Learn more about Search Results A - Page 834

- You may be interested
- Google DeepMindの研究者たちは、RT-2とい...
- 「責任ある生成AIのための3つの新興プラク...
- 「Appleが『AppleGPT』チャットボットを使...
- 私たちのインターン生の未来づくり:AIの...
- AIを学校に持ち込む:MITのアナント・アガ...
- 「ハロー効果:AIがサンゴ礁保護に深く関...
- AIの力による医療の革命:患者ケアと診断...
- 「ReactJSとChatGPTの統合:包括的なガイド」
- サンタクララ大学を卒業した早熟なティー...
- Earth.comとProvectusがAmazon SageMaker...
- 「UCLとイギリス帝国大学の研究者が、タス...
- 「Falcon 180Bをご紹介します:1800億のパ...
- ゾマト感情分析
- UCバークレーとスタンフォードの研究者チ...
- 最も近い近隣法を用いた写真モザイク:デ...

Pythonを使用して北極の氷の傾向を分析する
Pythonは、データサイエンスのための卓越したプログラミング言語として、計測データを収集・クリーニング・解釈することが容易になりますPythonを使って、予測をバックテストし、モデルを検証することができますそして...
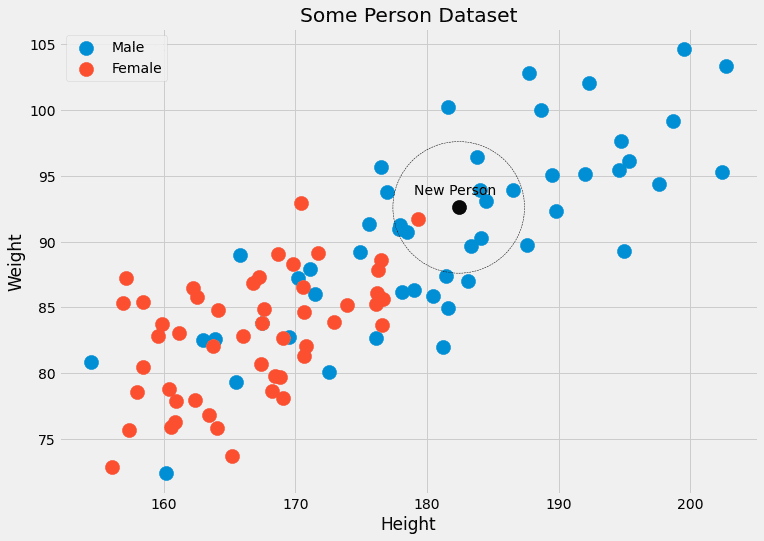
理論から実践へ:k最近傍法分類器の構築
k-最近傍法分類器は、新しいデータポイントを、k個の最も近い隣人の中で最も一般的なクラスに割り当てる機械学習アルゴリズムですこのチュートリアルでは、Pythonでこの分類器を構築および適用する基本的な手順を学びます

