Learn more about Search Results A - Page 801

- You may be interested
- 6つのGenAIポッドキャスト、聴くべきです
- 新しいOpenAIのGPTsサービスが小規模ビジ...
- メタAIのもう一つの革命的な大規模モデル ...
- 「AIと働き方の未来:AI時代における労働...
- 機械学習システムにおけるデータ品質の維持
- 「ExcelでのPython 高度なデータ分析への...
- 「DevOpsとDataOpsとの私の経験」
- 「Pythonにおけるパスの表現」
- 「プリズマーに会いましょう:専門家のア...
- 「大規模言語モデルは本当にそのすべての...
- 「イギリス、ロシアが数年にわたり議員や...
- 欧州連合と日本、AIと半導体の戦略的な協...
- 「AIデザインスタジオ、OpenAIによってグ...
- 時間を遡ってみよう:AIが古代ローマのな...
- 生成AIと予測AI:違いは何ですか?

🤗評価による言語モデルのバイアスの評価
大規模な言語モデルのサイズと能力は過去数年間で大幅に向上していますが、これらのモデルとそのトレーニングデータに刻み込まれたバイアスへの懸念も同様に高まっています。実際、多くの人気のある言語モデルは特定の宗教や性別に対してバイアスがあることが判明しており、これによって差別的な考えの促進やマージナライズドグループへの害の持続が引き起こされる可能性があります。 コミュニティがこのようなバイアスを探索し、言語モデルがエンコードする社会的な問題に対する理解を強化するために、私たちはバイアスのメトリクスと測定値を🤗 Evaluate ライブラリに追加する作業を行ってきました。このブログ投稿では、新しい機能のいくつかの例とその使用方法について紹介します。GPT-2 や BLOOM のような因果言語モデル (CLMs) の評価に重点を置き、プロンプトに基づいた自由なテキストの生成能力を活かします。 実際に作業を見るには、作成した Jupyter ノートブックをチェックしてください! ワークフローには次の2つの主要なステップがあります: あらかじめ定義された一連のプロンプトを言語モデルに提示する(🤗 データセットでホストされている) メトリクスや測定値を使用して生成物を評価する(🤗 Evaluate を使用) 有害な言語に焦点を当てた3つのプロンプトベースのタスクでバイアスの評価を進めましょう:有害性、極性、および害悪性。ここで紹介する作業は、Hugging Face ライブラリを使用してバイアスの分析にどのように活用するかを示すものであり、使用される特定のプロンプトベースのデータセットには依存しません。重要なことは、最近導入されたバイアスの評価用データセットがモデルが生み出す様々なバイアスを捉えていない初歩的なステップであるということです(詳細については以下の議論セクションを参照してください)。 有害性 実世界のコンテキストで CLM…

🤗 Optimum IntelとOpenVINOでモデルを高速化しましょう
昨年7月、インテルとHugging Faceは、Transformerモデルのための最新かつシンプルなハードウェアアクセラレーションツールの開発で協力することを発表しました。本日、私たちはOptimum IntelにIntel OpenVINOを追加したことをお知らせできて非常に嬉しく思います。これにより、Hugging FaceハブまたはローカルにホストされるTransformerモデルを使用して、様々なIntelプロセッサ上でOpenVINOランタイムによる推論を簡単に実行できます(サポートされているデバイスの完全なリストを参照)。OpenVINOニューラルネットワーク圧縮フレームワーク(NNCF)を使用してモデルを量子化し、サイズと予測レイテンシをわずか数分で削減することもできます。 この最初のリリースはOpenVINO 2022.2をベースにしており、私たちのOVModelsを使用して、多くのPyTorchモデルに対する推論を実現しています。事後トレーニング静的量子化と量子化感知トレーニングは、多くのエンコーダモデル(BERT、DistilBERTなど)に適用することができます。今後のOpenVINOリリースでさらに多くのエンコーダモデルがサポートされる予定です。現在、エンコーダデコーダモデルの量子化は有効化されていませんが、次のOpenVINOリリースの統合により、この制限は解除されるはずです。 では、数分で始める方法をご紹介します! Optimum IntelとOpenVINOを使用してVision Transformerを量子化する この例では、食品101データセットでイメージ分類のためにファインチューニングされたVision Transformer(ViT)モデルに対して事後トレーニング静的量子化を実行します。 量子化は、モデルパラメータのビット幅を減らすことによってメモリと計算要件を低下させるプロセスです。ビット数を減らすことで、推論時に必要なメモリが少なくなり、行列乗算などの演算が整数演算によって高速に実行できるようになります。 まず、仮想環境を作成し、すべての依存関係をインストールしましょう。 virtualenv openvino source openvino/bin/activate pip install pip --upgrade pip…

