Learn more about Search Results ImageNet - Page 7

- You may be interested
- 「AIは善良な存在です:その理由」
- 「NVIDIAがAIおよびHPCワークロードに特化...
- テキストと画像の検索を行うNodeJS AIアプ...
- 声サンプルデータ分析を使用したパーキン...
- A/Bテストを超えたアプローチで戦略を最適...
- 『責任ある生成AIの基準の確立』
- 「Googleのおかげで、ロボットにとっての...
- 「LLaMaTabに会おう:ブラウザ内で完全に...
- 「LoRAとQLoRAを用いた大規模言語モデルの...
- 「Pythonを使用した地理空間データの分析...
- 「2023年に試してみるべき20の中間旅行の...
- このAI研究は、AstroLLaMAを紹介しますこ...
- LLM(Language Model)をアプリケーション...
- 『LLM360をご紹介します:最初の完全オー...
- 量子コンピューティングが薬物探索にどの...
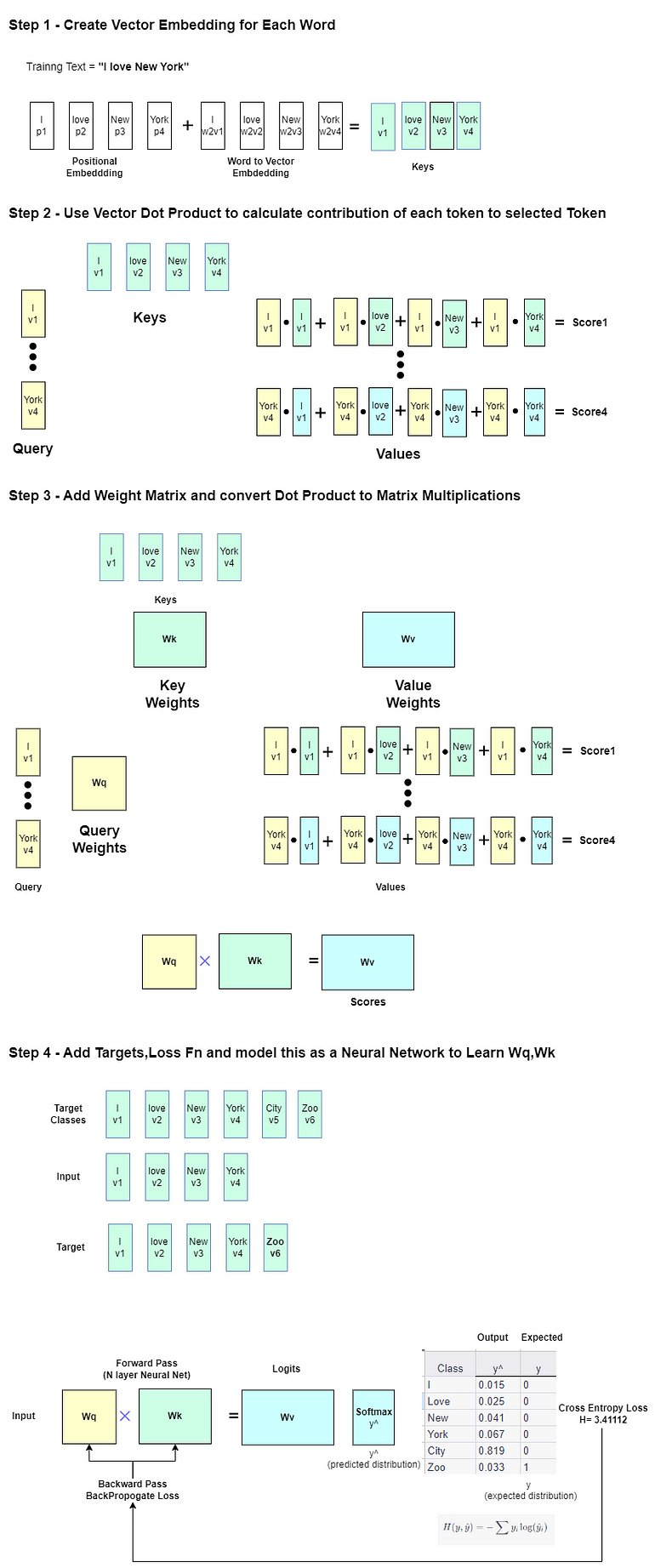
大規模言語モデルの探索 -Part 1
この記事は主に自己学習のために書かれていますそのため、広範囲かつ深い内容です興味のあるセクションをスキップしたり、自分が興味を持っている分野を探求するために、自由に特定のセクションをスキップしてください以下にいくつかの…

