Learn more about Search Results Scipy - Page 7

- You may be interested
- 『Amazon Search M5がAWS Trainiumを使用...
- 「Meditronを紹介:LLaMA-2に基づいたオー...
- 「量子インターネットへの新たなルート」
- 「ビリー・コーガンのネットワークをグラ...
- 衝撃的な現実:ChatGPTのデータ漏洩への脆...
- CMUの研究者が「Zeno」という名前の、機械...
- 「AIによる生成写真を用いた文学作品にお...
- AlphaTensorを使用して新しいアルゴリズム...
- ルーターLangchain:Langchainを使用して...
- RepVGG 構造的再パラメータ化の詳細な説明
- 「アウトライア検出手法の比較」
- アップルとEquall AIによる新しいAI研究が...
- 効率的な開発者ですか?それならAIがあな...
- 「データエンジニアリング入門ガイド」
- ホワイトハウス、AI安全への懸念に対処す...

「トップの画像処理Pythonライブラリ」
コンピュータビジョンは、デジタル写真、ビデオ、その他の視覚的な入力から有用な情報を抽出し、そのデータに基づいてアクションを起動したり推奨を行ったりするための人工知能(AI)の一分野です。この情報を抽出するためには、画像処理という画像を操作、編集、または操作してその特徴を抽出する現象が必要です。この記事では、Pythonで使用できるいくつかの便利な画像処理ライブラリについて説明します。 1. OpenCV OpenCVは、画像処理とコンピュータビジョンアプリケーションのための最も速く、広く使用されているライブラリの1つです。Githubでサポートされており、1000人以上の貢献者がライブラリの開発に寄与しています。1999年にIntelによって作成され、C、C++、Java、そして最も人気のあるPythonなど、多くの言語をサポートしています。OpenCVは、顔認識、物体検出、画像セグメンテーションなどのモデルを構築するための約2500のアルゴリズムを提供しています。 2. Mahotas Mahotasは、閾値処理、畳み込み、形態学的処理などの高度な機能を提供する画像処理とコンピュータビジョンのための高度なPythonライブラリです。C++で書かれており、高速です。 3. SimpleCV SimpleCVは、OpenCVのより簡単なバージョンと考えることができます。Pythonのフレームワークです。色空間、バッファ管理、固有値などの多くの画像処理の前提条件や概念を必要としません。そのため、初心者にも適しています。 4. Pillow Pillowは、Python Imaging Library(PIL)に基づいています。このライブラリは、広範なファイル形式のサポート、効率的な内部表現、かなり強力な画像処理機能を提供します。ポイント操作、フィルタリング、操作など、さまざまな画像処理活動を包括しています。 5. Scikit-Image Scikit-Imageは、画像処理のためのオープンソースのPythonライブラリです。元の画像を変換することにより、NumPy配列を画像オブジェクトとして使用します。NumPyはCプログラミングで構築されているため、画像処理に非常に高速で効果的なライブラリです。フィルタリング、モルフォロジー、特徴検出、セグメンテーション、幾何学的変換、色空間操作などのアルゴリズムが含まれています。 6. SimplelTK SimpleITKは、多次元画像解析を提供するオープンソースのライブラリです。画像を配列として考えるのではなく、空間内の点の集合として扱います。Python、R、Java、C#、Lua、Ruby、TCL、C ++などの言語をサポートしています。 7. SciPy…
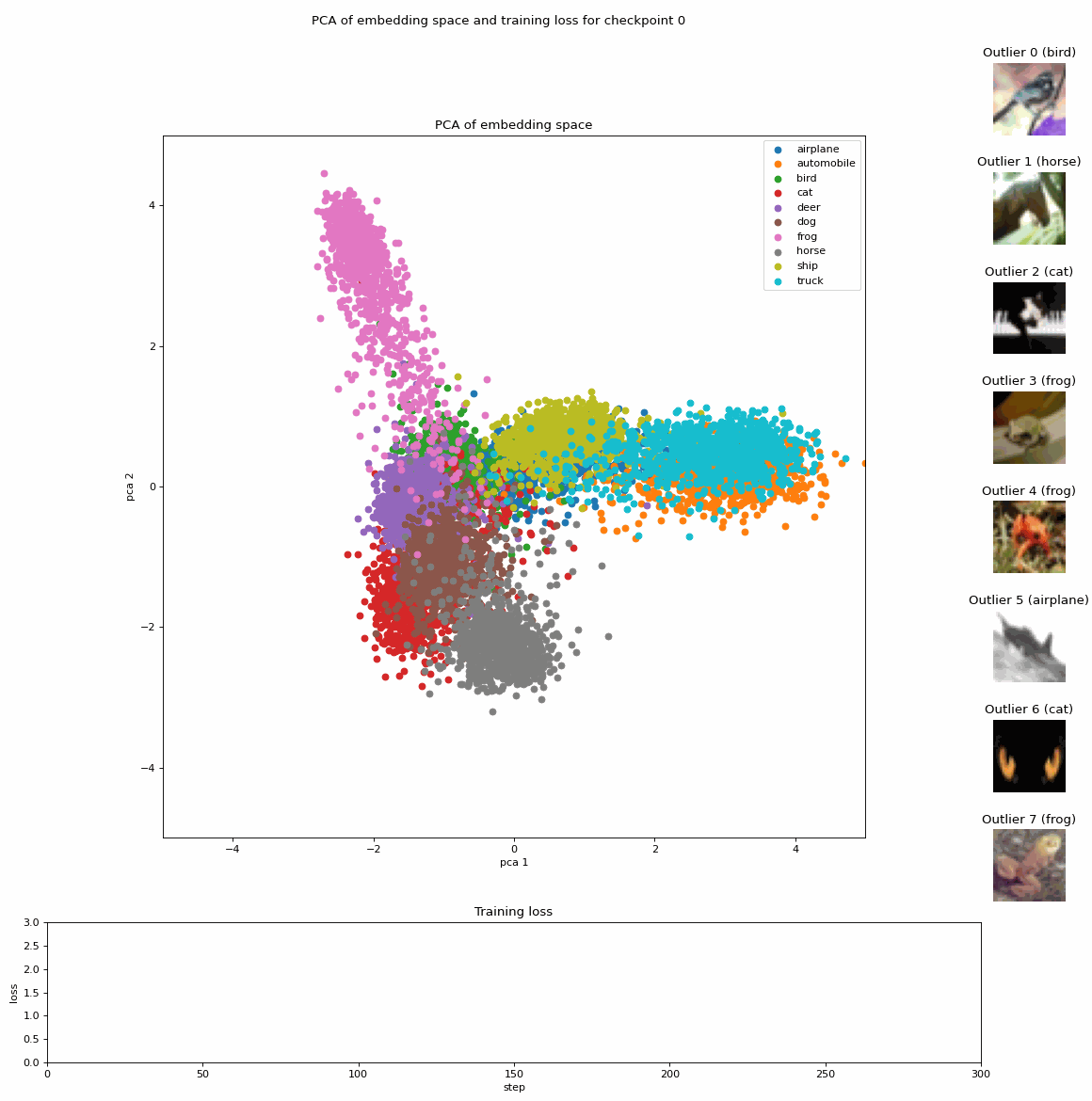
「ファインチューニング中に埋め込みのアニメーションを作成する方法」
「機械学習の分野では、ビジョントランスフォーマー(ViT)は画像分類に使用されるモデルの一種です従来の畳み込みニューラルネットワークとは異なり、ViTはトランスフォーマーアーキテクチャを使用します…」