新しい価格設定をご紹介します
ご注意いただいたかもしれませんが、最近、当社の料金ページは大幅に変更されています。 まず、Inference APIサービスの有料ティアを廃止します。Inference APIは引き続き誰でも無料で利用できます。ただし、高速でエンタープライズグレードの推論サービスをお探しの場合は、新しいソリューションである「Inference Endpoints」をご覧ください。 Inference Endpointsに加えて、Spaces向けのハードウェアアップグレードを最近導入しました。これにより、お好きなハードウェアでMLデモを実行することができます。これらのサービスの利用にはサブスクリプションは必要ありませんが、請求設定からアカウントにクレジットカードを追加する必要があります。また、組織に対して支払い方法を関連付けることもできます。 請求設定では、有料サービスに関するすべてを一元管理できます。そこから、個人のPROサブスクリプションを管理したり、支払い方法を更新したり、過去3ヶ月間の利用状況を可視化したりすることができます。有料サービスとサブスクリプションの利用料金は毎月の開始時に請求され、記録用の統合請求書が利用可能です。 要約: HFでは、AIのための計算への簡単なアクセスを提供することで収益化しています。AutoTrain、Spaces、Inference Endpointsなどのサービスは、Hubから直接アクセスできます。料金体系について詳しくは、当社の価格と請求システムについてのページをご覧ください。 ご質問があれば、お気軽にお問い合わせください。フィードバックを歓迎します🔥
トランスフォーマーにおける対比的探索を用いた人間レベルのテキスト生成 🤗
1. 紹介: 自然言語生成(テキスト生成)は自然言語処理(NLP)の中核的なタスクの一つです。このブログでは、現在の最先端のデコーディング手法であるコントラスティブサーチを神経テキスト生成のために紹介します。コントラスティブサーチは、元々「A Contrastive Framework for Neural Text Generation」[1]([論文] [公式実装])でNeurIPS 2022で提案されました。さらに、この続編の「Contrastive Search Is What You Need For Neural Text Generation」[2]([論文] [公式実装])では、コントラスティブサーチがオフザシェルフの言語モデルを使用して16の言語で人間レベルのテキストを生成できることが示されています。 [備考] テキスト生成に馴染みのないユーザーは、このブログ記事を詳しくご覧ください。 2.…

ホモモーフィック暗号化による暗号化データの感情分析
感情分析モデルは、テキストがポジティブ、ネガティブ、または中立であるかを判断することが広く知られています。しかし、このプロセスには通常、暗号化されていないテキストへのアクセスが必要であり、プライバシー上の懸念が生じる可能性があります。 ホモモーフィック暗号化は、復号化することなく暗号化されたデータ上で計算を行うことができる暗号化の一種です。これにより、ユーザーの個人情報や潜在的に機密性の高いデータがリスクにさらされるアプリケーションに適しています(例:プライベートメッセージの感情分析)。 このブログ投稿では、Concrete-MLライブラリを使用して、データサイエンティストが暗号化されたデータ上で機械学習モデルを使用することができるようにしています。事前の暗号学の知識は必要ありません。暗号化されたデータ上で感情分析モデルを構築するための実践的なチュートリアルを提供しています。 この投稿では以下の内容をカバーしています: トランスフォーマー トランスフォーマーをXGBoostと組み合わせて感情分析を実行する方法 トレーニング方法 Concrete-MLを使用して予測を暗号化されたデータ上の予測に変換する方法 クライアント/サーバープロトコルを使用してクラウドにデプロイする方法 最後に、この機能を実際に使用するためのHugging Face Spaces上の完全なデモで締めくくります。 環境のセットアップ まず、次のコマンドを実行してpipとsetuptoolsが最新であることを確認します: pip install -U pip setuptools 次に、次のコマンドでこのブログに必要なすべてのライブラリをインストールします。 pip install concrete-ml transformers…

