Learn more about Search Results Transformer - Page 85

- You may be interested
- 「MM-VID for GPT-4V(ision)による進化す...
- 「データ中心のAIの練習方法と、AIが自分...
- ジェネラティブAIを通じた感情分析のマス...
- コースを安定させる:LLMベースのアプリケ...
- 「初心者向けの14のエキサイティングなPyt...
- 「人生をゲームとして見るならば、それを...
- 「PostgreSQLとOpenAI埋め込みを使用した...
- キャッシュイン:「PAYDAY 3」がGeForce N...
- 「マックス・プランク研究所の研究者がPos...
- 「CityDreamerと出会う:無限の3D都市のた...
- VoAGIニュース、6月28日:データサイエン...
- ~自分自身を~ 繰り返さない
- 「LLMの解読:PythonでスクラッチからTran...
- 「マルチタスクアーキテクチャ:包括的な...
- ChatGPTを使って旅行のスケジュールを計画...
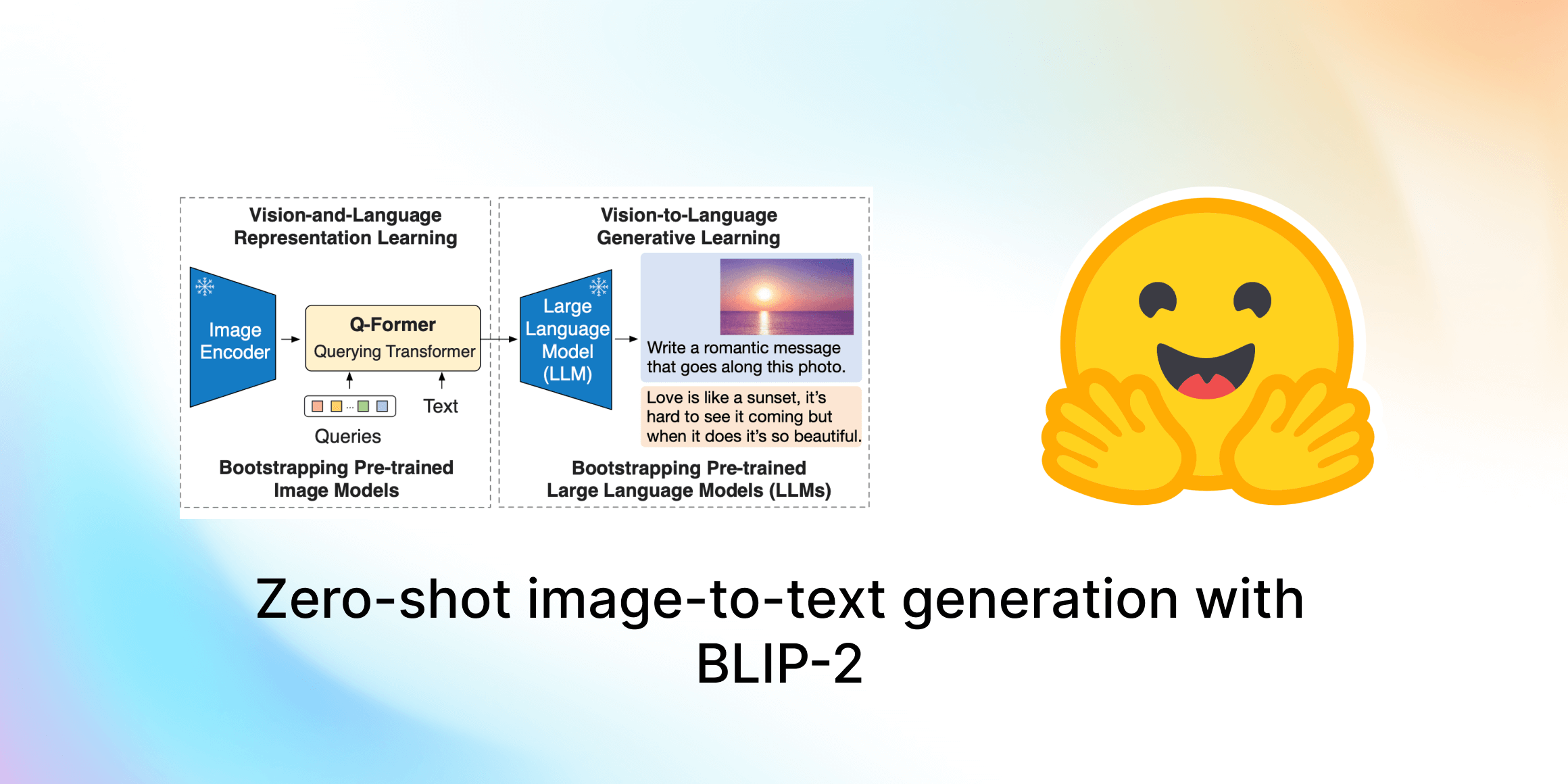
ゼロショット画像からテキスト生成 BLIP-2
このガイドでは、Salesforce ResearchのBLIP-2を紹介します。これは最先端のビジュアル言語モデルのスイートで、現在は🤗 Transformersで利用可能です。画像キャプショニング、プロンプト付き画像キャプショニング、ビジュアルな質問応答、チャットベースのプロンプトに使用する方法を紹介します。 目次 はじめに BLIP-2の内部構造は? Hugging Face TransformersでのBLIP-2の使用 画像キャプショニング プロンプト付き画像キャプショニング ビジュアルな質問応答 チャットベースのプロンプト 結論 謝辞 はじめに 近年、コンピュータビジョンと自然言語処理の分野で急速な進歩がありました。しかし、多くの現実世界の問題は本質的にマルチモーダルです。つまり、画像やテキストなど、複数の異なる形式のデータを含みます。ビジュアル言語モデルは、異なるモダリティを組み合わせることで、さまざまなアプリケーションの可能性を広げるという課題に直面しています。ビジュアル言語モデルが取り組むことができる画像からテキストへのタスクには、画像キャプショニング、画像テキスト検索、ビジュアルな質問応答などがあります。画像キャプショニングは視覚障害者の支援、有用な商品説明の作成、テキスト以外の不適切なコンテンツの特定などに役立ちます。画像テキスト検索はマルチモーダルな検索や自動運転などのアプリケーションに適用することができます。ビジュアルな質問応答は教育に役立ち、マルチモーダルなチャットボットを可能にし、さまざまなドメイン固有の情報検索アプリケーションを支援します。 現代のコンピュータビジョンと自然言語モデルは、より優れた性能を持つ一方で、以前のモデルと比べて大幅にサイズが増えています。単一のモダリティモデルの事前学習はリソースを消費し、高コストですが、ビジョンと言語のエンドツーエンドの事前学習のコストはますます高くなっています。BLIP-2は、事前学習済みのビジョンエンコーダとLLMの組み合わせを活用し、アーキテクチャ全体をエンドツーエンドで事前学習する必要なく、新しいビジュアル言語の事前学習パラダイムを導入することで、この課題に取り組んでいます。これにより、複数のビジュアル言語タスクで最先端の結果を実現しながら、訓練可能なパラメータの数と事前学習コストを大幅に削減することができます。さらに、この手法はマルチモーダルなChatGPTのモデルへの道を切り拓きます。 BLIP-2の内部構造は? BLIP-2は、既製の凍結された事前学習済み画像エンコーダと凍結された大規模言語モデルの間に、軽量なクエリングトランスフォーマ(Q-Former)を追加することで、ビジョンと言語モデルのモダリティのギャップを埋めます。