Learn more about Search Results Meg - Page 7

- You may be interested
- ChatGPTの応用:産業全体におけるポテンシ...
- 「業界アプリケーションにおける大規模言...
- 「AIrtist:芸術における共創とコンピュー...
- 「MLOpsに関する包括的なガイド」
- ChatGPTのコードインタプリター:知ってお...
- 「データサイエンスの手法がビジネスの成...
- Earth.comとProvectusがAmazon SageMaker...
- スタンフォード大学の研究者たちは、安定...
- 「2023年に注目すべき10の環境テック企業」
- このAI研究では、「DreamCraft3D」という...
- Graph RAG LLMによるナレッジグラフのパワ...
- BERT 101 – 最新のNLPモデルの解説
- 「2024年に注目すべきトップ10のリモート...
- 「Google AIがAltUpを紹介」
- 「30日間のマップチャレンジの私の3週目」

テキストデータのチャンキング方法-比較分析
自然言語処理(NLP)における「テキストチャンキング」プロセスは、非構造化テキストデータを意味のある単位に変換することを意味しますこの見かけ上シンプルなタスクには、複雑さが隠されています
「過小評価されている宝石Pt.1:あなたをプロにする8つのPandasメソッド」
しばらくはChatGPTを忘れましょう私たちの中には、シンプルなPandasの操作を行いたいときに毎回解決策をグーグルで検索することで疲れてしまう人もいます同じことをするための方法は数多く存在するようです...

「検索拡張生成のための情報検索」
「情報検索のパフォーマンスを劇的に向上させるための、3つ(と半分)のシンプルで実戦済みのヒント」
PlotlyとPandas:効果的なデータ可視化のための力の結集
昔々、私たちの多くがこの問題にぶつかったことがありましたもし才能がないか、前もってデザインのコースを受講したことがなければ、視覚的なものを作ることはかなり困難で時間がかかるかもしれません…
CPU上でBERT推論をスケーリングアップする(パート1)
.centered { display: block; margin: 0 auto; } figure { text-align: center; display: table; max-width: 85%; /* デモです; 必要に応じていくつかの量 (px や %) を設定してください */…
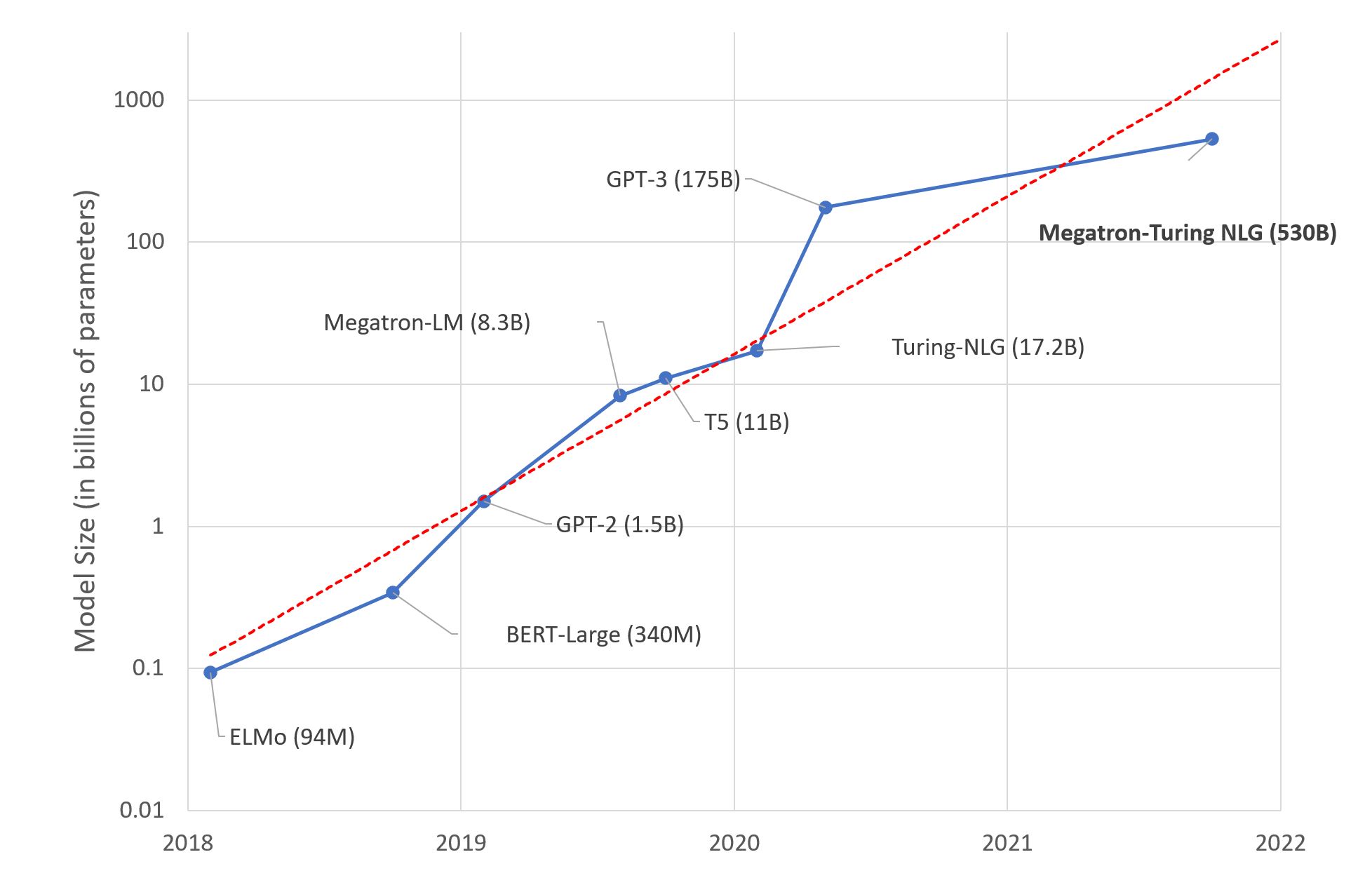
大規模言語モデル:新たなモーアの法則?
