのデータと結合されました(アカデミック論文や商業特許など)。機械学習システムにバイアスをかけないために、データセットにはsenolyticおよび非senolytic特性を持つ2,523の物質が含まれています。4,000以上の化合物のデータベースにアルゴリズムを適用した後、21の有望な候補が見つかりました。 テスト中に、ginkgetin、periplocin、およびoleandrinの3つの化合物は、健康な細胞に影響を与えずに老化細胞を除去することが示され、良好な候補物質となりました。結果は、oleandrinが3つの中で最も効果的であることを示しました。これらの3つは、ハーブ療法の一般的な成分です。 oleandrinの源はオウバイ(Nerium oleander)で、心不全や特定の不整脈(不整脈)の治療に使用される心臓薬digoxinと同等の効果を持つ物質です。oleandrinには抗がん、抗炎症、抗HIV、抗菌、抗酸化作用が観察されています。人間におけるoleandrinの治療的窓は狭く、治療用量を超えると高度に毒性があるため、食品添加物や医薬品としての販売や使用は違法です。 Linkedinもoleandrinと同様に、がん、炎症、微生物、神経系に対して有益な効果があり、抗酸化作用や神経保護特性があります。銀杏(Ginkgo biloba)は最も古い生きている樹種であり、その葉と種子は中国で数千年間、漢方薬として使用されています。この木はLinkedinの源です。この木の乾燥した葉を使用して処方箋なしで販売される銀杏エキスが作られています。これは、米国やヨーロッパでトップセラーのハーブサプリメントです。 研究者らは、彼らの結果が、以前の研究で特定されたsenolyticよりも同等またはそれ以上に効果的であることを示していると主張しています。彼らの機械学習ベースのアプローチは、製薬業界での通常のAIの使用とは異なるいくつかの新しい機能を備えています。 第1に、モデルトレーニングに公開されたデータのみを使用するため、内部でのトレーニング化合物の実験的な特性の追加費用は必要ありません。 第2に、senolysisは稀な分子特性であり、文献に報告されているsenolyticは少ないため、機械学習モデルは、通常はこの分野で考慮されるよりもはるかに小さなデータセットでトレーニングされました。この方法の効果は、文献データが通常予想されるよりも多様で限定的であるにもかかわらず、機械学習が文献データを最大限に活用できることを示しています。 第3に、標的非依存モデルトレーニングで薬理学的活性の表現型指標が使用されました。多くの状態は、重要な経済的および社会的負担を負っていますが、それらの状態のためには、少数またはまったくターゲットが知られていないため、表現型薬剤探索は、発見パイプラインを通じて進展する可能性のある化学の出発点の数を拡大する機会を提供します。

MatplotlibのチャートをHTMLページに埋め込む3つの方法
Pythonには、データ可視化を含むさまざまな操作を実行するための多くのライブラリが用意されていますただし、Matplotlibを使用して作成したチャートをHTMLページに統合することは複雑な場合があります最も簡単な方法は…

将来のPythonバージョン(3.12など)に一般のユーザーに先駆けてアクセスする方法
Python 3.12などの将来のバージョンを群衆より先にインストールしてテストする方法についてのチュートリアルで、新しい機能を体験して競争上の優位性を獲得する方法

マルチヘッドアテンションを使用した注意機構の理解
はじめに Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。 アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。 学習目標 アテンションメカニズムの概念 マルチヘッドアテンションについて Transformerのマルチヘッドアテンションのアーキテクチャ 他のタイプのアテンションメカニズムの概要 この記事は、データサイエンスブログマラソンの一環として公開されました。 アテンションメカニズムの理解 まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。 これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。 マルチヘッドアテンションとは? マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。 出典:Pngwing.com 計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。 数式表現 具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。 学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。 これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。 行列の説明 クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。 キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。 値:…

