Learn more about Search Results リポジトリ - Page 80

- You may be interested
- 「中国AI研究チームが導入した4K4D ハード...
- 研究ライフサイクルの中心に倫理的な原則...
- K-平均クラスタリングのためのワンストッ...
- ChatGPTを忘れてください、この新しいAIア...
- HashGNN Neo4j GDSの新しいノード埋め込み...
- 「視覚化された実装と共に、Graph Attenti...
- 50以上の最新の最先端AIツール(2023年7月)
- ディープラーニングによる触媒性能の秘密...
- 「AIは個人の知識管理をどのように変革し...
- EUはAIの新しいルールを進めます
- 「人種は心臓病を予測するために使用でき...
- 「除細動器を搭載したドローンが命を救っ...
- 小さなメモリに大きな言語モデルを適合さ...
- 「LLMsを使用したEコマース製品検索の強化」
- 「openCypher* はどんなリレーショナルデ...

カカオブレインからの新しいViTとALIGNモデル
Kakao BrainとHugging Faceは、新しいオープンソースの画像テキストデータセットCOYO(700億ペア)と、それに基づいてトレーニングされた2つの新しいビジュアル言語モデル、ViTとALIGNをリリースすることを発表しました。ALIGNモデルが無料かつオープンソースで公開されるのは初めてであり、ViTとALIGNモデルのリリースにトレーニングデータセットが付属するのも初めてです。 Kakao BrainのViTとALIGNモデルは、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータに従っていますが、オープンソースのCOYOデータセットでトレーニングされています。GoogleのViTとALIGNモデルは、巨大なデータセット(ViTは3億枚の画像、ALIGNは18億の画像テキストペア)でトレーニングされていますが、データセットが公開されていないため、複製することはできません。この貢献は、データへのアクセスも含めて、視覚言語モデリングを再現したい研究者にとって特に価値があります。Kakao ViTとALIGNモデルの詳細な情報は、こちらで確認できます。 このブログでは、新しいCOYOデータセット、Kakao BrainのViTとALIGNモデル、およびそれらの使用方法について紹介します!以下が主なポイントです: 史上初のオープンソースのALIGNモデル! オープンソースのデータセットCOYOでトレーニングされた初のViTとALIGNモデル Kakao BrainのViTとALIGNモデルは、Googleのバージョンと同等のパフォーマンスを示します ViTとALIGNのデモはHFで利用可能です!選んだ画像サンプルでオンラインでViTとALIGNのデモを試すことができます! パフォーマンスの比較 Kakao BrainのリリースされたViTとALIGNモデルは、Googleが報告した内容と同等またはそれ以上のパフォーマンスを示します。Kakao BrainのALIGN-B7-Baseモデルは、トレーニングペアが少ない(700億ペア対18億ペア)にもかかわらず、Image KNN分類タスクではGoogleのALIGN-B7-Baseと同等のパフォーマンスを発揮し、MS-COCO検索の画像からテキスト、テキストから画像へのタスクではより優れた結果を示します。Kakao BrainのViT-L/16は、モデル解像度384および512でImageNetとImageNet-ReaLで評価された場合、GoogleのViT-L/16と同様のパフォーマンスを発揮します。つまり、コミュニティはKakao BrainのViTとALIGNモデルを使用して、特にトレーニングデータへのアクセスが必要な場合に、GoogleのViTとALIGNリリースを再現することができます。最先端の性能を発揮しつつ、オープンソースで透明性のあるこれらのモデルのリリースを見ることができるのはとても興奮します! COYOデータセット これらのモデルのリリースの特徴は、モデルが無料かつアクセス可能なCOYOデータセットでトレーニングされていることです。COYOは、GoogleのALIGN 1.8B画像テキストデータセットに似た700億ペアの画像テキストデータセットであり、ウェブページから取得した「ノイズのある」代替テキストと画像のペアのコレクションですが、オープンソースです。COYO-700MとALIGN 1.8Bは「ノイズのある」データセットですが、最小限のフィルタリングが適用されています。COYOは、他のオープンソースの画像テキストデータセットであるLAIONとは異なり、以下の点が異なります。…
