Learn more about Search Results Gin - Page 7

- You may be interested
- 「Githubの使い方?ステップバイステップ...
- 最も近い近隣法を用いた写真モザイク:デ...
- 「たった1行のコードで、Optimum-NVIDIAが...
- Cox回帰の隠されたダークシークレット:Co...
- BScの後に何をすべきか?トップ10のキャリ...
- 「機械学習における確率的要素の本質を明...
- 情報抽出の始まり:キーワードを強調し、...
- Googleはチャットボットの使用について従...
- 「生成AIを通じて脆弱性を明らかにする」
- 「読むべき創造的エージェント研究論文」
- ネットワークの強化:異常検知のためのML...
- 「UBCと本田技研が、敏感なロボット用の革...
- 「アメリカでデータアナリストになる方法」
- 新しいGoogle AI研究では、ペアワイズラン...
- NVIDIA AIがSteerLMを発表:大規模言語モ...

Hugging Face HubでのSentence Transformers
過去数週間、私たちは機械学習エコシステム内の多くのオープンソースフレームワークと協力関係を築いてきました。特に私たちが興奮しているのは、Sentence Transformersです。 Sentence Transformersは、文、段落、画像の埋め込みのためのフレームワークです。これにより、意味のある埋め込みを導出することができます(1)。これは、意味検索や多言語ゼロショット分類などのアプリケーションに役立ちます。Sentence Transformers v2のリリースの一環として、たくさんのクールな新機能があります: ハブでモデルを簡単に共有することができます。 文の埋め込みと文の類似性のためのウィジェットおよび推論API。 より優れた文の埋め込みモデルが利用可能になりました(ベンチマークとハブ内のモデル)。 ハブには、100以上の言語の90以上の事前学習済みSentence Transformersモデルがあり、誰でもそれらを利用し、簡単に使用することができます。事前学習済みモデルは、数行のコードで直接ロードして使用できます: from sentence_transformers import SentenceTransformer sentences = ["Hello World", "Hallo Welt"] model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L6-v2')…

Amazon SageMakerを使用して、Hugging Faceモデルを簡単にデプロイできます
今年早くも、Hugging FaceをAmazon SageMakerで利用しやすくするためにAmazonとの戦略的な協力を発表し、最先端の機械学習機能をより速く提供することを目指しています。新しいHugging Face Deep Learning Containers (DLCs)を導入し、Amazon SageMakerでHugging Face Transformerモデルをトレーニングすることができます。 今日は、Amazon SageMakerでHugging Face Transformersを展開するための新しい推論ソリューションを紹介します!新しいHugging Face Inference DLCsを使用すると、トレーニング済みモデルをわずか1行のコードで展開できます。また、Model Hubから10,000以上の公開モデルを選択し、Amazon SageMakerで展開することもできます。 SageMakerでモデルを展開することで、AWS環境内で簡単にスケーリング可能な本番用エンドポイントが提供されます。モニタリング機能やエンタープライズ向けの機能も組み込まれています。この素晴らしい協力を活用していただければ幸いです! 以下は、新しいSageMaker Hugging Face…

Hugging Face Hubへようこそ、spaCyさん
spaCyは、産業界で広く使用される高度な自然言語処理のための人気のあるライブラリです。spaCyを使用すると、固有表現認識、テキスト分類、品詞タグ付けなどのタスクのためのパイプラインの使用とトレーニングが容易になり、大量のテキストを処理して分析する強力なアプリケーションを構築できます。 Hugging Faceを使用すると、spaCyパイプラインをコミュニティと簡単に共有できます!単一のコマンドで、モデルカードが含まれ、必要なメタデータが自動生成されたパイプラインパッケージをアップロードできます。推論APIは現在、固有表現認識(NER)をサポートしており、パイプラインをブラウザで対話的に試すことができます。また、パッケージ用のライブURLも提供されるため、プロトタイプから本番環境までのスムーズなパスでどこからでもpip installできます! モデルの検索 spaCy orgには、60以上のカノニカルモデルがあります。これらのモデルは最新の3.1リリースからのものであり、最新のリリースモデルをすぐに試すことができます!さらに、コミュニティからのすべてのspaCyモデルはここで見つけることができます:https://huggingface.co/models?filter=spacy。 ウィジェット この統合にはNERウィジェットのサポートも含まれており、NERコンポーネントを持つすべてのモデルは、デフォルトでこれを備えています!近日中に、テキスト分類や品詞タグ付けのサポートも追加されます。 既存のモデルの使用 Hubからのすべてのモデルは、pip installを使用して直接インストールすることができます。 pip install https://huggingface.co/spacy/en_core_web_sm/resolve/main/en_core_web_sm-any-py3-none-any.whl # spacy.load()を使用する。 import spacy nlp = spacy.load("en_core_web_sm") # モジュールとしてインポートする。…

