Learn more about Search Results A - Page 800

- You may be interested
- レオナルド・ダ・ヴィンチ:天才の心の内部
- 水中探査の革命:ブラウン大学のプリオボ...
- 「10 個の最高の AI スケジューリングアシ...
- 「トランスフォーマーベースのエンコーダ...
- 「ディープラーニングの解説:ニューラル...
- 「AutoGPTQとtransformersを使ってLLMsを...
- 『AIが人類を置き換える可能性』
- Acme 分散強化学習のための新しいフレーム...
- このAI研究は、高品質なビデオ生成のため...
- 「透明なセンサーが視線追跡を目に見えな...
- スポティファイはAIを取り入れる:個人に...
- Hugging FaceとFlowerを使用したフェデレ...
- 「AIを活用したツールにより、3Dプリント...
- テキサス大学の研究者たちは、機械学習を...
- 「PyTorch入門 – 最初の線形モデル...

最初のデシジョン トランスフォーマーをトレーニングする
以前の投稿で、transformersライブラリでのDecision Transformersのローンチを発表しました。この新しい技術は、Transformerを意思決定モデルとして使用するというもので、ますます人気が高まっています。 今日は、ゼロからオフラインのDecision Transformerモデルをトレーニングして、ハーフチータを走らせる方法を学びます。このトレーニングは、Google Colab上で直接行います。こちらで見つけることができます👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb *ジムのHalfCheetah環境でオフラインRLを使用して学習された「専門家」Decision Transformersモデルです。 ワクワクしませんか?では、始めましょう! Decision Transformersとは何ですか? Decision Transformersのトレーニング データセットの読み込みとカスタムデータコレータの構築 🤗 transformers Trainerを使用したDecision Transformerモデルのトレーニング 結論 次は何ですか? 参考文献 Decision Transformersとは何ですか? Decision…

ディフューザーの新着情報は何ですか?🎨
1か月半前に、モダリティを横断する拡散モデルのためのモジュールツールボックスを提供するdiffusersライブラリをリリースしました。数週間後には、高品質なテキストから画像への変換モデルであるStable Diffusionのサポートを追加し、誰でも無料のデモを試すことができるようにしました。最後の3週間では、チームはライブラリに1つまたは2つの新機能を追加することを決定しました。このブログ投稿では、diffusersバージョン0.3の新機能について概説します!GitHubリポジトリに⭐を付けるのを忘れないでください。 画像から画像へのパイプライン テキストの逆転 インペインティング より小さなGPUに最適化 Mac上で実行 ONNXエクスポーター 新しいドキュメント コミュニティ SD潜在空間での動画生成 モデルの説明可能性 日本語のStable Diffusion 高品質なファインチューニングモデル Stable Diffusionによるクロスアテンション制御 再利用可能なシード 画像から画像へのパイプライン 最も要望の多かった機能の1つは、画像から画像の生成を行うことです。このパイプラインでは、画像とプロンプトを入力すると、それに基づいて画像が生成されます! 公式のColabノートブックに基づいたコードを見てみましょう。 from diffusers import…

倫理と社会のニュースレター#1
