Learn more about Search Results A - Page 805

- You may be interested
- プリンストン大学の研究者が、MeZOという...
- VoAGIニュース、8月30日:Generative AIで...
- 創造力を解き放つ:ジェネレーティブAIとA...
- 「ChatGPTがクラッシュしましたか? OpenA...
- 「2023年のトップコンピュータビジョンツ...
- 「Surfer SEO レビュー:最高のAI SEO ツ...
- 2v2ゲームのためのデータ駆動型Eloレーテ...
- メタは、プライバシー侵害のチェックに関...
- Q&A:ブラジルの政治、アマゾンの人権...
- チャットGPTの潜在能力を引き出すためのプ...
- ボイジャーAGIニュース、10月11日:仕事を...
- OpenAIはGPT-4 Turboを搭載した次世代AIの...
- 「プログラマーの生産性を10倍にするため...
- サイバーエキスパートたちは、2024年の米...
- 「MATLABとAmazon SageMakerによる機械学習」

基礎モデルは人間のようにデータにラベルを付けることができますか?
ChatGPTの登場以来、Large Language Models(LLM)の開発に前例のない成長が見られ、特にプロンプト形式の指示に従うように微調整されたチャットモデルの開発が増えてきました。しかし、これらのモデルの比較は、その性能を厳密にテストするために設計されたベンチマークの不足により明確ではありません。指示とチャットモデルの評価は本質的に困難であり、ユーザーの好みの大部分は質的なスタイルに集約されていますが、過去のNLP評価ははるかに定義されていました。 このような状況で、新しい大規模言語モデル(LLM)が「モデルはChatGPTに対してN%の時間で優先される」という調子でリリースされるのはよくあることですが、その文から省かれているのは、そのモデルがGPT-4ベースの評価スキームで優先されるという事実です。これらのポイントが示そうとしているのは、異なる測定の代理となるものです:人間のラベラーが提供するスコア。人間のフィードバックから強化学習でモデルを訓練するプロセス(RLHF)は、2つのモデル補完を比較するためのインターフェースとデータを増やしました。このデータはRLHFプロセスで使用され、優先されるテキストを予測する報酬モデルを訓練するために使用されますが、モデルの出力を評価するための評価とランキングのアイデアは、より一般的なツールとなっています。 ここでは、ブラインドテストセットのinstructとcode-instructの分割それぞれからの例を示します。 反復速度の観点では、言語モデルを使用してモデルの出力を評価することは非常に効率的ですが、重要な要素が欠けています:下流のツールショートカットが元の測定形式と整合しているかどうかを調査することです。このブログ投稿では、オープンLLMリーダーボード評価スイートを拡張することで、選択したLLMから得られるデータラベルを信頼できるかどうかを詳しく調べます。 LLMSYS、nomic / GPT4Allなどのリーダーボードが登場し始めましたが、モデルの能力を比較するための完全なソースが必要です。一部のモデルは、既存のNLPベンチマークを使用して質問応答の能力を示すことができ、一部はオープンエンドのチャットからのランキングをクラウドソーシングしています。より一般的な評価の全体像を提示するために、Hugging Face Open LLMリーダーボードは、自動化された学術ベンチマーク、プロの人間のラベル、およびGPT-4の評価を含むように拡張されました。 目次 オープンソースモデルの評価 関連研究 GPT-4評価の例 さらなる実験 まとめとディスカッション リソースと引用 オープンソースモデルの評価 ヒトがデータをキュレートする必要があるトレーニングプロセスのどのポイントでもコストがかかります。これまでに、AnthropicのHHHデータ、OpenAssistantの対話ランキング、またはOpenAIのLearning to Summarize /…

はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
イントロダクション 数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。 まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。 さあ、始めましょう! ベンチマーキング – Transformers vs. DLinear 最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。 上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。 次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。 要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。 Autoformer…
ビジネス戦略において機械学習を使用する時と使用しない時の選択
それは明らかな質問ではありません初心者のデータサイエンティストにとっては、すぐに機械学習モデルを推進することは間違いです実際には、よりシンプルなルールベースのソリューションの方が効率的で実装が容易です...

