Learn more about Search Results ス - Page 852

- You may be interested
- MongoDBで結合操作を実行するためのシンプ...
- 「データに基づくストーリーテリングのた...
- AI時代の運転:AIへの恐怖が命を奪う代償...
- ReAct、Reasoning and Actingは、LLMをツ...
- イーロン・マスクのニューラリンクによる...
- データサイエンスのための善 利益を超えて...
- 「IBMのワトソンXコードアシスタントと出...
- 「AIドクター」は、入院後の再入院やその...
- 「2023年および2024年に注目すべきトップ7...
- 企業管理ソフトウェアはAI統合からどのよ...
- 「おそらく知らなかった4つのPython Itert...
- 「データモデリングのための一般人向けガ...
- ボードゲームをプレイするためのAIの教育
- 基本に戻ろう:プロビット回帰
- OpenCVを使用したカメラキャリブレーション

検索増強視覚言語事前学習
Google Research Perceptionチームの学生研究者Ziniu Huと研究科学者Alireza Fathiによる投稿 T5、GPT-3、PaLM、Flamingo、PaLIなどの大規模なモデルは、数百億のパラメータにスケーリングされ、大規模なテキストおよび画像データセットでトレーニングされると、多大な量の知識を格納する能力を示しました。これらのモデルは、画像キャプション、ビジュアルクエスチョンアンサリング、オープンボキャブラリー認識などのダウンストリームタスクで最先端の結果を達成しています。しかし、これらのモデルはトレーニングに膨大な量のデータを必要とし、数十億のパラメータ(多くの場合)を持ち、著しい計算要件を引き起こします。また、これらのモデルをトレーニングするために使用されるデータは古くなる可能性があり、世界の知識が更新されるたびに再トレーニングが必要になる場合があります。たとえば、2年前にトレーニングされたモデルは、現在のアメリカ合衆国大統領に関する古い情報を提供する可能性があります。 自然言語処理(RETRO、REALM)およびコンピュータビジョン(KAT)の分野では、検索増強モデルを使用してこれらの課題に取り組む研究がなされてきました。通常、これらのモデルは、単一のモダリティ(テキストのみまたは画像のみ)を処理できるバックボーンを使用して、知識コーパスから情報をエンコードおよび取得します。ただし、これらの検索増強モデルは、クエリと知識コーパスのすべての利用可能なモダリティを活用できず、モデルの出力を生成するために最も役立つ情報を見つけられない場合があります。 これらの問題に対処するために、「REVEAL:Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory」(CVPR 2023に掲載予定)では、複数のソースのマルチモーダル「メモリ」を利用して知識集中型クエリに答えることを学ぶビジュアル言語モデルを紹介します。REVEALは、ニューラル表現学習を使用して、さまざまな知識ソースをキー-バリューペアから成るメモリ構造に変換し、エンコードします。キーはメモリアイテムのインデックスとして機能し、対応する値はそれらのアイテムに関する関連情報を格納します。トレーニング中、REVEALは、キーエンベッディング、値トークン、およびこのメモリから情報を取得する能力を学習して、知識集中型クエリに対処します。このアプローチにより、モデルパラメータは暗記に専念するのではなく、クエリに関する推論に焦点を当てることができます。 