Learn more about Search Results Loom - Page 7

- You may be interested
- 「30日間のマップチャレンジの私の3週目」
- 「MapReduceを使用したスケールでのデータ...
- 「LLMの評価にLLMを使用する」
- AIの10年間のレビュー
- このAI論文では、マルチビューの冗長性を...
- JavaScriptを使用してOracleデータベース...
- ロボキャット:自己改善型ロボティックエ...
- AI生成アート:倫理的な意義と議論
- 「ハブスポット、ハブスポットAIおよび新...
- 「Nvidiaの画期的なAIイメージパーソナラ...
- 「どのようにして、1ビットのウェイトで大...
- 『ジュリエット・パウエル&アート・ク...
- データウェアハウスとデータレイクとデー...
- 「人気コンテストをごまかすためのGitHub...
- 「AIの革命:WatsonXの力を明らかにする」

『倫理と社会ニュースレター#5:ハグフェイスがワシントンに行くと、他の2023年夏の考え事』
人工知能(AI)における「倫理」について知っておくべき最も重要なことの一つは、それが「価値観」に関連しているということです。倫理は何が正しくて何が間違っているかを教えてくれるのではなく、透明性、安全性、公正などの価値観の語彙と優先順位を定めるための枠組みを提供します。今年の夏、私たちはAIの価値観についての理解を欧州連合、イギリス、アメリカの立法府に伝え、AIの規制の未来を形作るのに役立ちました。ここで倫理が光を放つのです:法律がまだ整っていないときに前進するための道筋を切り開くのに役立つのです。 Hugging Faceの主要な価値であるオープンさと責任を守るために、私たちはここで私たちが言ったことや行ったことのコレクションを共有しています。これには、私たちのCEOであるクレムが米国議会に対する証言や米国上院AI Insight Forumでの発言、E.U. AI Actに関するアドバイス、NTIAに対するAIの責任に関するコメント、そして私たちのChief Ethics Scientistであるメグの民主党議員団に対するコメントなどが含まれています。これらの議論の多くで共通していたのは、なぜAIのオープンさが有益であるのかという質問でした。私たちはこの質問に対する私たちの回答のコレクションをこちらで共有しています。 Hugging Faceのコア価値である民主化に則り、私たちは多くの時間を公に話すことに費やしてきました。そしてAIの世界で今起こっていることを説明するためにジャーナリストと対話する機会を与えられています。これには以下のものが含まれます: サーシャのAIのエネルギー使用と炭素排出に関するコメント(The Atlantic、The Guardian、2回、New Scientist、The Weather Network、The Wall Street Journal、2回)およびWall Street Journal op-edの一部の執筆;AIの終末論的なリスクに対する考え(Bloomberg、The Times、Futurism、Sky…

「AIディープフェイクがスロバキアの選挙でのディスインフォメーション(誤報)を広める」
週末に行われたスロバキアの選挙前のソーシャルメディアでの拡散されたディスインフォメーションは、人工知能(AI)によって作られたディープフェイク音声をフィーチャーした動画です

「トップ5のAIウェブスクレイピングプラットフォーム」
データの重要性への認識は、その膨大な収集へとつながりました。最初のステップは、組織が作業を進め、潜在能力を活用するための基盤を生成します。多くの手法が使用されていますが、それらは課題と関連しています。さまざまな産業で効率的なAIベースの自動化が行われており、それがデータの収集やウェブサイトからの抽出に取り込まれています。これにより、コンセプトと関連するツールにも精通し、タスクが容易になります。以下は、AIウェブスクレイピングのための5つの実用的なツールの要約です。 AIウェブスクレイピングとは何ですか? ウェブスクレイピングとは、ウェブサイトからのデータ抽出を指します。このタスクは、人間による手動、AIによる自動、またはその両方を組み合わせたハイブリッドアプローチによって可能です。AIウェブスクレイピングは、完全に自動化されたウェブデータの抽出や収集を指します。従来のプログラミング言語に基づくウェブスクレイピングの能力不足を、動的なウェブサイトに自己調整することで補完します。これらのツールは、これらと多くの他のアクションを達成します。 Kadoa.com 2003年に最初にリリースされたKadoaは、自動スクロールやページネーション、詳細ページの抽出、変更通知などの機能を持っています。このAIツールは、コーディングに依存せずに、ビデオ、テキスト、画像などのデータタイプをカテゴリー別にスクレイピングすることでユーザーを魅了します。取得したデータはJSON、Excel、CSV形式で保存することができます。Kadoaは、パターン認識のために生成AIを使用し、変更するウェブサイトからのデータ抽出に適しています。 Kadoaは、目的のウェブサイトのURLを入力すると動作します。データ、スケジュール、ソースを定義し、AIによってスクレイパーを生成し、ウェブサイトの変更に応じて適応します。正確さを確保しながら、データは希望の出力形式でさらに取得されます。データ抽出ワークフローの構成機能との統合設備により、ユーザーは楽々とタスクを実行することができます。Kadoa.comは、さまざまなビジネスニーズや財務支援に適しています。 価格: 14日間の無料トライアル セルフサービス: 月額39ドル エンタープライズ: カスタム 公式ウェブサイトはこちらをご覧ください。 Nimbleway API 別のAIウェブスクレイピングプラットフォームは、APIとして利用でき、統合設備が備わっています。Ruby、Python、JavaScriptなど、複数のプログラミング言語での機能を利用すると、統合が容易になります。このツールは、ビジネススケールに関係なく、複雑なウェブスクレイピングのタスクを処理し、データパイプラインを効率化することができます。高速性を誇り、ユーザーのワークフローに影響を与えずに、どのウェブソースにも対応しています。 このプラットフォームでは、テキストウェブ形式、画像、PDFなどのさまざまな形式からの簡単な抽出のために、自然言語処理(NLP)、機械学習(ML)アルゴリズム、および光学文字認識(OCR)などの技術を使用しています。ユーザーフレンドリーなインターフェースは、柔軟な配信方法で構造化されたデータを生成し、さまざまなビジネスニーズを満たします。 価格: エッセンシャル: 月額255ドル アドバンスド: 月額595ドル プロフェッショナル: 月額935ドル…

