Learn more about Search Results documentation - Page 7

- You may be interested
- If you have any further questions or ne...
- 検索の未来:ChatGPT、音声検索、画像検索...
- トップ5のデータ分析の認定資格
- 「機械学習をマスターするための10のGitHu...
- Amazon Pollyを使用してテキストが話され...
- 「GoogleはニュースのためのAIを宣伝し、...
- 画像から主要な色を抽出するREST APIの作...
- FLOPsとMACsを使用して、Deep Learningモ...
- PROsに対する推論
- 「Pythonを使用した地理空間データの分析...
- 「Amazon CloudWatchを使用して、Amazon S...
- UCサンタクルーズの研究者たちは、概念や...
- 「エンコーディングからエンベディングへ」
- 「Storytelling with Data」によると、デ...
- PolarsによるEDA:Pandasユーザーのための...

アルゴリズムのバイアスの理解:タイプ、原因、および事例研究
はじめに あなたのソーシャルメディアのフィードがあなたの興味を驚くほど正確に予測するのはなぜでしょうか?また、特定の個人がAIシステムとのやり取りで差別を受けるのはなぜでしょうか?その答えは、人工知能内の複雑で浸透力のある問題であるアルゴリズムの偏りにあります。この記事では、アルゴリズムの偏りとは何か、そのさまざまな側面、原因、および結果について開示します。さらに、責任あるAI開発と公正な利用のために、AIシステムへの信頼を確立することの緊迫性を強調します。 アルゴリズムの偏りとは何ですか? アルゴリズムの偏りとは、コンピュータプログラムが不公平な決定を下すことです。これは、完全に公平ではないデータから学習したためです。例えば、仕事を決定するのに役立つロボットを想像してください。そのロボットが主に男性の履歴書で訓練され、女性の資格についてはほとんど知識がない場合、候補者を選ぶ際に男性に不当に有利になるかもしれません。これはロボットが不公平でありたいわけではなく、バイアスのあるデータから学んだためです。アルゴリズムの偏りとは、コンピュータが教えられた情報のせいで、このように不公平な選択を意図せずにすることです。 出典:LinkedIN アルゴリズムの偏りの種類 データの偏り これは、AIモデルの訓練に使用されるデータが実世界の人口を代表していないため、偏ったまたはバランスの取れていないデータセットが生じると発生します。例えば、顔認識システムが主に肌の色の明るい人々の画像で訓練されている場合、より暗い肌色の人々を認識しようとする際にパフォーマンスが低下し、特定の人種グループに過度の影響を与えるデータの偏りが生じることがあります。 モデルの偏り これはAIモデルの設計とアーキテクチャ中に生じる偏りを指します。例えば、AIアルゴリズムが利益最大化のために設計されている場合、倫理的な考慮よりも財務上の利益を優先する決定を下すことがあり、公正性や安全性よりも利益最大化を優先するモデルの偏りが生じる可能性があります。 評価の偏り これは、AIシステムのパフォーマンスを評価するために使用される基準自体が偏っている場合に発生します。例えば、特定の文化や社会経済集団に有利な標準化されたテストを使用する教育評価AIの場合、教育における不平等を継続させる評価の偏りが生じる可能性があります。 アルゴリズムの偏りの原因 アルゴリズムの偏りの原因はいくつかありますが、それらの原因を理解し、差別を効果的に緩和し対処するためには重要です。以下にいくつかの主な原因を示します: バイアスのある訓練データ バイアスのある訓練データはバイアスの主な原因の一つです。AIシステムに教えるために使用されるデータが歴史的な偏見や不平等を反映している場合、AIはそのバイアスを学習し継続させる可能性があります。例えば、歴史的な採用データが女性や少数派グループに対してバイアスがある場合、採用のために使用されるAIも特定の人口を好む傾向があるかもしれません。 サンプリングバイアス サンプリングバイアスは、訓練に使用されるデータが全人口を代表していない場合に発生します。例えば、データが主に都市部から収集され、農村部からは収集されない場合、AIは農村のシナリオに対してうまく機能せず、農村の人口に対するバイアスが生じる可能性があります。 データの前処理 データのクリーニングと前処理の方法によってバイアスが導入される可能性があります。データの前処理方法がバイアスを考慮して慎重に設計されていない場合、最終的なモデルにおいてバイアスが持続したり増幅されたりすることがあります。 特徴選択 モデルを訓練するために選択される特徴や属性はバイアスを導入する可能性があります。特徴が公平性の影響を考慮せずに選択された場合、モデルは無意識に特定のグループを優遇する可能性があります。 モデルの選択とアーキテクチャ 機械学習アルゴリズムとモデルのアーキテクチャの選択はバイアスに寄与する場合があります。一部のアルゴリズムは他よりもバイアスの影響を受けやすく、モデルの設計方法はその公正性に影響を与える可能性があります。…

