Learn more about Search Results A - Page 813

- You may be interested
- 「2023年のAi4カンファレンスでジェネレー...
- 「AIを暴走させようとするハッカーたちに...
- 最適化アルゴリズム:ニューラルネットワ...
- 「ネットイース・ヨウダオがEmotiVoiceを...
- 「AIはオーディオブック制作をどのように...
- 「ICML 2023でのGoogle」
- 南開大学と字節跳動の研究者らが『ChatAny...
- 「DIRFAは、オーディオクリップをリアルな...
- Pythonコードの行数を100行未満で使用した...
- ジャバとデータエンジニアリング
- AWS Inferentiaでのディープラーニングト...
- 『広範な展望:NVIDIAの基調講演がAIの更...
- 紙のような、バッテリー不要のAI対応セン...
- 人工知能(AI)と法的身分
- バーゼル大学病院が、「TotalSegmentator...
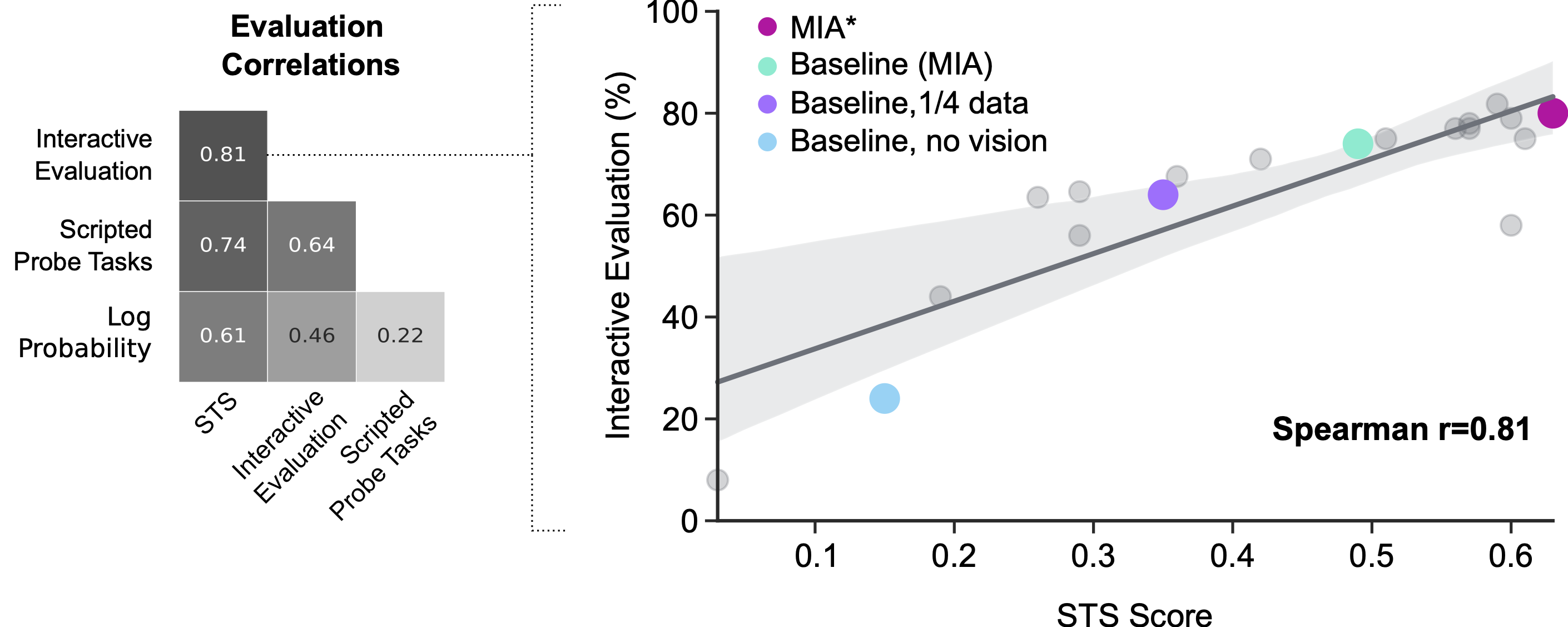
マルチモーダルインタラクティブエージェントの評価
この論文では、これらの既存の評価尺度の利点を評価し、Standardised Test Suite (STS) と呼ばれる評価方法の新しいアプローチを提案しますSTSは、実際の人間の相互作用データから採掘された行動シナリオを使用します