Hello, world! オープンソース企業として創業したHugging Faceは、技術におけるいくつかの重要な倫理的価値、すなわち協力、責任、透明性に基づいて設立されました。オープンな環境でコードを記述することは、自分のコードとその選択肢が世界に公開され、他の人が批判や追加を行うために利用可能であることを意味します。Hugging Face Hubをホストとしてモデルやデータを提供するようになると、リサーチコミュニティは再現性を直接統合し、それを会社の基本的な価値としました。そして、Hugging Faceに存在するデータセットやモデルの数が増えるにつれ、Hugging Faceのメンバーは、リサーチコミュニティによって定義された新たな価値に対応するために、ドキュメントの要件や無料の指導コースを導入しました。これにより、技術の進歩につながる数学、コード、プロセス、人々の理解を含む、監査可能性の価値が追加されました。 AIにおける倫理をどのように実施するかは、オープンな研究領域です。応用倫理と人工知能に関する学問や理論は数十年前から存在していましたが、AI開発における倫理の実践とテストされた手法は、過去10年間にわずかに現れ始めたに過ぎません。これは、AIシステムの構築ブロックである機械学習モデルが、それらの進歩を測定するために使用されてきた基準を超えたため、機械学習システムが日常生活に影響を与える実用的なアプリケーションの範囲で広範に採用されたためです。倫理に基づくAIの進歩に興味を持つ私たちのうちの何人かは、倫理的な原則に基づいて設立された機械学習企業に参加することは、成長が始まり、世界中の人々が倫理的なAIの問題に取り組み始めるときに、将来のAIがどのようになるかを根本的に形作る機会です。これは、倫理を念頭に置いて最初から設立されたテクノロジー企業がどのように見えるのかという、新しい形の現代のAIの実験です。機械学習に倫理の視点を当てるとは、良い機械学習を民主化するとはどういうことでしょうか。 このため、私たちは新しいHugging Face Ethics and Societyニュースレターで最近の考え方と取り組みを共有しています。このニュースレターは、春分点と夏至点に毎シーズン発行されます。これは、私たちHugging Faceの「倫理と社会の専門家」というオープンなグループが一緒になって機械学習の広範な社会的文脈やHugging Faceの役割に取り組むために作成されました。私たちは、会社全体が価値に基づいた意思決定を行うためには、専門チームではなく、共有の責任とコミットメントが必要であると考えています。私たちの仕事の倫理的なリスクを認識し、学ぶために、すべての関係者が責任を共有することが重要です。 私たちは、現在のところ「良い」機械学習の意味について継続的に研究しており、それを定義するための基準を提供しようとしています。これは進行中のプロセスであり、現在の日常生活に影響を与える機械学習コミュニティの異なる価値観と調和する点に到達するために、現在の日常生活で可能な限り何ができるかを見据えています。私たちは、Hugging Faceの創業の原則に基づいてこのアプローチを展開しています。 私たちはオープンソースコミュニティと協力することを目指しています。これには、ドキュメンテーションと評価のための現代化されたツール、コミュニティディスカッション、Discord、さらには異なる価値観に基づいて自分の作業を共有するための貢献者への個別サポートが含まれます。 私たちは、自分たちの考え方やプロセスを透明にすることを目指しています。プロジェクトの開始時に特定のプロジェクト価値についての執筆を共有し、AIポリシーについての考え方も共有しています。また、この作業に対するコミュニティからのフィードバックも学ぶためのリソースとして得ています。 私たちは、現在と将来の影響に対する責任を負いながら、これらのツールとアーティファクトの作成を基盤としています。この優先順位付けにより、機械学習システムをより監査可能で理解可能にするプロジェクト設計が実現しました。これには、ML以外の専門知識を持つ人々にも適した教育プロジェクトやコーディング不要のMLデータ分析ツールなどが含まれます。 これらの基本から出発し、私たちは、プロジェクトごとの特定の文脈と予測される影響に重点を置いた価値観の実施方法を取っています。したがって、ここではグローバルな価値観や原則の一覧を提供することはありません。その代わり、このニュースレターなど、プロジェクトごとの考え方を引き続き共有し、理解が進むにつれてさらに共有する予定です。異なる価値観と影響を受ける人々を特定するために、コミュニティのディスカッションが重要であると考えているため、Hugging Face Hubにオンラインで接続できる人は誰でも直接モデル、データ、およびスペースに関するフィードバックを提供できる機会を最近提供しました。オープンなディスカッションのツールと並行して、包括的なコミュニティスペースのための行動規範とコンテンツガイドラインを作成しました。セキュアなML開発のためのプライベートHub、モデルを厳密に評価するための評価ライブラリ、スキューとバイアスを分析するためのデータ解析のためのコード、モデルのトレーニング時の炭素排出量を追跡するためのツールを開発しています。また、倫理的および法的な問題について報告するためにモデルとスペースのリポジトリを「フラグ」とすることも可能にしました。…
