Learn more about Search Results LINK - Page 86

- You may be interested
- このAI論文は、自律言語エージェントのた...
- DLノート:勾配降下法
- 「データプライバシーを見る新しい方法」
- 機械学習インサイトディレクター【パート3...
- 3Dプリンターは郵便局の迅速かつ手頃な配...
- メタのラマ2:商業利用のためのオープンソ...
- このAI論文は、周波数領域での差分プライ...
- 「Pandas:データをワンホットエンコード...
- ユレカ:大規模な言語モデルをコーディン...
- 「AIにおけるウォータージャグ問題とは何...
- 因果推論:準実験
- 蒸留-ささやき:AI音声からテキストへの技...
- 「Amazon SageMakerの非同期エンドポイン...
- 「FLM-101Bをご紹介します:1010億パラメ...
- Falcon LLM:オープンソースLLMの新しい王者

Mr. Pavan氏のデータエンジニアリングの道は、ビジネスの成功を導く
はじめに 私たちは、Pavanさんから学ぶ素晴らしい機会を得ました。彼は問題解決に情熱を持ち、持続的な成長を追求する経験豊富なデータエンジニアです。会話を通じて、Pavanさんは自身の経験、インスピレーション、課題、そして成し遂げたことを共有しています。そのため、データエンジニアリングの分野における貴重な知見を提供してくれます。 Pavanさんの実績を探索する中で、再利用可能なコンポーネントの開発、効率化されたデータパイプラインの作成、グローバルハッカソンの優勝などに誇りを持っていることがわかります。彼は、データエンジニアリングを通じてクライアントのビジネス成長を支援することに情熱を注いでおり、彼の仕事が彼らの成功に与える影響について共有してくれます。さあ、Pavanさんの経験と知恵から学んで、データエンジニアリングの世界に没頭しましょう。 インタビューを始めましょう! AV:自己紹介と経歴について教えてください。 Pavanさん:私は情報技術の学生として学問の道を歩み始めました。当時、この分野での有望な求人が私を駆り立てていました。しかし、私のプログラミングに対する見方はMSハッカソン「Yappon!」に参加した時に変わりました。その経験が私に深い情熱をもたらしました。それは私の人生の転機となり、プログラミングの世界をより深く探求するスパークを生み出しました。 それ以来、私は4つのハッカソンに積極的に参加し、うち3つを優勝するという刺激的な結果を残しました。これらの経験は私の技術的なスキルを磨き、タスクの自動化や効率的な解決策の探求に執念を燃やすようになりました。私はプロセスの効率化や繰り返しタスクの削減に挑戦することで成長しています。 個人的には、私は内向的と外向的のバランスを取るambivertだと考えています。しかし、私は常に自分の快適ゾーンから踏み出して、成長と発展のための新しい機会を受け入れるように自分自身を鼓舞しています。プログラミング以外の私の情熱の1つはトレッキングです。大自然を探索し、自然の美しさに浸ることには魅力的な何かがあります。 私のコンピュータサイエンス愛好家としての旅は、仕事の見通しに対する実用的な見方から始まりました。しかし、ハッカソンに参加することで、プログラミングに対する揺るぎない情熱に変わっていきました。成功したプロジェクトの実績を持ち、自動化の才能を持っていることから、私はスキルを拡大し、コンピュータサイエンス分野での積極的な貢献を続けることを熱望しています。 AV:あなたのキャリアに影響を与えた人物を数名挙げて、どのように影響を受けたか教えてください。 Pavanさん:まず、私は母親と祖母に感謝しています。