私たちの新しいコンテンツガイドラインとポリシーをお知らせします
当社は、オープンで協力的かつ責任ある機械学習の推進を目指すコミュニティ主導のプラットフォームとして、私たちのコミュニティ全体に対して歓迎の場を維持しサポートすることを喜んでいます!この目標をサポートするために、私たちはコンテンツポリシーを更新しました。 完全なドキュメントに精通することをお勧めします。その間、このブログポストでは、私たちのコンテンツポリシーの更新の背景、理論の概要、および価値観について概説します。両方のリソースを参照することで、当社プラットフォームのコンテンツに対する期待と目標を包括的に理解することができます。 機械学習コンテンツのモデレーション 機械学習アーティファクトのモデレーションには新たな課題が生じます。静的なコンテンツよりも、人工知能システムやモデルの開発・展開に関連するリスクは、潜在的な損害を予測するために詳細な分析と包括的なアプローチが必要です。そのため、この新しいコンテンツポリシーの起草には、私たちの異なるメンバーや専門家からの努力が集約され、責任ある開発と展開をどのように実現するかについて明確化するために、全社的な視点と詳細な情報が必要とされています。 さらに、AIと機械学習の分野が拡大するにつれ、ユースケースとアプリケーションの多様性も増えています。これにより、最新の研究、倫理的考慮事項、ベストプラクティスについて常に最新情報にアップデートする必要があります。そのため、ユーザーの協力を促進することも、当社プラットフォームの持続可能性にとって重要です。具体的には、コミュニティタブなどのコミュニティ機能を通じて、リポジトリの著者、ユーザー、組織、および私たちのチームの間での協力的なソリューションを奨励・促進しています。 同意を基本とする価値観 機械学習システムの開発と使用において、人々の権利を尊重することを優先するため、技術と法律の進展に対応する前向きな視点を持ちます。機械学習によって可能になる情報処理の新たな方法は、AIの分野や規制の範囲で、人々の作業、イメージ、プライバシーに関する権利について全く新しい問題を提起しています。これらの議論の中心にあるのは、人々の権利をどのように具体化すべきかという点です。私たちはここで一つのアプローチを提供しています。 この変化し続ける法的状況の中で、害を引き起こすことを避けるために「同意」の本質的な価値を強調することがますます重要になっています。それにより、個人の主体性と主観的な経験に焦点を当てることができます。このアプローチは、同意に対する先見性とより共感的な理解をサポートするだけでなく、文化的および文脈的要素に対処するための積極的な措置を奨励します。特に、私たちのコンテンツポリシーは、ユーザーが見るコンテンツ、人々のアイデンティティと表現に関連する同意に対処することを目指しています。 このプラットフォームでの人々の同意と経験に対する配慮は、コミュニティコンテンツやユーザーの行動にも及びます。安全で歓迎する環境を維持するために、ユーザーやHugging Faceスタッフに対して攻撃的または嫌がらせの言葉を許容しません。ユーザーとリポジトリの著者の間の潜在的な紛争に対しては、必要な場合にのみ介入し、協力的な解決策の促進に重点を置いています。透明性を促進するために、私たちはコミュニティタブ内での公開討論を奨励しています。 私たちのアプローチは、私たちのユーザーの貴重な意見によって可能になり、改善を常に追求することを約束しています。ご質問やご心配事がある場合は、[email protected]までお問い合わせください。 オープンなAIとMLの協力を奨励する、友好的で支援的なコミュニティを築くために力を合わせましょう!皆さんとともに、誰もが歓迎される環境で大きな進歩を遂げることができます。

Open LLMのリーダーボードはどうなっていますか?