Q-FormerはBLIP-2の唯一の訓練可能な部分であり、画像エンコーダと言語モデルは凍結されたままです。 Q-Formerは、2つのサブモジュールからなるトランスフォーマモデルであり、同じセルフアテンションレイヤを共有しています: 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。 テキストトランスフォーマは、テキストエンコーダおよびテキストデコーダとして機能することができます。 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。…

Hugging FaceとAWSが協力し、AIをよりアクセスしやすくするためにパートナーシップを結成
AIをすべての人に開放し、アクセス可能にする時が来ました。それがHugging FaceとAmazon Web Services(AWS)の拡大した長期戦略的パートナーシップの目標です。両社は、次世代の機械学習モデルの利用可能性を加速させ、機械学習コミュニティがよりアクセスしやすくなり、開発者が最高のパフォーマンスを最低のコストで実現できるよう支援することを目指しています。 新しい世代のオープンでアクセス可能なAI 機械学習はすぐにすべてのアプリケーションに組み込まれつつあります。経済のあらゆるセクターに与える影響が明確になるにつれて、最新のモデルにアクセスし、評価できるようにすることは、これまで以上に重要になっています。AWSとのパートナーシップは、専用のツールを使用してクラウドで最新の機械学習モデルを構築、トレーニング、展開することをより迅速かつ容易にすることで、この未来への道を切り拓いています。 テキスト、音声、画像を処理および生成する新しいTransformerおよびDiffuserの機械学習モデルには、大幅な進歩がありました。しかし、これらの人気のある生成AIモデルのほとんどは公開されておらず、最大のテック企業と他のすべての企業との機械学習能力のギャップを広げています。この傾向に対抗するため、AWSとHugging Faceは協力して、次世代のモデルをグローバルなAIコミュニティに提供し、機械学習を民主化します。戦略的パートナーシップを通じて、Hugging FaceはAWSを優先的なクラウドプロバイダーとして活用し、Hugging Faceのコミュニティの開発者がAWSの最新のツール(Amazon SageMaker、AWS Trainium、AWS Inferentiaなど)にアクセスして、モデルをトレーニング、微調整、展開することができるようにします。これにより、開発者は特定のユースケースに対してモデルのパフォーマンスをさらに最適化し、コストを削減することができます。Hugging Faceは、Amazon SageMakerを使用して最新の革新的な研究成果を適用し、次世代のAIモデルを構築します。Hugging FaceとAWSは、機械学習の最新の進展をグローバルなAIコミュニティが利用できるようにし、生成AIアプリケーションの作成を加速させるためのギャップを埋めています。 「AIの未来はここにありますが、均等には分布していません」とHugging FaceのCEOであるClement Delangueは述べています。「アクセシビリティと透明性は、進歩を共有し、これらの新しい機能を賢明かつ責任を持って使用するためのツールを作成するための鍵です。Amazon SageMakerとAWS設計のチップは、私たちのチームとより大きな機械学習コミュニティが最新の研究をオープンに再現可能なモデルに変換できるようにします。誰でもそれを基礎に構築することができます」。 クラウドでAIを拡大するための協力 この拡大した戦略的パートナーシップにより、Hugging FaceとAWSは、Hugging Faceにホストされている最新のモデルをAmazon…

複雑なテキスト分類のユースケースにおいて、Hugging Faceを活用する
