Learn more about Search Results A - Page 829

- You may be interested
- この脳AIの研究では、安定した拡散を用い...
- 感情AIの科学:アルゴリズムとデータ分析...
- CMU(カーネギーメロン大学)およびNYU(...
- 「LLMOps対MLOps 違いを理解する」
- 「GPTモデルの信頼性に関する詳細な分析」
- 「Amazon SageMakerデータパラレルライブ...
- 「GPUを使用してAmazon SageMakerのマルチ...
- 大規模言語モデル(LLM)の微調整
- TaatikNet(ターティクネット):ヘブライ...
- 「つながる点 OpenAIの主張されたQ-Starモ...
- MLがDevOpsと出会うとき:MLOpsの理解方法
- 「機械学習リスク管理のための文化的な能力」
- MITの研究者は、ディープラーニングと物理...
- 経験がなくてもデータアナリストになる方法
- 「ChatGPTの高度な設定ガイド – Top...

小さなオーディオ拡散:クラウドコンピューティングを必要としない波形拡散
2GB以下のVRAMを持つコンシューマーラップトップとGPUでオーディオ波形拡散を用いてモデルをトレーニングし、音を生成する方法を探索する

MITの研究者が、生成プロセスの改善のために「リスタートサンプリング」を導入
微分方程式ベースの深層生成モデルは、最近、画像合成から生物学までのさまざまな分野で、高次元データのモデリングにおいて有力なツールとして登場しています。これらのモデルは、逆に微分方程式を反復的に解いて、基本的な分布(拡散モデルの場合はガウス分布など)を複雑なデータ分布に変換します。 これらの可逆プロセスをモデリングできる事前サンプラーは、次の2つのタイプに分類されています: 初期のランダム化後は決定論的に進化するODEサンプラー 生成トラジェクトリが確率的であるSDEサンプラー いくつかの研究によると、これらのサンプラーはさまざまな設定で利点を示しています。ODEソルバーによって生成されるより小さい離散化エラーにより、より大きなステップサイズでも使用可能なサンプル品質が得られます。ただし、その子孫の品質はすぐに飽和します。一方、SDEは大きなNFE領域で品質を向上させますが、サンプリングに費やす時間が増えます。 このことに触発されて、MITの研究者は、ODEとSDEの利点を組み合わせた新しいサンプリング手法であるRestartを開発しました。Restartサンプリングアルゴリズムは、固定時間内での2つのサブルーチンのK回の反復から構成されています:大量のノイズを導入するRestartフォワードプロセス(元の逆プロセスを「再開」)と、逆ODEを実行するRestartバックワードプロセス。 Restartアルゴリズムは、ランダム性とドリフトを分離し、Restartのフォワードプロセスで追加されるノイズの量は、以前のSDEのドリフトと交錯する小さな単一ステップのノイズよりもはるかに大きくなっており、蓄積されたエラーに対する収縮効果が増大します。各Restart反復で導入される収縮効果は、K回のフォワードとバックワードのサイクルによって強化されます。Restartは、決定論的な逆プロセスにより、離散化のミスを減らし、ODEのようなステップサイズを実現することができます。実際には、Restart間隔は、蓄積されたエラーが大きいシミュレーションの最後に配置されることが多く、収縮効果を最大限に活用するために使用されます。さらに、より困難な活動では、早期のミスを減らすために複数のRestart期間が使用されます。 実験結果は、さまざまなNFE、データセット、事前トレーニング済みモデルにおいて、Restartが品質と速度において最先端のODEおよびSDEソルバーを上回ることを示しています。特に、VPを使用したCIFAR-10では、Restartは以前の最良のSDEに比べて10倍のスピードアップを実現し、EDMを使用したImageNet 64×64では、ODEソルバーを上回る小さなNFE領域でも2倍のスピードアップを実現しています。 研究者はまた、RestartをLAION 512 x 512画像で事前トレーニングされたStable Diffusionモデルに適用して、テキストから画像への変換を行っています。Restartは、CLIP/Aestheticスコアによるテキスト-画像の整合性/視覚品質と、FIDスコアによる多様性の間で、変動する分類器なしのガイダンス強度を用いて、以前のサンプラーに比べてより良いバランスを実現しています。 Restartフレームワークの潜在的な可能性を十分に活用するために、チームは将来的にはモデルのエラー分析に基づいてRestartの適切なハイパーパラメータを自動的に選択するためのより道徳的な手法を構築する予定です。
機械学習システムにおけるデータ品質の維持
機械学習(ML)の眩しい世界では、洗練されたアルゴリズム、魅力的な視覚化、印象的な予測を考案する魅力に夢中になることは非常に容易です

