Learn more about Search Results ( link - Page 81

- You may be interested
- 「Artificial Narrow Intelligence(ANI)...
- データサイエンティストのための時系列分...
- ジェネレーティブAIアプリケーションを構...
- 「生成型AIのためのプロンプト微調整の技...
- 2023年のビデオ作成と編集のための40以上...
- 「新しいAmazon Kendra Alfrescoコネクタ...
- 「GoogleのDeblur AI:画像を鮮明にする」
- AIの闇面──クリエイターはどのように助け...
- 「Amazon Kendraを使用して、Adobe Experi...
- Pythonを使用したウェブサイトモニタリン...
- 「スマートな会話インターフェースのため...
- 「MLOpsに関する包括的なガイド」
- FedMLとThetaが分散型AIスーパークラスタ...
- 「IBMとNASAが連携し、地球科学GPTを創造...
- 「科学者たちが他の種とコミュニケーショ...

メタAIのもう一つの革命的な大規模モデル — 画像特徴抽出のためのDINOv2
Mete AIは、画像から自動的に視覚的な特徴を抽出する新しい画像特徴抽出モデルDINOv2の新バージョンを紹介しましたこれはAIの分野でのもう一つの革命的な進歩です...

グラフの復活:グラフの年ニュースレター2023年春
今日のナレッジグラフ、グラフデータベース、グラフアナリティクス、グラフAIの現在地と今後の方向性に関するニュースと分析を見つける

データエンジニアが本当にやっていること?
データ主導の世界では、データエンジニアのような裏方のヒーローたちは、スムーズなデータフローを確保するために重要な役割を果たしています。突然不適切なおすすめを受け取ったオンラインショッパーを想像してみてください。データエンジニアは問題を調査し、電子商取引プラットフォームのデータファンネルに欠陥があることを特定し、スムーズなデータパイプラインを迅速に実装します。データサイエンティストやアナリストに注目が集まる一方で、データエンジニアの執念深い努力によって、組織内の情報に基づく意思決定に必要なアクセスしやすく、よく準備されたデータが保証されています。データエンジニアは具体的に何をするのでしょうか?彼らはどのようにビジネスの成功に貢献しているのでしょうか?彼らの世界に飛び込んで、データエンジニアの職務内容、役割、責任、そしてあなたの燃えるような疑問に答えましょう。 データエンジニアの職務内容 データエンジニアは、生データを貴重な洞察に変換し、ビジネスアナリストやデータサイエンティストが活用できるように、データを収集、管理、変換することで重要な役割を果たします。彼らの主な目的は、データのアクセシビリティを確保し、企業がパフォーマンスを最適化し、情報に基づいた意思決定を行うことを可能にすることです。彼らはアルゴリズムを設計し、統計を分析し、ビジネス目標に応じてデータシステムを整合させ、効率を最大化します。データエンジニアには強力な分析スキル、多様なソースからデータを統合する能力、プログラミング言語の熟練度、および機械学習技術の知識が必要です。データエンジニアの職務内容は広範であり、組織のデータ主導の成功に貢献する多くの役割と責任を包括しています。 データエンジニアの役割と責任 データエンジニアの役割と責任は、要件に基づいて会社によって異なる場合があります。ただし、一般的なデータエンジニアの責任には、以下が含まれます: 完璧なデータパイプライン設計の開発および維持。 手動操作の自動化、データ配信の改善、スケーラビリティの向上のためのインフラ再設計など、内部プロセスの改善を特定し、計画し、実行する。 SQLおよびAWSビッグデータ技術を利用して、幅広いデータソースからの効果的なデータ抽出、変換、およびロードに必要なインフラの作成。 機能的および非機能的なビジネス目標を満たす膨大で複雑なデータセットの作成。 データファンネルを利用した分析ソリューションの構築により、新しい顧客獲得、業務効率改善、およびその他の重要な企業パフォーマンス指標に対する具体的な洞察を提供する。 エグゼクティブ、プロダクト、データ、およびデザインチームなどのステークホルダーがデータインフラ関連の課題に直面した場合に、彼らのデータインフラ要件を満たすために支援する。 複数のデータセンターやAWSリージョンを利用することで、国際境界を越えたデータのプライバシーとセキュリティを維持する。 データおよび分析プロフェッショナルと協力して、データシステムの運用を改善する。 さらに読む:ジョブ比較-データサイエンティストvsデータエンジニアvs統計学者 データエンジニアに必要なスキル データエンジニアになりたい場合、ある程度の技術的およびソフトスキルに精通している必要があります。 技術的スキル 自分たちの役割で優れた成果を出すために、データエンジニアは以下の技術的スキルを持っている必要があります。 コーディング Python、Java、SQL、NoSQL、Ruby、Perl、MatLab、R、SAS、C and C++、Scala、Golangなどのプログラミング言語の熟練度は、ほとんどの企業で高く評価されます。コーディングの堅牢な基盤は、データエンジニアのポジションにおいて不可欠です。 オペレーティングシステムの理解 データエンジニアは、Microsoft…
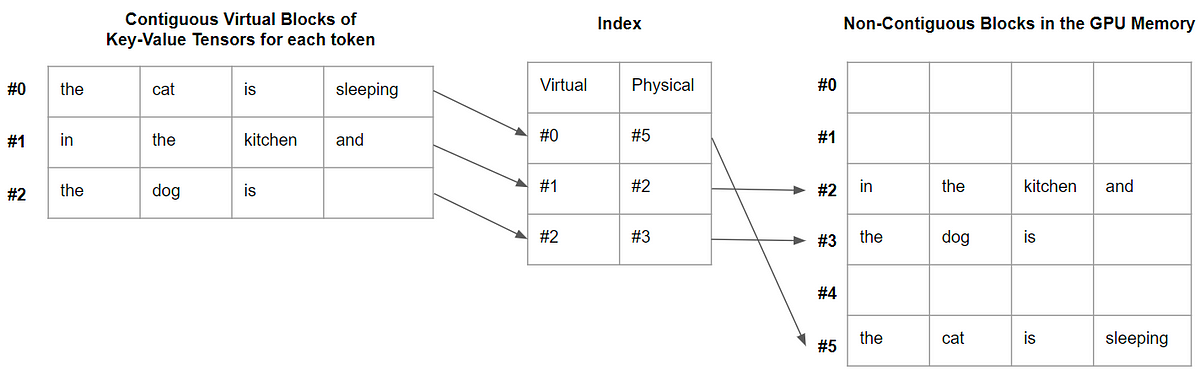
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します
私の博士号入学への道 – 人工知能
大学の出願書類を取り組んで、日々をカウントダウンして過ごした6ヶ月間の後、2023年秋に人工知能の博士号を取得することになりました以下の内容をまとめてみました…
特徴量が多すぎる?主成分分析を見てみましょう
次元の呪いは、機械学習における主要な問題の1つです特徴量の数が増えると、モデルの複雑さも増しますさらに、十分なトレーニングデータがない場合、それは...