Hugging Faceエキスパートアクセラレーションプログラムとのウィティワークスの成功物語 MLソリューションの迅速な構築に興味がある場合は、エキスパートアクセラレーションプログラムのランディングページをご覧いただき、こちらからお問い合わせください! ビジネスコンテキスト ITが進化し、世界を変え続ける中、業界内でより多様で包括的な環境を作り上げることが重要です。ウィティワークスは、この課題に取り組むために2018年に設立されました。最初は多様性を高めるための組織へのコンサルティング企業としてスタートし、ウィティワークスはまず、包括的な言語を使用した求人広告の作成において彼らを支援しました。この取り組みを拡大するため、2019年には英語、フランス語、ドイツ語で包括的な求人広告の作成を支援するWebアプリを開発しました。そして、その後、ブラウザ拡張機能として機能するライティングアシスタントを追加し、メール、LinkedInの投稿、求人広告などで潜在的なバイアスを自動的に修正し、説明するようにしました。目的は、ハイライトされた単語やフレーズの潜在的なバイアスを説明するマイクロラーニングの手法を提供することで、内部および外部のコミュニケーションにおける文化的変革を促進することでした。 ライティングアシスタントによる提案の例 最初の実験 ウィティワークスは最初に、アシスタントをゼロから構築するために基本的な機械学習アプローチを選びました。事前学習済みのspaCyモデルを使用した転移学習を行い、アシスタントは次のことができました: テキストを分析し、単語をレンマに変換する 言語分析を実行する テキストから言語的な特徴を抽出する(複数形と単数形、性別)、品詞タグ(代名詞、動詞、名詞、形容詞など)、単語の依存関係ラベル、名前付きエンティティの認識など 言語的な特徴に基づいて単語を検出・フィルタリングし、アシスタントは非包括的な単語をリアルタイムでハイライトし、代替案を提案することができました。 課題 語彙には約2300の非包括的な単語やイディオムがあり、それに対して基本的なアプローチは語彙の85%に対してうまく機能しましたが、文脈に依存する単語には失敗しました。そのため、課題は文脈に依存した非包括的な単語の分類器を構築することでした。このような課題(言語的な特徴を認識するのではなく、文脈を理解すること)は、Hugging Face transformersの使用につながりました。 文脈に依存した非包括的な単語の例: 化石燃料は再生可能な資源ではありません。Vs 彼は古い化石です。 柔軟なスケジュールを持っています。Vs スケジュールを柔軟に保つ必要があります。 Hugging Faceエキスパートが提供するソリューション 適切なMLアプローチを決定するためのガイダンスを受ける。…

制御ネット(ControlNet)は、🧨ディフューザー内での使用です
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます! 私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。 写実的なLofiガール また、それをあなたのインテリアデザイナーとして使用することもできます。 Before After あなたはスケッチのスクリブルを芸術的な絵に変えることができます。 Before After さらに、有名なロゴを生き生きとさせることもできます。 Before After ControlNetを使用すると、可能性は無限大です🌠 このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう! ControlNet: TL;DR ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。 ControlNetのトレーニングは次の手順で行われます:…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…