数日前、MicrosoftとNVIDIAは「世界最大かつ最もパワフルな生成言語モデル」と称される、Megatron-Turing NLG 530BというTransformerベースのモデルを発表しました。 これは、間違いなく機械学習エンジニアリングの印象的なデモンストレーションです。しかし、このメガモデルのトレンドに興奮すべきでしょうか?私自身はそう思いません。以下にその理由を説明します。 これがディープラーニングの脳です 研究者は、人間の脳が平均して860億個のニューロンと100兆個のシナプスを持つと推定しています。言語に特化しているわけではないことは明らかです。興味深いことに、GPT-4は約100兆個のパラメータを持つ予定です…この例えがどれほど不正確かもしれませんが、人間の脳と同じくらいの大きさの言語モデルを構築することが最善の長期的なアプローチなのか疑問に思わないでしょうか? もちろん、私たちの脳は進化の結果として何百万年もの間に生まれた驚異的なデバイスですが、ディープラーニングモデルは数十年しか存在していません。それでも、私たちの直感が何かが計算できないと感じるはずです。 ディープラーニング、深いポケット? 予想通り、巨大なテキストデータセットで5300億のパラメータを持つモデルをトレーニングするためには、相当なインフラストラクチャが必要です。実際に、MicrosoftとNVIDIAは数百台のDGX A100マルチGPUサーバーを使用しました。1台あたり199,000ドルで、ネットワーク機器やホスティングコストなども考慮すると、この実験を複製しようとする場合、1億ドル近く費やさなければなりません。それにつけてもフライドポテトはいかがでしょうか? 真剣に考えてみてください。どのようなビジネスケースを持つ組織が、ディープラーニングのインフラストラクチャに1億ドル、さらには1,000万ドルも費やす価値があるのでしょうか?ほとんどありません。では、これらのモデルは実際に誰のために存在するのでしょうか? その暖かい感覚はGPUクラスターです エンジニアリングの素晴らしさにもかかわらず、GPU上でのディープラーニングモデルのトレーニングは力技です。仕様書によると、各DGXサーバーは最大で6.5キロワット消費します。もちろん、データセンター(またはサーバールーム)には少なくとも同じくらいの冷却能力が必要です。あなたがスターク家であり、ウィンターフェルを冬の寒さから守る必要がある場合を除いて、これは別の問題です。 さらに、公衆の意識が気候変動や社会的責任の問題について高まるにつれ、組織は自らの炭素排出量を考慮する必要があります。2019年のマサチューセッツ大学の研究によれば、「GPU上でBERTをトレーニングすることは、アメリカ横断飛行とほぼ同等である」とされています。 