Learn more about Search Results リポジトリ - Page 83

- You may be interested
- 「AIパワード広告でソーシャルをより魅力...
- 言語モデルの構築:ステップバイステップ...
- 効率的にPythonコードを書く方法:初心者...
- 「3歳のロボットの子育て」
- ギアアップしてゲームオン:ギアボックス...
- 「大規模な言語モデルの公正な評価に向けて」
- 打ち上げ!最初のMLプロジェクトを始める...
- 「Declarai、FastAPI、およびStreamlitを...
- 「自然再造プロジェクトのグローバルな潜...
- 「AI意識の展開」
- 「マイクロソフト、Windows上でのCortana...
- 「ChatGPTの新しいカスタム指示がリリース...
- プロンプトエンジニアリングにおける並列...
- 複雑なAIモデルの解読:パデュー大学の研...
- Google AIは、環境の多様性と報酬の指定の...

MLにおけるETLデータパイプラインの構築方法
データ処理から迅速な洞察まで、頑強なパイプラインはどんなMLシステムにとっても必須ですデータチーム(データとMLエンジニアで構成される)はしばしばこのインフラを構築する必要があり、この経験は苦痛となることがありますしかし、MLでETLパイプラインを効率的に使用することで、彼らの生活をはるかに楽にすることができます本記事では、その重要性について探求します...

小売およびeコマースにおけるMLプラットフォームの構築
組織内で機械学習を利用して難しい問題を解決することは素晴らしいですさらに、eコマース企業にはMLが役立つケースがたくさんありますただし、より多くのMLモデルやシステムが本番環境で稼働するにつれて、信頼性のある管理のためにより多くのインフラが必要になりますそのため、多くの...

2023年のMLOpsの景色:トップのツールとプラットフォーム
2023年のMLOpsの領域に深く入り込むと、多くのツールやプラットフォームが存在し、モデルの開発、展開、監視の方法を形作っています総合的な概要を提供するため、この記事ではMLOpsおよびFMOps(またはLLMOps)エコシステムの主要なプレーヤーについて探求します...

Acme 分散強化学習のための新しいフレームワーク
Acmeは、読みやすく効率的な、研究指向の強化学習(RL)アルゴリズムを構築するためのフレームワークですAcmeのコアには、分散エージェントを含むさまざまな実行規模で実行できるRLエージェントの簡単な記述を可能にする設計思想がありますAcmeのリリースにより、学術研究機関や産業研究所で開発されたさまざまなRLアルゴリズムの結果を、機械学習コミュニティ全体で再現し拡張することが容易になることを目指しています

ロボット用の物理シミュレータを公開する
歩く時、足が地面に触れます書く時、指がペンに触れます物理的な接触が世界との相互作用を可能にしますしかし、このような普通の出来事でも、接触は驚くほど複雑な現象です2つの物体の界面で微小なスケールで起こる接触は、柔らかい場合もあれば硬い場合もあり、弾力的な場合もあればスポンジ状の場合もあり、滑りやすい場合もあれば粘り気のある場合もあります私たちの指先には4つの異なるタイプの触覚センサーがあるのも不思議ではありませんこの微妙な複雑さが、ロボット研究の重要な要素である物理的接触のシミュレーションを難しい課題にしています
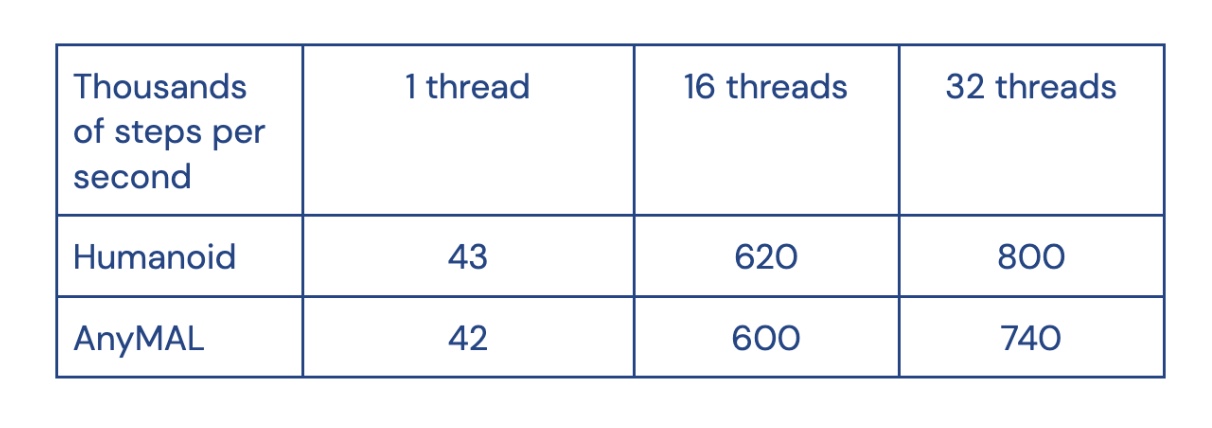
MuJoCoをオープンソース化
2021年10月、私たちはMuJoCo物理シミュレータを取得し、研究をサポートするために誰でも自由に利用できるようにしましたことを発表しましたまた、MuJoCoを最高水準の能力を持つフリーでオープンソースのコミュニティ主導のプロジェクトとして開発・維持することを約束しました本日、喜ばしいお知らせですが、オープンソース化が完了し、コードベース全体がGitHub上にあります!ここでは、なぜMuJoCoがオープンソースの協力プラットフォームとして優れているのかを説明し、今後のロードマップのプレビューを共有します

