Learn more about Search Results Kubernetes - Page 7

- You may be interested
- lazy_staticを使用してランタイムでRustの...
- ソフトウェア開発におけるAIの将来:トレ...
- コンピュート最適な大規模言語モデルトレ...
- 「スロープ・トランスフォーマーに出会っ...
- 「オープンソースAI」の神話
- 「読むべき創造的エージェント研究論文」
- 「SSCCコンプライアンスによるトレース能...
- 「機械学習の探求」
- このNVIDIAのAI論文は、検索補完と長い文...
- AIにおける事実性の向上 このAI研究は、よ...
- 動的に画像のサイズを調整する
- 分子の言語を学び、その特性を予測する
- サリー大学の研究者が新しい人工知能(AI...
- 「パーティションを使用しよう、ルーク!S...
- 「最も価値のあるコードは、書くべきでな...

BentoML入門:統合AIアプリケーションフレームワークの紹介
この記事では、統合されたAIアプリケーションフレームワークであるBentoMLを使用して、機械学習モデルの展開を効率化する方法について探求します
「BentoML入門:統合AIアプリケーションフレームワーク」
この記事では、統合されたAIアプリケーションフレームワークであるBentoMLを使用して、機械学習モデルの展開を効率化する方法について探求します

「ODSC Europe 2023 キーノート:マイクロソフトのヘンク・ブーレマンによるAzureを用いたPyTorchモデルの展開」
「ODSC Europeのバーチャルプログラムの一環として、私たちはMicrosoftのシニアクラウドアドボケートであるヘンク・ブーレマン氏に基調講演をお願いする機会を得ましたヘンク氏の専門分野はAI、Azure、アプリケーション開発です彼はまた、経験豊富なスピーカーでもあり、ユーザーグループでの講演も行っています...」

Hugging FaceとGraphcoreがIPU最適化されたTransformersのために提携
2021年AIハードウェアサミットでの発表により、Hugging Faceはデバイス最適化モデルやソフトウェア統合を含む新しいハードウェアパートナープログラムの開始を発表しました。ここでは、Intelligence Processing Unit(IPU)を開発したGraphcoreがプログラムの創設メンバーであり、Hugging Faceとのパートナーシップにより開発者が最新のTransformerモデルを簡単に高速化できるよう具体的な説明をしています。 GraphcoreとHugging Faceは、機械知能のパワーを利用するイノベーターにとって、手を取り合って作業を容易にするという共通の目標を持つ2つの企業です。 Hugging Faceのハードウェアパートナープログラムにより、Graphcoreシステムを使用して最新のTransformerモデルを展開し、Intelligence Processing Unit(IPU)に最適化されたモデルを最小限のコーディング複雑さで本番規模で使用することができます。 Intelligence Processing Unitとは何ですか? IPUは、GraphcoreのIPU-PODデータセンター計算システムを駆動するプロセッサです。この新しいタイプのプロセッサは、AIや機械学習の非常に特定の計算要件をサポートするように設計されています。細かい粒度の並列処理、低精度演算、スパース性の処理能力などがシリコンに組み込まれています。 GPUのようなSIMD/SIMTアーキテクチャを採用するのではなく、GraphcoreのIPUは大規模な並列処理を行うMIMDアーキテクチャを使用し、プロセッサコアの隣に超高帯域幅メモリをシリコンダイ上に配置しています。 この設計により、BERTやEfficientNetなどの最も人気のあるモデルや次世代のAIアプリケーションを実行する際に、高いパフォーマンスと新しいレベルの効率を実現します。 ソフトウェアは、IPUの機能を引き出す上で重要な役割を果たしています。GraphcoreのPoplar SDKは、Graphcoreの創設以来プロセッサと共同設計されています。現在は、PyTorchやTensorFlowなどの標準の機械学習フレームワーク、およびDockerやKubernetesなどのオーケストレーションや展開ツールと完全に統合されています。 広く使用されているこれらのサードパーティシステムとの互換性を持つようにPoplarを作成することで、開発者は他の計算プラットフォームからモデルを簡単に移植し、IPUの高度なAI機能を利用できるようになります。 本番向けのTransformerの最適化 Transformerは、AIの分野を完全に変革しました。CamemBERT(フランス語)からNLPの知見をコンピュータビジョンに適用するViTまで、Hugging Faceではさまざまなアプリケーションで広く使用されています。これらのマルチタレントモデルは、特徴抽出、テキスト生成、感情分析、翻訳など、さまざまな機能を実行できます。 すでに、Hugging…