「Amazon EUデザインと建設のためにAmazon SageMakerで動作する生成AIソリューション」
アマゾンEUデザイン・コンストラクション(Amazon D&C)チームは、ヨーロッパとMENA地域全体でアマゾン倉庫を設計・建設するエンジニアリングチームですプロジェクトの設計と展開のプロセスには、アマゾンとプロジェクト固有のガイドラインに関するエンジニアリング要件についての情報リクエスト(RFI)の多くの種類が含まれますこれらのリクエストは、基本ラインの取得から簡単なものから始まります [...]

機械学習エンジニアのためのLLMOps入門ガイド
イントロダクション OpenAIのChatGPTのリリースは、大規模言語モデル(LLM)への関心を高め、人工知能について誰もが話題にしています。しかし、それは単なる友好的な会話だけではありません。機械学習(ML)コミュニティは、LLMオプスという新しい用語を導入しました。私たちは皆、MLOpsについて聞いたことがありますが、LLMOpsとは何でしょうか。それは、これらの強力な言語モデルをライフサイクル全体で扱い管理する方法に関するものです。 LLMは、AI駆動の製品の作成と維持方法を変えつつあり、この変化が新しいツールやベストプラクティスの必要性を引き起こしています。この記事では、LLMOpsとその背景について詳しく解説します。また、LLMを使用してAI製品を構築する方法が従来のMLモデルと異なる点も調査します。さらに、これらの相違によりMLOps(機械学習オペレーション)がLLMOpsと異なる点も見ていきます。最後に、LLMOpsの世界で今後期待されるエキサイティングな展開について討論します。 学習目標: LLMOpsとその開発についての理解を深める。 例を通じてLLMOpsを使用してモデルを構築する方法を学ぶ。 LLMOpsとMLOpsの違いを知る。 LLMOpsの将来の展望を一部垣間見る。 この記事はデータサイエンスブロガソンの一環として公開されました。 LLMOpsとは何ですか? LLMOpsは、Large Language Model Operationsの略であり、MLOpsと似ていますが、特に大規模言語モデル(LLM)向けに設計されたものです。開発から展開、継続的なメンテナンスまで、LLMを活用したアプリケーションに関連するすべての要素を処理するために、新しいツールとベストプラクティスを使用する必要があります。 これをよりよく理解するために、LLMとMLOpsの意味を解説します: LLMは、人間の言語を生成できる大規模言語モデルです。それらは数十億のパラメータを持ち、数十億のテキストデータで訓練されます。 MLOps(機械学習オペレーション)は、機械学習によって動力を得るアプリケーションのライフサイクルを管理するために使用されるツールやプラクティスのセットです。 これで基本的な説明ができたので、このトピックをもっと詳しく掘り下げましょう。 LLMOpsについての話題とは何ですか? まず、BERTやGPT-2などのLLMは2018年から存在しています。しかし、ChatGPTが2022年12月にリリースされたことで、LLMOpsのアイデアにおいて著しい盛り上がりを目の当たりにするのは、ほぼ5年後のことです。 それ以来、私たちはLLMのパワーを活用したさまざまなタイプのアプリケーションを見てきました。これには、ChatGPTなどのお馴染みのチャットボットから(ChatGPTなど)、編集や要約のための個人用のライティングアシスタント(Notion AIなど)やコピーライティングのためのスキルを持ったもの(Jasperやcopy.aiなど)まで含まれます。また、コードの書き込みやデバッグのためのプログラミングアシスタント(GitHub Copilotなど)、コードのテスト(Codium AIなど)、セキュリティのトラブルの特定(Socket…