AlphaTensorを使用して新しいアルゴリズムを発見する
本日、Natureに掲載された私たちの論文では、AlphaTensorという初めての人工知能(AI)システムを紹介しましたこのシステムは、行列の乗算といった基礎的なタスクのための新しい効率的で証明可能なアルゴリズムを発見するためのものですこれにより、50年にわたる数学の未解決問題である行列の乗算を最速で行う方法を見つけることが可能となりましたこの論文はDeepMindがAIを使って科学を進め、最も基本的な問題を解決するための礎となるものです私たちのAlphaTensorシステムは、将棋やチェス、囲碁などのボードゲームで超人的な成績を収めたエージェントであるAlphaZeroを基にしており、この論文ではAlphaZeroがゲームから未解決の数学の問題に挑戦するまでの道のりを示しています

あなたのオープンソースのLLMプロジェクトはどれくらいリスクがあるのでしょうか?新たな研究がオープンソースのLLMに関連するリスク要因を説明しています
大規模言語モデル(LLM)と生成AI、例えばGPTエンジンは、最近AIの領域で大きな波を起こしており、小売個人や企業の間でこの新しいテクノロジーの波に乗ることへの大きな期待が市場に広がっています。しかし、この技術が市場で複数のユースケースを急速に担っている中で、特にオープンソースのLLMに関連するリスクについて、より詳細に注意を払い、使用に関連するリスクについてもっと詳細に注意を払う必要があります。 有名な自動ソフトウェア供給チェーンセキュリティプラットフォームであるRezilionが最近行った研究では、この具体的な問題を調査し、その結果は私たちを驚かせます。彼らは次の条件に合致するすべてのプロジェクトを考慮しました: 8ヶ月以内に作成されたプロジェクト(この論文の発表時点での2022年11月から2023年6月まで) LLM、ChatGPT、Open-AI、GPT-3.5、またはGPT-4のトピックに関連するプロジェクト GitHubで少なくとも3,000のスターを持つプロジェクト これらの条件により、主要なプロジェクトが研究の対象になることが保証されました。 彼らは研究を説明するために、Open Source Security Foundation(OSSF)が作成したScorecardというフレームワークを使用しました。Scorecardは、オープンソースプロジェクトのセキュリティを評価し、改善することを目的としたSASTツールです。評価は、脆弱性の数、定期的なメンテナンスの頻度、バイナリファイルの有無など、リポジトリに関するさまざまな情報に基づいて行われます。 これらのチェックの目的は、セキュリティのベストプラクティスと業界標準の遵守を確保することです。各チェックにはリスクレベルが関連付けられています。リスクレベルは、特定のベストプラクティスに準拠しないことに関連する推定リスクを表し、スコアに重みを加えます。 現在、18のチェックは3つのテーマに分けることができます:包括的なセキュリティプラクティス、ソースコードのリスク評価、およびビルドプロセスのリスク評価。OpenSSF Scorecardは、各チェックに対して0から10の序数スコアとリスクレベルスコアを割り当てます。 結果として、これらのほとんどのオープンソースのLLMとプロジェクトは、専門家が以下のように分類した重要なセキュリティ上の懸念事項に取り組んでいます: 1.信頼境界のリスク 不適切なサンドボックス化、不正なコードの実行、SSRFの脆弱性、不十分なアクセス制御、さらにはプロンプトインジェクションなどのリスクは、信頼境界の一般的な概念に該当します。 誰でも任意の悪意のあるnlpマスクコマンドを挿入することができ、それは複数のチャンネルを越えて伝播し、ソフトウェアチェーン全体に深刻な影響を与える可能性があります。 人気のある例の1つはCVE-2023-29374 LangChainの脆弱性(3番目に人気のあるオープンソースgpt)です。 2. データ管理リスク データ漏洩やトレーニングデータの改竄は、データ管理のリスクカテゴリに該当します。これらのリスクは、大規模言語モデルに限定されるものではなく、どんな機械学習システムにも関連しています。 トレーニングデータの改竄は、攻撃者がLLMのトレーニングデータや微調整手順を意図的に操作して、モデルのセキュリティ、効果性、倫理的な振る舞いを損なう脆弱性、バックドア、バイアスを導入することを指します。この悪意のある行為は、トレーニングプロセス中に誤解を招く情報や有害な情報を注入することで、LLMの完全性と信頼性を危険にさらすことを目的としています。 3.…