機械学習洞察のディレクター【パート4】
MLソリューションをより速く構築したい場合は、今すぐ hf.co/support をご覧ください! 👋 ML Insightsシリーズのディレクターへお帰りなさい!以前のエディションを見逃した場合は、こちらで見つけることができます: ディレクター・オブ・マシン・ラーニング・インサイト[パート1] ディレクター・オブ・マシン・ラーニング・インサイト[パート2:SaaSエディション] ディレクター・オブ・マシン・ラーニング・インサイト[パート3:金融エディション] 🚀 この第4弾では、次のトップマシン・ラーニング・ディレクターがそれぞれの業界へのマシン・ラーニングの影響について語ります:ハビエル・マンシージャ、ショーン・ギットンズ、サミュエル・フランクリン、エヴァン・キャッスル。全員が現在、豊富なフィールドの洞察を持つマシン・ラーニングのディレクターです。 免責事項:すべての意見は個人の意見であり、過去または現在の雇用者の意見ではありません。 ハビエル・マンシージャ – マーケティングサイエンス部門のマシン・ラーニングディレクター、メルカドリブレ 経歴:経験豊富な起業家でありリーダーであるハビエルは、2010年以来マシン・ラーニングを構築する高級企業であるMachinalisの共同設立者兼CTOでした(そう、ニューラルネットの突破前の時代です)。 MachinalisがMercado Libreに買収されたとき、その小さなチームは10,000人以上の開発者を持つテックジャイアントにマシン・ラーニングを可能にする能力として進化し、ほぼ1億人の直接ユーザーの生活に影響を与えました。ハビエルは、彼らのマシン・ラーニングプラットフォーム(NASDAQ MELI)の技術と製品のロードマップだけでなく、ユーザーのトラッキングシステム、ABテストフレームワーク、オープンソースオフィスもリードしています。ハビエルはPython-Argentinaの非営利団体PyArの積極的なメンバーおよび貢献者であり、家族や友人、Python、サイクリング、サッカー、大工仕事、そしてゆっくりとした自然の休暇が大好きです! おもしろい事実:私はSF小説を読むのが大好きで、引退後は短編小説を書くという10代の夢を再開する予定です。📚 メルカドリブレ:ラテンアメリカ最大の企業であり、コンチネンタルのeコマース&フィンテックの普遍的なソリューションです 1. eコマースにおいてMLがポジティブな影響を与えたのはどのような場合ですか? 詐欺防止や最適化されたプロセスやフローなど、特定のケースにおいてMLは不可能を可能にしたと言えます。他のほとんどの分野では想像もできなかった方法で、MLがUXの次のレベルを実現しました。…

拡散モデルライブイベント
嬉しいお知らせです!Hugging FaceとJonathan WhitakerとのDiffusion Models Classが11月28日に公開されます🥳!この無料のコースでは、ディープラーニングの今年の最もエキサイティングな進展の一つである拡散モデルの理論と応用について学ぶことができます。もし拡散モデルについて初めて聞いた方は、以下のデモでその可能性を実感してください: この公開に合わせて、11月30日にライブコミュニティイベントを開催します。あなたも参加することができます!プログラムには、Stable Diffusionのクリエイター、Stability AIとMetaの研究者など、興奮するトークが含まれています! 参加登録は、このフォームからお願いします。スピーカーやトークの詳細は以下で提供されています。 ライブトーク トークは、拡散モデルの高レベルなプレゼンテーションと、それらを使ってアプリケーションを構築するためのツールに焦点を当てます。