SetFit プロンプトなしで効率的なフューショット学習
SetFitは、通常のファインチューニングよりもサンプル効率が高く、ノイズに強いです。 事前学習済みの言語モデルを用いたフューショット学習は、データサイエンティストの悪夢であるほとんどラベルのないデータを扱うための有望な解決策として浮上しています 😱。 Intel LabsとUKP Labとの共同研究を通じて、Hugging FaceはSetFitを紹介できることを嬉しく思っています。SetFitは、Sentence Transformersのフューショットファインチューニングの効率的なフレームワークです。SetFitは少量のラベル付きデータで高い精度を達成します – 例えば、顧客レビュー(CR)感情データセットでクラスごとにわずか8つのラベル付きの例を使用すると、SetFitはフルトレーニングセットの3,000の例でRoBERTa Largeのファインチューニングと競争力を持ちます 🤯! 他のフューショット学習手法と比較して、SetFitにはいくつかの特徴があります: 🗣 プロンプトや口述者不要:フューショットファインチューニングの現在の技術は、例を基に言語モデルに適した形式に変換するための手作りのプロンプトや口述者が必要です。SetFitはプロンプトを一切必要とせず、わずかな数のラベル付きテキスト例から直接豊かな埋め込みを生成します。 🏎 高速トレーニング:SetFitは、高い精度を実現するためにT0やGPT-3のような大規模なモデルを必要としません。そのため、トレーニングと推論の速度は通常1桁以上速くなります。 🌎 多言語対応:SetFitはHubの任意のSentence Transformerと組み合わせて使用できるため、マルチリンガルなチェックポイントをファインチューニングするだけで、複数の言語でテキストを分類することができます。 詳細については、私たちの論文、データ、コードをご覧ください。このブログ投稿では、SetFitの動作方法と独自のモデルをトレーニングする方法について説明します。さあ、始めましょう! どのように動作するのか? SetFitは効率とシンプルさを考慮して設計されています。SetFitはまず、少数のラベル付き例(通常はクラスごとに8または16個)でSentence Transformerモデルをファインチューニングします。次に、ファインチューニングされたSentence…

非常に大規模な言語モデルとその評価方法
大規模な言語モデルは、Evaluation on the Hubを使用してゼロショット分類タスクで評価することができます! ゼロショット評価は、大規模な言語モデルの性能を測定するための研究者の人気のある方法であり、明示的にラベル付けされた例を示すことなくトレーニング中に能力を学習することが示されています。Inverse Scaling Prizeは、大規模なゼロショット評価を実施し、より大きなモデルがより小さなモデルよりも性能が低いタスクを発見するための最近のコミュニティの取り組みの一例です。 ハブ上での言語モデルのゼロショット評価の有効化 Evaluation on the Hubは、コードを書かずにHub上の任意のモデルを評価するのに役立ち、AutoTrainによって動作します。今では、Hub上の任意の因果言語モデルをゼロショットで評価することができます。ゼロショット評価は、トレーニングされたモデルが与えられたトークンセットを生成する可能性を測定し、ラベル付けされたトレーニングデータを必要としないため、研究者は高価なラベリング作業を省略することができます。 このプロジェクトのために、AutoTrainのインフラストラクチャをアップグレードし、大規模なモデルを無償で評価することができるようにしました 🤯!ユーザーがカスタムコードを書いてGPU上で大規模なモデルを評価する方法を見つけるのは高価で時間がかかるため、これらの変更により、660億のパラメータを持つ言語モデルを2000の文長のゼロショット分類タスクで評価するのに3.5時間かかり、コミュニティ内の誰でも実行できるようになりました。