「翼を広げよう:Falcon 180Bがここにあります」
はじめに 本日は、TIIのFalcon 180BをHuggingFaceに歓迎します! Falcon 180Bは、オープンモデルの最新技術を提供します。1800億のパラメータを持つ最大の公開言語モデルであり、TIIのRefinedWebデータセットを使用して3.5兆トークンを使用してトレーニングされました。これはオープンモデルにおける最長の単一エポックの事前トレーニングを表しています。 Hugging Face Hub(ベースモデルとチャットモデル)でモデルを見つけることができ、Falcon Chat Demo Spaceでモデルと対話することができます。 Falcon 180Bは、自然言語タスク全体で最先端の結果を実現しています。これは(事前トレーニング済みの)オープンアクセスモデルのリーダーボードをトップし、PaLM-2のようなプロプライエタリモデルと競合しています。まだ明確にランク付けすることは難しいですが、PaLM-2 Largeと同等の性能を持ち、Falcon 180Bは公に知られている最も能力のあるLLMの一つです。 このブログ投稿では、いくつかの評価結果を見ながらFalcon 180Bがなぜ優れているのかを探求し、モデルの使用方法を紹介します。 Falcon-180Bとは何ですか? Falcon 180Bはどれくらい優れていますか? Falcon 180Bの使用方法は? デモ ハードウェア要件…

「生成型AIのGPT-3.5からGPT-4への移行の道程」
導入 生成型人工知能(AI)領域におけるGPT-3.5からGPT-4への移行は、言語生成と理解の分野での飛躍的な進化を示しています。GPT-4は、「Generative Pre-trained Transformer 4」の略称であり、改良されたアーキテクチャとトレーニング方法を組み合わせた反復的な進歩の結晶です。 GPT-3.5はコンテキストの把握と一貫したテキストの生成において印象的な能力を示しましたが、GPT-4はさらにこの軌道を進化させます。洗練されたトレーニングデータ、より大きなモデルサイズ、高度な微調整技術を統合することで、GPT-4はより正確かつコンテキストに敏感な応答を生み出します。 この旅は、AIの能力向上への執念深い追求を示し、AIの進化の反復的な性質を強調しています。コンテンツ作成から顧客サービスまで、さまざまなセクターでのGPT-4の展開は、人間と機械の相互作用を革新する可能性を示しています。 GPT-4は、生成型AIの可能性を際立たせ、技術の迅速な進化を考察しています。この移行は、AIを深い人間のような言語理解と生成に導く洗練されたマイルストーンを示しています。 学習目標 GPT-4の豊かな言語能力を向上させるための基本的な技術的進歩を理解する。 バイアスや誤情報の影響に対処し、倫理的な複雑さに取り組む。 産業、コミュニケーション、社会へのGPT-4の広範な影響を探求する。 GPT-4との対話スタイルの発見を通じて、その創造性を明らかにする。 GPT-4が将来のAIの景色と創造性を形作る役割を想像する。 組織や産業内での倫理的なAIの統合アプローチを育てる。 この記事はデータサイエンスブログマラソンの一部として公開されました。 生成型AI言語モデルの進化を解明する 人間の成果の限界を超える革新が続く人工知能のダイナミックな領域を探求し、GPT-3.5から変革的なGPT-4へのマイルストーンを経て進化する生成型AI言語モデルの物語に没入します。この旅を技術の独創性の物語として想像し、各フェーズがAI内の人間の言語を再現するためのマイルストーンを表しているとします。GPT-3.5の背景は、言語理解の新たな時代を切り開く数値を超えた飛躍を象徴しています。タイムラインやギアの融合などの視覚的なメタファーは、この物語の共鳴を増幅させることができます。GPT-4は、AIの進歩だけでなく、人間の知性と技術の優位性を結ぶ架け橋としての象徴として浮かび上がります。GPT-3.5からGPT-4への移行は、深いシフトを示しており、私たちの旅はその意味、進歩、そしてAIの景色全体に広がる展望を探求することになります。 GPT-3.5がこの舞台に登場することで、GPT-4の到来の重要性が高まり、単なる数値の移行を超えた意義を持つようになりました。これは、言語の理解と生成が絡み合い、コミュニケーションの構造を再想像する時代を切り開く節目となる瞬間です。言語AIの進歩の行進を示すタイムラインや、言語生成の背後にある複雑な機械の組み合わせを象徴するギアの合成など、視覚的なメタファーは、この物語の共鳴を高めることができます。GPT-4は、AIの進化だけでなく、人間の知性と技術の威力を結ぶ架け橋としての象徴です。GPT-3.5からGPT-4への移行により、私たちの探求の核心となる深いシフトが生まれ、その意義、進歩、AIの景色全体に広がる展望に更に深く踏み込むことになります。 GPT-3.5のアーキテクチャ 自己注意メカニズム 自己注意メカニズムはトランスフォーマーのアーキテクチャの重要な要素です。このメカニズムにより、モデルは特定の単語に対して、シーケンス内の異なる単語の重要性を評価することができます。このメカニズムは、単語間の関係と依存関係を捉え、モデルがコンテキストを理解することを可能にします。 マルチヘッドアテンション GPT-3.5では、他のトランスフォーマーモデルと同様に、自己注意は複数の「ヘッド」またはサブアテンションメカニズムで使用されています。各ヘッドは入力シーケンスの異なる側面に焦点を当て、モデルにさまざまな関係やパターンを捉える能力を提供します。…