Hugging FaceとGraphcoreがIPU最適化されたTransformersのために提携
2021年AIハードウェアサミットでの発表により、Hugging Faceはデバイス最適化モデルやソフトウェア統合を含む新しいハードウェアパートナープログラムの開始を発表しました。ここでは、Intelligence Processing Unit(IPU)を開発したGraphcoreがプログラムの創設メンバーであり、Hugging Faceとのパートナーシップにより開発者が最新のTransformerモデルを簡単に高速化できるよう具体的な説明をしています。 GraphcoreとHugging Faceは、機械知能のパワーを利用するイノベーターにとって、手を取り合って作業を容易にするという共通の目標を持つ2つの企業です。 Hugging Faceのハードウェアパートナープログラムにより、Graphcoreシステムを使用して最新のTransformerモデルを展開し、Intelligence Processing Unit(IPU)に最適化されたモデルを最小限のコーディング複雑さで本番規模で使用することができます。 Intelligence Processing Unitとは何ですか? IPUは、GraphcoreのIPU-PODデータセンター計算システムを駆動するプロセッサです。この新しいタイプのプロセッサは、AIや機械学習の非常に特定の計算要件をサポートするように設計されています。細かい粒度の並列処理、低精度演算、スパース性の処理能力などがシリコンに組み込まれています。 GPUのようなSIMD/SIMTアーキテクチャを採用するのではなく、GraphcoreのIPUは大規模な並列処理を行うMIMDアーキテクチャを使用し、プロセッサコアの隣に超高帯域幅メモリをシリコンダイ上に配置しています。 この設計により、BERTやEfficientNetなどの最も人気のあるモデルや次世代のAIアプリケーションを実行する際に、高いパフォーマンスと新しいレベルの効率を実現します。 ソフトウェアは、IPUの機能を引き出す上で重要な役割を果たしています。GraphcoreのPoplar SDKは、Graphcoreの創設以来プロセッサと共同設計されています。現在は、PyTorchやTensorFlowなどの標準の機械学習フレームワーク、およびDockerやKubernetesなどのオーケストレーションや展開ツールと完全に統合されています。 広く使用されているこれらのサードパーティシステムとの互換性を持つようにPoplarを作成することで、開発者は他の計算プラットフォームからモデルを簡単に移植し、IPUの高度なAI機能を利用できるようになります。 本番向けのTransformerの最適化 Transformerは、AIの分野を完全に変革しました。CamemBERT(フランス語)からNLPの知見をコンピュータビジョンに適用するViTまで、Hugging Faceではさまざまなアプリケーションで広く使用されています。これらのマルチタレントモデルは、特徴抽出、テキスト生成、感情分析、翻訳など、さまざまな機能を実行できます。 すでに、Hugging…