BERT-Largeは3億4000万個のパラメータを持っています。Megatron-Turingの環境影響は計り知れません…私を知っている人たちは私を環境保護主義者とは呼ばないでしょうが、いくつかの数字は無視できません。 では? Megatron-Turing NLG 530Bや次に登場するどんなビーストに興奮していますか?いいえ。追加のコスト、複雑さ、環境への影響を考えると、(比較的小さい)ベンチマークの改善がその価値に見合っているとは思いません。これらの巨大モデルの構築と宣伝が組織の機械学習の理解と採用に役立っていると思いますか?いいえ。 私は何のためにこれらを行っているのか疑問に思っています。科学のための科学?昔ながらのマーケティング?技術的な優位性?おそらくそれぞれの要素が少しずつ関与しているでしょう。それらに任せておきましょう。 代わりに、高品質な機械学習ソリューションを構築するために皆さんが利用できる実用的で実行可能な技術に焦点を当てましょう。 事前学習済みモデルを使用する ほとんどの場合、カスタムのモデルアーキテクチャは必要ありません。カスタムのモデル(別のものですが)が必要な場合もありますが、それは専門家向けです。 始める良いポイントは、解決しようとしているタスクに対して事前学習されたモデルを探すことです(例えば、英語のテキストを要約するためのモデルなど)。…

機械学習の専門家 – マーガレット・ミッチェル
みなさん、こんにちは!Machine Learning Expertsへようこそ。私は司会のBritney Mullerです。今日のゲストは、マーガレット・ミッチェル(通称メグ)です。メグはGoogleのEthical AIグループの創設者兼共同リーダーであり、機械学習の分野でのパイオニアであり、50以上の論文を発表しているだけでなく、Ethical AIの分野でのリーディングリサーチャーでもあります。 メグがエシカルAIの重要性に気づいた瞬間(素晴らしいストーリー!)、MLチームが有害なデータバイアスにより意識的になる方法、およびMLにおける包括性と多様性の力(およびパフォーマンスの利点)について話すことができます。 このパワフルなエピソードをご紹介できることをとても楽しみにしています!こちらがメグ・ミッチェルとの対談です: 転写: 注:転写はわかりやすい読みやすさを提供するためにわずかに修正/再フォーマットされています。 あなたの経歴とHugging Faceへの経緯について少し共有していただけますか? Dr. マーガレット・ミッチェルの経歴: Reed Collegeで言語学の学士号を取得 – NLPに取り組んだ 学士号取得後、補助および補完技術に取り組み、修士課程中も同様に研究 ワシントン大学で計算言語学の修士号を取得 コンピュータサイエンスの博士号を取得 メグ:私はJohns Hopkinsでポスドクとして統計的な研究を行い、その後、Microsoft Researchに移り、ビジョンから言語生成に取り組み、盲目の人々が世界をより簡単に移動できるようにするSeeing…