彼女たちはサンスクリットの格言「Shatkarma Manushya yatnanam, saptakam daiva chintanam.」に象徴される価値観を私に教えてくれました。人間の努力と精神的な瞑想の重要性を強調したこの哲学は、私のキャリアを通じて指導原理となっています。彼女たちの揺るぎないサポートと信念は、私の常に刺激となっています。 また、私のB.Tech時代に教授だったSmriti Agrawal博士にも大きな成長を感じています。彼女はオートマトンとコンパイラ設計を教えながら、その科目についての深い理解を伝え、キャリア開発の重要性を強調しました。「6ヶ月で履歴書に1行も追加できない場合は、成長していない」という彼女の有益なアドバイスは、私のマインドセットを変えるきっかけになりました。このアドバイスは、私に目標を設定し、挑戦的なプロジェクトに取り組み、定期的にスキルセットを更新するよう駆り立て、私を常に成長と学びの機会に導いてくれました。 さらに、私にとって支援的な友人のネットワークを持っていることは幸運なことです。彼らは私のキャリアの旅において重要な役割を果たしています。彼らは、複雑なプログラミングの概念を理解するのを手伝ってくれたり、私をハッカソンに参加させてスキルを磨いたりすることで、私を引っ張り出し、最高の自分を引き出すのに欠かせない存在となっています。彼らの指導と励ましは、私を常に限界を超えて、最高の自分を引き出すのに不可欠であり、私の今までの進歩に欠かせません。 AV:なぜデータと一緒に働くことに興味を持ち、データエンジニアとしての役割の中で最もエキサイティングなことは何ですか? Pavanさん:私がデータと一緒に働くことに惹かれたのは、データが今日の世界であらゆるものを動かしていることを認識したからです。データは、意思決定の基盤であり、戦略の策定、革新の源泉です。データを生のままから意味のある洞察に変換し、それらの洞察を顧客やビジネスの成功につなげることが、私がデータと一緒に働くことに情熱を持つようになった原動力となりました。 データエンジニアとして私が最も興奮するのは、データ革命の最前線に立つ機会です。膨大な量の情報を効率的に収集、処理、分析するデータシステムを設計・実装する複雑なプロセスに魅了されています。データの膨大な量と複雑さは、創造的な問題解決と継続的な学習を必要とする刺激的な課題を提供します。 データエンジニアとして最もエキサイティングな側面の1つは、データの潜在的な可能性を引き出すことができることです。堅牢なパイプラインを構築し、高度な分析を実装し、最新技術を活用することで、情報を収集し、意思決定を支援し、変革につながる貴重な洞察を明らかにすることができます。データ駆動型のソリューションが直接顧客体験を改善し、業務効率を向上させ、ビジネス成長を促進する様子を見ることは、非常にやりがいを感じます。 また、この分野のダイナミックな性質は私を引っ張っていきます。データエンジニアリング技術と技法の急速な進歩は、常に新しいイノベーションの機会を提供してくれます。これらの進歩の最前線に立ち、継続的に学習し、スキルを磨き、複雑なデータ課題を解決するために適用することは、知的好奇心を刺激し、専門的にもやりがいを感じさせます。…
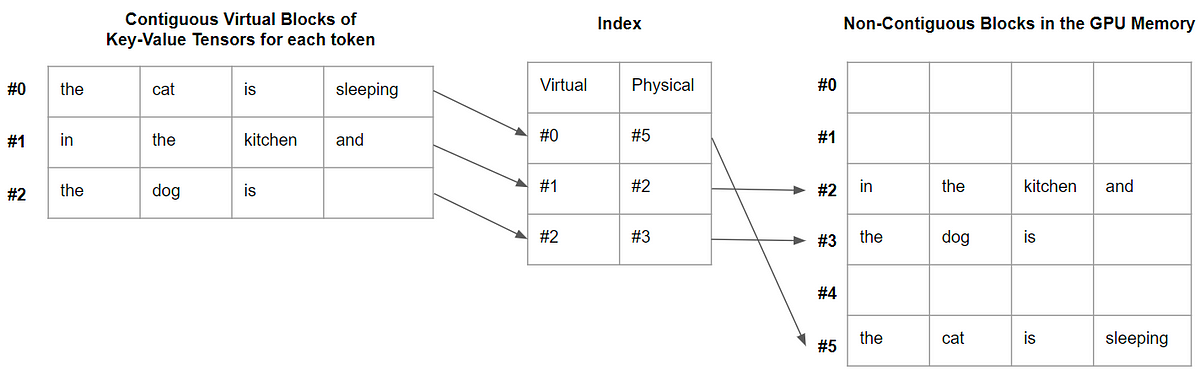
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します
次回のデータプロジェクトで興味深いデータセットを取得する5つの方法(Kaggle以外)
素晴らしいデータサイエンスプロジェクトの鍵は素晴らしいデータセットですが、素晴らしいデータを見つけることは言うほど簡単ではありません私がデータサイエンス修士課程を勉強していた頃を覚えていますが、それはちょうど...
