Learn more about Search Results OPT - Page 82

- You may be interested
- データサイエンティストのための時系列分...
- 「Pythonデコレータ:包括的なガイド」
- 「Google BigQuery / SQLでの5つの一般的...
- 「ハックからハーモニーへ:レコメンデー...
- 「ファストテキストを使用したシンプルな...
- 「医療AIの基礎モデル」
- MLflowを使用して機械学習の実験を追跡し...
- 「LangChainとOpenAI APIを使用した生成型...
- テキスト分類におけるトランスフォーマー...
- メタAIは、オープンで創造的なAIモデルを...
- 「マッキンゼー・レポートからの5つの重要...
- クラウドインスタンスのスタートアップス...
- UCバークレーの研究者たちは、「RLIF」と...
- 「今日使用されているAIoTの応用」
- 「洪水耐性のための地理空間分析」

「AIが、人間が想像もできない高効果な抗体を作り出している」
「ロボット、コンピュータ、アルゴリズムは、人間ができない方法で潜在的な新しい治療法を探し求めています」

「🤗 Transformersを使用してBarkを最適化する」
🤗 Transformersは、ドメインやタスクにわたる最新の最先端(SoTA)モデルを提供しています。これらのモデルから最高のパフォーマンスを引き出すには、推論速度とメモリ使用量を最適化する必要があります。 🤗 Hugging Faceエコシステムは、このような最適化ツールを提供し、ライブラリ内のすべてのモデルに一括して適用することができる簡単かつ使いやすいものです。これにより、わずか数行のコードでメモリの使用量を減らし、推論を改善することができます。 このハンズオンチュートリアルでは、🤗 Transformersでサポートされているテキスト音声合成(TTS)モデルであるBarkを、3つのシンプルな最適化に基づいて最適化する方法を実演します。これらの最適化は、🤗エコシステムのTransformers、Optimum、Accelerateライブラリにのみ依存しています。 このチュートリアルは、最適化されていないモデルとそのさまざまな最適化のベンチマークを行う方法をデモンストレーションするものでもあります。 説明の少ないがコードが含まれている、より簡略化されたバージョンのチュートリアルは、関連するGoogle Colabを参照してください。 このブログ投稿は次のように構成されています: 目次 Barkアーキテクチャのリマインダー 異なる最適化手法の概要とその利点 ベンチマーク結果のプレゼンテーション Barkは、suno-ai/barkで提案された、トランスフォーマーベースのテキスト音声合成モデルです。音声、音楽、背景音、シンプルな効果音など、さまざまなオーディオ出力を生成することができます。さらに、笑い声、ため息、泣き声など、非言語コミュニケーションの音も生成することができます。 Barkは、v4.31.0以降の🤗 Transformersで利用可能です! Barkで遊んでその能力を発見することができます。 Barkは4つの主要なモデルで構成されています: BarkSemanticModel(または「テキスト」モデルとも呼ばれる):トークン化されたテキストを入力とし、テキストの意味を捉えるセマンティックなテキストトークンを予測する因果自己回帰トランスフォーマーモデルです。 BarkCoarseModel(または「粗い音響」モデルとも呼ばれる):BarkSemanticModelモデルの結果を入力とし、EnCodecに必要な最初の2つのオーディオコードブックを予測する因果自己回帰トランスフォーマーモデルです。 BarkFineModel(「細かい音響」モデル):非因果オートエンコーダートランスフォーマーで、前のコードブック埋め込みの合計に基づいて最後のコードブックを反復的に予測します。 EncodecModelからすべてのコードブックチャネルを予測した後、Barkはそれを使用して出力オーディオ配列をデコードします。…
「AIがPowerPointと出会う」
この記事では、2023年5月のSnowflake SummitのStreamlit Hackathonで3位を獲得したオープンソースプロジェクトである「Instant Insight」アプリのバックエンドの仕組みについて詳しく説明しますウェブ...
「HaystackにおけるRAGパイプラインの拡張 DiversityRankerとLostInTheMiddleRankerの紹介」
最近の自然言語処理(NLP)と長文質問応答(LFQA)の進歩は、わずか数年前にはまるでSFの世界から来たようなものだと思われていたでしょう誰...