言語モデルの構築:ステップバイステップのBERTの実装ガイド
イントロダクション 言語処理を行う機械学習モデルの進歩は、ここ数年で急速に進んでいます。この進歩は、研究室を出て、いくつかの主要なデジタル製品の動力となり始めています。良い例として、BERTモデルがGoogle検索の重要な要素となったことが発表されたことがあります。Googleは、この進化(自然言語理解の進歩が検索に応用されること)は、「過去5年間で最大の進歩であり、検索の歴史上でも最大の進歩の1つ」と考えています。では、BERTとは何かについて理解しましょう。 BERTは、Bidirectional Encoder Representations from Transformersの略です。その設計では、未ラベルのテキストから左右の文脈の両方に依存して事前学習された深層双方向表現を作成します。我々は、追加の出力層を追加するだけで、事前学習されたBERTモデルを異なるNLPタスクに適用することができます。 学習目標 BERTのアーキテクチャとコンポーネントを理解する。 BERTの入力に必要な前処理ステップと、異なる入力シーケンスの長さを扱う方法を学ぶ。 TensorFlowやPyTorchなどの人気のある機械学習フレームワークを使用してBERTを実装するための実践的な知識を得る。 テキスト分類や固有表現認識などの特定の下流タスクにBERTを微調整する方法を学ぶ。 次に、「なぜそれが必要なのか?」という別の質問が出てきます。それを説明しましょう。 この記事は、データサイエンスブログマラソンの一環として公開されました。 なぜBERTが必要なのか? 適切な言語表現とは、機械が一般的な言語を理解する能力です。word2VecやGloveのような文脈非依存モデルは、語彙中の各単語に対して単一の単語埋め込み表現を生成します。例えば、”crane”という用語は、”crane in the sky”や”crane to lift heavy objects”といった文脈で厳密に同じ表現を持ちます。文脈モデルは、文内の他の単語に基づいて各単語を表現します。つまり、BERTはこれらの関係を双方向に捉える文脈モデルです。 BERTは、Semi-supervised…
データサイエンティストの成長を助けるスキル
データサイエンスの学習の初期段階であっても、おそらく入門するために必要なコアスキルについては十分な理解を持っているでしょう統計学の基礎、実務知識などが求められます
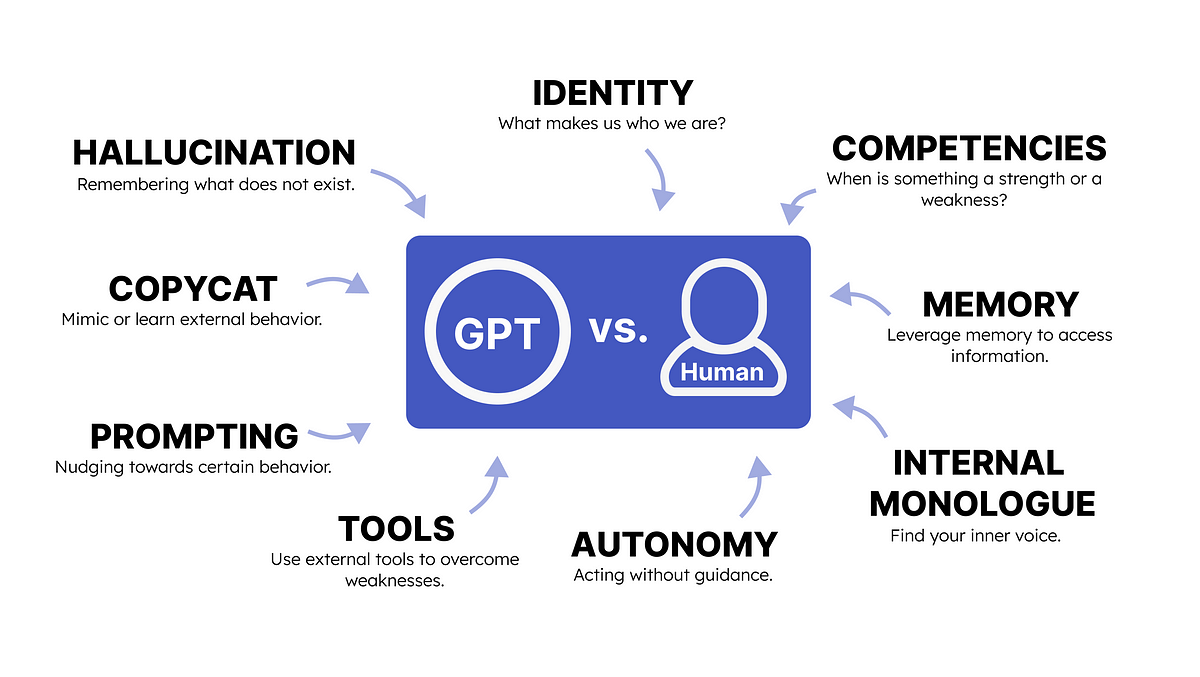
GPTと人間の心理学
GPTと人間の心理学との類推を行うことで、私たちは生成型AIの出力を促進する方法を理解することができます