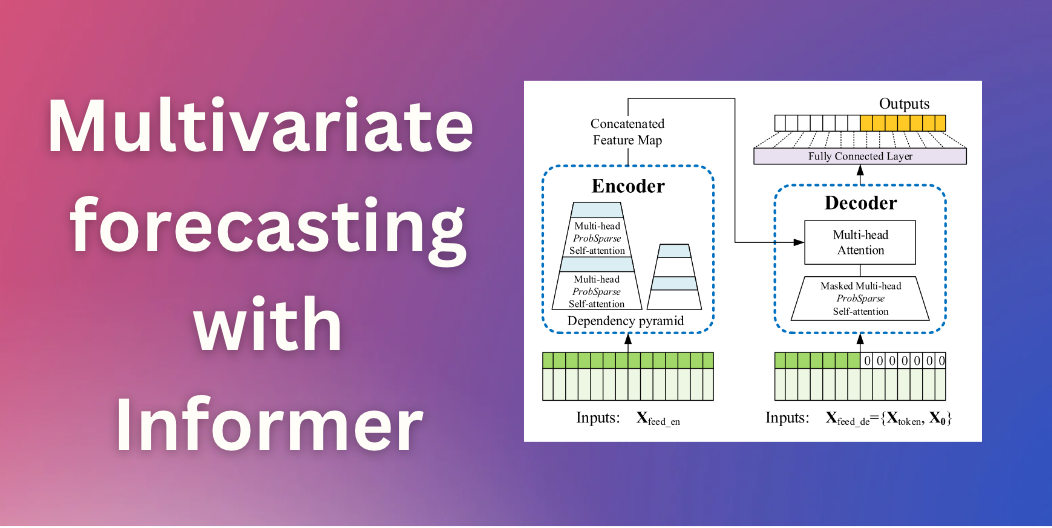
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

大規模言語モデルの高速推論:Habana Gaudi2アクセラレータ上のBLOOMZ
この記事では、🤗 Optimum Habanaを使用してHabana® Gaudi®2上のBLOOMのような数千億のパラメータを持つ大規模な言語モデルを簡単に展開する方法を紹介します。これは、この記事で示されたベンチマークに示されているように、市場で現在利用可能などのどのGPUよりも高速な推論を実行することを可能にします。 モデルがますます大きくなるにつれて、プロダクション環境に展開して推論を実行することはますます困難になっています。ハードウェアとソフトウェアの両方には、これらの課題に対処するための多くのイノベーションが見られますので、効率的にこれらの課題を克服する方法を見てみましょう! BLOOMZ BLOOMは、テキストのシーケンスを完了するためにトレーニングされた1760億のパラメータの自己回帰モデルです。46の異なる言語と13のプログラミング言語を扱うことができます。BigScienceイニシアチブの一環として設計され、トレーニングされたBLOOMは、世界中の多くの研究者とエンジニアが関わったオープンサイエンスプロジェクトです。最近では、同じアーキテクチャの別のモデルがリリースされました:BLOOMZは、BLOOMのいくつかのタスクで微調整されたバージョンであり、より良い汎化およびゼロショット[^1]の機能を持っています。 このような大規模なモデルは、トレーニングおよび推論の両方においてメモリと速度の新たな課題を提起します。16ビット精度でも、1インスタンスには352 GBのメモリが必要です!現時点では、そのような多くのメモリを持つデバイスはおそらく見つけることが難しいでしょうが、Habana Gaudi2のような最先端のハードウェアを使用すると、BLOOMとBLOOMZモデルで低い待ち時間で推論を実行することができます。 Habana Gaudi2 Gaudi2は、Habana Labsによって設計された第2世代のAIハードウェアアクセラレータです。1つのサーバーには8つのアクセラレータデバイス(Habana Processing UnitsまたはHPUsと呼ばれる)があり、それぞれ96GBのメモリを提供し、非常に大きなモデルを収める余地があります。ただし、モデルをホストするだけでは非常に興味深くありません。幸いにも、Gaudi2はその点で優れています:そのアーキテクチャは、アクセラレータが並列で一般行列乗算(GeMM)およびその他の操作を実行できるようにするため、深層学習ワークフローを高速化します。これらの特徴により、Gaudi2はLLMのトレーニングおよび推論の優れた候補となります。 HabanaのSDKであるSynapseAI™は、LLMトレーニングおよび推論を高速化するためにPyTorchとDeepSpeedをサポートしています。SynapseAIグラフコンパイラは、グラフに蓄積された操作の実行を最適化します(例:オペレータの統合、データレイアウトの管理、並列化、パイプライニングとメモリ管理、およびグラフレベルの最適化)。 さらに、HPUグラフとDeepSpeed-inferenceのサポートは、最近SynapseAIに導入され、以下のベンチマークに示すようにレイテンシに敏感なアプリケーションに適しています。 これらの機能は、🤗 Optimum Habanaライブラリに統合されており、Gaudiにモデルを展開することは非常に簡単です。こちらのクイックスタートページをご覧ください。 Gaudi2にアクセスしたい場合は、Intel Developer Cloudにアクセスし、このガイドに従ってください。…

倫理と社会のニュースレター#3:Hugging Faceにおける倫理的なオープンさ
