Learn more about Search Results MPT - Page 80

- You may be interested
- MPT-7Bをご紹介します MosaicMLによってキ...
- 敵対的なデータを使用してモデルを動的に...
- 「迅速エンジニアリングのための普遍的な...
- 「声AIがLLVCを発表:効率と速度に優れた...
- アマゾンセージメーカーの地理空間機能を...
- 『LEOと出会いましょう:先進的な3Dワール...
- 「ジェイソン・フラックスとともに会話型A...
- Amazon MusicはSageMakerとNVIDIAを使用し...
- データサイエンティストやアナリストのた...
- 「神秘的なニューラルマジックの解明:ア...
- 「これら6つの必須データサイエンススキル...
- 「ソーシャルメディアと機械学習を使用し...
- 「エンパワーリング・インサイト: マイク...
- 「スマートフォンのアタッチメントが神経...
- CV2(OpenCV)は、コンピュータビジョンの...

AIを活用した言語学習アプリの構築:2つのAIチャットからの学習
新しい言語を学び始めるときは、私は「会話ダイアログ」の本を買うのが好きです私はそのような本が非常に役立つと思っていますそれらは、言語がどのように動作するかを理解するのに役立ちます単に…

新しいAIモデル、たった30BパラメーターでGPT-3を凌駕する
世界的に有名なオープンソース言語モデル(LLMs)プロバイダーであるMosaicMLは、最新世代のNVIDIA H100アクセラレータを搭載した画期的なMPT-30Bモデル、すなわちBase、Instruct、Chatを発表しました。これらの最新鋭モデルは、元のGPT-3に比べて品質が大幅に向上しています。 また読む: Large Language Models(LLMs)とは何ですか? MPT-7Bの前例のない成功とMPT-30Bへの進化 2023年5月のリリース以来、MPT-7Bモデルは、330万ダウンロードという驚異的な数字を叩き出し、業界を席巻しています。この成功を更に広げるため、MosaicMLは、非常に期待されていたMPT-30Bモデルをリリースしました。これにより、様々なアプリケーションで新しい可能性が開け、更なる高みに到達しました。 MPT-30Bの無比な機能 MPT-30Bの最も注目すべき成果の1つは、たった30億のパラメータで、GPT-3の175億のうちの一部を使用して、GPT-3を超える品質を実現することができたことです。この画期的なパラメータ数の削減により、MPT-30Bは、ローカルハードウェアの導入にもよりアクセスしやすくなり、推論のコストも大幅に削減されます。