PIDを使用したバイナリツリーを用いた衝突しない乱数の生成
この記事では、APIを使用せずにPID(プロセスID)を持つバイナリツリーを使用して、衝突しない疑似乱数を生成する方法について説明します

より強力な言語モデルが本当に必要なのでしょうか?
大規模な言語モデルはますます人気が高まっていますしかし、それらの開発には特定の課題にも直面することになりますGPTモデルは唯一のアプローチではありません

2023年に読むための自然言語処理に関する5冊の無料の書籍
大型言語モデルは左右中央にリリースされており、それらをより理解するためにはNLPについて知る必要があります以下には、あなたを助けるための5冊の無料の書籍があります

2023年のトップビジネスインテリジェンスツール
トップのビジネスインテリジェンスソリューションは、データの洞察を見つけ、ステークホルダーに効果的に伝えることを容易にします。データは、営業やマーケティングからワークフローと効率性、採用と人事、総合的なパフォーマンスと収益性まで、あらゆるものに対して収集できるため、企業が意味のある洞察を見つけるために大量のデータを見極めることは今まで以上に重要です。しかし、この情報のほとんどは分断されており、専門のビジネスインテリジェンス(BI)ツールの助けを借りてのみ組み合わせることができます。 キーパフォーマンスインジケータ(KPI)は、このデータが正確な予測に基づいてビジネスの運営を改善する方法の一つです。多くのプログラムは組み込みの分析機能を提供していますが、その結果をビジネスインテリジェンスシステムにエクスポートすることができます。 最高のビジネスインテリジェンスツールは、複雑なデータのプレゼンテーションを簡素化するため、関係者に提示できるインタラクティブな表現に基づいています。 以下に、現在市場でトップのビジネスインテリジェンスツールを示します。 actiTIME actiTIMEは、企業の生産性を把握するのに役立つ時間とプロジェクト管理システムです。時間とプロジェクトの進捗状況は、そのサポートによってリアルタイムで監視することができ、予算内および期限内に終了することができます。この透明性とコントロールのレベルにより、管理者はリソースの割り当て、優先順位の設定、タイムテーブルについてよく情報を得て、よく判断することができます。actiTIMEのパフォーマンスデータとトレンドの視覚的表現は、管理者の迅速な状況把握を助けます。このグラフィックは、停滞、非効率性、改善の機会を見つけるのに役立ちます。このデータに基づいて是正措置を講じ、チームがプロジェクトの目標に積極的に取り組んでいることを保証します。 SAS Viya SAS Viyaは、堅牢で柔軟なビジネスアナリティクスプラットフォームであり、データへの簡単なアクセスと洞察に基づく分析を瞬時に提供します。モダンなマイクロサービスアーキテクチャに基づいて構築されたSAS Viyaは、ビッグデータと高度なアナリティクスの複雑さに対応できるようになっており、困難なビジネスの課題を解決し、情報を元にした適切な選択を行うことができます。SAS Viyaは、重要なデータとトレンドのグラフィカルな表現を提供し、分析を迅速化し、意思決定を改善します。報告書、チャート、マップ、ダッシュボードはすべて対話形式で表示されます。さらに、意思決定者の専門知識にかかわらず、意思決定の最適化を支援するために、決定木、シナリオシミュレーション、自動予測も含まれています。 Oracle BI Oracle BIは、ビジネスがより良い意思決定のためにデータを収集し分析するために使用できる包括的なBIツールセットです。高度な分析、レポート作成、ダッシュボードの機能など、さまざまなツールとテクノロジーにアクセスできます。これは、さまざまな業界で活動する企業の要求に合わせてカスタマイズできる堅牢なシステムです。Oracle BIを使用することで、企業はデータをよりよく理解し、生産性を向上させ、未開発の成長の機会を見つけることができます。Oracle BIには、営業プロセスの最適化から顧客行動分析、業績に関する具体的な洞察まで、企業が次のレベルに進むために必要なすべてが備わっています。 Clear Analytics 組織は、堅牢なデータレポートツールであるClear Analyticsを利用して、市場で優位に立つことができます。使いやすいインターフェースと強力な機能により、Clear Analyticsを使用することで、複雑なデータセットを迅速かつ効果的に分析し、トレンドを把握し、データに基づいた意思決定を行うことができます。事前のトレーニングは必要ないというのは、その主な利点の一つです。ほとんどの人にとって既に馴染みのあるExcelの機能を活用することで、Clear Analyticsは、より少ない時間と労力でパワフルなデータ分析機能を提供します。ソフトウェアはMicrosoft…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.