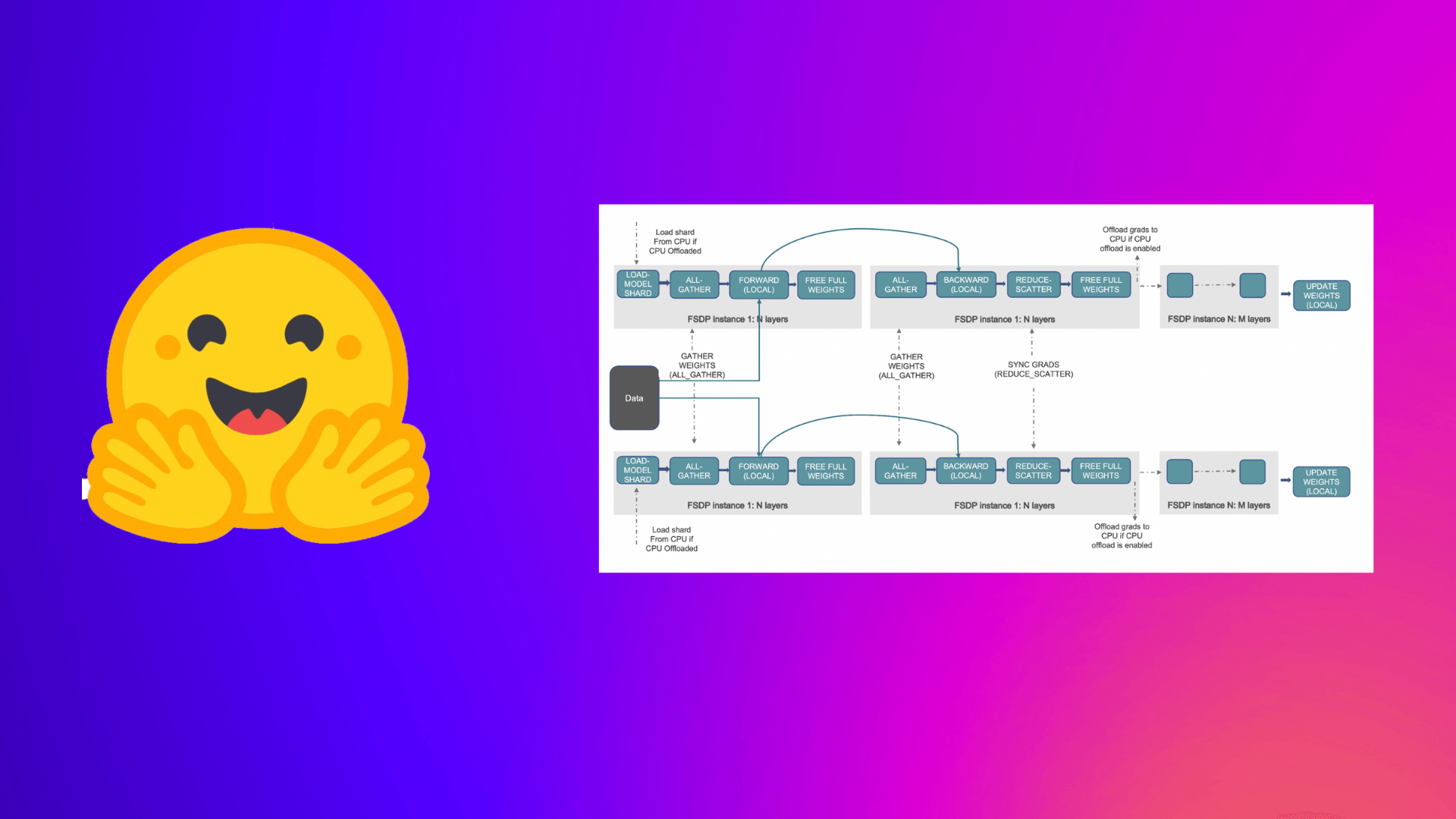
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

BLOOMトレーニングの技術背後
近年、ますます大規模な言語モデルの訓練が一般的になってきました。これらのモデルがさらなる研究のために公開されていない問題は頻繁に議論されますが、そのようなモデルを訓練するための技術やエンジニアリングについての隠された知識は滅多に注目されません。本記事では、1760億パラメータの言語モデルBLOOMを例に、そのようなモデルの訓練の裏側にあるハードウェアとソフトウェアの技術とエンジニアリングについて、いくつかの光を当てることを目指しています。 しかし、まず、この素晴らしい1760億パラメータモデルの訓練を可能にするために貢献してくれた企業や主要な人物やグループに感謝したいと思います。 その後、ハードウェアのセットアップと主要な技術的な構成要素について説明します。 以下はプロジェクトの要約です: 人々 このプロジェクトは、Hugging Faceの共同創設者でありCSOのThomas Wolf氏が考案しました。彼は巨大な企業と競争し、単なる夢だったものを実現し、最終的な結果をすべての人にアクセス可能にすることで、最も多くの人々にとっては夢であったものを実現しました。 この記事では、モデルの訓練のエンジニアリング側に特化しています。BLOOMの背後にある技術の最も重要な部分は、私たちにコーディングと訓練の助けを提供してくれた専門家の人々と企業です。 感謝すべき6つの主要なグループがあります: HuggingFaceのBigScienceチームは、数人の専任の従業員を捧げ、訓練を始めから終わりまで行うための方法を見つけるために、Jean Zayの計算機を超えるすべてのインフラストラクチャを提供しました。 MicrosoftのDeepSpeedチームは、DeepSpeedを開発し、後にMegatron-LMと統合しました。彼らの開発者たちはプロジェクトのニーズに多くの時間を費やし、訓練前後に素晴らしい実践的なアドバイスを提供しました。 NVIDIAのMegatron-LMチームは、Megatron-LMを開発し、私たちの多くの質問に親切に答えてくれ、一流の実践的なアドバイスを提供しました。 