ハイパーパラメータ最適化のためのトップツール/プラットフォーム2023年
ハイパーパラメータは、モデルの作成時にアルゴリズムの振る舞いを制御するために使用されるパラメータです。これらの要因は通常のトレーニングでは見つけることができません。モデルをトレーニングする前に、それらを割り当てる必要があります。 最適なハイパーパラメータの組み合わせを選ぶプロセスは、機械学習におけるハイパーパラメータの最適化またはチューニングとして知られています。 タスクに応じて利点と欠点を持つ、いくつかの自動最適化方法があります。 ディープラーニングモデルの複雑さとともに、ハイパーパラメータの最適化のためのツールの数も増えています。ハイパーパラメータの最適化(HPO)には、オープンソースのツールとクラウドコンピューティングリソースに依存したサービスの2つの種類のツールキットが一般的にあります。 以下に、MLモデルのハイパーパラメータ最適化に使用される主要なハイパーパラメータ最適化ライブラリとツールを示します。 ベイズ最適化 ベイジアン推論とガウス過程に基づいて構築されたPythonプログラムであるBayesianOptimisationは、ベイジアングローバル最適化を使用して、可能な限り少ない反復回数で未知の関数の最大値を見つけます。この方法は、探索と活用の適切なバランスを取ることが重要な高コスト関数の最適化に最適です。 GPyOpt GPyOptは、ベイジアン最適化のためのPythonオープンソースパッケージです。ガウス過程モデリングのためのPythonフレームワークであるGPyを使用して構築されています。このライブラリは、ウェットラボの実験、モデルと機械学習手法の自動セットアップなどを作成します。 Hyperopt Hyperoptは、条件付き、離散、および実数値の次元を含む検索空間上の直列および並列最適化に使用されるPythonモジュールです。ハイパーパラメータの最適化(モデル選択)を行いたいPythonユーザーに、並列化のための手法とインフラストラクチャを提供します。このライブラリでサポートされているベイジアン最適化の手法は、回帰木とガウス過程に基づいています。 Keras Tuner Keras Tunerモジュールを使用すると、機械学習モデルの理想的なハイパーパラメータを見つけることができます。コンピュータビジョン向けの2つのプリビルドカスタマイズ可能なプログラムであるHyperResNetとHyperXceptionがライブラリに含まれています。 Metric Optimisation Engine (MOE) Metric Optimisation Engine(MOE)は、最適な実験設計のためのオープンソースのブラックボックスベイジアングローバル最適化エンジンです。パラメータの評価に時間や費用がかかる場合、MOEはシステムのパラメータ最適化方法として有用です。A/Bテストを通じてシステムのクリックスルーや変換率を最大化したり、高コストのバッチジョブや機械学習予測手法のパラメータを調整したり、エンジニアリングシステムを設計したり、現実の実験の最適なパラメータを決定したりするなど、さまざまな問題に対応できます。 Optuna Optunaは、機械学習に優れた自動ハイパーパラメータ最適化のためのソフトウェアフレームワークです。ハイパーパラメータの検索空間を動的に構築するための命令的な定義によるユーザAPIを提供します。このフレームワークは、プラットフォームに依存しないアーキテクチャ、シンプルな並列化、Pythonicな検索空間のための多くのライブラリを提供します。…

