Learn more about Search Results A - Page 828

- You may be interested
- クロマに会ってください:LLMs用のAIネイ...
- CV2(OpenCV)は、コンピュータビジョンの...
- 「あなたのデータプロジェクトで行き詰ま...
- スマートインフラストラクチャのリスク評...
- Amazon SageMaker Studioで生産性を向上さ...
- 「大規模言語モデルのランドスケープをナ...
- FermiNet(フェルミネット):第一原理に...
- オープンAIは、開発者のアリーナでより大...
- 自動車産業の未来は、話す車かもしれません
- 「ハギングフェイスの研究者たちは、Disti...
- ChatGPTのTokenizerを解放する
- 「オムニバースへ:Blender 4.0 アルファ...
- 「ジェミニ発表ビデオでグーグルが誤解を...
- 施設分散問題:混合整数計画モデル
- 「多数から少数へ:機械学習における次元...
プレフィックス条件付きの画像キャプションと画像分類のデータセットの統合
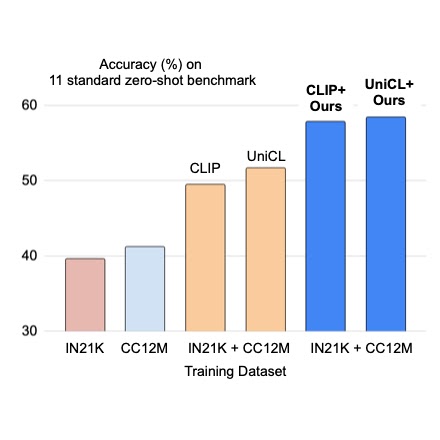
クラウドAIチームの学生研究者である斎藤邦明と知識チームの研究科学者であるソン・キヒョクによる投稿 ウェブスケールの画像キャプションデータセットでの視覚言語(VL)モデルの事前トレーニングは、画像分類データによる従来の事前トレーニングに対する強力な代替手段として最近注目されています。画像キャプションデータセットはより「オープンドメイン」であると考えられており、広範なシーンタイプや語彙の単語を含んでいるため、少数およびゼロショットの認識タスクで強力な性能を持つモデルが得られます。しかし、細粒度のクラスの説明を持つ画像は稀であり、画像キャプションデータセットは手動のキュレーションを経ていないため、クラスの分布が不均衡になる可能性があります。これに対して、ImageNetなどの大規模な分類データセットは通常キュレーションされており、バランスの取れたラベル分布を持つ細粒度のカテゴリを提供することができます。一見有望に聞こえるかもしれませんが、キャプションと分類データセットを直接組み合わせて事前トレーニングすることは、さまざまな下流タスクに対してうまく汎化しないバイアスのある表現を生み出す可能性があるため、通常は成功しないことがあります。 CVPR 2023で発表された「Prefix Conditioning Unifies Language and Label Supervision」では、分類とキャプションデータセットの両方を使用して補完的な利点を提供する事前トレーニング戦略を示しています。まず、データセットを単純に統合すると、モデルはデータセットのバイアスに影響を受け、下流のゼロショット認識タスクでの最適な性能を発揮しない結果となります。各データセットにおける画像ドメインと語彙のカバレッジは異なるためです。この問題に対処するために、我々はプレフィックス条件付けという新しい簡単で効果的な手法を使用して、トレーニング中にデータセットのバイアスと視覚的な概念を分離します。このアプローチにより、言語エンコーダは両方のデータセットから学習すると同時に、各データセットに対して特徴抽出を調整することができます。プレフィックス条件付けは、Contrastive Language-Image Pre-training(CLIP)やUnified Contrastive Learning(UniCL)などの既存のVL事前トレーニング目標に簡単に統合できる汎用の手法です。 高レベルのアイデア 分類データセットは少なくとも2つの方法でバイアスがかかる傾向があります:(1)画像には制限されたドメインの単一のオブジェクトがほとんど含まれており、(2)語彙が限定されており、ゼロショット学習に必要な言語の柔軟性を欠いています。たとえば、「犬の写真」というクラスの埋め込みは、通常、ImageNet向けに最適化されたものでは、ImageNetデータセットから引っ張られた画像の中央に1匹の犬の写真が表示されるものであり、他のデータセットに含まれる複数の位置にいる犬の画像や他の被写体との組み合わせにはうまく汎化しません。 それに対して、キャプションデータセットにはさまざまなシーンタイプと語彙が含まれています。以下に示すように、モデルが単純に2つのデータセットから学習する場合、言語の埋め込みは画像分類とキャプションデータセットのバイアスを絡め取る可能性があり、ゼロショット分類の汎化性能が低下することがあります。2つのデータセットのバイアスを分離できれば、キャプションデータセットに適した言語の埋め込みを使用して汎化性能を向上させることができます。 上:画像分類とキャプションデータセットのバイアスを絡め取る言語の埋め込み。下:2つのデータセットのバイアスを分離した言語の埋め込み。 プレフィックス条件付け プレフィックス条件付けは、プロンプトチューニングに部分的に触発された手法であり、学習可能なトークンを入力トークンシーケンスの前に追加することで、事前トレーニング済みのモデルバックボーンにタスク固有の知識を学習させ、それを使用して下流タスクを解決するための方法を指示します。プレフィックス条件付けアプローチは、プロンプトチューニングとは異なる2つの点で異なります:(1)データセットのバイアスを分離するために画像キャプションと分類データセットを統合するように設計されており、(2)VL事前トレーニングに適用される一方、標準のプロンプトチューニングはモデルの微調整に使用されます。プレフィックス条件付けは、ユーザーが提供するデータセットの種類に基づいてモデルバックボーンの振る舞いを明示的に制御する方法です。特に、さまざまなタイプのデータセットの数が事前にわかっている場合に役立ちます。 トレーニング中、接頭辞条件付けは、各データセットタイプごとにテキストトークン(接頭辞トークン)を学習し、データセットのバイアスを吸収し、残りのテキストトークンが視覚的な概念を学習することに集中できるようにします。具体的には、入力トークンの先頭に各データセットタイプごとの接頭辞トークンを追加し、入力データのタイプ(分類対キャプションなど)に関する言語エンコーダと視覚エンコーダに情報を提供します。接頭辞トークンはデータセットタイプ固有のバイアスを学習するため、言語表現のバイアスを分離し、入力キャプションなしでもテスト時に画像キャプションデータセットで学習された埋め込みを利用することができます。 CLIPでは、言語エンコーダと視覚エンコーダを使用して接頭辞条件付けを利用します。テスト時には、画像キャプションデータセットで使用された接頭辞を使用します。このデータセットはより広範なシーンタイプと語彙をカバーするため、ゼロショット認識の性能が向上します。 接頭辞条件付けのイラスト。 実験結果…