GraphcoreとHugging Faceが、IPU対応の新しいトランスフォーマーのラインアップを発表
GraphcoreとHugging Faceは、Hugging Face Optimumにおいて利用可能な機械学習のモダリティとタスクの範囲を大幅に拡張しました。Hugging Face Optimumは、Transformersのパフォーマンス最適化のためのオープンソースライブラリです。開発者は、GraphcoreのIPUで最高のパフォーマンスを提供するように最適化された幅広いHugging Face Transformerモデルに簡単にアクセスできるようになりました。 Optimum Graphcoreの発売後間もなく提供されたBERT Transformerモデルを含む、開発者は現在、自然言語処理(NLP)、音声、コンピュータビジョンをカバーする10のモデルにアクセスできます。これらのモデルには、IPUの設定ファイルと、事前学習および微調整済みのモデルの重みを使用するための準備が整っています。 新しいOptimumモデル コンピュータビジョン ViT(Vision Transformer)は、主要なコンポーネントとしてTransformerメカニズムを使用した画像認識の画期的な手法です。画像がViTに入力されると、言語システムで単語が処理されるのと同様に、画像は小さなパッチに分割されます。各パッチはTransformer(埋め込み)によってエンコードされ、個別に処理することができます。 NLP GPT-2(Generative Pre-trained Transformer 2)は、非常に大規模な英語のコーパスで自己教師付きの形式で事前学習されたテキスト生成Transformerモデルです。これは、テキストのラベリングを行わずに、公開されているデータを多く使用することができるため、自動的なプロセスでテキストから入力とラベルを生成することによって事前学習されました。より具体的には、文の次の単語を推測して文を生成するようにトレーニングされています。 RoBERTa(Robustly optimized BERT approach)は、自己教師付きの形式で大規模な英語のコーパスで事前学習されたTransformerモデルです(GPT-2と同様)。より具体的には、RoBERTaはマスクされた言語モデリング(MLM)の目的で事前学習されています。文を取り、モデルは入力の15%の単語をランダムにマスクし、全体のマスクされた文をモデルを通して実行し、マスクされた単語を予測する必要があります。RoBERTaはマスクされた言語モデリングに使用することができますが、主に下流タスクで微調整することを意図しています。…

TF Servingを使用してHugging FaceでTensorFlow Visionモデルを展開する
過去数ヶ月間、Hugging Faceチームと外部の貢献者は、TransformersにさまざまなビジョンモデルをTensorFlowで追加しました。このリストは包括的に拡大しており、ビジョントランスフォーマー、マスク付きオートエンコーダー、RegNet、ConvNeXtなど、最先端の事前学習モデルがすでに含まれています! TensorFlowモデルを展開する際には、さまざまな選択肢があります。使用ケースに応じて、モデルをエンドポイントとして公開するか、アプリケーション自体にパッケージ化するかを選択できます。TensorFlowには、これらの異なるシナリオに対応するツールが用意されています。 この投稿では、TensorFlow Serving(TF Serving)を使用してローカルでビジョントランスフォーマーモデル(画像分類用)を展開する方法を紹介します。これにより、開発者はモデルをRESTエンドポイントまたはgRPCエンドポイントとして公開できます。さらに、TF Servingはモデルのウォームアップ、サーバーサイドバッチ処理など、多くの展開固有の機能を提供しています。 この投稿全体で示される完全な動作するコードを取得するには、冒頭に示されているColabノートブックを参照してください。 🤗 TransformersのすべてのTensorFlowモデルには、save_pretrained()というメソッドがあります。このメソッドを使用すると、モデルの重みをh5形式およびスタンドアロンのSavedModel形式でシリアライズできます。TF Servingでは、モデルをSavedModel形式で提供する必要があります。そこで、まずビジョントランスフォーマーモデルをロードして保存します。 from transformers import TFViTForImageClassification temp_model_dir = "vit" ckpt = "google/vit-base-patch16-224" model = TFViTForImageClassification.from_pretrained(ckpt)…