多様な知識ソースから複数の知識エントリを取得する能力を持つビジュアル言語モデルを拡張することで、生成を支援します。 マルチモーダル知識コーパスからのメモリ構築 私たちのアプローチは、異なるソースからの知識アイテムのキーと値のエンベッディングを事前に計算し、キー-バリューペアにエンコードして統一された知識メモリにインデックスするREALMと似ています。各知識アイテムは、より詳細に表現されたトークンエンベッディングのシーケンスである値としてエンコードされます。以前の研究とは異なり、REVEALは、WikiData知識グラフ、Wikipediaのパッセージと画像、Web画像テキストペア、ビジュアルクエスチョンアンサリングデータなど、多様なマルチモーダル知識コーパスを活用しています。各知識アイテムは、テキスト、画像、両方の組み合わせ(たとえば、Wikipediaのページ)、または知識グラフからの関係または属性(たとえば、バラク・オバマは6’2 “の背丈)の場合があります。トレーニング中、モデルパラメータが更新されるたびに、REVEALはキーと値のエンベッディングを連続的に再計算します。ステップごとにメモリを非同期に更新します。 圧縮を使用したメモリのスケーリング メモリ値をエンコードするための素朴な解決策は、各知識アイテムのトークンのすべてのシーケンスを保持することです。次に、モデルは、すべてのトークンを連結してトランスフォーマーエンコーダーデコーダーパイプラインに送信することで、入力クエリとトップkの取得されたメモリ値を融合することができます。このアプローチには2つの問題があります。1つ目は、数億の知識アイテムをメモリに保持する場合、各メモリ値が数百のトークンから構成されている場合、実用的ではないことです。2つ目は、トランスフォーマーエンコーダーが自己注意のために合計トークン数×kに対して2次の複雑度を持っていることです。そのため、Perceiverアーキテクチャを使用して知識アイテムをエンコードおよび圧縮することを提案しています。Perceiverモデルは、トランスフォーマーデコーダーを使用して、フルトークンシーケンスを任意の長さに圧縮します。これにより、kが100にもなるトップkメモリエントリを取得できます。 以下の図は、メモリのキー-バリューペアを構築する手順を示しています。各知識項目は、マルチモーダル視覚言語エンコーダを介して処理され、画像とテキストのトークンのシーケンスに変換されます。キー・ヘッドはこれらのトークンをコンパクトな埋め込みベクトルに変換します。バリュー・ヘッド(パーセプター)は、これらのトークンを少なくし、知識項目に関する適切な情報を保持します。 異なるコーパスからの知識エントリを統一されたキーとバリューの埋め込みペアにエンコードし、キーはメモリのインデックスに使用され、値にはエントリに関する情報が含まれます。…

アクセラレータの加速化:科学者がGPUとAIでCERNのHPCを高速化
注:これは、高性能コンピューティングを利用した科学を前進させる研究者のシリーズの一環です。 Maria Gironeは、高速コンピューティングとAIを用いて、世界最大の科学コンピュータネットワークを拡大しています。 2002年以来、粒子物理学の博士号を持つ彼女は、40以上の国の170以上のサイトにまたがるシステムのグリッドで、CERNの大型ハドロン衝突型加速器(LHC)をサポートしています。HL-LHCと呼ばれる巨大加速器の高輝度版は、1年にエクサバイト単位のデータを生成する10倍の陽子衝突を生み出します。これは、2012年に2つの実験で宇宙の科学者たちの理解を確認したサブ原子粒子であるヒッグスボソンを発見したときに生成されたものよりも桁違いに多いです。 