Learn more about Search Results A - Page 815

- You may be interested
- 神経協調フィルタリングでレコメンデーシ...
- Mistral-7B-v0.1をご紹介します:新しい大...
- 拡散モデル:どのように拡散するのでしょ...
- Hugging Face Hubへようこそ、spaCyさん
- 「パクストンAIの共同創業者兼CEO、タング...
- ChatHNに会いましょう:ハッカーニュース...
- 「指先で軽く触れるだけで仮想オブジェク...
- 「ファインチューニング中に埋め込みのア...
- シンガポール国立大学の研究者が提案するM...
- 『日常のデザイン(AI)』
- 『特徴変換における欠損値の詳細な処理/代...
- 人工知能による投資アドバイス – メ...
- 「OpenAIのWebクローラーとFTCのミスステ...
- クラウドコンピューティングとウェアラブ...
- このAI論文では、Complexity-Impacted Rea...

Google DeepMindの発表
DeepMindとGoogle ResearchのBrainチームは、人工知能が人類が直面する最大の課題を解決するのに役立つ世界に向けて進歩を加速させるために協力します
.jpg)
DeepMindの最新研究(ICLR 2023)
来週は、2022年5月1日から5日までルワンダのキガリで開催される第11回国際学習表現会議(ICLR)の始まりを迎えますこれはアフリカで開催される初めての主要な人工知能(AI)の会議であり、パンデミックの始まり以来の初の対面イベントです世界中の研究者が集まり、AI、統計学、データサイエンスを含む深層学習の最先端の研究成果、およびマシンビジョン、ゲーム、ロボット工学を含む応用分野について共有します私たちはダイヤモンドスポンサーおよびDEIチャンピオンとして、この会議をサポートすることを誇りに思っています

ロボキャット:自己改善型ロボティックエージェント
ロボットは私たちの日常生活の一部として急速になっていますが、彼らはしばしば特定のタスクをうまく実行するためにのみプログラムされています最近のAIの進歩を活用することで、より多くの方法で助けることができるロボットが可能になるかもしれませんが、一般的な用途のロボットの構築には、現実世界のトレーニングデータを収集するために必要な時間の制約があり、進展が遅れています私たちの最新の論文では、自己改善型のAIエージェントであるロボキャットを紹介していますロボキャットは、異なるアームでさまざまなタスクを実行する方法を学び、その後、新しいトレーニングデータを自己生成して技術を向上させるのです