最近、Falcon 🦅のリリースおよびOpen LLM Leaderboardへの追加に関して、Twitter上で興味深い議論が起こりました。Open LLM Leaderboardは、オープンアクセスの大規模言語モデルを比較する公開のリーダーボードです。 この議論は、リーダーボードに表示されている4つの評価のうちの1つであるMassive Multitask Language Understanding(略称:MMLU)のベンチマークを中心に展開されました。 コミュニティは、リーダーボードの現在のトップモデルであるLLaMAモデル 🦙のMMLU評価値が、公開されたLLaMa論文の値よりも著しく低いことに驚きました。 そのため、私たちは何が起こっているのか、そしてそれを修正する方法を理解するために深堀りしました 🕳🐇 私たちとのこの冒険の旅において、私たちはLLaMAの評価に協力した素晴らしい@javier-m氏、そしてFalconチームの素晴らしい@slippylolo氏と話し合いました。もちろん、以下のエラーは彼らではなく、私たちに帰すべきです! この冒険の旅の中で、オンラインや論文で見る数値を信じるべきかどうか、モデルを単一の評価で評価する方法について多くのことを学ぶことができます。 準備はいいですか?それでは、シートベルトを締めましょう、出発します 🚀。 Open LLM Leaderboardとは何ですか? まず、Open LLM Leaderboardは、実際にはEleutherAI非営利AI研究所によって作成されたオープンソースのベンチマークライブラリEleuther…

倫理と社会ニュースレター#4:テキストから画像へのモデルにおけるバイアス
要約: テキストから画像へのモデルのバイアスを評価するためにより良い方法が必要です はじめに テキストから画像(TTI)生成は最近のトレンドであり、数千のTTIモデルがHugging Face Hubにアップロードされています。各モダリティは異なるバイアスの影響を受ける可能性がありますが、これらのモデルのバイアスをどのように明らかにするのでしょうか?このブログ投稿では、TTIシステムのバイアスの源泉、それらに対処するためのツールと潜在的な解決策について、私たち自身のプロジェクトと広範なコミュニティのものを紹介します。 画像生成における価値観とバイアスのエンコード バイアスと価値観には非常に密接な関係があります。特に、これらが与えられたテキストから画像モデルのトレーニングやクエリに埋め込まれている場合、この現象は生成された画像に大きな影響を与えます。この関係は、広範なAI研究分野で知られており、それに対処するためのかなりの努力が進行中ですが、特定のモデルで進化する人々の価値観を表現しようとする複雑さは依然として存在しています。これは、適切に明らかにし、対処するための持続的な倫理的な課題を提起します。 たとえば、トレーニングデータが主に英語である場合、それはおそらく西洋の価値観を伝えています。その結果、異なる文化や遠い文化のステレオタイプな表現が得られます。