Learn more about Search Results リポジトリ - Page 82

- You may be interested
- 「Swift Transformersのリリース:Appleデ...
- 健康医療におけるバイアスとの闘いに参加する
- LLM(Large Language Models)は、厳密に...
- プリンストンの研究者たちは、革新的な軽...
- Mojo | 新しいプログラミング言語
- 欠陥が明らかにされる:MLOpsコース作成の...
- OpenAIは、GPTBotを導入しましたこれは、...
- あなたのプロジェクトに最適な5つのデータ...
- Plotlyの3Dサーフェスプロットを使用して...
- 魅力的な方法:AIが人々がドイツ語や他の...
- 「共通の悪いデータの10つのケースとその...
- マイクロソフトリサーチがAIコンパイラの...
- 「NTUとSenseTimeの研究者が提案するSHERF...
- 2023年のデータの求人市場を解読する:数...
- 直感的にR2と調整済みR2のメトリックを探...

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…

Hugging Faceの推論エンドポイントを使用してLLMをデプロイする
オープンソースのLLMであるFalcon、(オープン-)LLaMA、X-Gen、StarCoder、またはRedPajamaは、ここ数ヶ月で大きく進化し、ChatGPTやGPT4などのクローズドソースのモデルと特定のユースケースで競合することができるようになりました。しかし、これらのモデルを効率的かつ最適化された方法で展開することはまだ課題です。 このブログ投稿では、モデルの展開を容易にするマネージドSaaSソリューションであるHugging Face Inference EndpointsにオープンソースのLLMを展開する方法と、応答のストリーミングとエンドポイントのパフォーマンステストの方法を紹介します。さあ、始めましょう! Falcon 40Bの展開方法 LLMエンドポイントのテスト JavaScriptとPythonでの応答のストリーミング 始める前に、Inference Endpointsについての知識をおさらいしましょう。 Hugging Face Inference Endpointsとは何ですか Hugging Face Inference Endpointsは、本番環境での機械学習モデルの展開を簡単かつ安全な方法で提供します。Inference Endpointsを使用することで、開発者やデータサイエンティストはインフラストラクチャの管理をせずにAIアプリケーションを作成できます。展開プロセスは数回のクリックで簡略化され、オートスケーリングによる大量のリクエストの処理、ゼロスケールへのスケールダウンによるインフラストラクチャのコスト削減、高度なセキュリティの提供などが可能となります。 LLM展開における最も重要な機能のいくつかは以下の通りです: 簡単な展開: インフラストラクチャやMLOpsの管理を必要とせず、本番用のAPIとしてモデルを展開できます。 コスト効率:…

Transformers.jsを使用してMLを搭載したウェブゲームの作成
このブログ記事では、ブラウザ上で完全に動作するリアルタイムのMLパワードWebゲーム「Doodle Dash」を作成した方法を紹介します(Transformers.jsのおかげで)。このチュートリアルの目的は、自分自身でMLパワードのWebゲームを作成するのがどれだけ簡単かを示すことです… ちょうどOpen Source AI Game Jam(2023年7月7日-9日)に間に合います。まだ参加していない場合は、ぜひゲームジャムに参加してください! ビデオ:Doodle Dashデモビデオ クイックリンク デモ:Doodle Dash ソースコード:doodle-dash ゲームジャムに参加:Open Source AI Game Jam 概要 始める前に、作成する内容について話しましょう。このゲームは、GoogleのQuick, Draw!ゲームに触発されており、単語とニューラルネットワークが20秒以内にあなたが描いているものを推測するというものです(6回繰り返し)。実際には、彼らのトレーニングデータを使用して独自のスケッチ検出モデルを訓練します!オープンソースは最高ですよね? 😍 このバージョンでは、1つのプロンプトずつできるだけ多くのアイテムを1分間で描くことができます。モデルが正しいラベルを予測した場合、キャンバスがクリアされ、新しい単語が与えられます。タイマーが切れるまでこれを続けてください!ゲームはブラウザ内でローカルに実行されるため、サーバーの遅延について心配する必要はありません。モデルはあなたが描くと同時にリアルタイムの予測を行うことができます… 🤯…