「Swift Transformersのリリース:AppleデバイスでのオンデバイスLLMsの実行」
私はiOS/Macの開発者に多くの敬意を持っています。2007年にiPhone向けのアプリを書き始めたときは、まだAPIやドキュメントさえ存在しませんでした。新しいデバイスは、制約空間におけるいくつかの見慣れない決定を採用しました。パワー、画面の広さ、UIのイディオム、ネットワークアクセス、永続性、遅延などの組み合わせは、それまでとは異なるものでした。しかし、このコミュニティはすぐに新しいパラダイムに適した優れたアプリケーションを作り出すことに成功しました。 私はMLがソフトウェアを構築する新しい方法だと信じており、多くのSwift開発者が自分のアプリにAI機能を組み込みたいと思っていることを知っています。MLのエコシステムは大きく成熟し、さまざまな問題を解決する数千のモデルが存在しています。さらに、LLM(Language and Learning Models)は最近、ほぼ汎用のツールとして登場しました。テキストやテキストに似たデータで作業するため、新しいドメインに適応させることができます。私たちは、LLMが研究所から出てきて、誰にでも利用可能なコンピューティングツールになりつつあるという、コンピューティングの歴史上の転換点を目撃しています。 ただし、LlamaのようなLLMモデルをアプリに使用するには、多くの人が直面し、単独で解決する必要があるタスクがあります。私たちはこの領域を探求し、コミュニティと一緒に取り組みを続けたいと考えています。開発者がより速く開発できるように、ツールとビルディングブロックのセットを作成することを目指しています。 今日は、このガイドを公開し、MacでCore MLを使用してLlama 2などのモデルを実行するために必要な手順を説明します。また、開発者をサポートするためのアルファ版のライブラリとツールもリリースしています。MLに興味のあるすべてのSwift開発者にPRやバグレポート、意見を提供して、一緒に改善するよう呼びかけています。 さあ、始めましょう! 動画: Llama 2 (7B)チャットモデルがCore MLを使用してM1 MacBook Proで実行されています。 今日リリース swift-transformersは、テキスト生成に焦点を当てたSwiftで実装されたtransformersライクなAPIを開発中のSwiftパッケージです。これはswift-coreml-transformersの進化版であり、より広範な目標を持っています。Hubの統合、任意のトークナイザのサポート、プラグイン可能なモデルなど。 swift-chatは、パッケージの使用方法を示すシンプルなアプリです。 transformersモデルのCore ML変換のための更新されたバージョンのexporters、Core ML変換ツールであるtransformers-to-coremlの更新されたバージョン。 これらのテキスト生成ツールで使用するために準備されたLlama…

「DPOを使用してLlama 2を微調整する」
はじめに 人間のフィードバックからの強化学習(RLHF)は、GPT-4やクロードなどのLLMの最終トレーニングステップとして採用され、言語モデルの出力が人間の期待に合致するようにするために使われます。しかし、これによってRLの複雑さがNLPにもたらされます。良い報酬関数を構築し、モデルに状態の価値を推定するように訓練し、同時に元のモデルからあまり逸脱せずに意味のあるテキストを生成するように注意する必要があります。このようなプロセスは非常に複雑で、正しく行うのは常に簡単ではありません。 最近の論文「Direct Preference Optimization」(Rafailov、Sharma、Mitchell他)では、既存の方法で使用されるRLベースの目的を、シンプルなバイナリクロスエントロピー損失を直接最適化できる目的に変換することを提案しており、これによりLLMの改善プロセスが大幅に簡素化されます。 このブログ記事では、TRLライブラリで利用可能なDirect Preference Optimization(DPO)メソッドを紹介し、さまざまなスタックエクスチェンジポータルの質問に対するランク付けされた回答を含むスタックエクスチェンジのデータセットで最近のLlama v2 7Bパラメータモデルを微調整する方法を示します。 DPO vs PPO 人間の派生した好みをRLを通じて最適化する従来のモデルでは、補助的な報酬モデルを使用し、興味のあるモデルを微調整して、この報酬をRLの仕組みを利用して最大化するようにします。直感的には、報酬モデルを使用して最適化するモデルにフィードバックを提供し、ハイリワードのサンプルをより頻繁に生成し、ローリワードのサンプルをより少なく生成するようにします。同時に、フリーズされた参照モデルを使用して、生成物があまり逸脱せずに生成の多様性を維持し続けるようにします。これは通常、参照モデルを介した全報酬最大化の目的にKLペナルティを追加することで行われ、モデルが報酬モデルをごまかしたり利用したりすることを防ぐ役割を果たします。 DPOの定式化は、報酬モデリングのステップをバイパスし、報酬関数から最適なRLポリシーへの解析的なマッピングを使用して、言語モデルを好みのデータに最適化します。このマッピングは、与えられた報酬関数が与えられた好みのデータとどれだけ合致するかを直感的に測定します。したがって、DPOはRLHFの損失の最適解から始まり、変数の変換を介して参照モデルに対する損失を導出することで、参照モデルのみに対する損失を得ることができます。 したがって、この直接的な尤度目的は、報酬モデルやポテンシャルに煩雑なRLベースの最適化を必要とせずに最適化することができます。 TRLのトレーニング方法 前述のように、通常、RLHFパイプラインは次の異なるパーツで構成されています: 教師あり微調整(SFT)ステップ データに好みのラベルを付けるプロセス 好みのデータで報酬モデルをトレーニングする そして、RL最適化ステップ TRLライブラリには、これらのパーツのためのヘルパーが付属していますが、DPOトレーニングでは報酬モデリングとRL(ステップ3と4)のタスクは必要ありません。代わりに、TRLのDPOTrainerにステップ2の好みのデータを提供する必要があります。このデータは非常に特定の形式を持ちます。具体的には、次の3つのキーを持つ辞書です: prompt:テキスト生成の際にモデルに与えられるコンテキストプロンプトです…