ミッション:オープンで良い機械学習 私たちのミッションは、良い機械学習(ML)を民主化することです。MLコミュニティの活動を支援することで、潜在的な害の検証と予防も可能になります。オープンな開発と科学は、権力を分散させ、多くの人々が自分たちのニーズと価値観を反映したAIに共同で取り組むことができるようにします。オープンさは研究とAI全体に広範な視点を提供する一方で、リスクコントロールの少ない状況に直面します。 MLアーティファクトのモデレーションには、これらのシステムのダイナミックで急速に進化する性質による独自の課題があります。実際、MLモデルがより高度になり、ますます多様なコンテンツを生成する能力を持つようになると、有害なまたは意図しない出力の可能性も増大し、堅牢なモデレーションと評価戦略の開発が必要になります。さらに、MLモデルの複雑さと処理するデータの膨大さは、潜在的なバイアスや倫理的な懸念を特定し対処する課題を悪化させます。 ホストとして、私たちはユーザーや世界全体に対して潜在的な害を拡大する責任を認識しています。これらの害は、特定の文脈に依存して少数派コミュニティに不公平に影響を与えることが多いです。私たちは、各文脈でプレイしている緊張関係を分析し、会社とHugging Faceコミュニティ全体で議論するアプローチを取っています。多くのモデルが害を増幅する可能性がありますが、特に差別的なコンテンツを含む場合、最もリスクの高いモデルを特定し、どのような対策を取るべきかを判断するための一連の手順を踏んでいます。重要なのは、さまざまなバックグラウンドを持つアクティブな視点が、異なる人々のグループに影響を与える潜在的な害を理解し、測定し、緩和するために不可欠であるということです。 私たちは、オープンソースの科学が個人を力付け、潜在的な害を最小限に抑えるために、ツールや保護策を作成するとともに、ドキュメンテーションの実践を改善しています。 倫理的なカテゴリ 私たちの仕事の最初の重要な側面は、価値観とステークホルダーへの配慮を優先するML開発のツールとポジティブな例を促進することです。これにより、ユーザーは具体的な手順を踏むことで未解決の問題に対処し、ML開発の標準的な実践に代わる可能性のある選択肢を提示することができます。 ユーザーが倫理に関連するMLの取り組みを発見し、関わるために、私たちは一連のタグを編纂しました。これらの6つの高レベルのカテゴリは、コミュニティメンバーが貢献したスペースの分析に基づいています。これらは、倫理的な技術について無専門用語の方法で考えるための設計されています: 厳密な作業は、ベストプラクティスを考慮して開発することに特に注意を払います。MLでは、これは失敗事例の検証(バイアスや公正性の監査を含む)、セキュリティ対策によるプライバシーの保護、および潜在的なユーザー(技術的および非技術的なユーザー)がプロジェクトの制約について知らされることを意味します。 コンセントフルな作業は、これらの技術を使用し、影響を受ける人々の自己決定を支援します。 社会的に意識の高い作業は、技術が社会、環境、科学の取り組みを支援する方法を示しています。 持続可能な作業は、機械学習を生態学的に持続可能にするための技術を強調し、探求します。 包括的な作業は、機械学習の世界でビルドし、利益を享受する人々の範囲を広げます。 探求的な作業は、コミュニティに技術との関係を再考させる不公正さと権力構造に光を当てます。 詳細はhttps://huggingface.co/ethicsをご覧ください。 これらの用語を探してください。新しいプロジェクトで、コミュニティの貢献に基づいてこれらのタグを使用し、更新していきます! セーフガード オープンリリースを「全てか無し」の視点で見ることは、MLアーティファクトのポジティブまたはネガティブな影響を決定する広範な文脈の多様性を無視しています。MLシステムの共有と再利用の方法に対するより多くの制御レバーがあることで、有害な使用や誤用を促進するリスクを減らすことができ、共同開発と分析をサポートします。よりオープンでイノベーションに参加できる環境を提供します。 私たちは、直接貢献者と関わり、緊急の問題に対処してきました。さらに進めるために、私たちはコミュニティベースのプロセスを構築しています。このアプローチにより、Hugging Faceの貢献者と貢献に影響を受ける人々の両方が、プラットフォームで利用可能なモデルとデータに関して制限、共有、追加のメカニズムについて情報提供することができます。私たちは、アーティファクトの起源、開発者によるアーティファクトの取り扱い、アーティファクトの使用状況について特に注意を払います。具体的には、次のような取り組みを行っています: コミュニティがMLアーティファクトやコミュニティコンテンツ(モデル、データセット、スペース、または議論)がコンテンツガイドラインに違反しているかどうかを判断するためのフラッグ機能を導入しました。 ハブのユーザーが行動規範に従っているかを確認するために、コミュニティのディスカッションボードを監視しています。 最もダウンロードされたモデルについて、社会的な影響やバイアス、意図された使用法と範囲外の使用法を詳細に説明するモデルカードを堅牢に文書化しています。…