私の博士号入学への道 – 人工知能
大学の出願書類を取り組んで、日々をカウントダウンして過ごした6ヶ月間の後、2023年秋に人工知能の博士号を取得することになりました以下の内容をまとめてみました…
特徴量が多すぎる?主成分分析を見てみましょう
次元の呪いは、機械学習における主要な問題の1つです特徴量の数が増えると、モデルの複雑さも増しますさらに、十分なトレーニングデータがない場合、それは...

紛争のトレンドとパターンの探索:マニプールのACLEDデータ分析
はじめに データ分析と可視化は、複雑なデータセットを理解し、洞察を効果的に伝えるための強力なツールです。この現実世界の紛争データを深く掘り下げる没入型探索では、紛争の厳しい現実と複雑さに深く踏み込みます。焦点は、長期にわたる暴力と不安定状態によって悲惨な状況に陥ったインド北東部のマニプール州にあります。私たちは、武装紛争ロケーション&イベントデータプロジェクト(ACLED)データセット[1]を使用し、紛争の多面的な性質を明らかにするための詳細なデータ分析の旅に出ます。 学習目標 ACLEDデータセットのデータ分析技術に熟達する。 効果的なデータ可視化のスキルを開発する。 脆弱な人口に対する暴力の影響を理解する。 紛争の時間的および空間的な側面に関する洞察を得る。 人道的ニーズに対処するための根拠に基づくアプローチを支援する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 利害の衝突 このブログで提示された分析と解釈に責任を持つ特定の組織や団体はありません。目的は、紛争分析におけるデータサイエンスの潜在力を紹介することです。さらに、これらの調査結果には個人的な利益や偏見が含まれておらず、紛争のダイナミクスを客観的に理解するアプローチが確保されています。データ駆動型の方法を促進し、紛争分析に関する広範な議論に情報を提供するために、積極的に利用することを推奨します。 実装 なぜACLEDデータセットを使用するのか? ACLEDデータセットを活用することで、データサイエンス技術の力を活用することができます。これにより、マニプール州の状況を理解するだけでなく、暴力に関連する人道的側面にも光を当てることができます。ACLEDコードブックは、このデータセット[2]で使用されるコーディングスキームと変数に関する詳細な情報を提供する包括的な参考資料です。 ACLEDの重要性は、共感的なデータ分析にあります。これにより、マニプール州の暴力に関する理解が深まり、人道的ニーズが明らかにされ、暴力の解決と軽減に貢献します。これにより、影響を受けるコミュニティに平和で包摂的な未来が促進されます。 このデータ駆動型の分析により、貴重な洞察力を得るだけでなく、マニプール州の暴力の人的コストにも光が当てられます。ACLEDデータを精査することで、市民人口、強制的移動、必要なサービスへのアクセスなど、地域で直面する人道的現実の包括的な描写が可能になります。 紛争のイベント まず、ACLEDデータセットを使用して、マニプール州の紛争のイベントを調査します。以下のコードスニペットは、インドのACLEDデータセットを読み込み、マニプール州のデータをフィルタリングして、形状が(行数、列数)のフィルタリングされたデータセットを生成します。フィルタリングされたデータの形状を出力します。 import pandas as pd # ACLEDデータをダウンロードして国別のcsvをインポートする…

あなたの次の夢の役割(2023年)を見つけるのに役立つ、最高のAIツール15選