さらに、MPT-30Bをベースにしたカスタムモデルのトレーニングに関連する費用は、オリジナルのGPT-3をトレーニングする見積もりよりも明らかに低くなっており、企業にとって魅力的な選択肢となっています。 もっと詳しく知る:実際のユースケースに向けたGPT3の大規模言語モデルのカスタマイズ さらに、MPT-30Bのトレーニングには、最大8,000トークンの長いシーケンスが含まれており、データ重視のエンタープライズアプリケーションを処理できるようになっています。これは、NVIDIAのH100 GPUを利用して、優れたスループットと高速なトレーニング時間を実現しています。 また読む:中国の強力なNvidia AIチップの隠された市場 MPT-30Bの無限のアプリケーションを探る 多くのビジョンを持った企業が、MosaicMLのMPTモデルを活用し、AIアプリケーションを革新しています。 先進的なWebベースのIDEであるReplitは、MosaicMLのトレーニングプラットフォームを活用して、優れたコード生成モデルを構築することに成功しました。Replitは、独自のデータを活用することで、コードの品質、スピード、コスト効率を著しく向上させました。 チャットボットの開発に特化した革新的なAIスタートアップであるScatter Labは、MosaicMLの技術を活用して独自のMPTモデルをトレーニングしました。その結果、英語と韓国語の両方を理解できる多言語の生成AIモデルが作成され、広範なユーザーベースのチャット体験を大幅に向上させました。 世界的に有名な旅行費用管理ソフトウェア会社であるNavanは、MPTが提供する堅牢な基盤を活用して、バーチャルトラベルエージェントや会話型ビジネスインテリジェンスエージェントなどの最新アプリケーションにカスタマイズされたLLMsを開発しています。Navanの共同創設者兼CTOであるIlan Twig氏は、MosaicMLの基礎モデルが、際立った効率性とスケールでの推論を提供すると同時に、非常に優れた言語能力を提供していると熱狂的に称賛しています。 もっと詳しく知る:AIの力を活用するビジネスリーダーには、DataHack Summit…
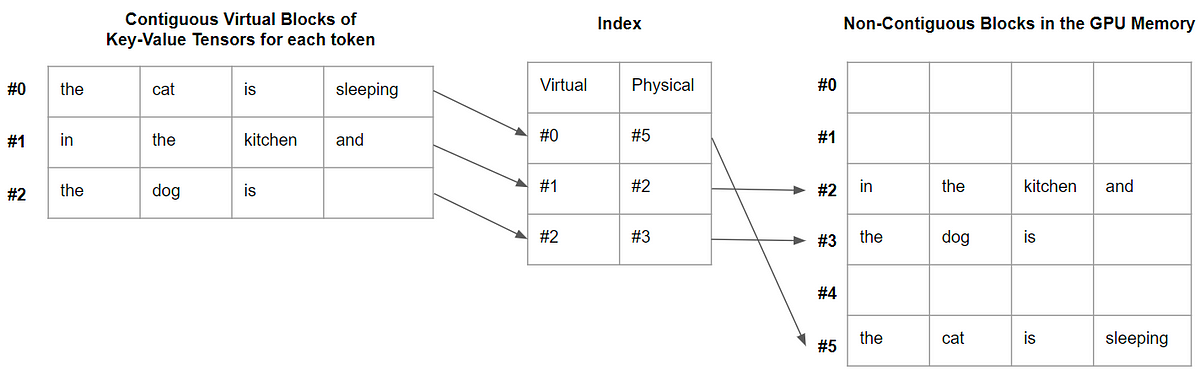
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します
チャットGPTの潜在能力を引き出すためのプロンプトエンジニアリングのマスタリング
プロンプトエンジニアリングは、ChatGPTやその他の大規模言語モデルのおかげで、風のように私たちの生活の一部にすぐになりました完全に新しい分野ではありませんが、現在...