Streamlitを使用して、Hugging Face Spacesにモデルとデータセットをホスティングする
Streamlitを使用してHugging Face Spacesでデータセットとモデルを紹介する Streamlitを使用すると、データセットを視覚化し、機械学習モデルのデモをきれいに構築することができます。このブログ記事では、モデルとデータセットのホスティング、およびHugging Face SpacesでのStreamlitアプリケーションの提供方法をご紹介します。 モデルのデモを作成する Hugging Faceのモデルを読み込んで、Streamlitを使用してクールなUIを構築することができます。この具体的な例では、「Write with Transformer」を一緒に再現します。GPT-2やXLNetなどのtransformerを使用して何でも書けるアプリケーションです。 推論の仕組みについては詳しく触れません。ただし、この特定のアプリケーションにはいくつかのハイパーパラメータ値を指定する必要があることを知っておく必要があります。Streamlitには、カスタムアプリケーションを簡単に実装できる多くのコンポーネントが提供されています。必要なハイパーパラメータを推論コード内で受け取るために、それらの一部を使用します。 .text_areaコンポーネントは、入力する文章を受け入れるための素敵なエリアを作成します。 Streamlitの.sidebarメソッドを使用すると、サイドバーで変数を受け入れることができます。 sliderは連続値を取るために使用されます。ステップを指定しない場合、値は整数として扱われますので、忘れずにステップを指定してください。 number_inputを使用すると、エンドユーザーに整数値の入力をさせることができます。 import streamlit as st # テキストボックスに表示されるデフォルトのテキストを追加 default_value =…
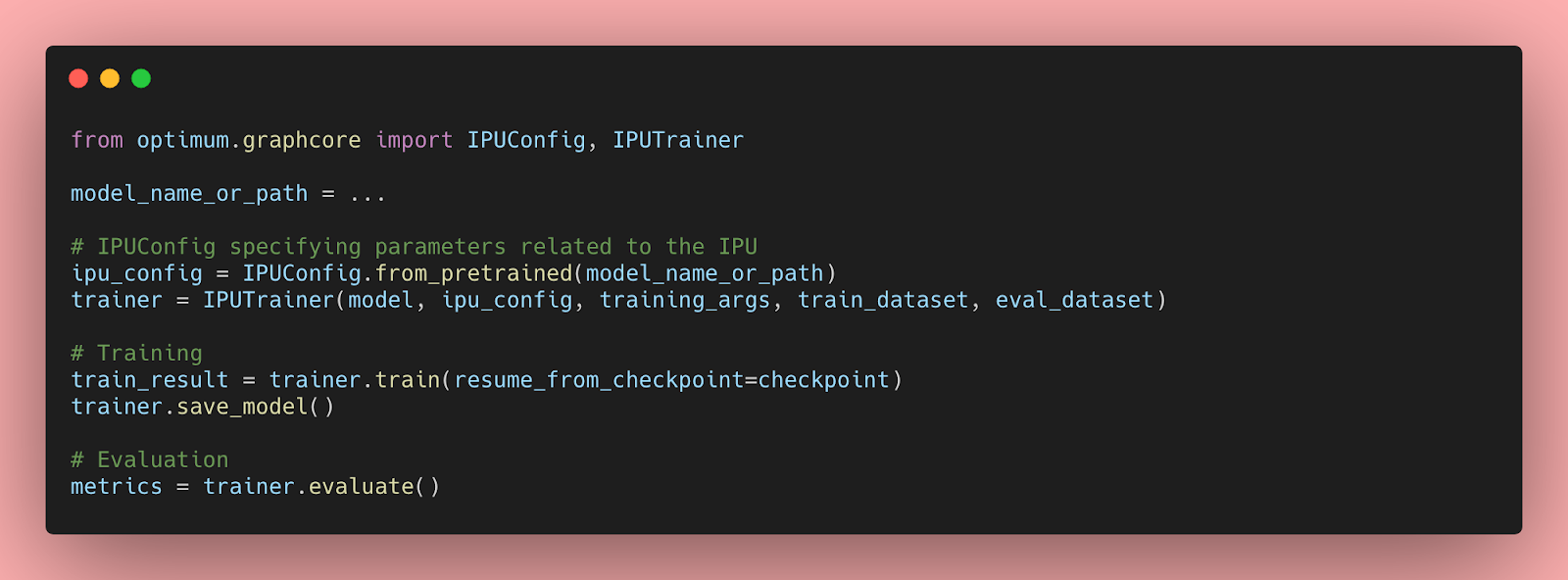
IPUを使用したHugging Face Transformersの始め方と最適化について
Transformerモデルは、自然言語処理、音声処理、コンピュータビジョンなど、さまざまな機械学習タスクで非常に効率的であることが証明されています。しかし、これらの大規模なモデルの予測速度は、会話型アプリケーションや検索などのレイテンシに敏感なユースケースでは実用的ではありません。さらに、実世界でのパフォーマンスを最適化するには、多くの企業や組織には到底手の届かない時間、労力、スキルが必要です。 幸いなことに、Hugging FaceはOptimumというオープンソースのライブラリを導入しました。このライブラリを使用すると、さまざまなハードウェアプラットフォーム上でTransformerモデルの予測レイテンシを大幅に削減することが容易になります。このブログ記事では、AIワークロードに最適化されたGraphcore Intelligence Processing Unit(IPU)向けにTransformerモデルを高速化する方法を学びます。 OptimumがGraphcore IPUと出会う GraphcoreとHugging Faceのパートナーシップにより、最初のIPUに最適化されたモデルとしてBERTが導入されました。今後数ヶ月にわたり、ビジョン、音声、翻訳、テキスト生成など、さまざまなアプリケーションに対応したIPUに最適化されたモデルをさらに導入していく予定です。 Graphcoreのエンジニアは、Hugging Faceのトランスフォーマーを使用してBERTをIPUシステムに実装し、最新のモデルを簡単にトレーニング、微調整、高速化できるように最適化しました。 IPUとOptimumの始め方 OptimumとIPUの使用を始めるために、BERTを例にして説明します。 このガイドでは、Graphcoreのクラウドベースの機械学習プラットフォームであるGraphcloudのIPU-POD16システムを使用し、Getting Started with Graphcloud のPyTorchのセットアップ手順に従います。 GraphcloudサーバーにはすでにPoplar SDKがインストールされています。別のセットアップを使用している場合は、PyTorch for the IPU:…