プライベートハブのご紹介:機械学習を活用した新しいビルド方法
機械学習は、企業が技術を構築する方法を変えつつあります。革新的な新製品のパワーを供給し、私たちが使い慣れて愛している既知のアプリケーションにスマートな機能を提供することから、MLは開発プロセスの中心にあります。 しかし、すべての技術の変化には新たな課題が伴います。 機械学習モデルの約90%が本番環境に到達しないとされています。馴染みのないツールや非標準的なワークフローがMLの開発を遅くしています。モデルやデータセットが内部で共有されないため、同じような成果物がチーム間で常にゼロから作成されます。データサイエンティストは、ビジネスステークホルダーに技術的な作業を示すのが難しく、正確でタイムリーなフィードバックを共有するのに苦労しています。そして、機械学習チームはDocker/Kubernetesや本番環境向けのモデル最適化に時間を浪費しています。 これらを考慮して、私たちはPrivate Hub(PH)を立ち上げました。機械学習の構築方法を革新する新しい方法です。研究から本番環境まで、セキュアかつコンプライアンスを確保しながら、機械学習ライフサイクルの各ステップを加速するための統合されたツールセットを提供します。PHはさまざまなMLツールを一つにまとめることで、機械学習の協力をよりシンプルで楽しく、生産的にします。 このブログ投稿では、Private Hubとは何か、なぜ役立つのか、そしてどのようにお客様がそれを使用してMLのロードマップを加速しているのかについて詳しく説明します。 一緒に読んでいただくか、興味を引くセクションにジャンプしてください 🌟: ハグフェースハブとは何ですか? プライベートハブとは何ですか? 企業はプライベートハブをどのように使用してMLのロードマップを加速しているのでしょうか? さあ、始めましょう! 🚀 1. ハグフェースハブとは何ですか? プライベートハブについて詳しく説明する前に、まずハグフェースハブについて見てみましょう。これはPHの中心的な要素です。 ハグフェースハブは、オープンソースで公開されているオンラインプラットフォームで、人々が簡単に協力してMLを構築できる場所です。ハブは、機械学習と一緒に技術を探求し、実験し、協力し、構築するための中心的な場所として機能します。 ハグフェースハブでは、次のようなMLアセットを作成または発見することができます: モデル:NLP、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などの最新の最先端モデルをホスティング。 データセット:さまざまなドメイン、モダリティ、言語に対応したデータの幅広いバリエーション。 スペース:ブラウザ内で直接MLモデルをショーケースするインタラクティブなアプリ。 ハブにアップロードされた各モデル、データセット、またはスペースは、Gitベースのリポジトリです。これはすべてのファイルを含むバージョン管理された場所で、従来のgitコマンドを使用してファイルをプル、プッシュ、クローン、操作することができます。モデル、データセット、およびスペースのコミット履歴を表示し、誰がいつ何を行ったかを確認することができます。 モデルのコミット履歴…
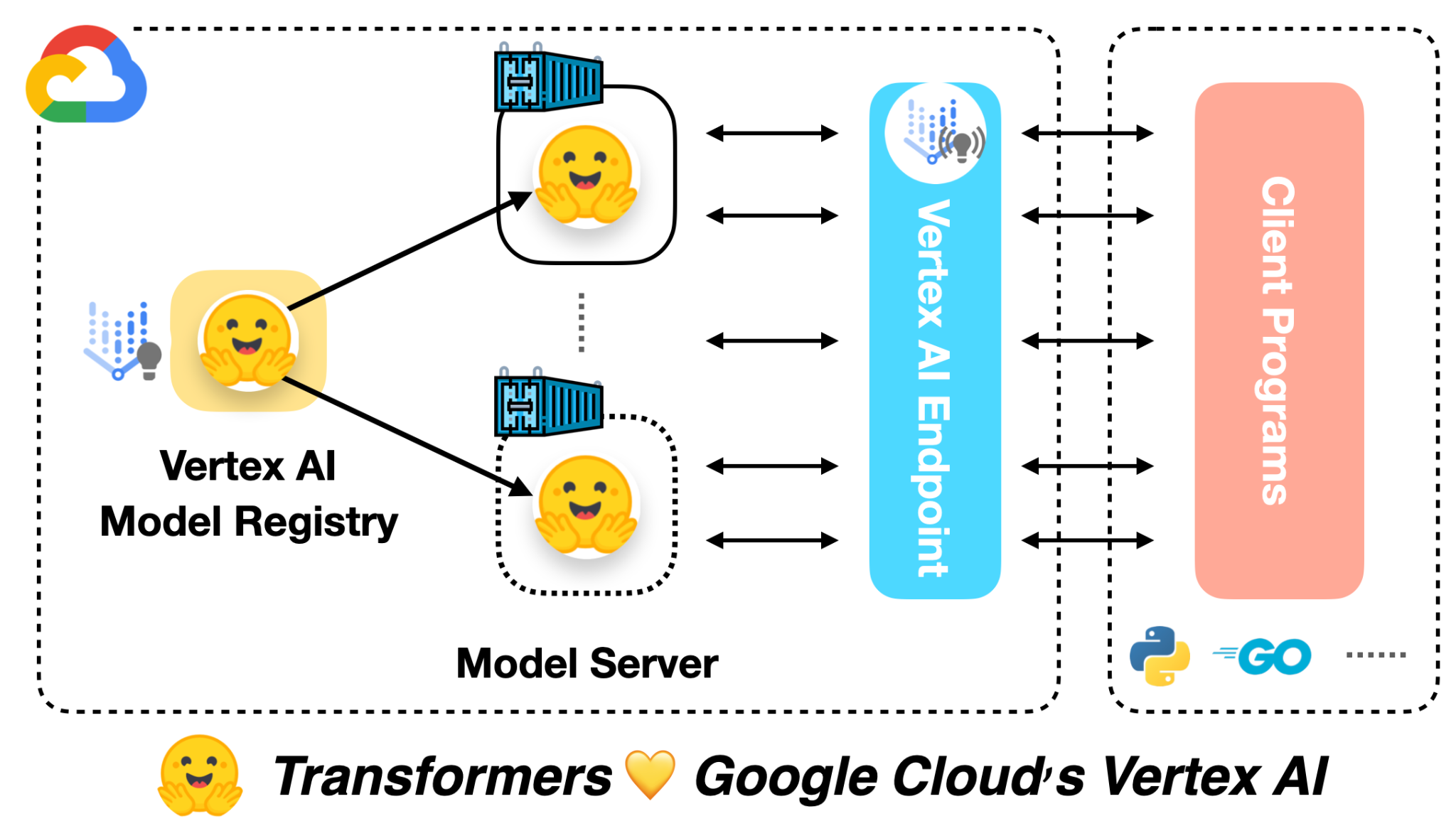
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