Resumaker.ai Resumaker.aiは、数分で履歴書を作成するのを支援するウェブサイトです。ポータルは、いくつかのカスタマイズ可能なデザイナー製履歴書テンプレートと直感的なツールを提供して、夢の仕事に就くのを手助けします。他の履歴書ビルダーとは異なり、Resumaker.aiの人工知能(AI)エンジンは、ユーザーのためにデータを自動的に完了・入力することで、履歴書作成プロセスを簡素化します。Resumaker.aiは、SSL暗号化などの対策を講じて、ユーザーデータを不正アクセスから保護します。ツールのライティングガイドとレコメンデーションを使用して、競合から目立つ履歴書をデザインすることができます。ユーザーは、投稿されたポジションの要件を反映させ、自己紹介を行い、自分の資格に関する主張を裏付けるために数字を活用することができます。 Interviewsby.ai 人工知能によって駆動されるプラットフォームであるInterviewsby.aiを使用することで、求職者はインタビューに備えることができます。ユーザーに合わせた模擬面接中に、人間の言葉を認識・解釈することができる言語モデルであるChatGPTがリアルタイムのフィードバックを提供します。希望する雇用に関する情報を入力することにより、アプリケーションはユーザーに適切で現実的なインタビューの質問を生成することができます。質問を作成する機能により、ユーザーが古くなったり関係のない素材でトレーニングする可能性がなくなります。Interviewsby.aiを使用することで、ユーザーはコントロールされた環境で面接スキルを磨き、自分の強みと弱みに注目した具体的なフィードバックを即座に受けることができます。 Existential ユーザーの興味、才能、価値観を評価することで、AIにより駆動される職業探索ツールであるExistentialは、ユーザーのプロフェッショナルな道筋について具体的な提言を行います。目的は、ユーザーにとって刺激的で挑戦的で満足のいく職業を示唆することです。アプリケーションには簡単な発見プロセスがあり、理想的な仕事に関する特定の質問に答えた後、プログラムはユーザーの興味に最も合った推奨事項を提供します。コミットする前に、ユーザーはこれらの選択肢について詳しく学び、自分の目的に合うかどうかを確認することができます。Existentialは、個人が自分の運命を形作り、仕事に意味を見出すことを目指しています。 Jobscan 求職者は、人工知能(AI)によって駆動されるJobscan ATS Resume CheckerおよびJob Search Toolsを使用することで、面接を受ける可能性を高めることができます。プログラムは、求人情報と応募者の履歴書を分析し、関連する資格を分離するための独自の人工知能アルゴリズムを使用します。応募者の履歴書を分析した後、プログラムは、応募者の強みと改善の余地がある部分を詳細に説明したマッチ率レポートを生成します。Jobscan ATS Resume Checkerの助けを借りて、あなたの履歴書をApplicant Tracking Systems(ATS)に最適化し、注目される可能性を高めることができます。 Aragon 人工知能(AI)によって駆動されるプログラムであるAragon Professional Headshotsは、写真家に行かずに、ヘアメイクに時間をかけずに、修正を待たずに、洗練されたヘッドショットを撮影できるようにするツールです。ユーザーは10枚のセルフィーをアップロードし、ツールは瞬時に40枚の高精細写真を返します。さらに、アプリケーションは、AES256でデータを暗号化し、SOC 2およびISO 27001の認定を取得したサービスプロバイダーにのみデータを保存することにより、ユーザーのプライバシーを保護します。ただし、18歳未満の人は利用しないでください。これは利用規約の違反となります。…

AIの未来を形作る ビジョン・ランゲージ・プリトレーニング・モデルの包括的な調査と、ユニモーダルおよびマルチモーダルタスクにおける役割
機械学習研究の最新リリースで、ビジョン言語事前学習(VLP)とその多様なタスクへの応用について、研究チームが深く掘り下げています。この論文は、単一モーダルトレーニングのアイデアを探究し、それがマルチモーダル適応とどのように異なるかを説明しています。そして、VLPの5つの重要な領域である特徴抽出、モデルアーキテクチャ、事前トレーニング目標、事前トレーニングデータセット、およびダウンストリームタスクを示しています。研究者たちは、既存のVLPモデルとその異なる側面での適応をレビューしています。 人工知能の分野は常に、モデルを人間と同じように知覚、思考、そしてパターンや微妙なニュアンスを理解する方法でトレーニングしようとしてきました。