GradioがHugging Faceに参加します!
GradioはHugging Faceに参加します! Gradioは機械学習のスタートアップを買収することにより、Hugging Faceはユーザー、開発者、データサイエンティストが高いレベルの結果を得て、より良いモデルとツールを作成するために必要なツールを提供することができるようになります… えーと、上記のような買収に関する段落は非常に一般的であり、アルゴリズムがそれらを書くことができます。 実際、そうです!この最初の段落はAcquisition Post Generatorという、Hugging Face Spaces上の機械学習デモで書かれました。 あなた自身のブラウザで実行することができます。任意の2つの会社の名前を提供すれば、買収を発表する記事の始まりとして妥当なサウンディングを得ることができます! Acquisition Post Generatorは、私たちのオープンソースのGradioライブラリを使用して構築されました。これは、Hugging Faceとの最近のコラボレーションの1つにすぎません。そして、私は興奮して発表します…🥁 Hugging FaceがGradioを買収 することを(はい、最初の段落はアルゴリズムによって書かれたかもしれませんが、それは本当です!) Gradioの創設者の1人として、私たちの旅の次のステップについてはもっと興奮していることはありません。私は2019年にどのように始まったかをはっきりと覚えています。スタンフォード大学の博士課程生として、医師である私の1人の共同研究者と医療コンピュータビジョンモデルを共有するのに苦労しました。私は彼に私の機械学習モデルをテストしてもらう必要がありましたが、彼はPythonを知らず、独自の画像で簡単にモデルを実行することができませんでした。私は、機械学習エンジニアがコンピュータビジョンモデルのデモを簡単に構築して共有できるツールを想像しました。それによって、フィードバックが向上し、信頼性の高いモデルが生まれることになるのです🔁 私は才能あるルームメイトのAli Abdalla、Ali Abid、Dawood Khanを募集して、2019年に最初のバージョンのGradioをリリースしました。私たちはテキスト、音声、ビデオなど、さらなる機械学習の領域をカバーするように徐々に拡大しました。研究者だけでなく、スタートアップから公開企業まで、業界の異なる分野のチームが機械学習モデルを共有する必要があることがわかりました。Gradioはその両方に役立つことができます。私たちが最初にライブラリをリリースして以来、30万以上のデモがGradioで作成されました。私たちは、コントリビュータのコミュニティ、サポートしてくれる投資家、そして今年私たちの会社に参加した素晴らしいAhsen Khaliqの存在なしでは、これを実現することはできませんでした。…

Hugging Face Transformers と Amazon SageMaker を使用して、GPT-J 6B を推論のためにデプロイします
約6ヶ月前の今日、EleutherAIはGPT-3のオープンソースの代替となるGPT-J 6Bをリリースしました。GPT-J 6BはEleutherAIs GPT-NEOファミリーの6,000,000,000パラメータの後継モデルであり、テキスト生成のためのGPTアーキテクチャに基づくトランスフォーマーベースの言語モデルです。 EleutherAIの主な目標は、GPT-3と同じサイズのモデルを訓練し、オープンライセンスの下で一般の人々に提供することです。 過去6ヶ月間、GPT-Jは研究者、データサイエンティスト、さらにはソフトウェア開発者から多くの関心を集めてきましたが、実世界のユースケースや製品にGPT-Jを本番環境に展開することは非常に困難でした。 Hugging Face Inference APIやEleutherAIs 6b playgroundなど、製品ワークロードでGPT-Jを使用するためのホステッドソリューションはいくつかありますが、自分自身の環境に簡単に展開する方法の例は少ないです。 このブログ記事では、Amazon SageMakerとHugging Face Inference Toolkitを使用して、数行のコードでGPT-Jを簡単に展開する方法を学びます。これにより、スケーラブルで信頼性の高いセキュアなリアルタイムの推論が可能な通常サイズのNVIDIA T4(約500ドル/月)のGPUインスタンスを使用します。 しかし、それに入る前に、なぜGPT-Jを本番環境に展開するのが困難なのかを説明したいと思います。 背景 6,000,000,000パラメータモデルの重みは、約24GBのメモリを使用します。float32でロードするためには、少なくとも2倍のモデルサイズのCPU RAMが必要です。初期重みのために1倍、チェックポイントのロードのために1倍です。したがって、GPT-Jをロードするには少なくとも48GBのCPU RAMが必要です。 モデルをよりアクセス可能にするために、EleutherAIはfloat16の重みを提供しており、transformersには大規模な言語モデルのロード時のメモリ使用量を削減する新しいオプションがあります。これらすべてを組み合わせると、モデルのロードにはおおよそ12.1GBのCPU…