紛争のトレンドとパターンの探索:マニプールのACLEDデータ分析
はじめに データ分析と可視化は、複雑なデータセットを理解し、洞察を効果的に伝えるための強力なツールです。この現実世界の紛争データを深く掘り下げる没入型探索では、紛争の厳しい現実と複雑さに深く踏み込みます。焦点は、長期にわたる暴力と不安定状態によって悲惨な状況に陥ったインド北東部のマニプール州にあります。私たちは、武装紛争ロケーション&イベントデータプロジェクト(ACLED)データセット[1]を使用し、紛争の多面的な性質を明らかにするための詳細なデータ分析の旅に出ます。 学習目標 ACLEDデータセットのデータ分析技術に熟達する。 効果的なデータ可視化のスキルを開発する。 脆弱な人口に対する暴力の影響を理解する。 紛争の時間的および空間的な側面に関する洞察を得る。 人道的ニーズに対処するための根拠に基づくアプローチを支援する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 利害の衝突 このブログで提示された分析と解釈に責任を持つ特定の組織や団体はありません。目的は、紛争分析におけるデータサイエンスの潜在力を紹介することです。さらに、これらの調査結果には個人的な利益や偏見が含まれておらず、紛争のダイナミクスを客観的に理解するアプローチが確保されています。データ駆動型の方法を促進し、紛争分析に関する広範な議論に情報を提供するために、積極的に利用することを推奨します。 実装 なぜACLEDデータセットを使用するのか? ACLEDデータセットを活用することで、データサイエンス技術の力を活用することができます。これにより、マニプール州の状況を理解するだけでなく、暴力に関連する人道的側面にも光を当てることができます。ACLEDコードブックは、このデータセット[2]で使用されるコーディングスキームと変数に関する詳細な情報を提供する包括的な参考資料です。 ACLEDの重要性は、共感的なデータ分析にあります。これにより、マニプール州の暴力に関する理解が深まり、人道的ニーズが明らかにされ、暴力の解決と軽減に貢献します。これにより、影響を受けるコミュニティに平和で包摂的な未来が促進されます。 このデータ駆動型の分析により、貴重な洞察力を得るだけでなく、マニプール州の暴力の人的コストにも光が当てられます。ACLEDデータを精査することで、市民人口、強制的移動、必要なサービスへのアクセスなど、地域で直面する人道的現実の包括的な描写が可能になります。 紛争のイベント まず、ACLEDデータセットを使用して、マニプール州の紛争のイベントを調査します。以下のコードスニペットは、インドのACLEDデータセットを読み込み、マニプール州のデータをフィルタリングして、形状が(行数、列数)のフィルタリングされたデータセットを生成します。フィルタリングされたデータの形状を出力します。 import pandas as pd # ACLEDデータをダウンロードして国別のcsvをインポートする…