SQLクエリにおいてGPT-4よりも優れたもの:NSQL(完全なオープンソース)
ChatGPTや他のLLM(Language Model)を使用してSQLクエリを生成しようとしたことがある方は手を挙げてください私は試してみましたし、現在も試しています!しかし、新しいオープンソースのファミリーが登場したことをお伝えできるのがとても嬉しいです...
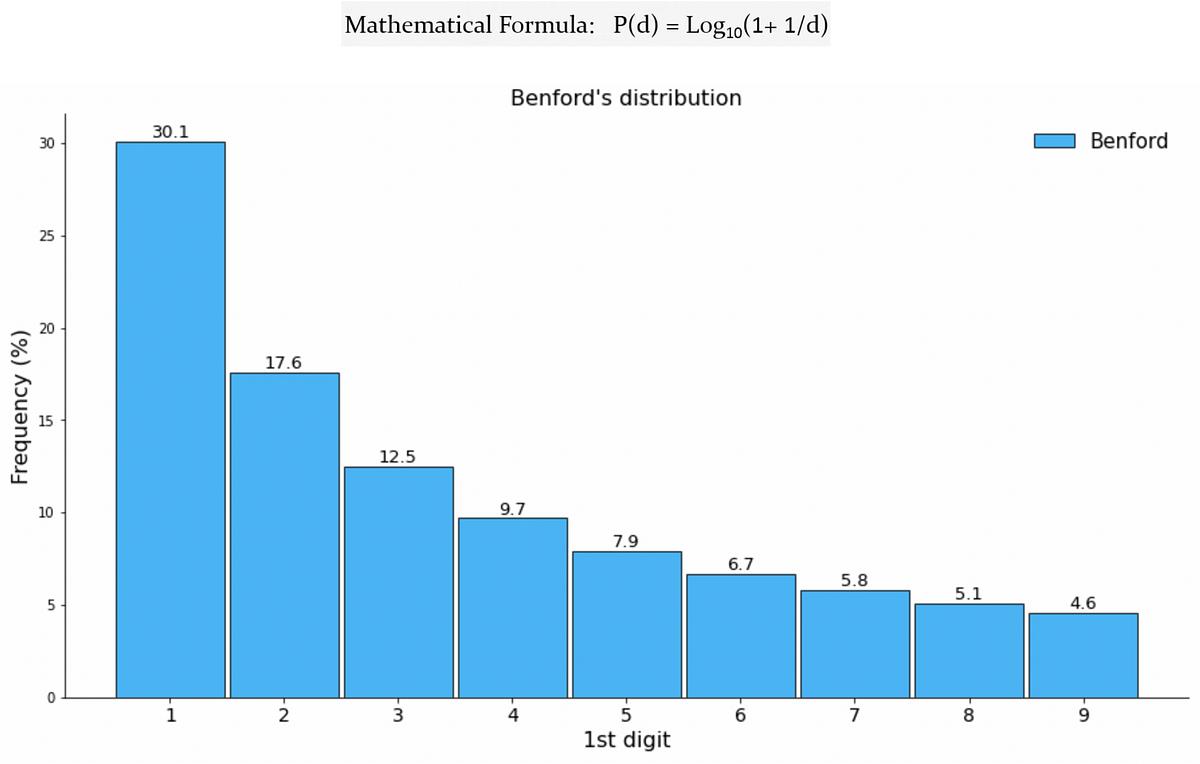
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します

ドレスコードの解読👗 自動ファッションアイテム検出のためのディープラーニング
電子商取引の活気ある世界では、ファッション業界は独自のランウェイですしかし、もし我々がこのランウェイのドレスコードを、デザイナーの目ではなく、ディープラーニングの精度で解読できるとしたら...

リアルワールドのMLOpsの例:Brainlyでのビジュアル検索のためのエンドツーエンドのMLOpsパイプライン
シリーズ「実世界のMLOpsの例」の第2回目では、Brainlyの機械学習エンジニアであるPaweł Pęczekが、Brainlyのビジュアル検索チームにおけるエンドツーエンドの機械学習オペレーション(MLOps)プロセスを詳しく説明しますそして、MLOpsで成功するためには、技術やプロセスだけではなく、さらに詳細な情報を共有します Enjoy...

CVモデルの構築と展開:コンピュータビジョンエンジニアからの教訓
コンピュータビジョン(CV)モデルの設計、構築、展開の経験を3年以上積んできましたが、私は人々がこのような複雑なシステムの構築と展開において重要な側面に十分な注力をしていないことに気づきましたこのブログ投稿では、私自身の経験と、最先端のCVモデルの設計、構築、展開において得た貴重な知見を共有します...

Pythonでトレーニング済みモデルを保存する方法
実世界の機械学習(ML)のユースケースに取り組む際、最適なアルゴリズム/モデルを見つけることは責任の終わりではありませんこれらのモデルを将来の使用や本番環境への展開のために保存、保管、パッケージ化することが重要ですこれらのプラクティスはいくつかの理由から必要です:再強調すると、MLモデルの保存と保管...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.