Learn more about Search Results A - Page 809

- You may be interested
- 革新的な製造プロセスへの3Dインサイト
- 「AIデータ統合とコンテンツベースのマッ...
- マシンラーニングの革命:光フォトニック...
- ミッドジャーニーV5:ミッドジャーニーの...
- LangChainによるAIの変革:テキストデータ...
- 「Cheetorと会ってください:幅広い種類の...
- ディープラーニングのマスタリング:分岐...
- データサイエンティストのためのAI Chrome...
- AIパワーを活用した機会の開放-イギリス
- 「エンジニアリングは永遠に変わりました」
- SCD(Slowly Changing Dimensions)を理解...
- 「50以上の新しい最先端の人工知能(AI)...
- 「力強いコネクティビティ:IoTにおけるエ...
- 「Chroma DBガイド | 生成AI LLMのための...
- 次回のLLM(法務修士)の申請に使用するた...

インタラクティブな知能の模倣
最初に、仮想のロボットが移動したり物体を操作したりお互いに話したりすることができる興味深いさまざまな相互作用が行えるシミュレートされた環境であるプレイルームを作成しますプレイルームの寸法はランダム化され、棚、家具、窓やドアのようなランドマーク、子供のおもちゃや日常の物体の配置もランダム化されます環境の多様性により、空間や物体の関係についての推論、参照の曖昧さ、包含性、構築、サポート、遮蔽、部分的な可視性などを含む相互作用が可能となりますプレイルームには2つのエージェントが埋め込まれ、共同意図、協力、プライベートな知識の伝達などを研究するための社会的な要素を提供します

MuZero ルールなしでGo、チェス、将棋、アタリをマスターする
2016年、我々はAlphaGoという初めて人間を囲碁で打ち負かすことのできる人工知能(AI)プログラムを紹介しました2年後、その後継者であるAlphaZeroは、ゼロから囲碁、チェス、将棋をマスターするために学習しましたそして今、学術誌Natureに掲載された論文で、我々はMuZeroを紹介していますこれは汎用アルゴリズムの追求において重要な進展ですMuZeroは、未知の環境で勝利戦略を計画する能力により、ルールを教えられることなく囲碁、チェス、将棋、アタリをマスターします

データ、アーキテクチャ、または損失:マルチモーダルトランスフォーマーの成功に最も貢献する要素は何ですか?
この研究では、マルチモーダルトランスフォーマーの成功において、注意機構、損失関数、事前学習データといった要素が重要であるかどうかを検証します私たちは、言語と画像のトランスフォーマーが互いに注意を払うマルチモーダルな注意機構が、これらのモデルの成功に重要であることを発見しました他の種類の注意機構を持つモデル(深さやパラメーターが増えていても)は、マルチモーダルな注意機構を持つ浅くて小さいモデルと比較して同等の結果を達成することができません

大規模データ分析のエンジンとしてのゲーム理論
現代のAIシステムは、画像内のオブジェクトを認識したり、タンパク質の3D構造を予測したりするタスクに取り組む際、熱心な学生が試験の準備をするようなアプローチを取ります多くの例題に基づいてトレーニングを行うことで、彼らは時間とともにミスを最小限に抑え、成功を達成しますしかし、これは孤独な取り組みであり、既知の学習の形態の一つに過ぎません学習はまた、他の人々との相互作用や遊びによっても行われます非常に複雑な問題を一人で解決できる個人は稀です問題解決をゲームのような特性で行うことにより、以前のDeepMindの取り組みではAIエージェントがCapture the Flagをプレイしたり、Starcraftでグランドマスターレベルを達成したりすることが可能になりましたこれは、ゲーム理論に基づいたこのような視点が他の基本的な機械学習の問題を解決するのに役立つのではないかと考えさせられます