トランスフォーマーによるグラフ分類
前回のブログでは、グラフ上での機械学習の理論的な側面について調査しました。このブログでは、Transformersライブラリを使用してグラフ分類を行う方法について調査します(デモノートブックをここからダウンロードして一緒に進めることもできます!) 現時点では、Transformersで利用できる唯一のグラフトランスフォーマーモデルはMicrosoftのGraphormerですので、こちらを使用します。他のモデルも使用して統合する人々がどのような結果を出すか楽しみにしています 🤗 必要条件 このチュートリアルに従うためには、datasetsとtransformers(バージョン>= 4.27.2)がインストールされている必要があります。これはpip install -U datasets transformersで行うことができます。 データ グラフデータを使用するためには、独自のデータセットから始めるか、Hubで利用可能なデータセットを使用することができます。既に利用可能なデータセットを使用することに焦点を当てますが、自分のデータセットを追加することも自由です! 読み込み Hubからのグラフデータセットの読み込みは非常に簡単です。まず、ogbg-mohivデータセット(StanfordのOpen Graph Benchmarkのベースライン)をロードしましょう。これはOGBリポジトリに保存されています: from datasets import load_dataset # Hubには1つのスプリットしかありません dataset =…
AWS Inferentia2を使用してHugging Face Transformersを高速化する
過去5年間、Transformerモデル[1]は、自然言語処理(NLP)、コンピュータビジョン(CV)、音声など、多くの機械学習(ML)タスクのデファクトスタンダードとなりました。今日、多くのデータサイエンティストやMLエンジニアは、BERT[2]、RoBERTa[3]、Vision Transformer[4]などの人気のあるTransformerアーキテクチャ、またはHugging Faceハブで利用可能な130,000以上の事前学習済みモデルを使用して、最先端の精度で複雑なビジネス問題を解決するために頼っています。 しかし、その優れた性能にもかかわらず、Transformerは本番環境での展開には困難を伴うことがあります。モデル展開に通常関連するインフラストラクチャの設定に加えて、我々はInference Endpointsサービスで大部分の問題を解決しましたが、Transformerは通常、数ギガバイトを超える大きなモデルです。GPT-J-6B、Flan-T5、Opt-30Bなどの大規模言語モデル(LLM)は数十ギガバイトであり、BLOOMなどの巨大なモデルは350ギガバイトもあります。 これらのモデルを単一のアクセラレータに適合させることは非常に困難ですし、会話型アプリケーションや検索のようなアプリケーションが必要とする高スループットと低推論レイテンシを実現することはさらに難しいです。MLの専門家たちは、大規模モデルをスライスし、アクセラレータクラスタに分散させ、レイテンシを最適化するために複雑な手法を設計してきました。残念ながら、この作業は非常に困難で時間がかかり、多くのMLプラクティショナーには到底手の届かないものです。 Hugging Faceでは、MLの民主化を進めるとともに、すべての開発者と組織が最先端のモデルを利用できるようにすることを目指しています。そのため、今回はAmazon Web Servicesと提携し、Hugging Face TransformersをAWS Inferentia 2に最適化することに興奮しています!これは、前例のないスループット、レイテンシ、パフォーマンス、スケーラビリティを提供する新しい特別な推論アクセラレータです。 