スケールを通じた高精度の差分プライバシー画像分類の解除
前の研究の経験的な証拠によると、DP-SGDにおける効用の低下は、より大規模なニューラルネットワークモデルでより深刻になる傾向がありますこれには、難しい画像分類のベンチマークで最高のパフォーマンスを達成するために定期的に使用されるモデルも含まれます私たちの研究では、この現象を調査し、トレーニング手順とモデルアーキテクチャの両方に一連の単純な修正を提案して、標準的な画像分類ベンチマークでのDPトレーニングの正確性を大幅に向上させることを示しています
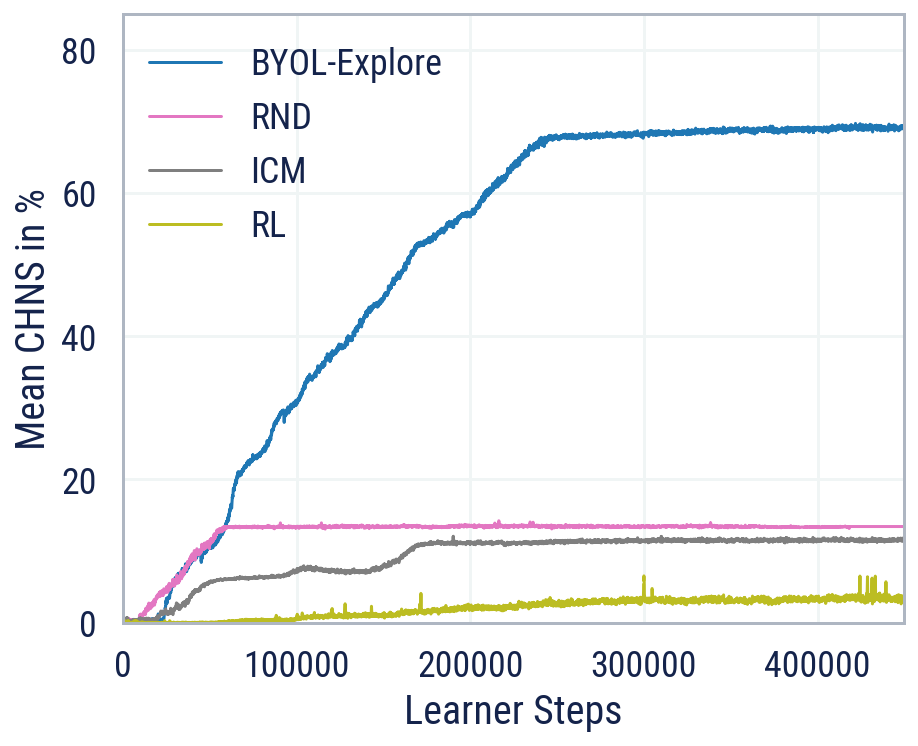
BYOL-Explore ブートストラップ予測による探索
BYOL-Exploreを紹介しますこれは、視覚的に複雑な環境での好奇心に基づいた探索のための概念的にシンプルでありながら一般的なアプローチですBYOL-Exploreは、追加の補助的な目的ではなく、潜在空間での単一の予測損失を最適化することによって、世界表現、世界の動態、および探索方針をすべて一緒に学習します我々は、BYOL-Exploreが視覚的に豊かな3D環境を持つ難解な部分観測可能な連続アクションの困難な探索ベンチマークであるDM-HARD-8で効果的であることを示します