「LangChain、Google Maps API、Gradioを使用してスマートな旅行スケジュール案内ツールを作る(パート1)」
2022年の後半にChatGPTがリリースされて以来、大規模な言語モデル(LLM)とそれらの応用に対する興味が、チャットボットや検索などの消費者向け製品において爆発的に増えてきました...

ラングチェーン101:パート2ab (大規模な言語)モデルについて知っておくべきすべて
(次を見逃さないように、著者をフォローしてください...」

アマゾンセージメーカーでのLlama 2のベンチマーク
大型言語モデル(LLM)や他の生成型AIモデルの展開は、計算要件とレイテンシのニーズのために課題となることがあります。Hugging Face LLM Inference Containerを使用してAmazon SageMaker上でLlama 2を展開する企業に有用な推奨事項を提供するために、Llama 2の60以上の異なる展開設定を分析した包括的なベンチマークを作成しました。 このベンチマークでは、さまざまなサイズのLlama 2をAmazon EC2インスタンスのさまざまなタイプでさまざまな負荷レベルで評価しました。私たちの目標は、レイテンシ(トークンごとのミリ秒)とスループット(秒あたりのトークン数)を測定し、次の3つの一般的なユースケースに最適な展開戦略を見つけることです: 最も費用対効果の高い展開:低コストで良好なパフォーマンスを求めるユーザー向け 最高のレイテンシ展開:リアルタイムサービスのレイテンシを最小限に抑えるための展開 最高のスループット展開:秒あたりの処理トークンを最大化するための展開 このベンチマークを公正かつ透明で再現可能なものにするために、使用したすべてのアセット、コード、データを共有しています: GitHubリポジトリ 生データ 処理済みデータのスプレッドシート 私たちは、顧客がLLMsとLlama 2を効率的かつ最適に自社のユースケースに使用できるようにしたいと考えています。ベンチマークとデータに入る前に、使用した技術と手法を見てみましょう。 Amazon SageMaker上のLlama 2のベンチマーク Hugging…
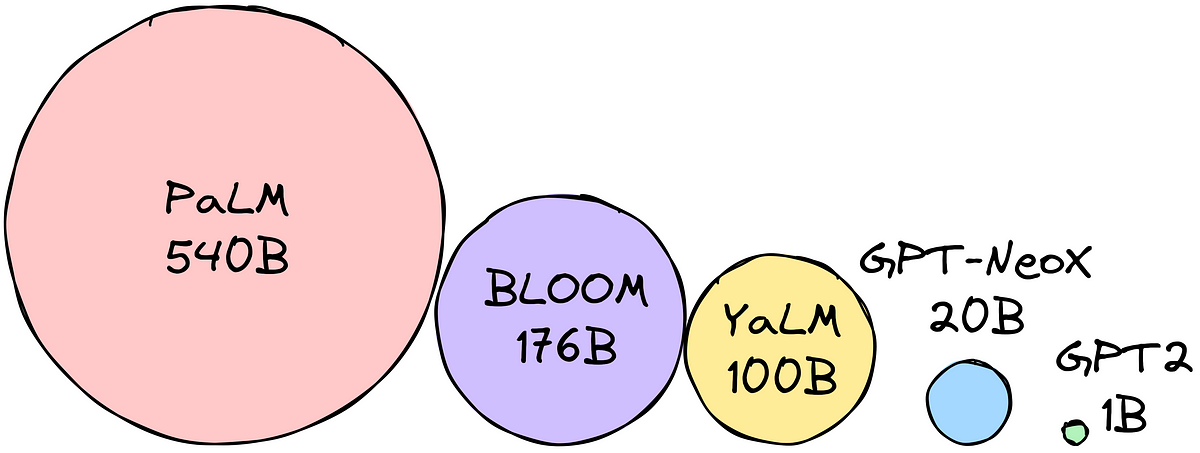
小さなメモリに大きな言語モデルを適合させる方法:量子化
大型言語モデルは、テキスト生成、翻訳、質問応答などのタスクに使用することができますしかし、LLM(大型言語モデル)は非常に大きく、多くのメモリを必要とします…

「修理の闘い」
「修理の権利を巡る闘いが消費者に有利に傾いている方法」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.