AIの未来を形作る ビジョン・ランゲージ・プリトレーニング・モデルの包括的な調査と、ユニモーダルおよびマルチモーダルタスクにおける役割
機械学習研究の最新リリースで、ビジョン言語事前学習(VLP)とその多様なタスクへの応用について、研究チームが深く掘り下げています。この論文は、単一モーダルトレーニングのアイデアを探究し、それがマルチモーダル適応とどのように異なるかを説明しています。そして、VLPの5つの重要な領域である特徴抽出、モデルアーキテクチャ、事前トレーニング目標、事前トレーニングデータセット、およびダウンストリームタスクを示しています。研究者たちは、既存のVLPモデルとその異なる側面での適応をレビューしています。 人工知能の分野は常に、モデルを人間と同じように知覚、思考、そしてパターンや微妙なニュアンスを理解する方法でトレーニングしようとしてきました。ビジュアル、オーディオ、テキストなど、可能な限り多くのデータ入力フィールドを組み込もうとする試みがいくつか行われてきました。ただし、これらのアプローチのほとんどは、単一モーダル意味で「理解」の問題を解決しようとしたものです。 単一モーダルアプローチは、1つの側面のみを評価するアプローチであり、例えばビデオの場合、音声またはトランスクリプトに焦点を絞っており、マルチモーダルアプローチでは、可能な限り多くの利用可能な特徴をターゲットにしてモデルに組み込もうとします。たとえば、ビデオを分析する際に、音声、トランスクリプト、スピーカーの表情をとらえて、文脈を本当に「理解」することができます。 マルチモーダルアプローチは、リソースが豊富であり、訓練に必要な大量のラベル付きデータを取得することが困難であるため、課題があります。Transformer構造に基づく事前トレーニングモデルは、自己教師あり学習と追加タスクを活用して、大規模な非ラベルデータからユニバーサルな表現を学習することで、この問題に対処しています。 NLPのBERTから始まり、単一モーダルの方法でモデルを事前トレーニングすることで、限られたラベル付きデータでダウンストリームタスクを微調整することができることが示されています。研究者たちは、同じ設計哲学をマルチモーダル分野に拡張することで、ビジョン言語事前学習(VLP)の有効性を探究しました。VLPは、大規模なデータセットで事前トレーニングモデルを使用して、モダリティ間の意味的な対応関係を学習します。 研究者たちは、VLPアプローチの進歩について、5つの主要な領域を検討しています。まず、VLPモデルが画像、ビデオ、テキストを前処理して表現する方法、使用されるさまざまなモデルを強調して説明しています。次に、単一ストリームの観点とその使用可能性、デュアルストリームフュージョンとエンコーダのみ対エンコーダデコーダ設計の観点を探究しています。 論文では、VLPモデルの事前トレーニングについてさらに探求し、完了、マッチング、特定のタイプに分類しています。これらの目標は、ユニバーサルなビジョン言語表現を定義するのに役立ちます。研究者たちは、2つの主要な事前トレーニングデータセットのカテゴリである画像言語モデルとビデオ言語モデルについて概説しました。論文では、マルチモーダルアプローチが文脈を理解し、より適切にマッピングされたコンテンツを生成するためにどのように役立つかを強調しています。最後に、記事は、事前トレーニングモデルの有効性を評価する上での重要性を強調しながら、VLPのダウンストリームタスクの目標と詳細を提示しています。 https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf この論文では、SOTA(State-of-the-Art)のVLPモデルについて詳細な概要が提供されています。これらのモデルをリストアップし、その主要な特徴やパフォーマンスを強調しています。言及されているモデルは、最先端の技術開発の堅固な基盤であり、将来の開発のベンチマークとして役立ちます。 研究論文に基づくと、VLPアーキテクチャの将来は有望で信頼性があります。彼らは、音響情報の統合、知識と認知学習、プロンプトチューニング、モデル圧縮と加速、およびドメイン外の事前学習など、様々な改善の領域を提案しています。これらの改善領域は、新しい研究者たちがVLPの分野で前進し、画期的なアプローチを打ち出すためにインスピレーションを与えることを目的としています。
線形回帰の理論的な深堀り
多くのデータサイエンス志望のブロガーが行うことがあります 線形回帰に関する入門的な記事を書くことですこれは、この分野に入る際に最初に学ぶモデルの1つであるため、自然な選択肢です...
Pythonの依存関係管理:どのツールを選ぶべきですか?
あなたのデータサイエンスプロジェクトが拡大するにつれて、依存関係の数も増えますプロジェクトの環境を再現可能かつメンテナンス可能に保つために、効率的な依存関係を使用することが重要です...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.