「3つの医療機関が生成型AIを使用している方法」
「Med-PaLM 2および他の生成型AIソリューションを使用するGoogle Cloudのヘルスケア顧客を紹介します」

AudioLDM 2, でも速くなりました ⚡️
AudioLDM 2は、Haohe Liuらによる「AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining」で提案されました。AudioLDM 2は、テキストプロンプトを入力として受け取り、対応するオーディオを予測します。リアルな音効、人の声、音楽を生成することができます。 生成されるオーディオは高品質ですが、元の実装での推論の実行は非常に遅いです。10秒のオーディオサンプルを生成するのに30秒以上かかります。これは、深いマルチステージのモデリングアプローチ、大きなチェックポイントサイズ、最適化されていないコードなど、複数の要素の組み合わせによるものです。 このブログ記事では、Hugging Faceの🧨 Diffusersライブラリを使用してAudioLDM 2を使用する方法を紹介し、半精度、フラッシュアテンション、コンパイルなどのコードの最適化、スケジューラの選択、ネガティブプロンプティングなどのモデルの最適化を探求します。その結果、推論時間を10倍以上短縮でき、出力オーディオの品質の低下は最小限です。ブログ記事には、コードはすべて含まれていますが、説明は少なめです。 最後まで読んでください。わずか1秒で10秒のオーディオサンプルを生成する方法がわかります! モデルの概要 Stable Diffusionに触発され、AudioLDM 2はテキストからオーディオへの潜在的な拡散モデル(LDM)であり、テキストの埋め込みから連続的なオーディオ表現を学習します。 全体の生成プロセスは以下のように要約されます: テキスト入力x\boldsymbol{x}xを与えると、2つのテキストエンコーダーモデルが使用され、テキストの埋め込みが計算されます:CLAPのテキストブランチとFlan-T5のテキストエンコーダー…