アフリカにおける機械学習の強化を推進する運動のリーダーシップ
オープンな役割を表示する: https://www.deepmind.com/careers/jobs?sort=alphabetical Game Theory and Multi-agentチームの研究エンジニアであるAvishkar Bhoopchandは、DeepMindへの道のりと、彼がアフリカ全土でディープラーニングの知名度を高めるために取り組んでいることについて共有しています。 Deep Learning Indaba 2022について詳しく知るには、毎年開催されるアフリカのAIコミュニティの集まりであるDeep Learning Indaba 2022をご覧ください。今年の8月、チュニジアで開催されます。 仕事の典型的な1日はどのようなものですか? 研究エンジニアおよびテクニカルリードとして、毎日同じではありません。通勤中にポッドキャストやオーディオブックを聴くことから始めることが多いです。朝食後、メールとアドミンに集中してから最初のミーティングに入ります。これらは、チームメンバーとの個別のミーティングやプロジェクトの更新、多様性、公平性、包含(DE&I)の作業グループなど様々です。 午後には、自分のやることリストのための時間を確保しようとします。これらのタスクには、プレゼンテーションの準備、研究論文の読み込み、コードの記述やレビュー、実験の設計と実施、結果の分析などが含まれることがあります。 在宅勤務の場合、私の犬フィンが私を忙しくさせます!彼に教えることは、強化学習(RL)のようなものです – 職場で人工エージェントを訓練する方法のようなものです。そのため、私の時間の多くはディープラーニングや機械学習について考えることに費やされます。 AIに興味を持つようになったきっかけは何ですか? ケープタウン大学で知能エージェントのコースを受講している最中、私の講師がRLを用いてゼロから歩くことを学んだ六脚ロボットのデモを行いました。その瞬間から、人間や動物のメカニズムを使用して学習可能なシステムを構築する可能性について考えることができなくなりました。 当時、南アフリカでは機械学習の応用や研究は実際には選択肢ではありませんでした。私の同僚の多くと同様に、私もソフトウェアエンジニアとして金融業界で働くことになりました。大規模で堅牢なシステムの設計やユーザー要件を満たすための経験を積むことができました。しかし、6年後、私はもっと何かを求めるようになりました。 その頃、ディープラーニングが急速に広まり始めました。最初はCourseraのAndrew…

発達心理学に触発された深層学習モデルによる直感的な物理学の学習
現在のAIシステムは、非常に若い子供に比べても直感的な物理学の理解において劣っています本研究では、このAIの問題に取り組み、具体的には発達心理学の分野に基づいています

YouTubeと協力しています
YouTubeの体験向上のために、私たちのAI研究を活用しています私たちの研究によって人々の生活を豊かにすることを支援し、Alphabetの企業と提携して、私たちの技術を日々数十億人が利用する製品やサービスの改善に活かしています

DeepMindの最新の研究(ICML 2022)
今週末から、第39回国際機械学習会議(ICML 2022)が2022年7月17日から23日まで、アメリカのメリーランド州ボルチモアのボルチモア・コンベンションセンターでハイブリッド形式で開催されます人工知能、データサイエンス、機械ビジョン、計算生物学、音声認識などの分野で研究を行っている研究者たちが、機械学習の最先端の研究成果を発表し、出版します

科学者が本当のスーパーヒーローであることを実感する
私たちのマルチエージェント研究チームの研究エンジニアであるエドガー・ドゥエニェス・グスマンにお会いください彼は、ゲーム理論、コンピュータサイエンス、社会進化の知識を活用して、AIエージェントがより良く協力するための取り組みを行っています
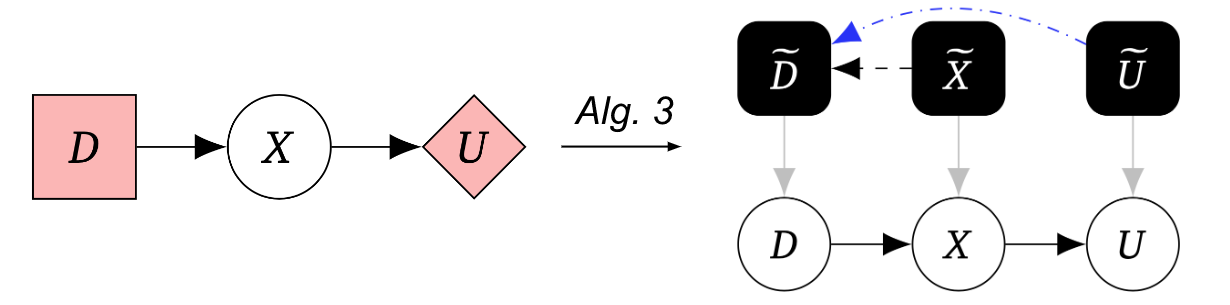
システムにエージェントが存在するかを発見する
私たちは、意図した目標を追求する安全で適合した人工汎用知能(AGI)システムを構築したいと考えています因果関係図(CIDs)は、エージェントのインセンティブについて推論することができる意思決定状況をモデル化する方法ですトレーニングの設定とエージェントの行動を形成するインセンティブを関連付けることで、CIDsはエージェントをトレーニングする前に潜在的なリスクを明らかにし、より良いエージェントの設計にインスピレーションを与えることができますしかし、CIDがトレーニングの設定の正確なモデルであるかどうかをどのように知ることができるでしょうか?

