Learn more about Search Results Yi - Page 80

- You may be interested
- 「Pythonデータ構造について知っておくべ...
- ゲーム開発のためのAI:5日間で農業ゲーム...
- なぜ人々は人工知能AIを恐れているのか?
- 「データサイエンティストプロフェッショ...
- AIフロンティアシリーズ:人材
- 微調整、再教育、そして更なる進化:カス...
- 「ML技術はがん治療率をより正確に予測す...
- DPT(Depth Prediction Transformers)を...
- 「すべてのオンライン投稿は、AIの所有物...
- 「個人AIの世界におけるプライバシー、信...
- 「強化学習の実践者ガイド」
- 新しいCMUとMetaによるAI研究、PyNeRFの導...
- 「Amazon SageMaker JumpStartで大規模な...
- ペース、努力、スタミナ
- データ・コモンズは、AIを使用して世界の...

健康医療におけるバイアスとの闘いに参加する
Leo Anthony Celiは、あらゆる人口に対する臨床データの収集と分析において、産業が焦点を広げるよう招待しています
AIにおいて大胆であることは、最初から責任を持つことを意味します
GoogleのJames Manyika氏は、Googleが人々と社会に利益をもたらすためにAIを責任ある形で適用する方法について話しています

「Storytelling with Data」によると、データの視覚化をすぐに改善するためのMatplotlibのヒント
「Storytelling with Data」(Cole Nussbaumer Knaflic著)で得た教訓に基づいて、Matplotlibとseabornのデータ可視化を改善する方法

RedPajamaプロジェクト:LLMの民主化を目指すオープンソースイニシアチブ
アクセス可能な大規模言語モデルを通じてコミュニティを強化するプロジェクトのリーダーシップを担っています

より速いデータ検索のためのSQLクエリの最適化方法
今日は、なぜSQLクエリの最適化が重要であり、どのようなテクニックを使用して最適化できるかについて話します

連邦政府、自動車メーカーに対し、マサチューセッツ州の「修理の権利」法に従わないよう指示
州の修理権法は、テレマティクスサービスへのオープンアクセスを求めています
Word2Vec、GloVe、FastText、解説
コンピューターは我々と同じように単語を理解することができませんコンピューターは数字を扱うことが好きですですから、コンピューターが単語とその意味を理解するのを助けるために、私たちは「埋め込み」と呼ばれるものを使用しますこれらの埋め込みは…