AWS Inferentia2の紹介 AWS Inferentia2は、2019年に発売されたInferentia1の次世代です。Inferentia1のパワーにより、Amazon EC2 Inf1インスタンスは、NVIDIA A10G GPUをベースとしたG5インスタンスと比較して、スループットが25%向上し、コストが70%削減されました。そして、Inferentia2により、AWSは再び限界を em>押し広げています。 新しいInferentia2チップは、Inferentiaと比較してスループットが4倍向上し、レイテンシが10倍低下します。同様に、新しいAmazon…

🤗 Transformersを使用してTensorFlowとTPUで言語モデルをトレーニングする
イントロダクション TPUトレーニングは有用なスキルです:TPUポッドは高性能で非常にスケーラブルであり、数千万から数百億のパラメータまで、どんなスケールでもモデルをトレーニングすることが容易です。GoogleのPaLMモデル(5000億パラメータ以上!)は完全にTPUポッドでトレーニングされました。 以前、TensorFlowを使用した小規模なTPUトレーニングと、TPUでモデルを動作させるために理解する必要がある基本的なコンセプトを紹介するチュートリアルとColabの例を作成しました。今回は、TensorFlowとTPUを使用してマスクされた言語モデルをゼロからトレーニングするためのすべての手順、トークナイザのトレーニングとデータセットの準備から最終的なモデルのトレーニングとアップロードまでを詳しく説明します。これはColabだけでなく、専用のTPUノード(またはVM)が必要なタスクであり、そこに焦点を当てます。 Colabの例と同様に、TensorFlowの非常にクリーンなTPUサポートであるXLAとTPUStrategyを活用しています。また、🤗 Transformers内のほとんどのTensorFlowモデルが完全にXLA互換であるという利点もあります。そのため、TPU上で実行するために必要な作業はほとんどありません。 ただし、この例はColabの例とは異なり、実際のトレーニングランに近いスケーラブルな例です。デフォルトではBERTサイズのモデルしか使用していませんが、いくつかの設定オプションを変更することで、コードをより大きなモデルとより強力なTPUポッドスライスに拡張することができます。 動機 なぜ今このガイドを書いているのでしょうか?実際、🤗 Transformersは何年もの間TensorFlowをサポートしてきましたが、これらのモデルをTPUでトレーニングすることはコミュニティにとって主要な問題でした。これは以下の理由によるものです: 多くのモデルがXLA互換ではなかった データコレクターがネイティブのTF操作を使用していなかった 私たちはXLAが将来の技術であると考えています。それはJAXのコアコンパイラであり、TensorFlowでの一流のサポートを受けており、PyTorchからも使用できます。そのため、私たちはコードベースをXLA互換にするために大きな取り組みを行い、XLAとTPUの互換性に立ちはだかるその他の障害を取り除きました。これにより、ユーザーは私たちのほとんどのTensorFlowモデルをTPUで煩わずにトレーニングできるはずです。 現在のLLM(言語モデル)と生成AIの最近の重要な進歩により、モデルのトレーニングに対する一般の関心が高まり、最新のGPUにアクセスすることが非常に困難になりました。TPUでのトレーニング方法を知っていると、超高性能な計算ハードウェアへのアクセスする別の方法を手に入れることができます。それは、eBayで最後のH100の入札戦に敗れてデスクで醜い泣きをするよりもずっと品位があります。あなたにはもっと良いものがふさわしいのです。そして経験から言えることですが、TPUでのトレーニングに慣れると、戻りたくなくなるかもしれません。 予想されること WikiTextデータセット(v1)を使用してRoBERTa(ベースモデル)をゼロからトレーニングします。モデルのトレーニングだけでなく、トークナイザをトレーニングし、データをトークン化してTFRecord形式でGoogle Cloud Storageにアップロードし、TPUトレーニングでアクセスできるようにします。コードはこのディレクトリにあります。ある種の人にとっては、このブログ投稿の残りをスキップして、コードに直接ジャンプすることもできます。