DataHour ChatGPTの幻視を80%減らす
はじめに 自然言語処理(NLP)モデルは近年、チャットボットから言語翻訳までさまざまなアプリケーションで人気が高まっています。しかし、NLPの最大の課題の1つは、モデルによって生成されるChatGPTの幻覚や不正確な応答を削減することです。この記事では、NLPモデルの幻覚を削減するために必要な技術と課題について説明します。 観測性、調整、テスト 幻覚を削減するための最初のステップは、モデルの観測性を向上させることです。これには、ユーザーフィードバックとモデルのパフォーマンスをプロダクションでキャプチャするフィードバックループの構築が含まれます。調整では、より多くのデータを追加したり、検索の問題を修正したり、プロンプトを変更したりすることで、不正確な応答を改善します。テストは、変更が結果を改善し、回帰を引き起こさないことを確認するために必要です。観測性の課題には、顧客が不正確な応答のスクリーンショットを送信することによって引き起こされるイライラが含まれます。これに対処するために、データの取り込みと秘密のコードを使用してログを毎日監視することができます。 言語モデルのデバッグとチューニング 言語モデルのデバッグとチューニングのプロセスでは、モデルの入力と応答を理解することが重要です。デバッグには、生のプロンプトを特定のチャンクや参照に絞り込むためにログが必要です。ログは、誰にでも理解しやすく、実行可能なものでなければなりません。チューニングでは、モデルにどれだけのドキュメントを与えるべきかを決定します。デフォルトの数値は常に正確ではなく、類似検索では正しい答えが得られないことがあります。目標は、何がうまくいかなかったのか、それを修正する方法を見つけることです。 OpenAI埋め込みの最適化 アプリケーションで使用されるOpenAI埋め込みのパフォーマンスを最適化することに直面したベクトルデータベースクエリアプリケーションの開発者は、いくつかの課題に直面しました。最初の課題は、モデルに渡す最適なドキュメント数を決定することであり、これはチャンキング戦略の制御とドキュメント数のための制御可能なハイパーパラメータの導入によって解決されました。 2番目の課題は、プロンプトのバリエーションであり、Better Promptというオープンソースライブラリを使用して、パープレキシティに基づいて異なるプロンプトバージョンのパフォーマンスを評価しました。3番目の課題は、マルチリンガルシナリオでの文の変換子よりもOpenAI埋め込みの結果の改善が見つかったことです。 AI開発の技術 この記事では、AI開発で使用される3つの異なる技術について説明しています。最初の技術はパープレキシティであり、与えられたタスクにおけるプロンプトのパフォーマンスを評価するために使用されます。2番目の技術は、ユーザーが異なるプロンプト戦略を簡単にテストできるパッケージの構築です。3番目の技術は、インデックスの実行であり、何かが欠けているか理想的でない場合に追加のデータを使用してインデックスを更新することが含まれます。これにより、質問のよりダイナミックな処理が可能になります。 GPT-3 APIを使用してパープレキシティを計算する スピーカーは、クエリに基づいてパープレキシティを計算するためにGPT-3 APIを使用した経験について説明しています。彼らはAPIを介してプロンプトを実行し、最適な次のトークンのログ確率を返すプロセスについて説明しています。また、新しい情報を埋め込むのではなく、特定の書き方を模倣するために大規模な言語モデルを微調整する可能性についても言及しています。 複数の質問に対する応答の評価 テキストでは、50以上の質問に対する応答の評価の課題について説明しています。すべての応答を手動で採点するのは時間がかかるため、会社は自動評価ツールの使用を検討しました。しかし、単純なはい/いいえの判断枠組みでは不十分であり、回答が正しくない理由は複数あります。会社は評価をさまざまなコンポーネントに分割しましたが、自動評価ツールの単一の実行は不安定で一貫性がありませんでした。これを解決するために、質問ごとに複数のテストを実行し、応答を完璧、ほぼ完璧、一部正しい情報を含む不正確、完全に不正確なものに分類しました。 NLPモデルでの幻覚の削減 スピーカーは、自然言語処理モデルでの幻覚を削減するためのプロセスについて説明しています。彼らは意思決定プロセスを4つのカテゴリに分け、50以上のカテゴリに対して自動機能を使用しました。また、評価プロセスをコア製品に展開し、評価を実行してCSBにエクスポートすることも可能にしました。スピーカーはプロジェクトに関する詳細情報のためのGitHubリポジトリに言及しています。そして、観測性、調整、テストなどの手順を取り上げ、幻覚率を40%から5%未満に削減することができました。 結論 NLPモデルにおけるChatGPTの幻想を減らすことは、可観測性、調整、テストといった複雑なプロセスを必要とします。開発者はプロンプトのバリエーション、埋め込みの最適化、複数の質問に対する応答の評価も考慮する必要があります。また、困惑度、プロンプト戦略のテスト用パッケージの作成、インデックスの実行といったテクニックもAI開発に役立つことがあります。AI開発の未来は、小規模でプライベート、またはタスク固有の要素にあります。 要点 NLPモデルにおけるChatGPTの幻想を減らすには、可観測性、調整、テストが必要です。…
学習トランスフォーマーコード入門:パート1 – セットアップ
あなたについてはわかりませんが、コードを見ることの方が論文を読むよりも簡単なことがありますAdventureGPTに取り組んでいた時、まずはReActの実装であるBabyAGIのソースコードを読むことから始めました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.