ジュネーブの呼び声 彼女は南イタリアで育った最初の日から科学が大好きでした。 「大学で、宇宙を支配する基本的な力について学びたかったので、物理学に焦点を合わせました」と彼女は言います。「私はCERNに惹かれました。それは、世界中の異なる地域の人々が科学に共通の情熱を持って一緒に働く場所です。」 レマン湖とジュラ山脈の間にある欧州原子核研究機構は、1万2千人以上の物理学者の中心地です。 CERNとフランス・スイス国境にあるLHCの地図(CERN提供の画像) 27キロメートルのリングは、陽子が光速の99.9999991%で疾走する世界最速のレーシングトラックと呼ばれることがあります。超伝導磁石は絶対零度に近く動作し、太陽よりも一時的に何百万倍も熱い衝突を生み出します。 ラボのドアを開く 2016年、Gironeは、革新を加速し、将来のコンピューティング課題に取り組むために学術および産業研究者を集めるグループであるCERN openlabのCTOに任命されました。彼女は、イタリアのHPCおよびAIの専門家であるE4 Computer Engineeringとの協力を通じて、NVIDIAと密接に協力しています。 最初の行動の1つで、GironeはCERN openlabのAIに関する最初のワークショップを開催しました。 産業界の参加者たちは、その技術に熱心でした。物理学者たちは、課題について説明しました。 「その日の終わりに、私たちは2つの異なる世界から来たことに気づきましたが、人々はお互いに耳を傾け、熱心に次に何をするか提案しました」と彼女は言います。 物理AIの高まり 今日、高エネルギー物理学全体のデータ処理チェーンにAIを適用する出版物の数が増加しているとGironeは報告しています。彼女は、複雑な問題をAIで解決する機会を見出す若い研究者を引き付けると述べています。 一方、研究者たちは物理ソフトウェアをGPUアクセラレータに移植し、GPU上で実行される既存のAIプログラムを使用しています。 「NVIDIAの支援なしに、私たちの研究者が問題を解決し、質問に答え、記事を書くために協力することは、これほど迅速には起こりませんでした」と彼女は言います。「NVIDIAの人々が、科学が技術と並行して進化する方法、およびGPUを用いたアクセラレーションをどのように利用できるかを理解していることは、非常に重要でした。」 エネルギー効率は、Gironeのチームの別の優先事項です。…
Microsoft BingはNVIDIA Tritonを使用して広告配信を高速化
Jiusheng Chen氏のチームは加速しました。 彼らは、NVIDIA Triton Inference ServerをNVIDIA A100 Tensor Core GPUで実行することにより、Microsoft Bingのユーザーに対してパーソナライズされた広告を7倍のスループットで低コストで提供しています。 主任ソフトウェアエンジニアリングマネージャーと彼のクルーにとって、これは素晴らしい成果です。 複雑なシステムの調整 Bingの広告サービスは、常に進化している数百のモデルを使用しています。それぞれは、10ミリ秒未満のリクエストに応答する必要があります。これは目に見えるのと同じくらい速いです。 最新のスピードアップは、AIモデルをより高速に実行するためにチームが提供した2つの革新に始まりました:BangとEL-Attention。 これらを併用することで、より少ない時間とコンピュータメモリでより多くの処理を行うための高度な技術が適用されます。モデルトレーニングは、効率化のためにAzure Machine Learningをベースにしています。 NVIDIA A100 MIGで飛行 次に、チームは、広告サービスをNVIDIA T4からA100 GPUにアップグレードしました。…