Boto3 vs AWS Wrangler PythonによるS3操作の簡素化
このチュートリアルでは、boto3とawswranglerの2つの強力なライブラリを探索し、比較することで、PythonによるAWS S3開発の世界に深く入り込んでいきます実際、この記事では以下の内容をカバーします…
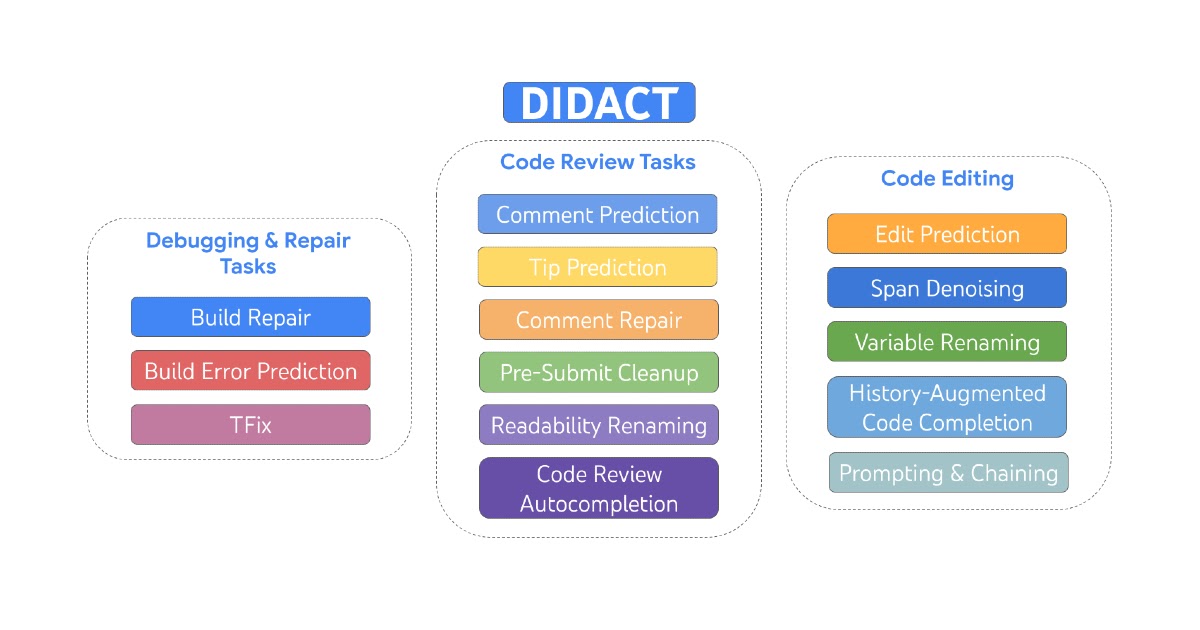
ソフトウェア開発活動のための大規模シーケンスモデル
Google の研究科学者である Petros Maniatis と Daniel Tarlow が投稿しました。 ソフトウェアは一度に作られるわけではありません。編集、ユニットテストの実行、ビルドエラーの修正、コードレビューのアドレス、編集、リンターの合意、そしてより多くのエラーの修正など、少しずつ改善されていきます。ついには、コードリポジトリにマージするに十分な良い状態になります。ソフトウェアエンジニアリングは孤立したプロセスではなく、人間の開発者、コードレビュワー、バグ報告者、ソフトウェアアーキテクト、コンパイラ、ユニットテスト、リンター、静的解析ツールなどのツールの対話です。 今日、私たちは DIDACT(Dynamic Integrated Developer ACTivity)を説明します。これは、ソフトウェア開発の大規模な機械学習(ML)モデルをトレーニングするための方法論です。 DIDACT の新規性は、完成したコードの磨き上げられた最終状態だけでなく、ソフトウェア開発のプロセス自体をトレーニングデータのソースとして使用する点にあります。開発者が作業を行う際に見るコンテキストと、それに対するアクションを組み合わせて、モデルはソフトウェア開発のダイナミクスについて学び、開発者が時間を費やす方法により合わせることができます。私たちは、Google のソフトウェア開発の計装を活用して、開発者活動データの量と多様性を以前の作品を超えて拡大しました。結果は、プロのソフトウェア開発者にとっての有用性と、一般的なソフトウェア開発スキルを ML モデルに注入する可能性という2つの側面で非常に有望です。 DIDACT は、編集、デバッグ、修復、およびコードレビューを含む開発活動をトレーニングするマルチタスクモデルです。 私たちは DIDACT Comment…