以下の例では、同じプロンプト「北京の家」に対してERNIE ViLG(左)とStable Diffusion v 2.1(右)の結果を比較すると、この現象が顕著に現れます: バイアスの源泉 近年、自然言語処理(Abidら、2021年)およびコンピュータビジョン(BuolamwiniおよびGebru、2018年)の両方の単一モダリティのAIシステムにおけるバイアス検出に関する重要な研究が行われています。MLモデルは人々によって構築されるため、すべてのMLモデル(そして技術全般)にはバイアスが存在します。これは、画像の中で特定の視覚的特性が過剰または過少に表現される(たとえば、オフィスワーカーのすべての画像にネクタイがある)ことや、文化的および地理的なステレオタイプの存在(たとえば、白いドレスとベールを着た花嫁のすべての画像、代表的な花嫁のイメージである赤いサリーの花嫁など)が現れることで現れます。AIシステムは広く異なるセクターやツール(例:Firefly、Shutterstock)に展開される社会技術的なコンテキストで展開されるため、既存の社会的なバイアスや不平等を強化する可能性があります。以下にバイアスの源泉の非徹底的なリストを示します: トレーニングデータのバイアス:テキストから画像への変換のための人気のあるマルチモーダルデータセット(たとえば、テキストから画像へのLAION-5B、画像キャプショニングのMS-COCO、ビジュアルクエスチョンアンサリングのVQA v2.0など)には、多数のバイアスや有害な関連が含まれていることが判明しています(Zhaoら、2017年、PrabhuおよびBirhane、2021年、Hirotaら、2022年)。これらのデータセットでトレーニングされたモデルには、画像生成の多様性の欠如や、文化やアイデンティティグループの共通のステレオタイプが永続化するという初期の結果がHugging Face Stable Biasプロジェクトから示されています。たとえば、CEO(右)とマネージャー(左)のDall-E 2の生成結果を比較すると、両方とも多様性に欠けていることがわかります: 事前トレーニングデータのフィルタリングにおけるバイアス:モデルのトレーニングに使用される前に、データセットに対して何らかの形のフィルタリングが行われることがよくあります。これにより、異なるバイアスが導入されます。たとえば、Dall-E 2の作者たちは、トレーニングデータのフィルタリングが実際にバイアスを増幅することを発見しました。これは、既存のデータセットが女性をより性的な文脈で表現するというバイアスや、使用されるフィルタリング手法の固有のバイアスに起因する可能性があると彼らは仮説を立てています。 推論におけるバイアス:Stable…
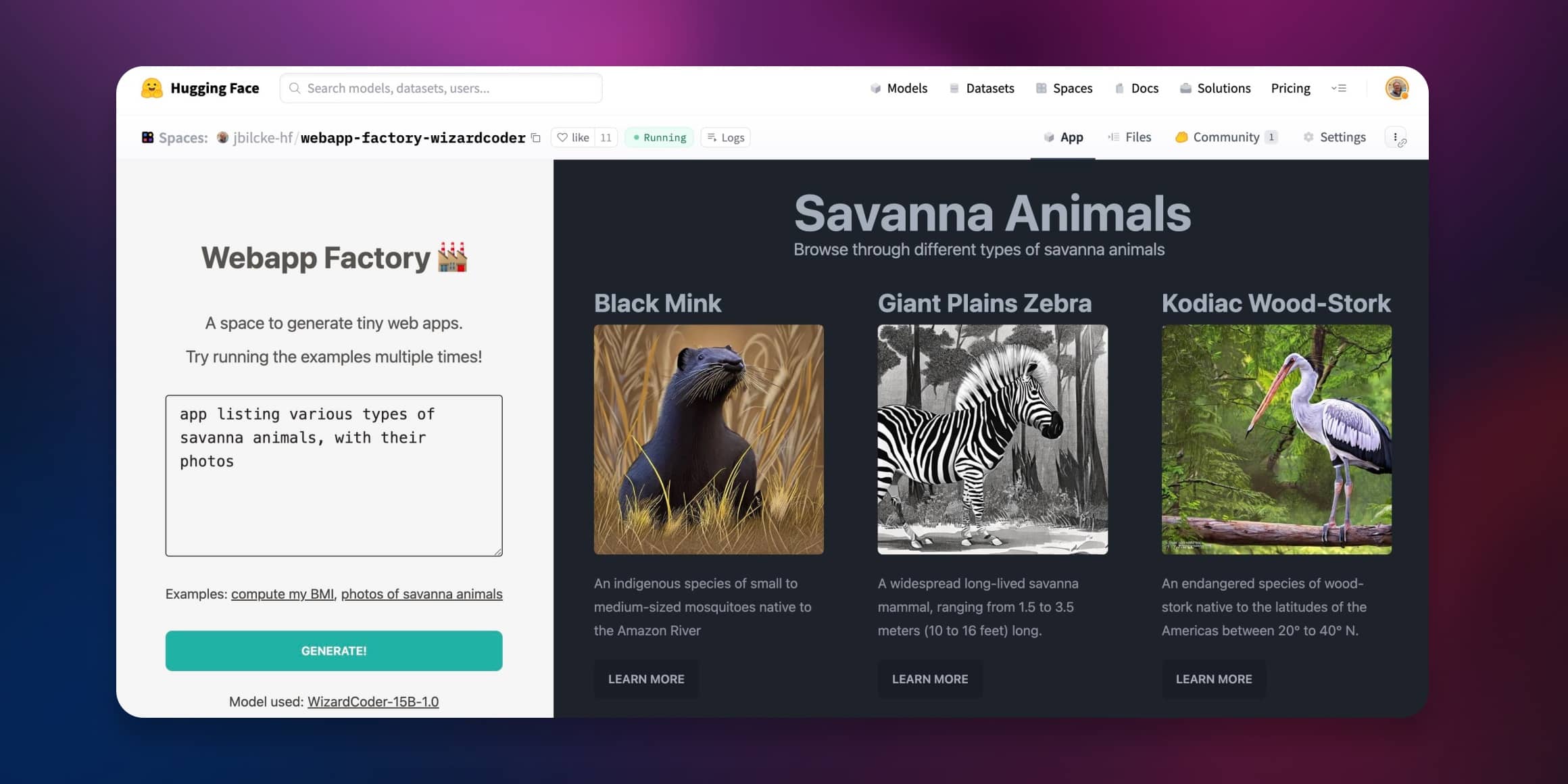
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…

チューリングテスト、中国の部屋、そして大規模言語モデル
チューリングテストは、AIの分野での古典的なアイデアですもともとは模倣ゲームと呼ばれ、アラン・チューリングは1950年に自身の論文「計算機械と知性」でこのテストを提案しましたこのテストの目標は...