ハギングフェイスにおけるコンピュータビジョンの状況 🤗
弊社の自慢は、コミュニティとともに人工知能の分野を民主化することです。その使命の一環として、私たちは過去1年間でコンピュータビジョンに注力し始めました。🤗 Transformersにビジョントランスフォーマー(ViT)を含めるというPRから始まったこの取り組みは、現在では8つの主要なビジョンタスク、3000以上のモデル、およびHugging Face Hub上の100以上のデータセットに成長しました。 ViTがHubに参加して以来、多くのエキサイティングな出来事がありました。このブログ記事では、コンピュータビジョンの持続的な進歩をサポートするために何が起こったのか、そして今後何がやってくるのかをまとめます。 以下は、カバーする内容のリストです: サポートされているビジョンタスクとパイプライン 独自のビジョンモデルのトレーニング timmとの統合 Diffusers サードパーティーライブラリのサポート デプロイメント その他多数! コミュニティの支援:一つずつのタスクを可能にする 👁 Hugging Face Hubは、次の単語予測、マスクの埋め込み、トークン分類、シーケンス分類など、さまざまなタスクのために10万以上のパブリックモデルを収容しています。現在、我々は8つの主要なビジョンタスクをサポートし、多くのモデルチェックポイントを提供しています: 画像分類 画像セグメンテーション (ゼロショット)オブジェクト検出 ビデオ分類 奥行き推定 画像から画像への合成…

リアルワールドのMLOpsの例:Brainlyでのビジュアル検索のためのエンドツーエンドのMLOpsパイプライン
シリーズ「実世界のMLOpsの例」の第2回目では、Brainlyの機械学習エンジニアであるPaweł Pęczekが、Brainlyのビジュアル検索チームにおけるエンドツーエンドの機械学習オペレーション(MLOps)プロセスを詳しく説明しますそして、MLOpsで成功するためには、技術やプロセスだけではなく、さらに詳細な情報を共有します Enjoy...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.