あなたのオープンソースのLLMプロジェクトはどれくらいリスクがあるのでしょうか?新たな研究がオープンソースのLLMに関連するリスク要因を説明しています
大規模言語モデル(LLM)と生成AI、例えばGPTエンジンは、最近AIの領域で大きな波を起こしており、小売個人や企業の間でこの新しいテクノロジーの波に乗ることへの大きな期待が市場に広がっています。しかし、この技術が市場で複数のユースケースを急速に担っている中で、特にオープンソースのLLMに関連するリスクについて、より詳細に注意を払い、使用に関連するリスクについてもっと詳細に注意を払う必要があります。 有名な自動ソフトウェア供給チェーンセキュリティプラットフォームであるRezilionが最近行った研究では、この具体的な問題を調査し、その結果は私たちを驚かせます。彼らは次の条件に合致するすべてのプロジェクトを考慮しました: 8ヶ月以内に作成されたプロジェクト(この論文の発表時点での2022年11月から2023年6月まで) LLM、ChatGPT、Open-AI、GPT-3.5、またはGPT-4のトピックに関連するプロジェクト GitHubで少なくとも3,000のスターを持つプロジェクト これらの条件により、主要なプロジェクトが研究の対象になることが保証されました。 彼らは研究を説明するために、Open Source Security Foundation(OSSF)が作成したScorecardというフレームワークを使用しました。Scorecardは、オープンソースプロジェクトのセキュリティを評価し、改善することを目的としたSASTツールです。評価は、脆弱性の数、定期的なメンテナンスの頻度、バイナリファイルの有無など、リポジトリに関するさまざまな情報に基づいて行われます。 これらのチェックの目的は、セキュリティのベストプラクティスと業界標準の遵守を確保することです。各チェックにはリスクレベルが関連付けられています。リスクレベルは、特定のベストプラクティスに準拠しないことに関連する推定リスクを表し、スコアに重みを加えます。 現在、18のチェックは3つのテーマに分けることができます:包括的なセキュリティプラクティス、ソースコードのリスク評価、およびビルドプロセスのリスク評価。OpenSSF Scorecardは、各チェックに対して0から10の序数スコアとリスクレベルスコアを割り当てます。 結果として、これらのほとんどのオープンソースのLLMとプロジェクトは、専門家が以下のように分類した重要なセキュリティ上の懸念事項に取り組んでいます: 1.信頼境界のリスク 不適切なサンドボックス化、不正なコードの実行、SSRFの脆弱性、不十分なアクセス制御、さらにはプロンプトインジェクションなどのリスクは、信頼境界の一般的な概念に該当します。 誰でも任意の悪意のあるnlpマスクコマンドを挿入することができ、それは複数のチャンネルを越えて伝播し、ソフトウェアチェーン全体に深刻な影響を与える可能性があります。 人気のある例の1つはCVE-2023-29374 LangChainの脆弱性(3番目に人気のあるオープンソースgpt)です。 2. データ管理リスク データ漏洩やトレーニングデータの改竄は、データ管理のリスクカテゴリに該当します。これらのリスクは、大規模言語モデルに限定されるものではなく、どんな機械学習システムにも関連しています。 トレーニングデータの改竄は、攻撃者がLLMのトレーニングデータや微調整手順を意図的に操作して、モデルのセキュリティ、効果性、倫理的な振る舞いを損なう脆弱性、バックドア、バイアスを導入することを指します。この悪意のある行為は、トレーニングプロセス中に誤解を招く情報や有害な情報を注入することで、LLMの完全性と信頼性を危険にさらすことを目的としています。 3.…
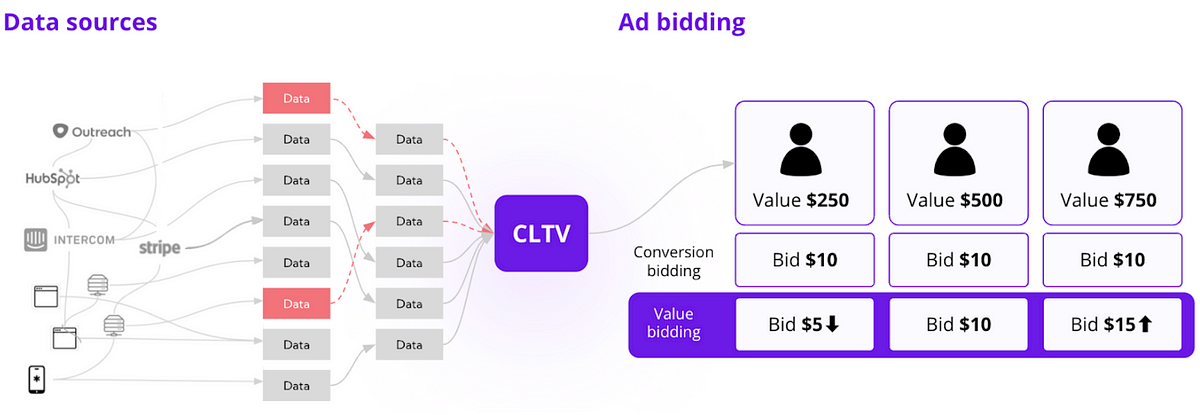
広告費用の収益率におけるデータ品質の問題の隠れたコスト
あなたのデータには、銀行口座になる顧客とならない顧客について多くの情報がありますB2B企業でライフサイクルマーケティングマネージャーとして働いているかどうかに関係なく、それは事実です
ロジスティック回帰における行列とベクトルの演算
任意の人工ニューラルネットワーク(ANN)アルゴリズムの基礎となる数学は理解するのが困難かもしれませんさらに、フィードフォワードや...
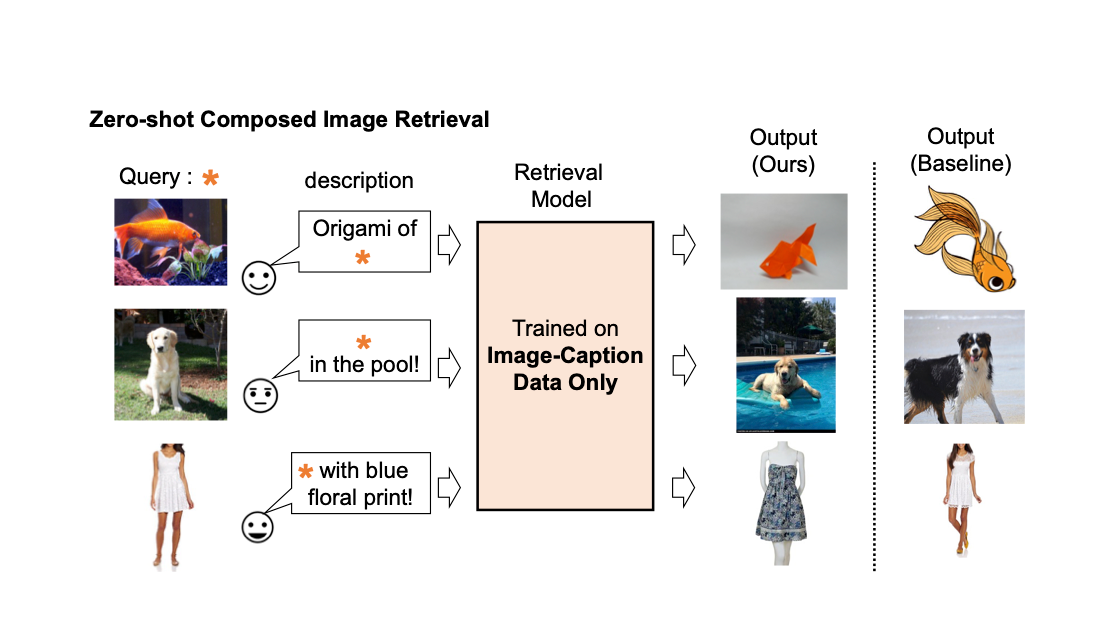
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…

実際の無人運転車を仮想環境でテストする
オハイオ州立大学の研究者が開発した「Vehicle-in-Virtual-Environment」ソフトウェアは、完全に安全な仮想環境で自動運転車のテストを可能にします

ファイバーオプティックスマートパンツは、動きを監視する低コストな方法を提供します
研究者たちは、ポリマーオプティカルファイバーを使用したスマートパンツを開発しましたこのパンツは、着用者の動きを追跡し、苦痛の兆候が検知された場合には臨床医や介護者に警告を発することができます

データサイエンスにおける正規分布の適用と使用
データサイエンスを始める際に非常に困難なことの一つは、その旅がどこから始まり、どこで終わるのかを正確に把握することですデータサイエンスの旅の終わりに関して言えば、それは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.