光ベクトルビームマルチビット
この技術は、レーザーの振幅ではなく、ベクトル品質因子を変調することによって動作します

「音のシンフォニーを解読する:音楽工学のためのオーディオ信号処理」
異なる種類のデータを処理し分析し、実用的な洞察を得る能力は、情報時代で最も重要なスキルの1つですデータは私たちの周りにあります:私たちが読む本から...
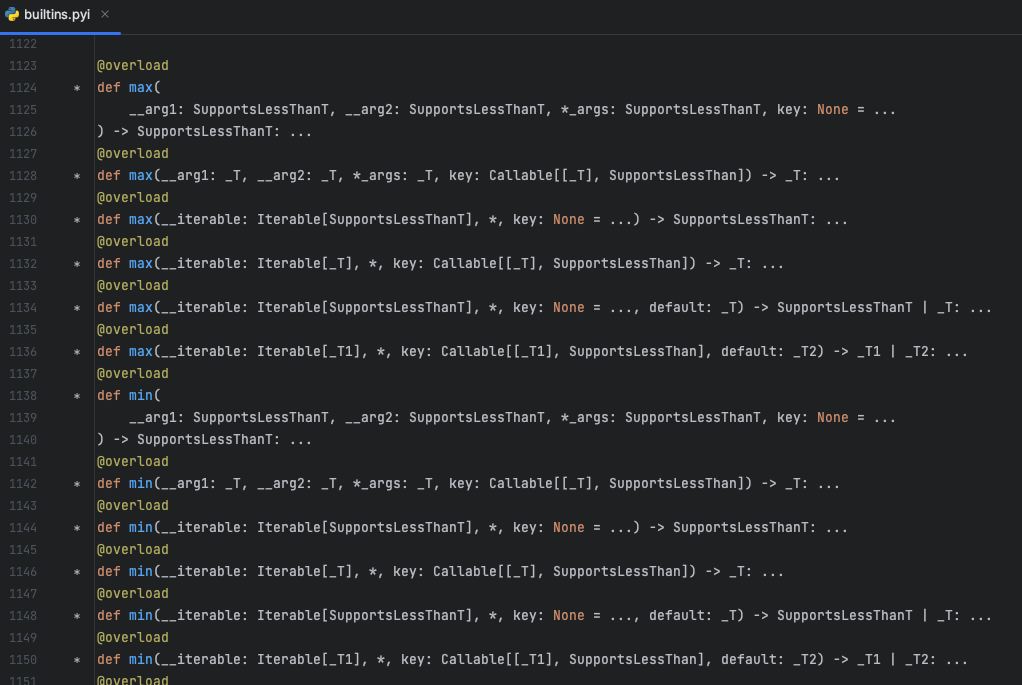
「Pythonデコレーターは開発者のエクスペリエンスをスーパーチャージします🚀」
Pythonの@overloadデコレータは、Pythonの組み込みモジュールであるtypingで見つけることができますこのデコレータは、開発者が関数やメソッドに複数のタイプ固有のシグネチャを指定することを可能にしますこれにより、…

AWSは、大規模なゲーミング会社のために、Large Language Model (LLM) を使って有害なスピーチを分類するためのファインチューニングを行います
「ビデオゲーム業界は、世界中で30億人以上のユーザーベースを持っています1毎日大量のプレイヤーが仮想的にお互いとやり取りしています残念ながら、現実の世界と同様に、すべてのプレイヤーが適切に礼儀正しくコミュニケーションを取るわけではありません社会的責任を持ったゲーム環境を作り維持するために、AWSは努力しています…」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.