「インクリメンタルラーニング:メリット、実装、課題」
インクリメンタルラーニングは、学術界における動的なアプローチを表しており、徐々で一貫した知識の吸収を促しています。学習者に大量の情報を押し付ける従来の方法とは異なり、インクリメンタルラーニングは複雑な主題を管理可能な断片に分解します。機械学習においては、インクリメンタルなアプローチによりAIモデルを新しい知識を段階的に吸収するように訓練します。これにより、モデルは既存の理解を保持・強化し、持続的な進歩の基盤を形成します。 インクリメンタルラーニングとは何ですか? インクリメンタルラーニングは、新しいデータを小さな管理可能な増分で徐々に導入することによって、年々知識を蓄積していく教育的なアプローチです。すべてを即座に学ぼうとするのではなく、インクリメンタルラーニングは複雑なトピックを小さなチャンクに分割します。このアプローチは、スペースドリペティション(間隔をあけた反復)、定期的な復習、以前に学んだ概念の強化を重視し、理解力、記憶力、主題の長期的な習得を共に向上させます。 インクリメンタルラーニングでは、AIモデルは以前に獲得した情報を忘れずに知識を徐々に向上させます。したがって、これは人間の学習パターンを模倣しています。この学習は、データの入力が順序立てて行われる場合やすべてのデータの保存が実現不可能な場合に重要です。 インクリメンタルラーニングの利点 メモリの強化、リソースの効率的な利用、リアルタイムの変化への適応、または学習をより管理可能な旅にするために、インクリメンタルラーニングは幅広い魅力的な利点を提供します: 記憶力の向上:以前に学んだ素材を再訪し、積み重ねることにより、インクリメンタルラーニングは記憶力を向上させ、知識を年々確固たるものにします。 リソースの効率的な利用:インクリメンタルラーニングモデルは一度に少ないデータを保存する必要があるため、メモリの節約に役立ちます。 リアルタイムの適応:インクリメンタルラーニングモデルはリアルタイムの変化に適応する能力を持っています。たとえば、製品推薦システムはユーザーの好みを学習し、関連する興味を引く製品を推奨します。 効率的な学習:タスクを小さなパートに分割することにより、インクリメンタルラーニングはMLモデルの新しいタスクへの学習能力を迅速に向上させ、精度を向上させます。 持続可能な学習習慣:インクリメンタルラーニングはプロセスを圧倒的に減らし、管理可能にすることで、持続可能な学習習慣を促進します。 アプリケーション指向:インクリメンタルラーニングは、概念の定期的な実践と適用が内在化されており、実用的な理解とスキルを向上させます。 インクリメンタルラーニングの実世界の応用 これらの例は、インクリメンタルラーニングが言語能力からAIモデルの精度、自動運転車の安全性まで、さまざまな領域で深みと洗練を加える方法を示しています。既存の知識を基に構築することの変革的な影響を示すこの動的なアプローチにより、より知的で適応性のあるシステムが生まれます。 言語学習 インクリメンタルラーニングは、言語習得の領域でその地歩を築いており、学習者が徐々に語彙を構築し文法の複雑さを理解していく旅です。この徐々のアプローチにより、学習者は時間をかけて語学力を向上させることができます。基本的なフレーズのマスタリングから複雑な文構造の理解まで、インクリメンタルラーニングは包括的な言語力を養成する道を開きます。 AIと機械学習 AIと機械学習のダイナミックな世界では、インクリメンタルラーニングの技術が新しい情報の流入に基づいてモデルを磨き、置き換える役割を果たしています。これらの技術により、モデルは最新のデータに更新され、進化するパターンと洞察に適応します。この柔軟なアプローチは、変化が唯一の定数であるドメインで特に重要であり、AIシステムが高い精度と関連性を維持することを可能にします。 詐欺検知システム 金融セクターに進出すると、インクリメンタルラーニングのアルゴリズムは銀行システム内の不正行為に対抗するために重要です。Mastercardは、これらのアルゴリズムを使用してさまざまな変数を検討し、不正な取引の確率を評価しています。新しいデータインスタンスごとに、アルゴリズムは自身の理解を洗練し、不正行為の検出精度を高め、金融取引を保護します。 自動運転車 自動運転車の領域は、インクリメンタルラーニングが輝く別の領域です。自動運転車は蓄積された知識の力を利用し、以前の経験から学び、より効果的に周囲の環境をナビゲートします。これらの車は道路を走行する際にさまざまな状況からデータを収集し、異なるシナリオの理解を向上させます。テスラの車は、道路からデータを収集して機械学習モデルを改善し、より安全でスマートな運転体験を創造しています。 推薦システム デジタルの世界では、増分学習によって私たちが日々遭遇する個別化された推薦が形成されます。ニュース記事から映画の提案まで、推薦システムは私たちの好みを理解し、私たちの嗜好に合ったコンテンツをカリキュレートします。このアプローチは徐々に洗練され、ユーザーがカスタマイズされた魅力的な消費の旅を楽しむことができるように、推薦を微調整していきます。…
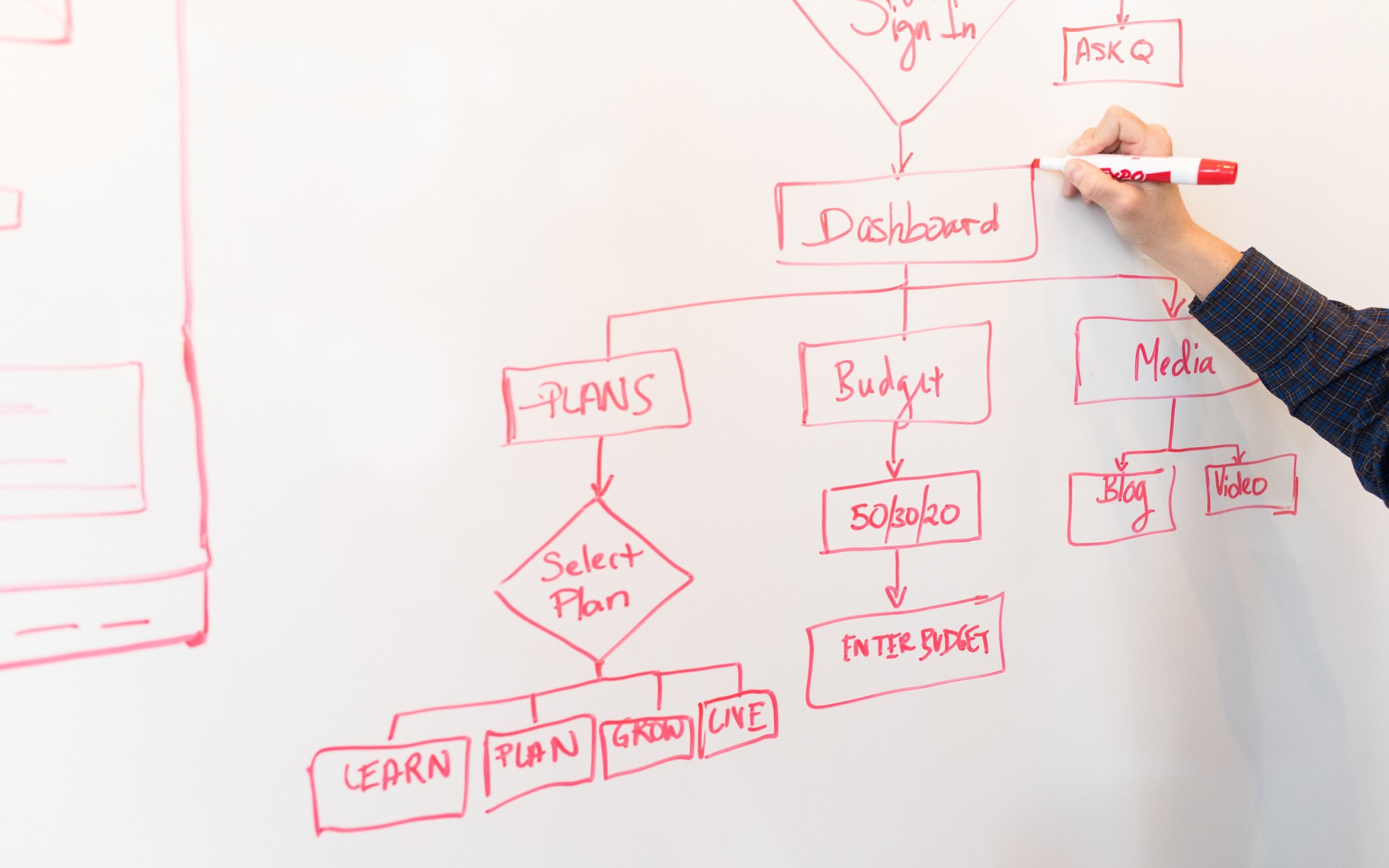
開発者の皆さんへ:ダイアグラムはそんなに複雑である必要はありません
「図表は有用な情報を含んでいるだけでなく、読みやすいものでなければなりませんそして、作成するのも簡単で、楽しいことが望ましいです!」