検索増強視覚言語事前学習
Google Research Perceptionチームの学生研究者Ziniu Huと研究科学者Alireza Fathiによる投稿 T5、GPT-3、PaLM、Flamingo、PaLIなどの大規模なモデルは、数百億のパラメータにスケーリングされ、大規模なテキストおよび画像データセットでトレーニングされると、多大な量の知識を格納する能力を示しました。これらのモデルは、画像キャプション、ビジュアルクエスチョンアンサリング、オープンボキャブラリー認識などのダウンストリームタスクで最先端の結果を達成しています。しかし、これらのモデルはトレーニングに膨大な量のデータを必要とし、数十億のパラメータ(多くの場合)を持ち、著しい計算要件を引き起こします。また、これらのモデルをトレーニングするために使用されるデータは古くなる可能性があり、世界の知識が更新されるたびに再トレーニングが必要になる場合があります。たとえば、2年前にトレーニングされたモデルは、現在のアメリカ合衆国大統領に関する古い情報を提供する可能性があります。 自然言語処理(RETRO、REALM)およびコンピュータビジョン(KAT)の分野では、検索増強モデルを使用してこれらの課題に取り組む研究がなされてきました。通常、これらのモデルは、単一のモダリティ(テキストのみまたは画像のみ)を処理できるバックボーンを使用して、知識コーパスから情報をエンコードおよび取得します。ただし、これらの検索増強モデルは、クエリと知識コーパスのすべての利用可能なモダリティを活用できず、モデルの出力を生成するために最も役立つ情報を見つけられない場合があります。 これらの問題に対処するために、「REVEAL:Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory」(CVPR 2023に掲載予定)では、複数のソースのマルチモーダル「メモリ」を利用して知識集中型クエリに答えることを学ぶビジュアル言語モデルを紹介します。REVEALは、ニューラル表現学習を使用して、さまざまな知識ソースをキー-バリューペアから成るメモリ構造に変換し、エンコードします。キーはメモリアイテムのインデックスとして機能し、対応する値はそれらのアイテムに関する関連情報を格納します。トレーニング中、REVEALは、キーエンベッディング、値トークン、およびこのメモリから情報を取得する能力を学習して、知識集中型クエリに対処します。このアプローチにより、モデルパラメータは暗記に専念するのではなく、クエリに関する推論に焦点を当てることができます。 多様な知識ソースから複数の知識エントリを取得する能力を持つビジュアル言語モデルを拡張することで、生成を支援します。 マルチモーダル知識コーパスからのメモリ構築 私たちのアプローチは、異なるソースからの知識アイテムのキーと値のエンベッディングを事前に計算し、キー-バリューペアにエンコードして統一された知識メモリにインデックスするREALMと似ています。各知識アイテムは、より詳細に表現されたトークンエンベッディングのシーケンスである値としてエンコードされます。以前の研究とは異なり、REVEALは、WikiData知識グラフ、Wikipediaのパッセージと画像、Web画像テキストペア、ビジュアルクエスチョンアンサリングデータなど、多様なマルチモーダル知識コーパスを活用しています。各知識アイテムは、テキスト、画像、両方の組み合わせ(たとえば、Wikipediaのページ)、または知識グラフからの関係または属性(たとえば、バラク・オバマは6’2 “の背丈)の場合があります。トレーニング中、モデルパラメータが更新されるたびに、REVEALはキーと値のエンベッディングを連続的に再計算します。ステップごとにメモリを非同期に更新します。 圧縮を使用したメモリのスケーリング メモリ値をエンコードするための素朴な解決策は、各知識アイテムのトークンのすべてのシーケンスを保持することです。次に、モデルは、すべてのトークンを連結してトランスフォーマーエンコーダーデコーダーパイプラインに送信することで、入力クエリとトップkの取得されたメモリ値を融合することができます。このアプローチには2つの問題があります。1つ目は、数億の知識アイテムをメモリに保持する場合、各メモリ値が数百のトークンから構成されている場合、実用的ではないことです。2つ目は、トランスフォーマーエンコーダーが自己注意のために合計トークン数×kに対して2次の複雑度を持っていることです。そのため、Perceiverアーキテクチャを使用して知識アイテムをエンコードおよび圧縮することを提案しています。Perceiverモデルは、トランスフォーマーデコーダーを使用して、フルトークンシーケンスを任意の長さに圧縮します。これにより、kが100にもなるトップkメモリエントリを取得できます。 以下の図は、メモリのキー-バリューペアを構築する手順を示しています。各知識項目は、マルチモーダル視覚言語エンコーダを介して処理され、画像とテキストのトークンのシーケンスに変換されます。キー・ヘッドはこれらのトークンをコンパクトな埋め込みベクトルに変換します。バリュー・ヘッド(パーセプター)は、これらのトークンを少なくし、知識項目に関する適切な情報を保持します。 異なるコーパスからの知識エントリを統一されたキーとバリューの埋め込みペアにエンコードし、キーはメモリのインデックスに使用され、値にはエントリに関する情報が含まれます。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.