「セマンティックカーネルへのPythonistaのイントロ」
ChatGPTのリリース以来、大規模言語モデル(LLM)は産業界とメディアの両方で非常に注目されており、これによりLLMを活用しようとする前例のない需要が生まれました...
「マルチタスクアーキテクチャ:包括的なガイド」
多くのタスクを実行するためにニューラルネットワークを訓練することは、マルチタスク学習として知られていますこの投稿では、複数の密な計算ビジョンタスクを実行するモデルを訓練します

「VoAGI創設者グレゴリー・ピアテツキーシャピロとの30周年記念インタビュー」
グレゴリー・ピアテツキー・シャピロは、30年前に知識発見に関する初期のワークショップを組織した後、VoAGIを設立しましたこの回顧的なインタビューでは、彼はVoAGIの成長、ディープラーニングなどの重要なイノベーション、AIの社会的影響への懸念について振り返っています

このAI研究は、深層学習システムが継続的な学習環境で使用される際の「可塑性の喪失」という問題に取り組んでいます
現代の深層学習アルゴリズムは、トレーニングが一度だけ行われるかなりのデータ収集に焦点を当てています。声の認識や画像の分類における深層学習の初期の成功例は、すべてこのような一度だけのトレーニング設定を使用していました。リプレイバッファとバッチ処理は、深層学習が強化学習に適用される場合に後から追加され、トレーニングがほぼ一度だけの設定に非常に近くなりました。GPT-3やDallEのような最新の深層学習システムのトレーニングにも大量のデータバッチが使用されました。これらの状況で最も一般的なアプローチは、データを継続的に収集し、トレーニング構成で定期的に新しいネットワークを作成することです。もちろん、多くのアプリケーションではデータ分布が時間とともに変化し、トレーニングを継続する必要があります。現代の深層学習技術は、一度だけのトレーニング設定を念頭に開発されました。 これに対して、永続的な学習問題設定は、新鮮なデータからの継続的な学習に焦点を当てています。継続的な学習オプションは、学習システムが動的なデータストリームに対処しなければならない問題に最適です。たとえば、家の中を動き回るロボットを考えてみてください。一度だけのトレーニング設定を使用すると、家のレイアウトが変更されるたびにロボットをゼロから再トレーニングするか、無用の危険にさらすことになります。定期的にデザインが変更される場合は、ゼロから再トレーニングする必要があります。一方、ロボットは新しい情報から簡単に学習し、継続的な学習シナリオの下で家の変化に常に適応することができます。最近、生涯学習の重要性が高まり、これに対応するためのより専門的な会議が開催されています。例えば、Life-long Learning Agents Conference(CoLLAS)です。 彼らは自分たちのエッセイで継続的な学習の環境に重点を置いています。新鮮なデータにさらされると、深層学習システムは以前に学んだもののほとんどを失ってしまう、これを「壊滅的な忘却」と呼ぶ状態です。言い換えれば、深層学習の技術は継続的な学習の問題では安定性を維持しません。1900年代後半に、初期のニューラルネットワークがこのような振る舞いを最初に示しました。「壊滅的な忘却」による安定性の保持についての深層継続学習に関しては、最近多くの記事が書かれています。 新しい仕事が提供されると、ネットワークの設定には新しい出力、つまりヘッドが追加され、タスクが増えるにつれて出力の数も増えていきます。そのため、古いヘッドからの干渉の効果がプラスチシティの喪失の結果と混同されることがあります。Chaudhryらによると、新しいタスクの開始時に古いヘッドが取り除かれた場合、プラスチシティの喪失はわずかであり、彼らが見たプラスチシティの喪失の主な原因は古いヘッドからの干渉であることを示唆しています。以前の研究者が10の課題しか使用しなかったため、深層学習技術が長い課題リストに直面した場合のプラスチシティの喪失を測定することはできませんでした。 これらの論文の結果は、深層学習システムが重要な適応性の一部を失っていることを示唆していますが、誰もが継続的な学習がプラスチシティを失っているとまだ示していません。最近の作品でプラスチシティの喪失が著しいと示されている強化学習の分野では、現代の深層学習におけるプラスチシティの喪失の証拠がより多く存在します。Nishikinらは、強化学習の問題における初期学習が後の学習に否定的な影響を与えることを示し、「プライマシーバイアス」という用語を提唱しました。 方針の変更による結果として、強化学習は基本的に連続的であり、この結果は学習が継続する場合に深層学習ネットワークが柔軟性を失っている可能性があります。また、Lyleらは、一部の深層強化学習エージェントが新しいスキルを獲得する能力を最終的に失う可能性があることを示しました。これらは重要なデータポイントですが、現代の深層強化学習の複雑さのため、明確な結論を出すことは容易ではありません。これらの研究は、心理学の文献や機械学習、強化学習の最新の研究を含めています。本研究では、アルバータ大学コンピュータ科学部およびCIFAR AIチェア、アルバータマシンインテリジェンス研究所の研究者が現代の深層学習におけるプラスチシティの喪失についてより結論的な回答を提供します。 彼らは、持続的な教師あり学習の問題が深層学習のアプローチに柔軟性を失わせ、この柔軟性の喪失が深刻であることを示しています。ImageNetデータセットを使用した連続的な教師あり学習の問題を数百回の学習試行を含めて行い、深層学習が柔軟性の喪失に悩んでいることを最初に示します。強化学習において常に発生する複雑性と関連する混乱は、代わりに教師あり学習のタスクを使用することで排除されます。何百ものタスクを持っているおかげで、柔軟性の喪失の完全な量も把握することができます。彼らは次に、MNISTの変形とゆっくり変化する回帰問題という2つの計算コストの低い問題を使用して、深層学習の柔軟性の欠如の普遍性を証明します。さらに、深層学習の柔軟性の喪失の重大性と一般性を示した後、その起源をより深く理解したいとしています。