BERTopicとHugging Face Hubの統合をご紹介します
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。 トピックモデリングとは何ですか? トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。 各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。 BERTopicとは何ですか? BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。 BERTopicライブラリの概要 BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。 BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。 Hugging Face Hubを使用したBERTopicモデルの管理 最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。 BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます from bertopic import BERTopic topic_model…

カカオブレインからの新しいViTとALIGNモデル
Kakao BrainとHugging Faceは、新しいオープンソースの画像テキストデータセットCOYO(700億ペア)と、それに基づいてトレーニングされた2つの新しいビジュアル言語モデル、ViTとALIGNをリリースすることを発表しました。ALIGNモデルが無料かつオープンソースで公開されるのは初めてであり、ViTとALIGNモデルのリリースにトレーニングデータセットが付属するのも初めてです。 Kakao BrainのViTとALIGNモデルは、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータに従っていますが、オープンソースのCOYOデータセットでトレーニングされています。GoogleのViTとALIGNモデルは、巨大なデータセット(ViTは3億枚の画像、ALIGNは18億の画像テキストペア)でトレーニングされていますが、データセットが公開されていないため、複製することはできません。この貢献は、データへのアクセスも含めて、視覚言語モデリングを再現したい研究者にとって特に価値があります。Kakao ViTとALIGNモデルの詳細な情報は、こちらで確認できます。 このブログでは、新しいCOYOデータセット、Kakao BrainのViTとALIGNモデル、およびそれらの使用方法について紹介します!以下が主なポイントです: 史上初のオープンソースのALIGNモデル! オープンソースのデータセットCOYOでトレーニングされた初のViTとALIGNモデル Kakao BrainのViTとALIGNモデルは、Googleのバージョンと同等のパフォーマンスを示します ViTとALIGNのデモはHFで利用可能です!選んだ画像サンプルでオンラインでViTとALIGNのデモを試すことができます! パフォーマンスの比較 Kakao BrainのリリースされたViTとALIGNモデルは、Googleが報告した内容と同等またはそれ以上のパフォーマンスを示します。Kakao BrainのALIGN-B7-Baseモデルは、トレーニングペアが少ない(700億ペア対18億ペア)にもかかわらず、Image KNN分類タスクではGoogleのALIGN-B7-Baseと同等のパフォーマンスを発揮し、MS-COCO検索の画像からテキスト、テキストから画像へのタスクではより優れた結果を示します。