「Pymcと統計モデルを記述するための言語の紹介」
「ベイズ推論のほとんどの例がそれが何であるかを誤解している理由についての前回の記事では、ベイズ統計の初心者の間で一般的な誤解を明確にしましたそれは、…」
アップリフトモデルの評価
業界での因果推論の最も広く利用されているアプリケーションの1つは、アップリフトモデリング、または条件付き平均治療効果の推定ですある処置の因果効果を推定する際には、

TransformersとRay Tuneを使用したハイパーパラメータの検索
Anyscale チームの Richard Liaw によるゲストブログ投稿 最先端の研究実装や数千ものトレーニング済みモデルへの簡単なアクセスが可能な Hugging Face transformers ライブラリは、自然言語処理の成功と成長において重要な存在となっています。 良いパフォーマンスを達成するために、ほとんどのユーザーはパラメータのチューニングを行う必要があります。しかし、ほとんどの人はハイパーパラメータのチューニングを無視するか、小さな探索空間で簡素なグリッドサーチを行うことを選択します。 しかし、簡単な実験でも高度なチューニング手法の利点を示すことができます。以下は、Hugging Face transformers の BERT モデルを RTE データセットで実行した最近の実験結果です。PBT のような遺伝的最適化手法は、標準的なハイパーパラメータ最適化手法と比較して大幅なパフォーマンス向上を提供できます。 アルゴリズム 最高の検証精度 最高のテスト精度 合計…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…