深層学習フレームワークの比較
「開発者に最適なトップのディープラーニングフレームワークを見つけてください機能、パフォーマンス、使いやすさを比較して、AIのコーディングの旅を最適化してください」
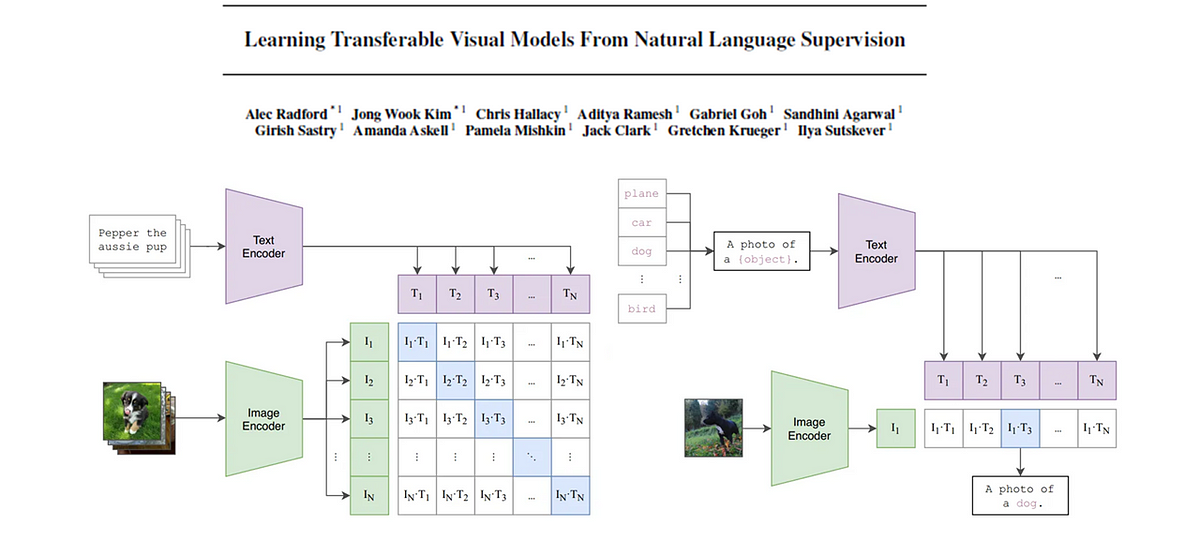
CLIP基礎モデル
この記事では、CLIP(対照的な言語画像事前学習)の背後にある論文を詳しく解説しますキーコンセプトを抽出し、わかりやすく解説しますさらに、画像...
「より良い機械学習システムの構築 – 第3章:モデリング楽しみが始まります」
こんにちは、お帰りなさいまたここでお会いできてうれしいですあなたがもっと良いプロフェッショナルになりたいという意欲、より良い仕事をしたいという願望、そしてより良いMLシステムを構築したいということを本当に感謝していますあなたは素晴らしいです、これからも頑張ってください!このシリーズでは、私は...

エッジにおける生涯学習
「忘れない方法を学ぶことは重要なスキルです」
「非構造化データ内のデータスライスの検出」 翻訳結果は以下の通りです: 「非構造化データ内でデータスライスを見つける」
データスライスは、モデルが異常な動作をするデータの意味のあるサブセットです非構造化データの問題(例:画像、テキスト)に取り組む際に、これらのスライスを見つけることは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.