Kakao BrainのViT-L/16は、モデル解像度384および512でImageNetとImageNet-ReaLで評価された場合、GoogleのViT-L/16と同様のパフォーマンスを発揮します。つまり、コミュニティはKakao BrainのViTとALIGNモデルを使用して、特にトレーニングデータへのアクセスが必要な場合に、GoogleのViTとALIGNリリースを再現することができます。最先端の性能を発揮しつつ、オープンソースで透明性のあるこれらのモデルのリリースを見ることができるのはとても興奮します! COYOデータセット これらのモデルのリリースの特徴は、モデルが無料かつアクセス可能なCOYOデータセットでトレーニングされていることです。COYOは、GoogleのALIGN 1.8B画像テキストデータセットに似た700億ペアの画像テキストデータセットであり、ウェブページから取得した「ノイズのある」代替テキストと画像のペアのコレクションですが、オープンソースです。COYO-700MとALIGN 1.8Bは「ノイズのある」データセットですが、最小限のフィルタリングが適用されています。COYOは、他のオープンソースの画像テキストデータセットであるLAIONとは異なり、以下の点が異なります。…

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…
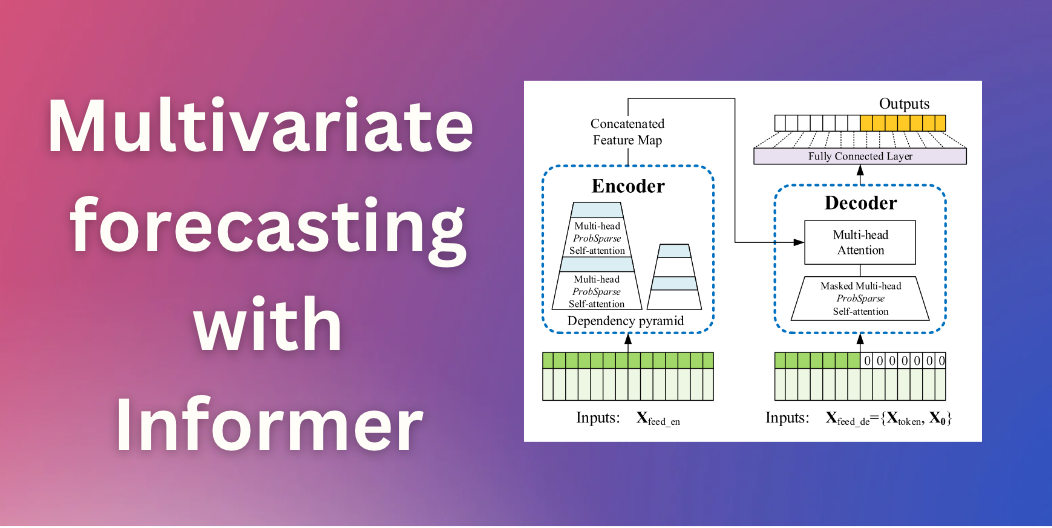
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

ディフューザを使用してControlNetをトレーニングしてください
イントロダクション ControlNetは、追加の条件を付加することで拡散モデルを細かく制御することができるニューラルネットワーク構造です。この技術は、「Adding Conditional Control to Text-to-Image Diffusion Models」という論文で登場し、すぐにオープンソースの拡散コミュニティで広まりました。著者はStable Diffusion v1-5を制御するための8つの異なる条件をリリースしました。これには、ポーズ推定、深度マップ、キャニーエッジ、スケッチなどが含まれます。 このブログ投稿では、3Dシンセティックフェイスに基づいた顔のポーズモデルであるUncanny Facesモデルのトレーニング手順を詳細に説明します(実際にはUncanny Facesは予期しない結果であり、それがどのように実現されたかについては後ほどご紹介します)。 安定した拡散のためのControlNetのトレーニングの始め方 独自のControlNetをトレーニングするには、3つのステップが必要です: 条件の計画:ControlNetはStable Diffusionをさまざまなタスクに対応できる柔軟性があります。事前にトレーニングされたモデルはさまざまな条件を示しており、コミュニティはピクセル化されたカラーパレットに基づいた他の条件を作成しています。 データセットの構築:条件が決まったら、データセットの構築の時間です。そのためには、データセットをゼロから構築するか、既存のデータセットの一部を使用することができます。モデルをトレーニングするためには、データセットには3つの列が必要です:正解のimage、conditioning_image、およびprompt。 モデルのトレーニング:データセットの準備ができたら、モデルのトレーニングの時間です。これは、ディフューザーのトレーニングスクリプトのおかげで最も簡単な部分です。少なくとも8GBのVRAMを持つGPUが必要です。 1. 条件の計画 条件を計画するために、次の2つの質問を考えると役立ちます: どのような条件を使用したいですか? 既存のモデルで「通常の」画像を私の条件に変換できるものはありますか?…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.