埋め込みを使った始め方
ノートブックコンパニオンを使用したこのチュートリアルをチェックしてください: 埋め込みの理解 埋め込みは、テキスト、ドキュメント、画像、音声などの情報の数値表現です。この表現は、埋め込まれているものの意味を捉え、多くの産業アプリケーションに対して堅牢です。 テキスト「投票の主な利点は何ですか?」に対する埋め込みは、たとえば、384個の数値のリスト(例:[0.84、0.42、…、0.02])でベクトル空間で表現されることがあります。このリストは意味を捉えているため、異なる埋め込み間の距離を計算して、2つの文の意味がどれだけ一致するかを判断するなど、興味深いことができます。 埋め込みはテキストに限定されません!画像の埋め込み(たとえば、384個の数値のリスト)を作成し、テキストの埋め込みと比較して文が画像を説明しているかどうかを判断することもできます。この概念は、画像検索、分類、説明などの強力なシステムに適用されています! 埋め込みはどのように生成されるのでしょうか?オープンソースのライブラリであるSentence Transformersを使用すると、画像やテキストから最先端の埋め込みを無料で作成することができます。このブログでは、このライブラリを使用した例を紹介しています。 埋め込みの用途は何ですか? 「[…] このMLマルチツール(埋め込み)を理解すると、検索エンジンからレコメンデーションシステム、チャットボットなど、さまざまなものを構築できます。データサイエンティストやMLの専門家である必要はありませんし、大規模なラベル付けされたデータセットも必要ありません。」- デール・マルコウィッツ、Google Cloud。 情報(文、ドキュメント、画像)が埋め込まれると、創造性が発揮されます。いくつかの興味深い産業アプリケーションでは、埋め込みが使用されます。たとえば、Google検索ではテキストとテキスト、テキストと画像をマッチングさせるために埋め込みを使用しています。Snapchatでは、「ユーザーに適切な広告を適切なタイミングで提供する」ために埋め込みを使用しています。Meta(Facebook)では、ソーシャルサーチに埋め込みを使用しています。 埋め込みから知識を得る前に、これらの企業は情報を埋め込む必要がありました。埋め込まれたデータセットを使用することで、アルゴリズムは素早く検索、ソート、グループ化などを行うことができます。ただし、これは費用がかかり、技術的にも複雑な場合があります。この投稿では、シンプルなオープンソースのツールを使用して、データセットを埋め込み、分析する方法を紹介します。 埋め込みの始め方 小規模なよく寄せられる質問(FAQ)エンジンを作成します。ユーザーからのクエリを受け取り、最も類似したFAQを特定します。米国社会保障メディケアFAQを使用します。 しかし、まず、データセットを埋め込む必要があります(他のテキストでは、エンコードと埋め込みの用語を交換可能に使用します)。Hugging FaceのInference APIを使用すると、簡単なPOSTコールを使用してデータセットを埋め込むことができます。 質問の意味を埋め込みが捉えるため、異なる埋め込みを比較してどれだけ異なるか、または類似しているかを確認することができます。これにより、クエリに最も類似した埋め込みを取得し、最も類似したFAQを見つけることができます。このメカニズムの詳細な説明については、セマンティックサーチのチュートリアルをご覧ください。 要するに、以下の手順を実行します: Inference APIを使用してメディケアのFAQを埋め込む。 埋め込まれた質問を無料ホスティングするためにHubにアップロードする。…

🧨ディフューザーを使用した安定した拡散
…🧨 ディフューザーを使用して Stable Diffusionは、CompVis、Stability AI、およびLAIONの研究者とエンジニアによって作成されたテキストから画像への潜在的な拡散モデルです。これは、LAION-5Bデータベースのサブセットから512×512の画像でトレーニングされています。LAION-5Bは現在存在する最大の、自由にアクセス可能な多様性のあるデータセットです。 この記事では、Stable Diffusionと🧨 ディフューザーのライブラリを使用する方法、モデルの動作の説明、およびディフューザーを使用して画像生成パイプラインをカスタマイズする方法について説明します。 注意:ディフュージョンモデルの動作原理を基本的に理解することを強くお勧めします。ディフュージョンモデルが完全に新しいものである場合、次のブログ記事のいずれかを読むことをお勧めします: 注釈付きディフュージョンモデル 🧨 ディフューザーの始め方 それでは、いくつかの画像を生成しましょう 🎨。 Stable Diffusionの実行 ライセンス モデルを使用する前に、モデルのライセンスを受け入れて重みをダウンロードして使用する必要があります。 注意:ライセンスはもはやUIを介して明示的に受け入れる必要はありません。 このライセンスは、このような強力な機械学習システムの潜在的な有害な影響を緩和するために設計されています。ユーザーには、ライセンスを完全かつ注意深く読むことをお願いします。以下に要約を提供します: モデルを意図的に違法または有害な出力やコンテンツの生成や共有に使用することはできません。 生成した出力に対する権利は主張しません。使用は自由であり、使用に関してはライセンスで設定された規定に違反してはならず、その使用については責任があります。 重みを再配布し、モデルを商業的および/またはサービスとして使用することができます。ただし、その場合、ライセンスで設定された使用制限とCreativeML OpenRAIL-Mのコピーをすべてのユーザーに提供する必要があります。…

Pythonでトレーニング済みモデルを保存する方法
実世界の機械学習(ML)のユースケースに取り組む際、最適なアルゴリズム/モデルを見つけることは責任の終わりではありませんこれらのモデルを将来の使用や本番環境への展開のために保存、保管、パッケージ化することが重要ですこれらのプラクティスはいくつかの理由から必要です:再強調すると、MLモデルの保存と保管...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.