Evaluation on the Hubでは現在、660億のパラメータまでのモデルの評価をサポートしており、より大きなモデルのサポートも今後提供される予定です。 ゼロショットテキスト分類タスクは、プロンプトと可能な補完を含むデータセットを受け取ります。補完はプロンプトと連結され、各トークンの対数確率が合計され、正しい補完と比較するために正規化され、タスクの正確性が報告されます。 このブログ記事では、WinoBiasという職業に関連するジェンダーバイアスを測定する共参照タスクにおいて、ゼロショットテキスト分類タスクを使用してさまざまなOPTモデルを評価します。WinoBiasは、モデルが職業を言及する文章においてステレオタイプな代名詞を選ぶ可能性が高いかどうかを測定し、結果はモデルのサイズに関して逆のスケーリング傾向を示していることがわかります。 事例研究:WinoBiasタスクへのゼロショット評価 WinoBiasデータセットは、補完の選択肢が分類オプションであるゼロショットタスクとしてフォーマットされています。各補完は代名詞によって異なり、対象は職業に対して反ステレオタイプ的な補完に対応します(例:「開発者」は男性が主導するステレオタイプ的な職業なので、「彼女」が反ステレオタイプ的な代名詞になります)。例はこちらをご覧ください: 次に、Evaluation on the…

日本語安定拡散
Stable Diffusionは、CompVis、Stability AI、およびLAIONによって開発され、テキストのプロンプトを入力するだけで非常に正確な画像を生成する能力により、多くの関心を集めています。Stable Diffusionは、主にLAION-5Bデータセットの英語のサブセットであるLAION2B-enをトレーニングデータとして使用しており、その結果、より西洋文化に向かった傾向のある画像を生成するために英語のテキストのプロンプトが必要です。 株式会社rinnaは、Stable Diffusionを日本語のキャプション付き画像でファインチューニングすることで、日本語に特化したテキストから画像を生成するモデル「Japanese Stable Diffusion」を開発しました。Japanese Stable Diffusionは日本語のテキストのプロンプトを受け入れ、翻訳では表現が難しい日本語圏の文化を反映した画像を生成します。 このブログでは、Japanese Stable Diffusionの開発の背景と学習方法について説明します。Japanese Stable DiffusionはHugging FaceとGitHubで利用可能です。コードは🧨 Diffusersに基づいています。 Hugging Faceモデルカード:https://huggingface.co/rinna/japanese-stable-diffusion Hugging Face Spaces:https://huggingface.co/spaces/rinna/japanese-stable-diffusion GitHub:https://github.com/rinnakk/japanese-stable-diffusion Stable…

データセットとモデルにおけるDOI(デジタルオブジェクト識別子)の紹介
私たちの使命は、良い機械学習を民主化することです。それには、MLモデルやデータセットの再現性を高め、より良くドキュメント化し、使いやすく共有できるようなベストプラクティスが含まれます。 この課題を解決するために、喜んでお知らせしますが、ハブからモデルまたはデータセットのDOIを直接生成できるようになりました! DOIはリポジトリの設定から直接生成することができ、誰でもモデルまたはデータセットのページで「このモデル/データセットを引用する」とクリックすることであなたの作品を引用することができます🔥。 DOIとは何か、なぜ重要なのか? DOI(Digital Object Identifier)は、記事から図表、データセットやモデルなど、デジタルオブジェクトを一意に識別する文字列です。DOIはオブジェクトのメタデータに関連しており、オブジェクトのURL、バージョン、作成日、説明などが含まれます。