モーターコントロールから具現化された知能へ
人間や動物の動きを用いて、ロボットにボールをドリブルさせることや、シミュレートされた人型キャラクターに箱を運ばせたりサッカーをさせることを教える 試行錯誤を通じて障害物コースを進む方法を学ぶ人型キャラクター。これにより独特な解決策が生まれることがあります。 Heessら「Emergence of locomotion behaviours in rich environments」(2017)より。 5年前、完全に関節の動く人型キャラクターに障害物コースを進む方法を教えるという課題に取り組みました。これは強化学習(RL)が試行錯誤を通じて何ができるかを示しましたが、具体的な知識がない状態から各関節にどのような力を加えるべきかを知るためには、多くのデータが必要でした。エージェントはランダムな体の震えから始まり、すぐに地面に倒れてしまいました。この問題は、以前に学んだ動きを再利用することで緩和することができます。 以前に学んだ動きの再利用:エージェントが「立ち上がる」ためには大量のデータが必要でした。初めはどの関節にどのような力を加えるべきかを知らなかったため、エージェントはランダムな体の震えから始まり、すぐに地面に倒れてしまいました。この問題は、以前に学んだ動きを再利用することで緩和することができます。 独特な動き:エージェントがついに障害物コースを進む方法を学んだとしても、不自然な(しかし面白い)動きパターンで進むことになります。これは、ロボットなどの実際の応用には非現実的である可能性があります。 ここでは、これらの課題に対する解決策であるニューラル確率モーター原理(NPMP)と呼ばれる手法を説明し、人型フットボールの論文でどのようにこの手法が使用されているかについても議論します。この論文は、本日Science Roboticsで公開されました。 また、この手法は、ビジョンからの人型の全身操作(例:物体を運ぶ人型)や現実世界でのロボット制御(例:ボールをドリブルするロボット)も可能にすることについても議論します。 NPMPを使用してデータを制御可能なモータープリミティブに絞り込む NPMPは、短期間のモーター意図を低レベルの制御信号に変換する汎用のモーター制御モジュールであり、オフラインまたはRLを介して動作キャプチャ(MoCap)データを模倣することで訓練されます。このMoCapデータは、興味のある動作を行う人間や動物にトラッカーを装着して記録されます。 MoCap軌跡(グレーで表示)を模倣するエージェント このモデルには2つの部分があります: 将来の軌跡を受け取り、モーター意図に圧縮するエンコーダー。 エージェントの現在の状態とこのモーター意図に基づいて次のアクションを生成する低レベルコントローラー。 NPMPモデルはまず参照データを低レベルコントローラーに絞り込みます(左)。この低レベルコントローラーは、新しいタスクにプラグアンドプレイのモーター制御モジュールとして使用できます(右) トレーニング後、低レベルコントローラは新しいタスクを学習するために再利用できます。一方、高レベルコントローラはモーターの意図を直接最適化することができます。これにより、効率的な探索が可能になります。ランダムにサンプリングされたモーターの意図でも、連続した行動が生成されるため、最終的な解決策が制約されます。 ヒューマノイドフットボールにおける発生的なチーム協調…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.