事例研究:Hugging Face InfinityとモダンなCPUを使用したミリ秒レイテンシー
はじめに 転移学習は、自然言語処理(NLP)から音声およびコンピュータビジョンのタスクまで、機械学習を新たな精度レベルに変えてきました。Hugging Faceでは、これらの新しい複雑なモデルと大規模なチェックポイントをできるだけ簡単にアクセス可能かつ利用可能にするために、努力して取り組んでいます。しかし、研究者やデータサイエンティストがTransformersの新しい世界に移行している一方で、これらの大規模で複雑なモデルを実稼働環境で大規模に展開することができる企業はほとんどありません。 主なボトルネックは、予測のレイテンシーであり、大規模な展開を実行するために高コストになり、リアルタイムのユースケースが実用的になりません。これを解決するには、どの機械学習エンジニアリングチームにとっても難しいエンジニアリング上の課題であり、ハードウェアまでモデルを最適化するための高度な技術の使用を必要とします。 Hugging Face Infinityでは、最も人気のあるTransformerモデルに対して、低レイテンシー、高スループット、ハードウェアアクセラレーションされた推論パイプラインを簡単に展開できるコンテナ化されたソリューションを提供しています。企業は、Transformersの精度と大容量展開に必要な効率性を、使いやすいパッケージで手に入れることができます。このブログ投稿では、最新世代のIntel Xeon CPU上で実行されるInfinityの詳細なパフォーマンス結果を共有したいと思います。 Hugging Face Infinityとは Hugging Face Infinityは、お客様が最新のTransformerモデルを最適化したエンドツーエンドの推論パイプラインを任意のインフラストラクチャ上で展開できるコンテナ化されたソリューションです。 Hugging Face Infinityには、2つの主要なサービスがあります: Infinityコンテナは、Dockerコンテナとして提供されるハードウェア最適化された推論ソリューションです。 Infinity Multiverseは、Hugging Face Transformerモデルをターゲットハードウェアに最適化するモデル最適化サービスです。Infinity MultiverseはInfinityコンテナと互換性があります。…

Hugging Face Hubへようこそ、Stable-baselines3さん🤗
私たちはHugging Faceで、深層強化学習の研究者や愛好家向けのエコシステムに貢献しています。そのため、私たちはStable-Baselines3をHugging Face Hubに統合したことをお知らせできることをうれしく思っています。 Stable-Baselines3は、最も人気のあるPyTorch深層強化学習ライブラリの1つであり、さまざまな環境(Gym、Atari、MuJoco、Procgenなど)でエージェントのトレーニングとテストを簡単に行うことができます。この統合により、保存されたモデルをホストできるようになり、コミュニティから強力なモデルをロードすることができます。 この記事では、その方法を紹介します。 インストール Hugging Face Hubでstable-baselines3を使用するには、次の2つのライブラリをインストールする必要があります。 pip install huggingface_hub pip install huggingface_sb3 モデルの検索 現在、Space Invaders、Breakout、LunarLanderなどをプレイするエージェントの保存されたモデルをアップロードしています。さらに、コミュニティからすべてのstable-baselines-3モデルをここで見つけることができます。 必要なモデルを見つけたら、リポジトリIDをコピーするだけです。 Hubからモデルをダウンロードする この統合の最もクールな機能は、HubからStable-baselines3に保存されたモデルを非常に簡単にロードできることです。 そのためには、保存されたモデルを含むリポジトリのrepo-idと、リポジトリ内の保存されたモデルzipファイルの名前をコピーする必要があります。 例えば、sb3/demo-hf-CartPole-v1…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.