私たちの人種的正義の取り組みについての最新情報
2020年6月、アメリカのミネアポリスでジョージ・フロイドが殺害され、世界中で数百万人が声を上げてブラック・ライブズ・マターの抗議活動に連帯した後、私は他の多くの人々と同様に、この状況について考え、弊社がどのように貢献できるかを反省しましたその後、DeepMindが人種差別と人種的公正に取り組む意図についていくつかの考えを共有しました
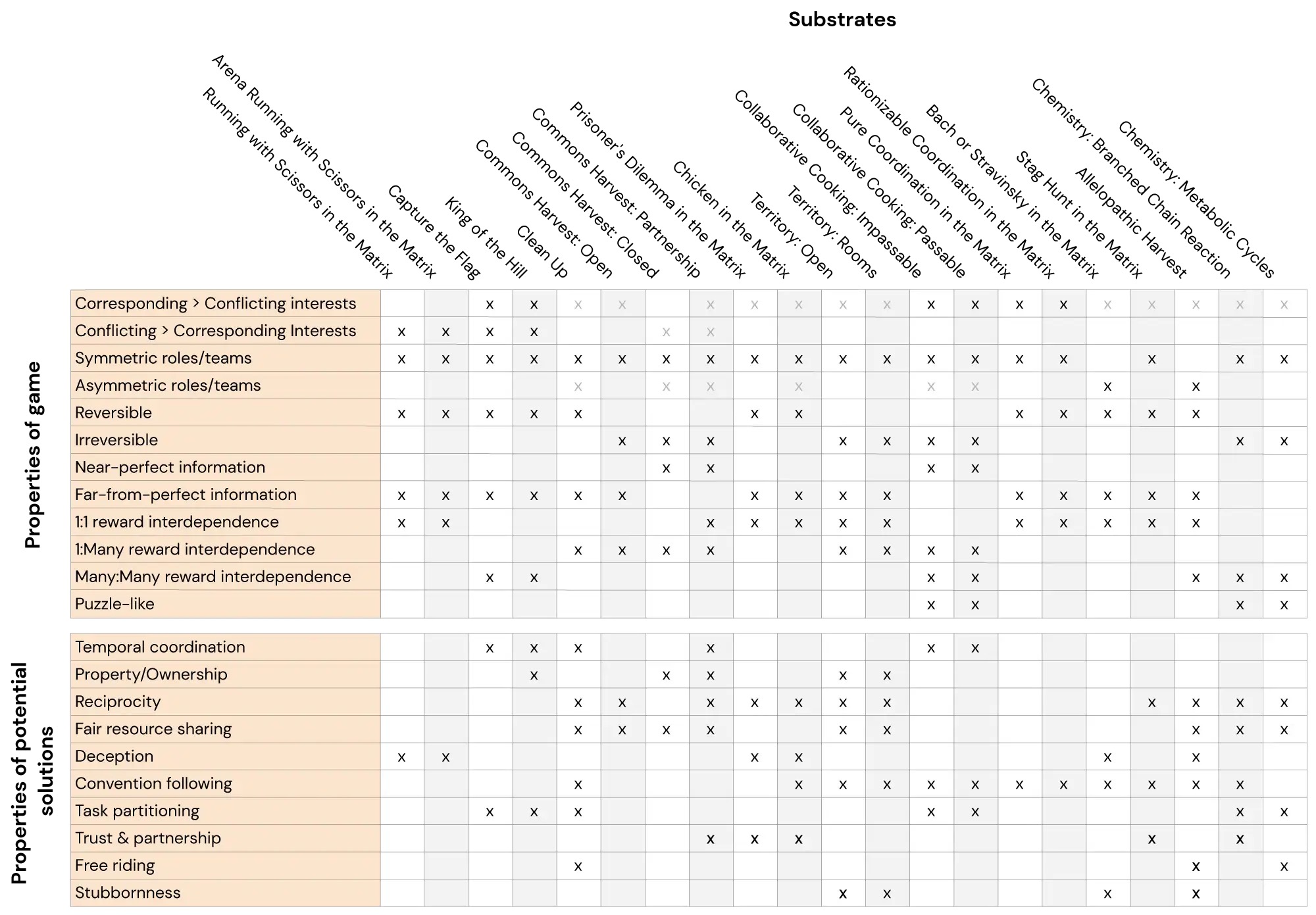
メルティングポット:マルチエージェント強化学習の評価スイート
ここでは、スケーラブルなマルチエージェント強化学習の評価スイートであるMelting Potを紹介しますMelting Potは、既知の個体と未知の個体の両方を含む新しい社会的状況への一般化を評価し、協力、競争、欺瞞、報復、信頼、頑固さなど、さまざまな社会的相互作用をテストするために設計されていますMelting Potは、研究者に21のMARL「基板」(マルチエージェントゲーム)でエージェントを訓練する機会を提供し、これらの訓練されたエージェントを評価するために85以上のユニークなテストシナリオを提供します
.jpg)
プロテオームスケールでの高精度なタンパク質構造予測を可能にする
多くの新しい機械学習のイノベーションがAlphaFoldの現在の精度に貢献しています以下にシステムの概要を高レベルで示しますネットワークアーキテクチャの技術的な説明については、私たちのAlphaFoldのメソッド論文と特に詳細な補足情報をご覧ください