ロボティクスシミュレーションとは何ですか?
ロボットは倉庫内で商品を運搬し、食品を包装し、車両の組み立てを助けています。バーガーをひっくり返したり、ラテを提供することもあります。 彼らはなぜそんなに早くスキルを身につけたのでしょうか?それはロボティクスシミュレーションのおかげです。 進歩を飛躍的に遂げ、私たちの周りの産業を変革しています。 ロボティクスシミュレーションの概要 ロボティクスシミュレータは、物理的なロボットを必要とせずに、仮想環境に仮想ロボットを配置して、ロボットのソフトウェアをテストするものです。また、最新のシミュレータは、物理的なロボット上で実行される機械学習モデルのトレーニングに使用されるデータセットを生成することもできます。 この仮想世界では、開発者はロボットや環境、その他のロボットが遭遇する可能性のある要素のデジタルバージョンを作成します。これらの環境は、物理法則に従い、現実の重力、摩擦、材料、照明条件を模倣することができます。 ロボティクスシミュレーションを使用する人々 ロボットは今日、大規模なスケールで業務を支援しています。最も大きく革新的なロボット企業のいくつかは、ロボティクスシミュレーションに頼っています。 シミュレーションによって明らかにされた運用効率により、フルフィルメントセンターは1日に数千万個のパッケージを処理することができます。 Amazon Roboticsはフルフィルメントセンターを支援するためにそれを使用しています。BMWグループは自動車組立工場の計画を加速するためにそれを活用しています。Soft Roboticsは食品のパッケージングのためのグリッピングを完璧にするためにそれを適用しています。 自動車メーカーは世界中でロボティクスを活用しています。 「自動車メーカーは約1400万人を雇用しています。デジタル化により、産業の効率、生産性、スピードが向上します」とNVIDIAのCEOジェンセン・ファンは最新のGTC基調講演で述べています。 ロボティクスシミュレーションの動作原理 高度なロボティクスシミュレータは、物理の基本方程式を適用することから始まります。例えば、オブジェクトが時間の小さい増分またはタイムステップでどのように移動するかを決定するために、ニュートンの運動の法則を使用することができます。また、ロボットが蝶番のような関節で構成されているか、他のオブジェクトを通過できない制約を組み込むこともできます。 シミュレータは、オブジェクト間の潜在的な衝突を検出し、衝突するオブジェクト間の接点を特定し、オブジェクトが互いに通過するのを防ぐための力や衝撃を計算するためのさまざまな方法を使用します。シミュレータは、ユーザーが求めるセンサーシグナル(例:ロボットの関節でのトルクやロボットのグリッパーとオブジェクトとの間の力)も計算することができます。 シミュレータは、ユーザーが要求するだけのタイムステップ数でこのプロセスを繰り返します。 NVIDIA Isaac Simなどの一部のシミュレータは、各タイムステップでシミュレータの出力を物理的に正確な可視化も提供することができます。 ロボティクスシミュレータの利用方法 ロボティクスシミュレータのユーザーは、通常、ロボットのコンピュータ支援設計モデルをインポートし、仮想シーンを構築するために興味のあるオブジェクトをインポートまたは生成します。開発者は、タスクプランニングやモーションプランニングを実行するためのアルゴリズムのセットを使用し、それらの計画を実行するための制御信号を指定することができます。これにより、ロボットはオブジェクトを拾って目標位置に配置するなど、特定の方法でタスクを実行し移動することができます。 開発者は、計画と制御信号の結果を観察し、必要に応じて修正して成功を確保することができます。最近では、機械学習ベースの手法へのシフトが見られています。つまり、制御信号を直接指定する代わりに、ユーザーは衝突しないように指定された動作(例:特定の場所に移動する)を指定します。この状況では、データ駆動型のアルゴリズムが、ロボットのシミュレートされたセンサーシグナルに基づいて制御信号を生成します。…
木材トランジスターが根付く
電子工学の新たな方向性?