ビジュアル、オーディオ、テキストなど、可能な限り多くのデータ入力フィールドを組み込もうとする試みがいくつか行われてきました。ただし、これらのアプローチのほとんどは、単一モーダル意味で「理解」の問題を解決しようとしたものです。 単一モーダルアプローチは、1つの側面のみを評価するアプローチであり、例えばビデオの場合、音声またはトランスクリプトに焦点を絞っており、マルチモーダルアプローチでは、可能な限り多くの利用可能な特徴をターゲットにしてモデルに組み込もうとします。たとえば、ビデオを分析する際に、音声、トランスクリプト、スピーカーの表情をとらえて、文脈を本当に「理解」することができます。 マルチモーダルアプローチは、リソースが豊富であり、訓練に必要な大量のラベル付きデータを取得することが困難であるため、課題があります。Transformer構造に基づく事前トレーニングモデルは、自己教師あり学習と追加タスクを活用して、大規模な非ラベルデータからユニバーサルな表現を学習することで、この問題に対処しています。 NLPのBERTから始まり、単一モーダルの方法でモデルを事前トレーニングすることで、限られたラベル付きデータでダウンストリームタスクを微調整することができることが示されています。研究者たちは、同じ設計哲学をマルチモーダル分野に拡張することで、ビジョン言語事前学習(VLP)の有効性を探究しました。VLPは、大規模なデータセットで事前トレーニングモデルを使用して、モダリティ間の意味的な対応関係を学習します。 研究者たちは、VLPアプローチの進歩について、5つの主要な領域を検討しています。まず、VLPモデルが画像、ビデオ、テキストを前処理して表現する方法、使用されるさまざまなモデルを強調して説明しています。次に、単一ストリームの観点とその使用可能性、デュアルストリームフュージョンとエンコーダのみ対エンコーダデコーダ設計の観点を探究しています。 論文では、VLPモデルの事前トレーニングについてさらに探求し、完了、マッチング、特定のタイプに分類しています。これらの目標は、ユニバーサルなビジョン言語表現を定義するのに役立ちます。研究者たちは、2つの主要な事前トレーニングデータセットのカテゴリである画像言語モデルとビデオ言語モデルについて概説しました。論文では、マルチモーダルアプローチが文脈を理解し、より適切にマッピングされたコンテンツを生成するためにどのように役立つかを強調しています。最後に、記事は、事前トレーニングモデルの有効性を評価する上での重要性を強調しながら、VLPのダウンストリームタスクの目標と詳細を提示しています。 https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf この論文では、SOTA(State-of-the-Art)のVLPモデルについて詳細な概要が提供されています。これらのモデルをリストアップし、その主要な特徴やパフォーマンスを強調しています。言及されているモデルは、最先端の技術開発の堅固な基盤であり、将来の開発のベンチマークとして役立ちます。 研究論文に基づくと、VLPアーキテクチャの将来は有望で信頼性があります。彼らは、音響情報の統合、知識と認知学習、プロンプトチューニング、モデル圧縮と加速、およびドメイン外の事前学習など、様々な改善の領域を提案しています。これらの改善領域は、新しい研究者たちがVLPの分野で前進し、画期的なアプローチを打ち出すためにインスピレーションを与えることを目的としています。
線形回帰の理論的な深堀り
多くのデータサイエンス志望のブロガーが行うことがあります 線形回帰に関する入門的な記事を書くことですこれは、この分野に入る際に最初に学ぶモデルの1つであるため、自然な選択肢です...
Pythonの依存関係管理:どのツールを選ぶべきですか?
あなたのデータサイエンスプロジェクトが拡大するにつれて、依存関係の数も増えますプロジェクトの環境を再現可能かつメンテナンス可能に保つために、効率的な依存関係を使用することが重要です...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.