マイクロソフトリサーチは、競合モデルよりも大幅に小さいサイズで、Pythonコーディングに特化した新しい大規模言語モデルphi-1を紹介しました
トランスフォーマーのデザインが発見されて以来、大規模な人工ニューラルネットワークのトレーニングの技術は飛躍的に進歩してきましたが、この成果の基礎となる科学はまだ幼い段階にあります。同じ時期にトランスフォーマーがリリースされたことで、圧倒的で混乱するような結果の中に秩序が出現し、計算量またはネットワークサイズを増やすと性能が予測可能に向上するというスケーリング則が判明しました。これらのスケーリング則は、深層学習におけるスケールの調査のためのガイドとして機能し、これらの則の変化の発見により性能が急激に向上しました。 本論文では、別の軸に沿ってデータ品質をどのように改善できるかを調査しています。高品質のデータはより良い結果を生み出します。たとえば、データのクリーニングは、現在のデータセットを作成するための重要なステップであり、比較的小さなデータセットまたはデータをより多くのイテレーションに通すことができます。ニューラルネットワークに英語を教えるために人工的に作成された高品質のデータセットであるTinyStoriesに関する最近の研究は、高品質のデータの利点がこれ以上のものであることを示しています。改良されたスケーリング則により、高品質のデータは大規模なモデルの性能を、よりシンプルなトレーニング/モデルで一致させることができるようになります。 この研究では、マイクロソフトリサーチの著者たちは、良質なデータが大規模言語モデル(LLMs)のSOTAをさらに向上させながら、データセットのサイズとトレーニング計算を大幅に減らすことができることを実証しています。トレーニングが必要なモデルが小さいほど、LLMsの環境コストを大幅に削減することができます。彼らは、コーディングのためにトレーニングされたLLMsを使用して、自分のdocstringsから特定のPython関数を構築しました。後者の論文で提唱された評価基準であるHumanEvalは、コード上でLLMのパフォーマンスを比較するために頻繁に使用されています。 彼らは、1.3Bパラメータモデルをトレーニングし、phi-1と呼びます。7Bトークン以上(合計50Bトークン以上)を約8回通過した後、200Mトークン未満でファインチューニングを行い、高品質のデータが確立されたスケーリングルールを破る能力を示しました。一般的には、「教科書の品質」のデータを事前にトレーニングし、GPT-3.5を使用して人工的に生成されたデータとオンラインソースからのフィルタリングされたデータの両方を使用し、ファインチューニングには「教科書の演習のような」データを使用します。彼らは、1つのLLM生成のみを使用して、競合モデルよりもはるかに小さなデータセットとモデルサイズでありながら、HumanEvalで50.6%のpass@1精度、MBPP (Mostly Basic Python Programs)で55.5%のpass@1精度を達成しました。 彼らは、7Bトークン以上(合計50Bトークン以上)を約8回通過した後、200Mトークン未満でファインチューニングを行い、1.3Bパラメータのphi-1モデルをトレーニングすることで、高品質のデータが確立されたスケーリングルールを破る能力を示しました。一般的には、「教科書の品質」のデータを事前にトレーニングし、GPT-3.5を使用して人工的に生成されたデータとオンラインソースからのフィルタリングされたデータの両方を使用し、ファインチューニングには「教科書の演習のような」データを使用します。彼らは、1つのLLM生成のみを使用して、競合モデルよりもはるかに小さなデータセットとモデルサイズでありながら、HumanEvalで50.6%のpass@1精度、MBPP (Mostly Basic Python Programmes)で55.5%のpass@1精度を達成しました。

なぜ無料のランチがあるのか
機械学習の領域における「無料の昼食はない」定理は、数学の世界におけるゲーデルの不完全性定理を思い起こさせますこれらの定理はよく引用されますが、めったに...

モデルオプスとは何ですか?
モデルオプスは、使用中のモデルを管理および実行するための手順と機器の集合ですMLチームはDevOpsチームと協力し、各モデルを本番環境に展開します
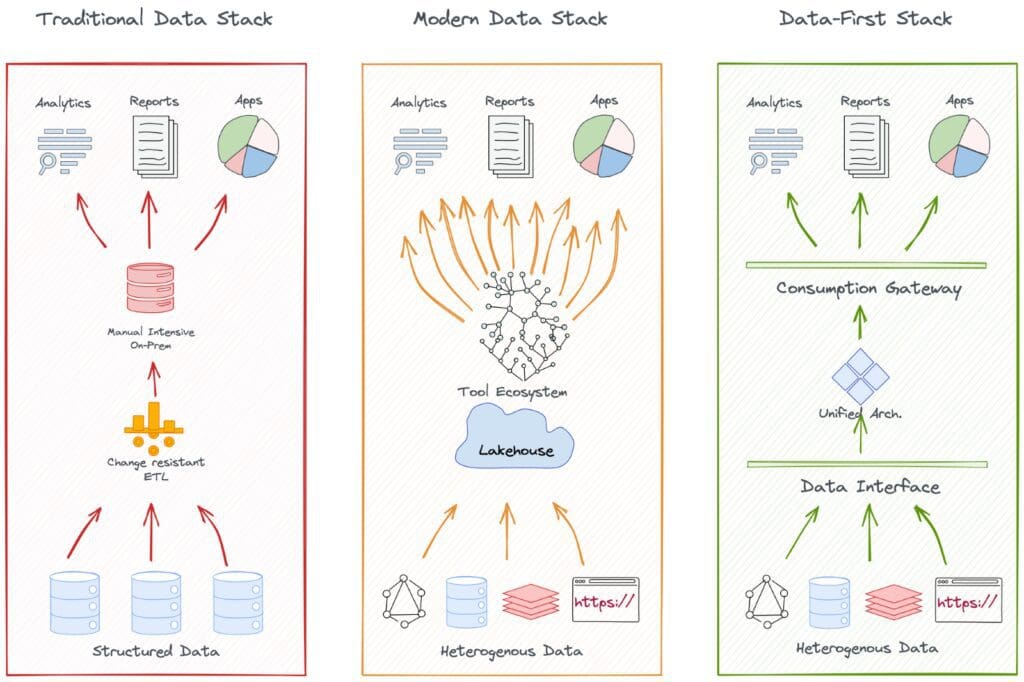
データランドスケープの進化
この記事は進化の物語を進化パターンの観点からデータ空間で追跡します進化の旅路の重要なマイルストーン、その達成、課題、それらの課題を解決した次のマイルストーンの状態について語りますこの記事はビジネスと技術の両面からの観点で書かれています...