アルファフォールドの力を世界の手に
昨年12月にAlphaFold 2を発表した際、それは50年間のタンパク質折りたたみ問題の解決策として称賛されました先週、私たちはこの非常に革新的なシステムを作成する方法についての科学論文とソースコードを公開しましたそして、本日は人体のすべてのタンパク質の形状に関する高品質な予測を共有していますさらに、科学者が研究に頼る20の追加の生物のタンパク質の形状についても予測を行っています

一般的に、オープンエンドの遊びから優れたエージェントが生まれる
近年、人工知能エージェントは複雑なゲーム環境で成功を収めています例えば、AlphaZeroは、プレイ方法の基本ルールを知らないままスタートし、チェス、将棋、囲碁の世界チャンピオンプログラムに勝利しました強化学習(RL)を通じて、この単一のシステムは、試行錯誤の反復的なプロセスを通じて、ゲームのラウンドごとにプレイすることで学習しましたしかし、AlphaZeroはまだ各ゲームごとに別々にトレーニングを行いましたRLのプロセスをゼロから繰り返さなければ、別のゲームやタスクを単純に学習することはできませんでしたAtari、Capture the Flag、StarCraft II、Dota 2、Hide-and-Seekなど、RLの他の成功も同様ですDeepMindの使命である科学と人類の進歩のための知能の解決策を見つけるために、私たちはこの制限を克服する方法を探求しました一度に1つのゲームを学習する代わりに、これらのエージェントは完全に新しい条件に反応し、見たこともないゲームやタスクを含む、さまざまなゲームやタスクをプレイできるようになるはずです

世界のデータを処理できるアーキテクチャの構築
今日のAIシステムで使用されるほとんどのアーキテクチャは、専門的なものです2Dの残差ネットワークは画像処理には適していますが、自動運転車で使用されるLidar信号やロボット工学で使用されるトルクなどの他の種類のデータには最適な選択肢ではありませんさらに、標準的なアーキテクチャは通常、1つのタスクのみを考慮して設計されており、エンジニアはしばしば入出力を再構築、歪曲、または他の方法で変更する必要がありますこれによって標準的なアーキテクチャが問題を正しく処理できるように期待します音声や画像など、複数の種類のデータを扱う場合はさらに複雑であり、単純なタスクでも多くの異なる部品から構成される複雑で手動チューニングされたシステムが必要になることが通常ですDeepMindの使命である科学と人類の進歩のために知能を解決するために、私たちは多くの種類の入力と出力を使用する問題を解決できるシステムを構築したいと考え、あらゆる種類のデータを処理できるより一般的かつ柔軟なアーキテクチャを探求し始めました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.