DOIは研究や学術コミュニティでデジタルリソースを参照するための一般的に受け入れられた手段であり、書籍のISBNに相当します。 DOIを持つことで、モデルやデータセットに関する情報を見つけやすくし、世界と共有するための永続的なリンクを提供します。そのため、DOIを持つデータセットやモデルは永続的に存在し、サポートへの要求を行わない限り削除されることはありません。 Hugging FaceでDOIが割り当てられる方法は? 私たちはDataCiteと提携しており、登録されたハブのユーザーは自分のモデルやデータセットのDOIをリクエストすることができます。必要なメタデータを入力すると、新しい輝かしいDOIがもらえます🌟! モデルやデータセットの新しいバージョンがある場合、DOIは簡単に更新でき、以前のDOIのバージョンは古くなります。これにより、オブジェクトの特定のバージョンを参照するのが簡単になります。 私たちがさらに改善できるアイデアはありますか?このような多くの機能は、コミュニティのフィードバックから直接提供されています。ご意見やご要望があれば、お知らせください。または、huggingface/hub-docsの問題を開いてください🤗 このパートナーシップにはDataCiteチームに感謝します!また、このhub-docsのGitHubの問題に関する議論を開始し、育ててくれたAlix Leroyさん、Bram Vanroyさん、Daniel van Strienさん、Yoshitomo Matsubaraさんにも感謝します。

最適化ストーリー:ブルーム推論
この記事では、bloomをパワーアップする効率的な推論サーバーの裏側について説明します。 数週間にわたり、レイテンシーを5倍削減し(スループットを50倍に増やしました)、このような速度向上を達成するために私たちが経験した苦労やエピックな勝利を共有したかったです。 さまざまな人々が多くの段階で関与していたため、ここではすべてをカバーすることはできません。また、最新のハードウェア機能やコンテンツが定期的に登場するため、一部の内容は古くなっているか、まったく間違っている可能性があることをご了承ください。 もし、お好みの最適化手法が議論されていなかったり、正しく表現されていなかったりした場合は、お詫び申し上げます。新しいことを試してみたり、間違いを修正するために、ぜひお知らせください。 言うまでもなく、まず大きなモデルが最初にアクセス可能でなければ、それを最適化する理由はありません。これは、多くの異なる人々によってリードされた信じられないほどの取り組みでした。 トレーニング中にGPUを最大限に活用するために、いくつかの解決策が検討され、結果としてMegatron-Deepspeedが最終的なモデルのトレーニングに選ばれました。これは、コードがそのままではtransformersライブラリと互換性がない可能性があることを意味します。 元のトレーニングコードのため、通常行っていることの1つである既存のモデルをtransformersに移植することに取り組みました。目標は、トレーニングコードから関連する部分を抽出し、transformers内に実装することでした。この取り組みには「Younes」が取り組みました。これは、1ヶ月近くかかり、200のコミットが必要でした。 後で戻ってくるいくつかの注意点があります: 小さなモデルbigscience/bigscience-small-testingとbigscience/bloom-560mを用意する必要があります。これは非常に重要です。なぜなら、それらと一緒に作業するとすべてが高速化されるからです。 まず、最後のログがバイトまで完全に同じになることを望むことをあきらめる必要があります。PyTorchのバージョンがカーネルを変更し、微妙な違いを導入する可能性があり、異なるハードウェアでは異なるアーキテクチャのため異なる結果が得られる場合があります(コストの理由から常にA100 GPUで開発したくはないでしょう)。 すべてのモデルにとって、良い厳格なテストスイートを作ることは非常に重要です 私たちが見つけた最高のテストは、固定された一連のプロンプトを持つことでした。プロンプトを知っており、決定論的な結果が得られる必要があります。2つの生成物が同じであれば、小さなログの違いは無視できます。ドリフトが見られるたびに調査する必要があります。それは、あなたのコードがやるべきことをしていないか、または実際にそのモデルがドメイン外であるためにノイズに対してより敏感であるかのいずれかです。