ジャン・ゼイのスーパーコンピュータを管理しているIDRIS / GENCIチームは、計算リソースをプロジェクトに寄付し、優れたシステム管理のサポートを提供しました。 PyTorchチームは、このプロジェクトのために基礎となる非常に強力なフレームワークを作成し、訓練の準備中に私たちをサポートし、複数のバグを修正し、PyTorchコンポーネントの使いやすさを向上させました。 BigScience Engineeringワーキンググループのボランティア プロジェクトのエンジニアリング側に貢献してくれたすべての素晴らしい人々を全て挙げることは非常に困難なので、Hugging Face以外のいくつかの主要な人物を挙げます。彼らはこのプロジェクトのエンジニアリングの基盤となりました。 Olatunji Ruwase、Deepak…

Sentence Transformersモデルのトレーニングと微調整
このNotebook Companion付きのチュートリアルをご覧ください: センテンス変換モデルのトレーニングまたはファインチューニングは、利用可能なデータと目標のタスクに大きく依存します。キーは2つあります: モデルにデータを入力し、データセットを適切に準備する方法を理解する。 データセットと関連する異なる損失関数を理解する。 このチュートリアルでは、以下の内容を学びます: “スクラッチ”から作成するか、Hugging Face Hubからファインチューニングすることにより、センテンス変換モデルの動作原理を理解する。 データセットの異なる形式について学ぶ。 データセットの形式に基づいて選択できる異なる損失関数について確認する。 モデルのトレーニングまたはファインチューニング。 Hugging Face Hubにモデルを共有する。 センテンス変換モデルが最適な選択肢でない場合について学ぶ。 センテンス変換モデルの動作原理 センテンス変換モデルでは、可変長のテキスト(または画像ピクセル)を、その入力の意味を表す固定サイズの埋め込みにマップします。埋め込みの取得方法については、前回のチュートリアルをご覧ください。この投稿では、テキストに焦点を当てています。 センテンス変換モデルの動作原理は次の通りです: レイヤー1 – 入力テキストは、Hugging Face Hubから直接取得できる事前学習済みTransformerモデルを通過します。このチュートリアルでは、「distilroberta-base」モデルを使用します。Transformerの出力は、すべての入力トークンに対する文脈化された単語の埋め込みです。テキストの各トークンに対する埋め込みを想像してください。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.