大規模言語モデル(LLM)に関する驚くべき8つの事実
近年、大規模言語モデル(LLM)の公開的な展開が広範な関心と活動を引き起こしています。新しい技術がもたらす切迫した懸念があるため、この焦点は正当化されていますが、いくつかの重要な要因を見落とすこともあります。 最近では、ChatGPTなどのLLMとそれらに基づく製品について、ジャーナリスト、政策立案者、学者から様々な分野で関心が高まっています。しかし、この技術が多くの点で驚くべきものであるため、簡潔な説明では重要な詳細が抜け落ちることがあります。 以下に、この技術に関する8つの予想外の側面があります。 LLMの機能は、意図的なイノベーションがなくても、投資が増えるにつれて予測可能に増加します。 LLMに対する研究や投資の増加は、スケーリング法則の結果と言えます。研究者が将来のモデルに与えるデータの量、モデルのサイズ(パラメーターで測定)、およびトレーニングに使用されるコンピューティングの量を増やすと、スケーリング法則により、それらのモデルがどの程度能力があるか(FLOPsで測定)を精確に予測できます。そのため、コストのかかる実験を行うことなく、特定の予算内で最適なモデルのサイズなど、重要な設計上の決定を行うことができます。 予測の精度は、現代の人工知能研究の文脈でも前例のないレベルです。R&Dチームが経済的に有益なシステムを開発することに成功することが期待される多数のモデルトレーニングイニシアチブを提供することができるため、投資を推進するための有力な手段でもあります。 最新のLLMのトレーニング方法はまだ公開されていませんが、最近の詳細な報告によると、これらのシステムの基本的なアーキテクチャは、ほとんど変わっていないとされています。 LLMにリソースが注がれると、予想外に重要な行動がしばしば現れます。 ほとんどの場合、モデルが未完了のテキストの続きを正確に予測できる能力は、プレトレーニングテストの損失によって測定され、スケーリング規則によってのみ予測できます。 この指標は平均的に多くの実用的な活動におけるモデルの有用性と相関しますが、モデルが特定の才能を発揮し始めたり、特定のタスクを実行できるようになるタイミングを予測することは容易ではありません。 具体的には、GPT-3のfew-shot learning(つまり、1回の相互作用で新しいタスクを少数の例から学習する能力)や、chain-of-thought reasoning(つまり、数学のテストで生徒が行うように、難しいタスクの理由を書き出し、改善されたパフォーマンスを示す能力)などは、現代のLLMの中で最初のものとして際立っています。 将来のLLMは必要な機能を開発する可能性があり、一般的に受け入れられている境界はほとんどありません。 ただし、LLMの進歩は、専門家の予想よりも予期せぬものであることがあります。 LLMは、外部世界の表現を獲得し利用することがよくあります。 ますます多くの証拠が、LLMが世界の内部表現を構築し、テキストの特定の言語形式に対して無関心な抽象レベルで推論することを可能にしていることを示しています。この現象の証拠は、最大かつ最新のモデルで最も強力であるため、システムがより大規模にスケールアップされるとより堅牢になることが予想されます。ただし、現在のLLMはこれをより効果的に行う必要があります。 広範な実験技術や理論モデルに基づく以下の調査結果が、この主張を支持しています。 モデルの内部色表現は、人間が色を知覚する方法に関する経験的な知見と非常に一致しています。 モデルは、著者の知識や信念を推測し、文書の将来の方向性を予測することができます。 物語はモデルに情報を提供し、それが物語に表現されているオブジェクトの特徴や位置の内部表現を変更します。 モデルは、奇妙なものを紙に描く方法を提供することがあります。 Winograd Schema…

PyTorchを使った効率的な画像セグメンテーション:パート1
この4部作では、PyTorchを使用して深層学習技術を使った画像セグメンテーションをゼロから段階的に実装しますシリーズを開始するにあたり、必要な基本的なコンセプトとアイデアについて説明します

PyTorchを使用した効率的な画像セグメンテーション:パート3
この4部シリーズでは、PyTorchを使用して深層学習技術を使い、画像セグメンテーションをスクラッチからステップバイステップで実装しますこのパートでは、CNNベースラインモデルを最適化することに焦点を当てます

機械学習における再現性の重要性
どのように、データ管理、バージョン管理、実験トラッキングの改善アプローチが再現可能なMLパイプラインの構築に役立つか
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.