いくつかのプロンプトと十分に長いプロンプトがあれば、すべてのプロンプトを誤ってトリガーする可能性は低くなります。プロンプトが多ければ多いほど良く、プロンプトが長ければ長いほど良いです。 最初のモデル(small-testing)は、bloomと同じようにbfloat16であり、すべてが非常に似ているはずですが、それほどトレーニングされていないか、うまく機能しないため、出力が大きく変動します。そのため、これらの生成テストに問題がありました。2番目のモデルはより安定していましたが、bfloat16ではなくfloat16でトレーニングおよび保存されていました。そのため、2つの間にはエラーの余地があります。 完全に公平を期すために言えば、bfloat16→float16への変換は推論モードでは問題なさそうです(bfloat16は主に大きな勾配を扱うために存在しません)。 このステップでは、重要なトレードオフが発見され、実装されました。bloomは分散環境でトレーニングされたため、一部のコードはLinearレイヤー上でテンソル並列処理を行っており、単一のGPU上で同じ操作を実行すると異なる結果が得られていました。これを特定するのにかなりの時間がかかり、100%の準拠を選択した場合、モデルの速度が遅くなりましたが、少しの差がある場合は実行が速く、コードがシンプルになりました。設定可能なフラグを選択しました。 注:この文脈でのパイプライン並列処理(PP)は、各GPUがいくつかのレイヤーを所有し、各GPUがデータの一部を処理してから次のGPUに渡すことを意味します。 これで、動作可能なtransformersのクリーンなバージョンがあり、これに取り組むことができます。 Bloomは352GB(176Bパラメーターのbf16)のモデルであり、それに合わせるために少なくともそれだけのGPU RAMが必要です。一時的に小さなマシンでCPUにオフロードすることを検討しましたが、推論速度が桁違いに遅くなるため、それを取り下げました。 次に、基本的にはパイプラインを使用したかったのです。つまり、ドッグフーディングであり、これがAPIが常に裏で使用しているものです。 ただし、pipelinesは分散意識がありません(それがその目的ではありません)。オプションを簡単に話し合った後、新しく作成されたdevice_map="auto"を使用してモデルのシャーディングを管理するためにaccelerateを使用することにしました。いくつかのバグを修正し、transformersのコードを修正してaccelerateが正しい仕事をするのを助ける必要がありました。 これは、transformersのさまざまなレイヤーを分割し、各GPUにモデルの一部を与えて動作させることで機能します。つまり、GPU0が作業を行い、次にGPU1に引き渡し、それ以降同様に行います。 最終的には、上に小さなHTTPサーバーを置くことで、bloom(大規模なモデル)を提供できるようになりました!…
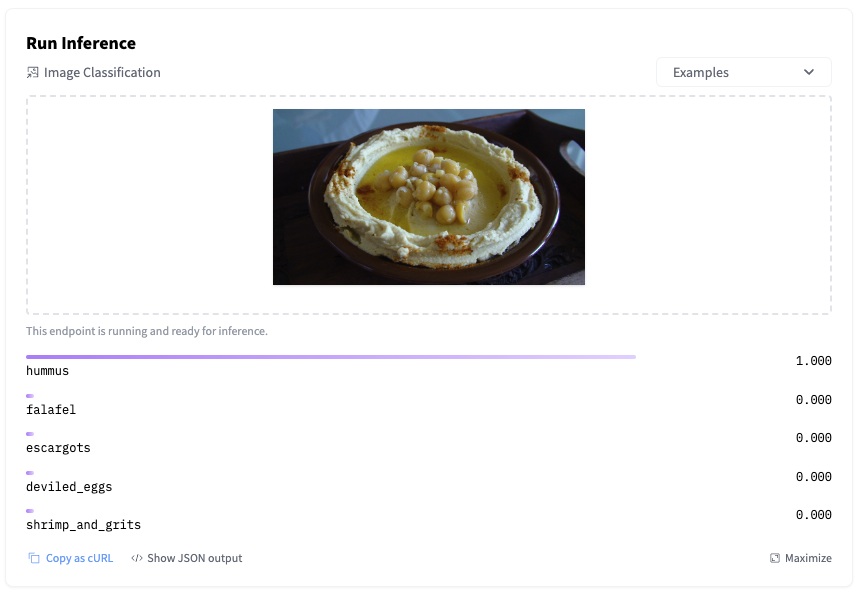
ハギングフェイス推論エンドポイントの始め方
機械学習モデルのトレーニングは非常に簡単になりました。特に、事前学習済みモデルと転移学習の台頭により、簡単なことが多いです。もちろん、時にはそれほど簡単ではないこともありますが、少なくとも、モデルのトレーニングはクリティカルなアプリケーションを壊すことはありませんし、お客様にサービス品質に不満を抱かせることもありません。しかし、モデルのデプロイメントは別ですね… はい、みんな経験があります。 モデルを本番環境でデプロイするには、通常、数々の手順を踏む必要があります。モデルをコンテナにパッケージ化し、インフラストラクチャをプロビジョニングし、予測APIを作成し、セキュリティを確保し、スケーリングし、監視するなどです。正直に言って、これらのプラミングを構築するのには実際の機械学習作業の貴重な時間が奪われてしまいます。残念なことに、うまくいかないこともあります。 私たちは、新しく発表されたHugging Face Inference Endpointsを使ってこの問題を解決しようと努めています。最新の状態を維持しつつ、機械学習をますます簡単にすることを目指して、Hugging Faceハブから直接機械学習モデルをお気に入りのクラウド上の管理されたインフラストラクチャに数回のクリックでデプロイできるサービスを構築しました。