ただし、しばらくお付き合いいただければ、コードベースのいくつかのキーポイントについて詳しく見ていきます。 ここで紹介するアイデアの多くは、私たちのColabの例でも触れられていましたが、それらをすべて組み合わせて実際に動作するフルエンドツーエンドの例をユーザーに示したかったのです。次の図は、🤗 Transformersを使用した言語モデルのトレーニングに関わる手順の概要を図解したものです。TensorFlowとTPUを使用しています。 データの取得とトークナイザのトレーニング 先述のように、WikiTextデータセット(v1)を使用しました。データセットの詳細については、Hugging Face Hubのデータセットページにアクセスして調べることができます。 データセットは既に互換性のある形式でHubに利用可能なので、🤗 datasetsを使用して簡単にロードして操作することができます。ただし、この例ではトークナイザをゼロから学習しているため、以下のような手順を踏んでいます:…

フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
要約:Google Colabの無料ティア上で最も強力なオープンソースのテキストから画像への変換モデルIFを実行する方法を紹介します。 また、Hugging Face Spaceでモデルの機能を直接探索することもできます。 公式のIF GitHubリポジトリから圧縮された画像。 はじめに IFは、ピクセルベースのテキストから画像への生成モデルで、DeepFloydによって2023年4月下旬にリリースされました。モデルのアーキテクチャは、GoogleのクローズドソースのImagenに強く影響を受けています。 IFは、Stable Diffusionなどの既存のテキストから画像へのモデルと比較して、次の2つの利点があります: モデルは、レイテントスペースではなく「ピクセルスペース」(つまり、非圧縮画像上で)で直接動作し、Stable Diffusionのようなノイズ除去プロセスを実行しません。 モデルは、Stable Diffusionでテキストエンコーダとして使用されるCLIPよりも強力なテキストエンコーダであるT5-XXLの出力で訓練されます。 その結果、IFは高周波の詳細(例:人の顔や手など)を持つ画像を生成する能力に優れており、信頼性のあるテキスト付き画像を生成できる最初のオープンソースの画像生成モデルです。 ピクセルスペースで動作し、より強力なテキストエンコーダを使用することのデメリットは、IFが大幅に多くのパラメータを持っていることです。T5、IFのテキストから画像へのUNet、IFのアップスケーラUNetは、それぞれ4.5B、4.3B、1.2Bのパラメータを持っています。それに対して、Stable Diffusion 2.1のテキストエンコーダとUNetは、それぞれ400Mと900Mのパラメータしか持っていません。 しかし、メモリ使用量を低減させるためにモデルを最適化すれば、一般のハードウェア上でもIFを実行することができます。このブログ記事では、🧨ディフューザを使用してその方法を紹介します。 1.)では、テキストから画像への生成にIFを使用する方法を説明し、2.)と3.)では、IFの画像バリエーションと画像インペインティングの機能について説明します。 💡 注意:メモリの利得と引き換えに速度の利得を得るために、IFを無料ティアのGoogle Colab上で実行できるようにしています。A100などの高性能なGPUにアクセスできる場合は、公式のIFデモのようにすべてのモデルコンポーネントをGPU上に残して、最大の速度で実行することをお勧めします。…
Hugging Face Unity APIのインストールと使用方法
Hugging Face Unity APIは、Hugging Face Inference APIの簡単に使用できる統合です。これにより、開発者はUnityプロジェクトでHugging Face AIモデルにアクセスして使用することができます。このブログ投稿では、Hugging Face Unity APIのインストールと使用方法について説明します。 インストール Unityプロジェクトを開きます Window -> Package Managerに移動します +をクリックし、Add Package from git URLを選択します https://github.com/huggingface/unity-api.gitを入力します…