アルファベットは、遠隔地域でのインターネット提供のためにレーザーに賭けています
ターラプロジェクトは、レーザーを使用してインターネットアクセスを遠隔地や農村地域にもたらすことを目的としています

海洋ナビゲーションのためのロボットプラットフォームを構築するために、カイアシ類が泳ぐ方法を模倣する
ブラウン大学とメキシコ国立自治大学の研究者たちは、水中を航行するためにメタクロナル泳法を模倣したロボットプラットフォームを発明しました

研究者たちは、磁気のトリックを使って、量子コンピューティングの進歩を遂げました
研究チームは、半導体材料フレークを使用して「分数量子異常ホール」状態を検出することにより、故障耐性のある量子ビットの構築に向けて一歩を踏み出しました

人工知能による投資アドバイス – メリットとデメリット
私たちは、テクノロジーなしで未来の生活を想像することができません朝一番に私たちはニュースを読んだり未読のメッセージがあるか確認するために携帯電話をチェックしますテクノロジーは、エンターテイメント、医療、教育などさまざまな産業において要件を満たす能力を示してきました人工知能を活用することによって… 投資アドバイスのメリットとデメリット 詳細を読む »

データのクレンジングを通じたデジタルトランスフォーメーションの向上ガイド
デジタル変革は、急速に進化するデジタルの風景に適応し、企業が成長するために重要な要素ですデジタル変革の恩恵を十分に活用するためには、組織は正確かつ信頼性のあるデータに依存する必要がありますしかし、多くの企業はデータ品質の問題に苦しんでおり、これはデジタル変革の取り組みを妨げる可能性がありますこれは…データクレンジングを通じたデジタル変革の向上ガイドです詳細はこちらをご覧ください
南アメリカにおける降水量と気候学的なラスターデータの活用
2023年にエルニーニョ現象が激化するにつれて、気候学的および降水データは、その気象パターンと地球全体または地域の気候ダイナミクスへの影響を解読するために基本的な要素となっています...
デノイザーの夜明け:表形式のデータ補完のためのマルチ出力MLモデル
表形式のデータにおける欠損値の扱いは、データサイエンスにおける基本的な問題ですこの記事では、デノイジングに関する文献から着想を得た洗練された手法を紹介し、表形式のデータ補完においてマルチアウトプットの機械学習モデルを活用する方法を提案します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.