Amazon SageMaker Data WranglerのSnowflakeへの直接接続でビジネスインサイトまでの時間を短縮してください
Amazon SageMaker Data Wranglerは、1つのビジュアルインターフェイスで、コードを書くことなく機械学習(ML)ワークフローでデータの選択とクリーニング、特徴量エンジニアリングの実行に必要な時間を週から分単位に短縮することができ、データの準備を自動化することができますSageMaker Data Wranglerは、人気のあるSnowflakeをサポートしています
Pythonの依存関係管理:どのツールを選ぶべきですか?
あなたのデータサイエンスプロジェクトが拡大するにつれて、依存関係の数も増えますプロジェクトの環境を再現可能かつメンテナンス可能に保つために、効率的な依存関係を使用することが重要です...

大規模言語モデルに関するより多くの無料コース
大規模言語モデルについて学びたいですか? DeepLearning.AI、Google Cloud、Udacityなどの無料のコースで、すぐに始めましょう

AIのダークサイドを明らかにする:プロンプトハッキングがあなたのAIシステムを妨害する方法
LLMsによるハッキングを防止し、データを保護するために、AIシステムを保護してくださいこの新興脅威に対するリスク、影響、予防策を学んでください

ChatGPTを使った効率的なデバッグ
大規模言語モデルの力を借りて、デバッグ体験を向上させ、より速く学習する
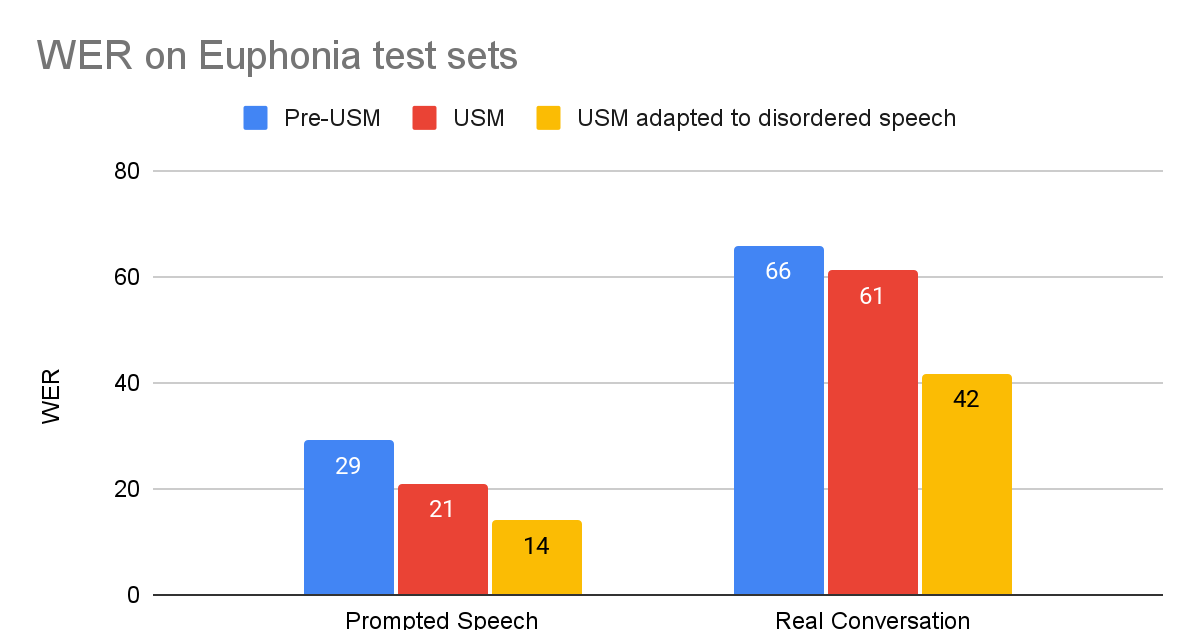
Google Researchにおける責任あるAI 社会的善のためのAI
Google Research、AI for Social GoodのソフトウェアエンジニアであるJimmy TobinとKatrin Tomanekが投稿しました。 GoogleのAI for Social Goodチームは、研究者、エンジニア、ボランティア、その他のメンバーが、ポジティブな社会的インパクトに焦点を合わせたチームです。私たちの使命は、公衆衛生、アクセシビリティ、危機対応、気候とエネルギー、自然と社会の各分野で、現実世界での価値を実現することによって、AIの社会的な利益を示すことです。私たちは、未開発なコミュニティに対してポジティブな変化をもたらす最良の方法は、変化をもたらす人々やその組織と協力することだと信じています。 このブログ記事では、AI for Social Good内のチームであるProject Euphoniaが行った作業について説明します。このチームは、障害のある人々のための自動音声認識(ASR)の改善を目的としています。通常の発話を持つ人々にとって、ASRモデルの単語エラー率(WER)は10%未満になることがありますが、吃音、失語症、失行症などの障害のある人々の場合、エチオロジーと重症度に応じてWERは50%または90%に達することがあります。この問題に対処するために、私たちは1,000人以上の参加者と協力して、1,000時間以上の障害のある音声サンプルを収集し、個人化されたASRが障害のある人々のパフォーマンスギャップを埋めるための実現可能な道であることを示しました。私たちは、レイヤー凍結技術を使用して、3〜4分のトレーニング音声で個人化が成功することを示しました。 この作業は、個人化された音声モデルを必要とする人々にとって有益であるProject Relateの開発につながりました。GoogleのSpeechチームと共同で構築されたProject Relateは、典型的な音声の理解が難しい人々が自分自身のモデルをトレーニングできるようにするものです。人々はこれらの個人化されたモデルを使用して、より効果的にコミュニケーションを取り、より独立した生活を送ることができます。ASRをよりアクセス可能で使いやすくするために、デジタルアシスタント技術、ディクテーションアプリ、および会話で使用するために、GoogleのUniversal Speech Model(USM)を調整する方法について説明します。 課題に対処する Project Relateのユーザーと緊密に連携して作業を行うことで、個人化されたモデルは非常に有用であることが明らかになりましたが、多くのユーザーにとって、数十または数百の例を記録することは困難です。さらに、個人化されたモデルは、自由形式の会話では常にうまく機能しなかったこともわかりました。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.