テキストからビデオへのモデルの深掘り
ModelScopeで生成されたビデオサンプルです。 テキストからビデオへの変換は、生成モデルの驚くべき進歩の長いリストの中で次に来るものです。その名前の通り、テキストからビデオへの変換は、時間的にも空間的にも一貫性のある画像のシーケンスをテキストの説明から生成する、比較的新しいコンピュータビジョンのタスクです。このタスクは、テキストから画像への変換と非常によく似ているように思えるかもしれませんが、実際にははるかに難しいものです。これらのモデルはどのように動作し、テキストから画像のモデルとはどのように異なり、どのようなパフォーマンスが期待できるのでしょうか? このブログ記事では、テキストからビデオモデルの過去、現在、そして未来について論じます。まず、テキストからビデオとテキストから画像のタスクの違いを見直し、条件付きと非条件付きのビデオ生成の独特の課題について話し合います。さらに、テキストからビデオモデルの最新の開発について取り上げ、これらの方法がどのように機能し、どのような能力があるのかを探ります。最後に、Hugging Faceで取り組んでいるこれらのモデルの統合と使用を容易にするための取り組みや、Hugging Face Hub内外でのクールなデモやリソースについて話します。 さまざまなテキストの説明を入力として生成されたビデオの例、Make-a-Videoより。 テキストからビデオ対テキストから画像 最近の開発が非常に多岐にわたるため、テキストから画像の生成モデルの現在の状況を把握することは困難かもしれません。まずは簡単に振り返りましょう。 わずか2年前、最初のオープンボキャブラリ、高品質なテキストから画像の生成モデルが登場しました。VQGAN-CLIP、XMC-GAN、GauGAN2などの最初のテキストから画像のモデルは、すべてGANアーキテクチャを採用していました。これらに続いて、2021年初めにOpenAIの非常に人気のあるトランスフォーマーベースのDALL-E、2022年4月のDALL-E 2、Stable DiffusionとImagenによって牽引された新しい拡散モデルの新たな波が続きました。Stable Diffusionの大成功により、DreamStudioやRunwayML GEN-1などの多くの製品化された拡散モデルや、Midjourneyなどの既存製品との統合が実現しました。 テキストから画像生成における拡散モデルの印象的な機能にもかかわらず、拡散および非拡散ベースのテキストからビデオモデルは、生成能力においてはるかに制約があります。テキストからビデオは通常、非常に短いクリップで訓練されるため、長いビデオを生成するためには計算コストの高いスライディングウィンドウアプローチが必要です。そのため、これらのモデルは展開とスケーリングが困難であり、文脈と長さに制約があります。 テキストからビデオのタスクは、さまざまな面で独自の課題に直面しています。これらの主な課題のいくつかには以下があります: 計算上の課題:フレーム間の空間的および時間的な一貫性を確保することは、長期的な依存関係を伴い、高い計算コストを伴います。そのため、このようなモデルを訓練することは、ほとんどの研究者にとって手の届かないものです。 高品質なデータセットの不足:テキストからビデオの生成のためのマルチモーダルなデータセットは希少で、しばしばスパースに注釈が付けられているため、複雑な動きのセマンティクスを学ぶのが難しいです。 ビデオのキャプションに関する曖昧さ:モデルが学習しやすいようにビデオを記述する方法は未解決の問題です。完全なビデオの説明を提供するためには、複数の短いテキストプロンプトが必要です。生成されたビデオは、時間の経過に沿って何が起こるかを物語る一連のプロンプトやストーリーに基づいて条件付ける必要があります。 次のセクションでは、テキストからビデオへの進展のタイムラインと、これらの課題に対処するために提案されたさまざまな手法について別々に議論します。高レベルでは、テキストからビデオの作業では以下のいずれかを提案しています: 学習しやすいより高品質なデータセットの作成。 テキストとビデオのペアデータなしでこのようなモデルを訓練する方法。 より計算効率の良い方法で長く、高解像度のビデオを生成する方法。 テキストからビデオを生成する方法…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.