シンプルで安全でスケーラブルです。すべてが手に入ります。 では、これがどのように機能するかをご紹介します! Inference Endpointsでモデルをデプロイする Inference Endpointsがサポートしているタスクのリストを見て、最近AutoTrainでfood101データセット上で微調整したSwin画像分類モデルをデプロイすることにしました。このモデルの構築方法に興味がある場合は、このビデオで全体のプロセスを確認できます。 モデルページから、デプロイをクリックし、Inference Endpointsを選択します。 これにより、エンドポイントの作成ページに直接移動します。 最新のリビジョンのモデルを、eu-west-1リージョンのAWSでホストされる単一のGPUインスタンスにデプロイすることにしました。オプションで、オートスケーリングを設定することもできますし、カスタムコンテナにモデルをデプロイすることもできます。 次に、エンドポイントにアクセスできるユーザーを決定する必要があります。最もセキュアから最もセキュアまで、3つのオプションがあります: パブリック: エンドポイントはパブリックなHugging Faceサブネットで実行され、認証なしでインターネット上の誰でもアクセスできます。これを選択する前によく考えてください! プロテクテッド: エンドポイントはパブリックなHugging Faceサブネットで実行され、適切な組織トークンを持つインターネット上の誰でもアクセスできます。…

MTEB 大規模テキスト埋め込みベンチマーク
MTEBは、さまざまな埋め込みタスクでテキスト埋め込みモデルのパフォーマンスを測定するための大規模ベンチマークです。 🥇リーダーボードは、さまざまなタスクで最高のテキスト埋め込みモデルの包括的なビューを提供します。 📝論文は、MTEBのタスクとデータセットについての背景を説明し、リーダーボードの結果を分析しています! 💻Githubリポジトリには、ベンチマークのためのコードとリーダーボードへの任意のモデルの提出が含まれています。 テキスト埋め込みの重要性 テキスト埋め込みは、意味情報をエンコードするテキストのベクトル表現です。コンピュータは計算を行うために数値の入力を必要とするため、テキスト埋め込みは多くのNLPアプリケーションの重要な要素です。たとえば、Googleはテキスト埋め込みを検索エンジンの動力源として使用しています。テキスト埋め込みは、クラスタリングによる大量のテキストのパターン検出や、最近のSetFitのようなテキスト分類モデルへの入力としても使用できます。ただし、テキスト埋め込みの品質は、使用される埋め込みモデルに大きく依存します。MTEBは、さまざまなタスクに対して最適な埋め込みモデルを見つけるのに役立つように設計されています! MTEB 🐋 Massive:MTEBには8つのタスクにわたる56のデータセットが含まれ、現在リーダーボード上の>2000の結果を要約しています。 🌎 Multilingual:MTEBには最大112の異なる言語が含まれています!Bitext Mining、Classification、STSにおいていくつかの多言語モデルをベンチマークにかけました。 🦚 Extensible:新しいタスク、データセット、メトリクス、またはリーダーボードの追加に関しては、どんな貢献も大歓迎です。リーダーボードへの提出やオープンな課題の解決については、GitHubリポジトリをご覧ください。最高のテキスト埋め込みモデルの発見の旅にご参加いただければ幸いです。 MTEBのタスクとデータセットの概要。多言語データセットは紫の色で表示されます。 モデル MTEBの初期ベンチマークでは、最新の結果を謳うモデルやHubで人気のあるモデルに焦点を当てました。これにより、トランスフォーマーの代表的なモデルが多く含まれています。🤖 平均英語MTEBスコア(y)対速度(x)対埋め込みサイズ(円のサイズ)でモデルをグループ化しました。 次の3つの属性にモデルを分類して、タスクに最適なモデルを簡単に見つけることをお勧めします: 🏎 最大速度 Gloveのようなモデルは高速ですが、文脈の理解が不足しており、平均MTEBスコアが低くなります。 ⚖️ 速度とパフォーマンス…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.