「OceanBaseを使用して、ゼロからLangchainの代替を作成する」
「オーシャンベースとAIの統合からモデルのトレーニングやチャットボットの作成まで、興味深い旅を通じてこのトピックを探求します」

「Llama 2がコーディングを学ぶ」
イントロダクション Code Llamaは、コードタスクに特化した最新のオープンアクセスバージョンであり、Hugging Faceエコシステムでの統合をリリースすることに興奮しています! Code Llamaは、Llama 2と同じ許容されるコミュニティライセンスでリリースされ、商業利用が可能です。 今日、私たちは以下をリリースすることに興奮しています: モデルカードとライセンスを備えたHub上のモデル Transformersの統合 高速かつ効率的な本番用推論のためのテキスト生成推論との統合 推論エンドポイントとの統合 コードのベンチマーク Code LLMは、ソフトウェアエンジニアにとってのエキサイティングな開発です。IDEでのコード補完により生産性を向上させることができ、ドックストリングの記述などの繰り返しや面倒なタスクを処理することができ、ユニットテストを作成することもできます。 目次 イントロダクション 目次 Code Llamaとは? Code Llamaの使い方 デモ Transformers…
「ジェネラティブAIを使用した7つのプロジェクト」
ジェネラティブAIを利用した個人プロジェクトで強力なポートフォリオを作り方を学びましょうこれにより、あなたは他の人と差をつけることができます!
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.