AIを学校に持ち込む:MITのアナント・アガルワルとの対話
NVIDIAのAI Podcastの最新エピソードで、edXの創設者であり2Uの最高プラットフォーム責任者であるAnant Agarwal氏は、オンライン教育の未来と、AIが学習体験を革新している方法について語りました。 大規模オープンオンラインコース(MOOC)の強力な提唱者であるAgarwal氏は、教育のアクセシビリティと品質の重要性について話しました。このMITの教授であり、著名なedtechの先駆者でもある彼は、edXプラットフォームでのChatGPTプラグインや、AIによる学習アシスタントであるedX Xpertの実装を強調しました。 関連記事 Jules Anh Tuan Nguyen氏が説明する、AIが切断された手の義手やビデオゲームを操作する方法 ミネソタ大学のポストドクトラル研究者が、義手を手の指の動きまで自分の意思で制御できるようにする取り組みについて説明しています。 OverjetのAi Wardah Inam氏が歯科医療にAIを導入することについて語る NVIDIA InceptionのメンバーであるOverjetは、AIを歯科医療に導入することを急いでいます。同社のCEOであるWardah Inam博士は、AIを利用して患者ケアを改善することについて説明しています。 ImmunaiのCTO兼共同創設者であるLuis Voloch氏が、深層学習を用いた新しい薬剤の開発について語る Immunaiの共同創設者兼最高技術責任者であるLuis Voloch氏は、機械学習とデータサイエンスのマインドセットで免疫システムの課題に取り組むことについて話しています。 AI Podcastを購読する:Amazon Musicで利用可能…

Link-credible:Steam、Epic Games Store、Ubisoftアカウントリンクを使用して、GeForce NOWでより速くゲームに参加しましょう
Steam、Epic Games Store、UbisoftアカウントにGeForce NOWをリンクして、お気に入りのゲームにより迅速にアクセスできます。 また、Ubisoft Forwardが6月12日(月)に開催されるので、最新のニュースや発表を披露するゲームパブリッシャーの今後のGeForce NOWに追加されるゲームを垣間見ることができます。 さらに、今週は2つの新しいゲームがクラウドからストリーミングできるようになりました。また、UbisoftからTom Clancy’s The Division 2の最新シーズンも配信開始となります。 リンクされたアカウント GeForce NOWは、Steam、Epic、そして最近ではUbisoftのアカウントを直接サービスにリンクすることで、メンバーにとってゲームを便利かつ簡単にすることができます。各プレイセッションごとにアカウントにサインインする必要がなく、一度リンクするだけで、メンバーはデバイス間で自動的にサインインできるようになります。 自動的で超音速。 今日から、Ubisoft Connectゲームを起動するには、アプリ内でUbisoftアカウントをリンクする必要があります。これが完了すると、Rainbow Six Siege、Far Cry 6、The Division 2などの人気Ubisoftゲームを簡単にプレイできます。…

進め、GOを通過し、もっと多くのゲームを収集:Xbox Game PassがGeForce NOWにやってくる