NLPの就職面接をマスターする
NLPとは何か、そしてNLPに関連する仕事の面接で期待される質問のタイプは何ですか?
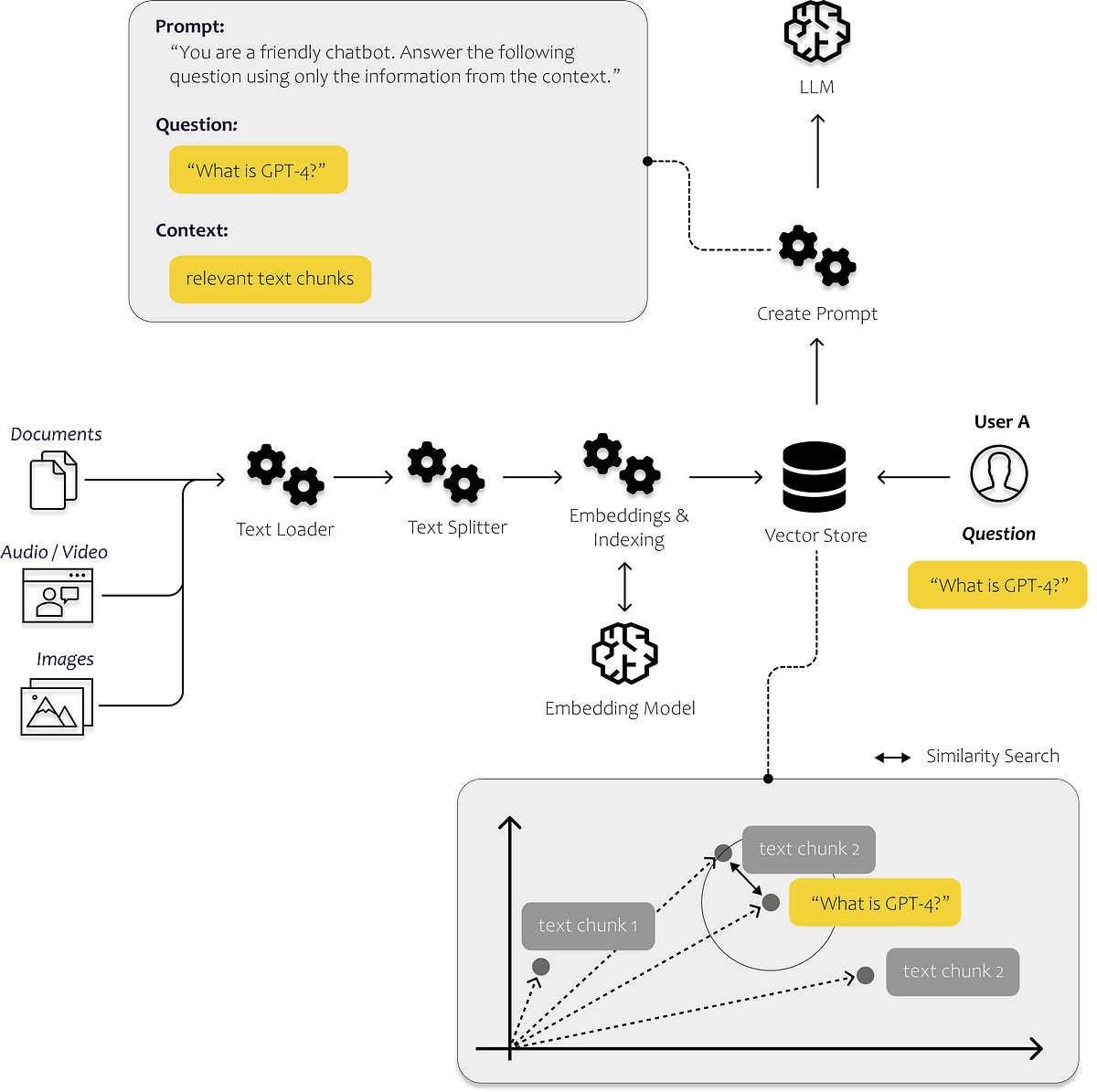
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.