SQLクエリにおいてGPT-4よりも優れたもの:NSQL(完全なオープンソース)
ChatGPTや他のLLM(Language Model)を使用してSQLクエリを生成しようとしたことがある方は手を挙げてください私は試してみましたし、現在も試しています!しかし、新しいオープンソースのファミリーが登場したことをお伝えできるのがとても嬉しいです...
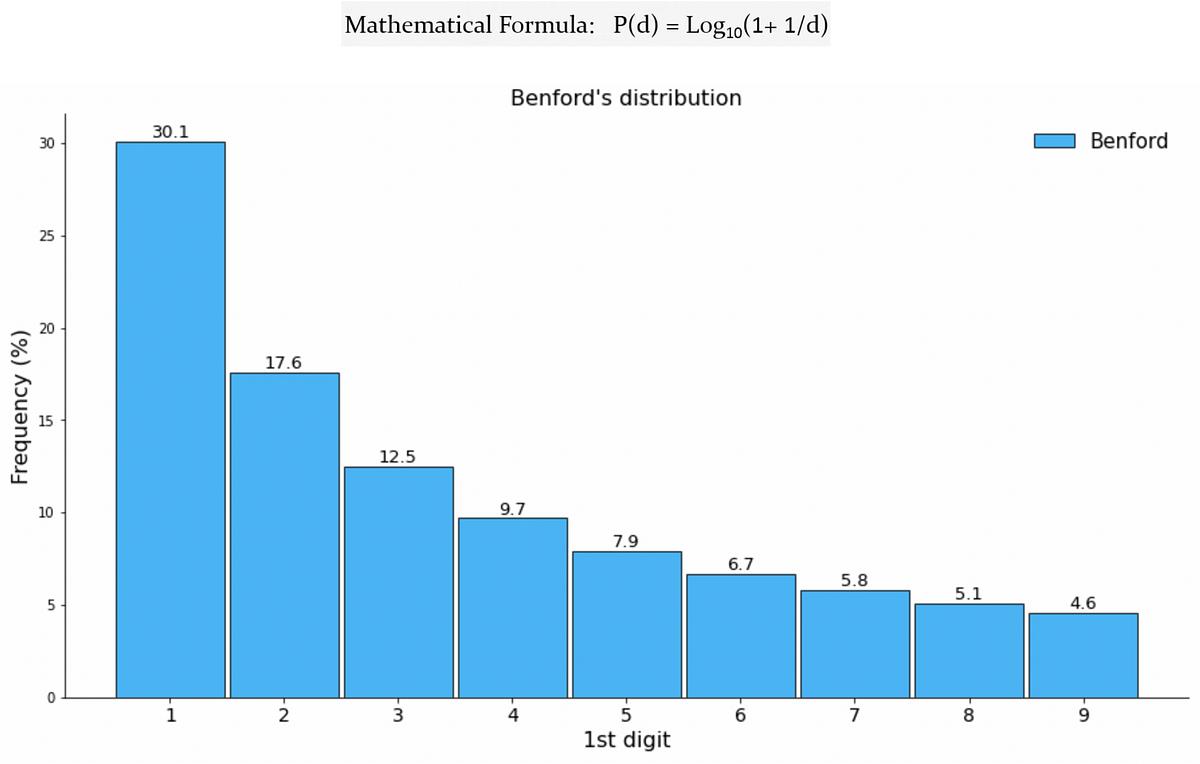
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.