インターンを募集しています!
AIの中でも、–と自負してもいいくらい–最もクールな場所の一つで未来を一緒に築きたいですか?2023年のインターンシッププログラムを発表します。ハギングフェイスのメンターと協力して、AIと機械学習の最先端の問題に取り組みます。 バックグラウンドを問わず、応募者を歓迎します!理想的には、いくつかの関連する経験があり、責任ある機械学習の民主化の使命に興奮しています。私たちの分野の進歩は、既存の格差を不均衡に悪化させる可能性があります。それが、社会の最も弱者である人々、特に有色人種、労働階級の出身者、女性、LGBTQ+の人々に不利な影響を与えることがあります。これらのコミュニティは、私たちの研究コミュニティが行う仕事の中心に置かれなければなりません。したがって、これらのアイデンティティを反映した個人の経験を持つ人々からの提案を強く推奨します! ポジション 次のインターンシップのポジションがオープンソースチームで利用可能です。それぞれのライブラリのメンテナと一緒に働きます: Accelerate Internship,ライブラリに新しく影響力のある機能を統合するためのリーダーシップポジション。 Text to Speech Internship,テキストから音声再生に取り組むポジション。 次の科学チームのポジションが利用可能です: Embodied AI Internship,シミュレータでの強化学習に取り組むEmbodied AIチームとの協力ポジション。 Fast Distributed Training Framework Internship,大規模言語モデルの柔軟な分散トレーニングのためのフレームワークを作成するポジション。 Datasets for LLMs Internship,次世代の大規模言語モデルと関連ツールのトレーニングデータセットを作成するポジション。…
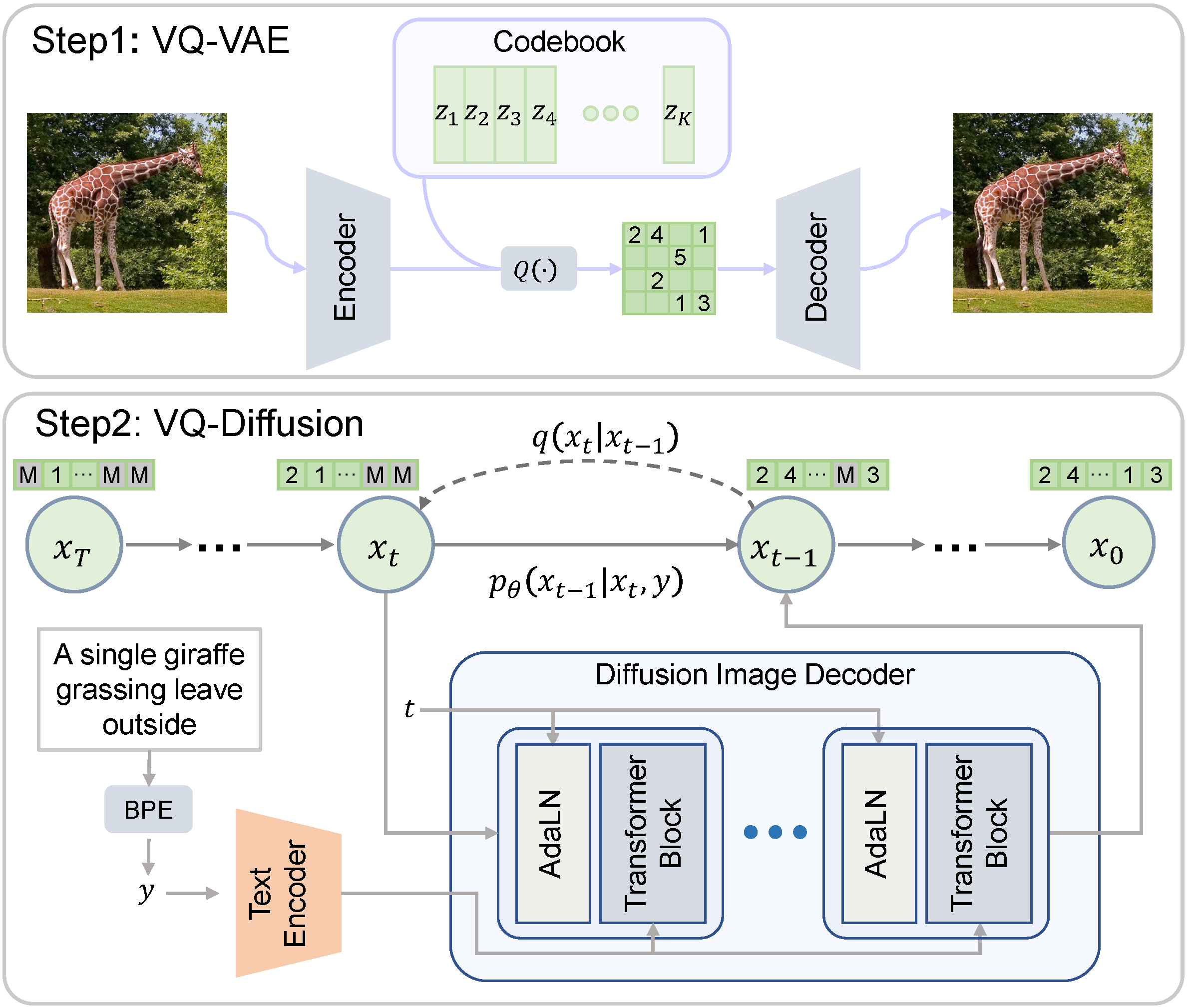
VQ-Diffusion
ベクトル量子化拡散(VQ-Diffusion)は、中国科学技術大学とMicrosoftによって開発された条件付き潜在拡散モデルです。一般的に研究されている拡散モデルとは異なり、VQ-Diffusionのノイジングとデノイジングのプロセスは量子化された潜在空間で動作します。つまり、潜在空間は離散的なベクトルの集合で構成されています。離散的な拡散モデルは、連続的な対応物と比較する興味深い比較対象を提供します。 Hugging Faceモデルカード Hugging Face Spaces オリジナルの実装 論文 デモ 🧨 Diffusersを使用すると、わずか数行のコードでVQ-Diffusionを実行できます。 依存関係をインストールする pip install 'diffusers[torch]' transformers ftfy パイプラインをロードする from diffusers import VQDiffusionPipeline pipe =…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.