Xbox Game PassのサポートがGeForce NOWにやってきます。 メンバーは間もなく、NVIDIAのクラウドゲームサーバーを通じてXbox Game PassカタログからサポートされたPCゲームをプレイできるようになります。Game PassおよびMicrosoft Storeのサポートが今後数ヶ月で展開される方法について詳しくはこちら。 さらに、Age of Empires IV:Anniversary Editionは、世界で最も人気のあるリアルタイムストラテジーフランチャイズの最初のタイトルとしてGeForce NOWに登場します。 Game Pass-tic Partnership 先週末発表されたところによると、Game Passメンバーは間もなく、GeForce NOWでGame PassカタログのサポートされたPCゲームをプレイできるようになります。 来る数ヶ月で、@XboxGamePassPCのゲームをNVIDIA GeForce…
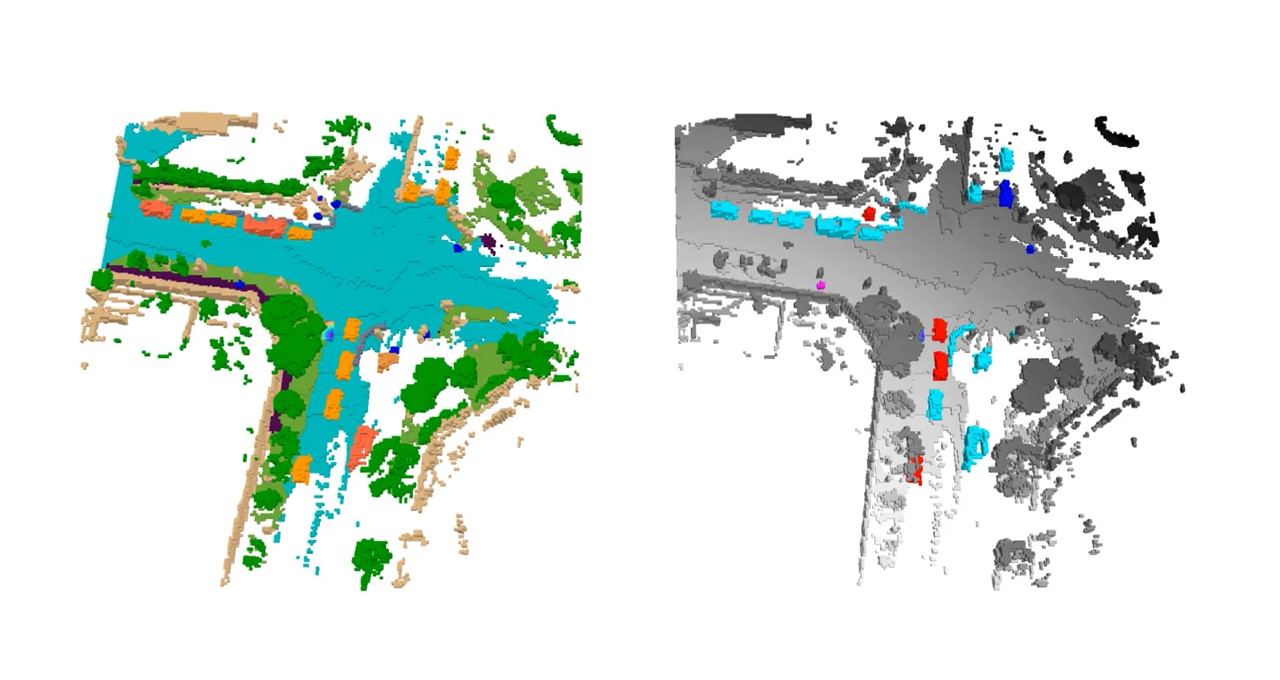
NVIDIAリサーチがCVPRで自律走行チャレンジとイノベーション賞を受賞
NVIDIAは、カナダのバンクーバーで開催されるComputer Vision and Pattern Recognition Conference(CVPR)において、自律走行開発の3D占有予測チャレンジで激戦を制し、優勝者として紹介されます。 この競技には、10地域にまたがる約150チームから400以上の投稿がありました。 3D占有予測とは、シーン内の各ボクセルの状態を予測するプロセスであり、つまり3Dバードアイビューグリッド上の各データポイントを指します。ボクセルは、フリー、占有、または不明として識別することができます。 安全で堅牢な自動運転システムの開発に不可欠な3D占有グリッド予測は、NVIDIA DRIVEプラットフォームによって可能になる最新の畳み込みニューラルネットワークやトランスフォーマーモデルを使用して、自律車両(AV)の計画および制御スタックに情報を提供します。 「NVIDIAの優勝ソリューションには、2つの重要なAVの進歩があります」と、NVIDIAの学習と知覚のシニアリサーチサイエンティストであるZhiding Yu氏は述べています。「優れたバードアイビュー認識を生み出す最新のモデル設計を実証することができます。さらに、3D占有予測での10億パラメーターまでのビジュアルファウンデーションモデルの効果と大規模な事前学習の有効性を示しています。」 自動運転の知覚は、画像内のオブジェクトや空きスペースなどの2Dタスクの処理から、複数の入力画像を使用して3Dで世界を理解することに進化しています。 これにより、複雑な交通シーン内のオブジェクトについて柔軟で精密な細かい表現が提供されるようになり、これはNVIDIAのAV応用研究および著名な科学者であるJose Alvarez氏によれば、「自律走行の安全感知要件を達成するために重要です。」 Yu氏は、NVIDIA Researchチームの受賞作品を、6月18日(日)10:20 a.m. PTに開催されるCVPRのEnd-to-End Autonomous Driving Workshopおよび6月19日(月)4:00 p.m. PTに開催されるVision-Centric…

Python開発のための12のVSCodeのヒントとトリック
VSCode からより少なくしてより多くを達成するための簡単なヒント

2023年に知っておく必要があるデータ分析ツール
成功するデータアナリストになるために知っておく必要があるツールは何ですか?
Rによるディープラーニング
このチュートリアルでは、Rで深層学習タスクを実行する方法を学びます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.