Learn more about Search Results GLUE - Page 7

- You may be interested
- 小さなメモリに大きな言語モデルを適合さ...
- 「AIの使用を支持する俳優たちと、支持し...
- 「Saturn 大規模な言語モデルおよびその他...
- ChatGPTを使って旅行のスケジュールを計画...
- 誰が雨を止めるのか? 科学者が気候協力を...
- 「LlamaIndex 最新バージョン:Python に...
- MLにおけるETLデータパイプラインの構築方法
- 実際の無人運転車を仮想環境でテストする
- 2023年のトップビジネスインテリジェンス...
- 国連事務総長、AIに関する高位諮問機関を発足
- エンテラソリューションズの創設者兼CEO、...
- 私はスポティファイで3回の大量解雇を乗り...
- Amazon SageMaker 上で MPT-7B を微調整する
- プロジェクトゲームフェイスをご紹介しま...
- 「大規模言語モデルを改善するための簡単...

🤗 Hubでのスーパーチャージド検索
huggingface_hubライブラリは、ホスティングエンドポイント(モデル、データセット、スペース)を探索するためのプログラム的なアプローチを提供する軽量なインタフェースです。 これまでは、このインタフェースを介してハブでの検索は難しく、ユーザーは「知っているだけ」で慣れなければならない多くの側面がありました。 この記事では、huggingface_hubに追加されたいくつかの新機能を紹介し、ユーザーにJupyterやPythonインタフェースを離れずに使用したいモデルやデータセットを検索するためのフレンドリーなAPIを提供します。 始める前に、システムに最新バージョンのhuggingface_hubライブラリがない場合は、次のセルを実行してください: !pip install huggingface_hub -U 問題の位置づけ: まず、自分がどのようなシナリオにいるか想像してみましょう。テキスト分類のためにハブでホストされているすべてのモデルを見つけたいとします。これらのモデルはGLUEデータセットでトレーニングされ、PyTorchと互換性があります。 https://huggingface.co/models を単に開いてそこにあるウィジェットを使用することもできます。しかし、これによりIDEを離れて結果をスキャンする必要がありますし、必要な情報を得るためにはいくつかのボタンクリックが必要です。 もしもIDEを離れずにこれを解決する方法があったらどうでしょうか?プログラム的なインタフェースであれば、ハブを探索するためのワークフローにも簡単に組み込めるかもしれません。 ここでhuggingface_hubが登場します。 このライブラリに慣れている方は、すでにこの種のモデルを検索できることを知っているかもしれません。しかし、クエリを正しく取得することは試行錯誤の痛ましいプロセスです。 それを簡略化することはできるでしょうか?さあ、見てみましょう! 必要なものを見つける まず、HfApiをインポートします。これはHugging Faceのバックエンドホスティングと対話するのに役立つクラスです。モデル、データセットなどを通じて対話することができます。さらに、いくつかのヘルパークラスもインポートします:ModelFilterとModelSearchArguments from huggingface_hub import HfApi, ModelFilter,…

機械学習でパワーアップした顧客サービス
このブログ投稿では、実際の顧客サービスのユースケースをシミュレートし、Hugging Faceエコシステムの機械学習ツールを使用してそれに対処します。 強くお勧めするのは、このノートブックをテンプレート/例として使用して、あなた自身の実世界のユースケースを解決することです。 タスク、データセット、モデルの定義 実際のコーディングに取り掛かる前に、自動化または一部自動化したいユースケースの明確な定義を持つことが重要です。ユースケースの明確な定義は、最適なタスク、使用するデータセット、および適用するモデルを特定するのに役立ちます。 NLPタスクの定義 では、自然言語処理モデルを使用して解決したい仮想的な問題について考えてみましょう。私たちは製品を販売しており、顧客サポートチームはフィードバック、クレーム、質問を含む数千のメッセージを受け取っています。理想的には、これらのメッセージにすべて返答する必要があります。 すぐに明らかになるのは、顧客サポートがすべてのメッセージに返信することは不可能であるということです。したがって、私たちは最も不満な顧客にのみ返信し、これらのメッセージに100%回答することを決定します。それらは中立的なメッセージや肯定的なメッセージと比べて最も緊急性があると考えられるためです。 非常に不満な顧客のメッセージが全メッセージの一部であると仮定し、不満なメッセージを自動的にフィルタリングできるとすると、顧客サポートはこの目標を達成できるはずです。 不満なメッセージを自動的にフィルタリングするために、自然言語処理技術を適用する予定です。 最初のステップは、私たちのユースケース(不満なメッセージのフィルタリング)を機械学習タスクにマッピングすることです。 Hugging Face Hubのタスクページは、与えられたシナリオに最も適したタスクを確認するための素晴らしい場所です。各タスクには詳細な説明と潜在的な使用例があります。 最も不満な顧客のメッセージを見つけるタスクは、テキスト分類のタスクとしてモデル化できます。メッセージを次の5つのカテゴリのいずれかに分類します:非常に不満、不満、中立、満足、または非常に満足。 適切なデータセットの見つけ方 タスクを決定したら、次にモデルをトレーニングするためのデータを見つける必要があります。これはユースケースのパフォーマンスにとって通常はモデルアーキテクチャを選ぶよりも重要です。モデルはトレーニングされたデータの質によってのみ優れた性能を発揮します。したがって、データセットの選択と作成には非常に注意が必要です。 不満なメッセージのフィルタリングという仮想的なユースケースを考えると、使用可能なデータセットを見てみましょう。 実際のユースケースでは、おそらくNLPシステムが処理する実際のデータを最もよく表す内部データがあるでしょう。したがって、そのような内部データをNLPシステムのトレーニングに使用するべきです。ただし、モデルの汎用性を向上させるために公開されているデータも含めることは役立ちます。 Hugging Face Hubの利用可能なデータセットをすべて見てみましょう。左側にはタスクカテゴリやより具体的なタスクに基づいてデータセットをフィルタリングできます。私たちのユースケースはテキスト分類 -> 感情分析に対応しているので、これらのフィルタを選択しましょう。このノートブックの執筆時点では、約80のデータセットが残ります。データセットを選ぶ際には、次の2つの側面を評価する必要があります:…
Habana GaudiでのTransformersの始め方
数週間前に、Habana LabsとHugging Faceが協力してTransformerモデルのトレーニングを加速することを発表できたことを喜んでお知らせいたします。 Habana Gaudiアクセラレータは、最新のGPUベースのAmazon EC2インスタンスと比較して、機械学習モデルのトレーニングにおいて最大40%の価格パフォーマンス向上を提供します。私たちはこの価格パフォーマンスの利点をTransformersにもたらすことに非常に興奮しています🚀 この実践的な投稿では、Amazon Web ServicesでHabana Gaudiインスタンスを素早くセットアップし、テキスト分類用にBERTモデルを微調整する方法を紹介します。通常どおり、コードはすべて提供されているため、プロジェクトで再利用できます。 さあ、始めましょう! AWSでHabana Gaudiインスタンスをセットアップする Habana Gaudiアクセラレータを使用する最も簡単な方法は、Amazon EC2 DL1インスタンスを起動することです。これらのインスタンスには、Habana SynapseAI® SDKがプリインストールされたHabana Deep Learning Amazon Machine Image(AMI)が搭載されています。また、GaudiアクセラレーションされたDockerコンテナを実行するために必要なツールも含まれています。他のAMIやコンテナを使用したい場合は、Habanaのドキュメントに手順が記載されています。…
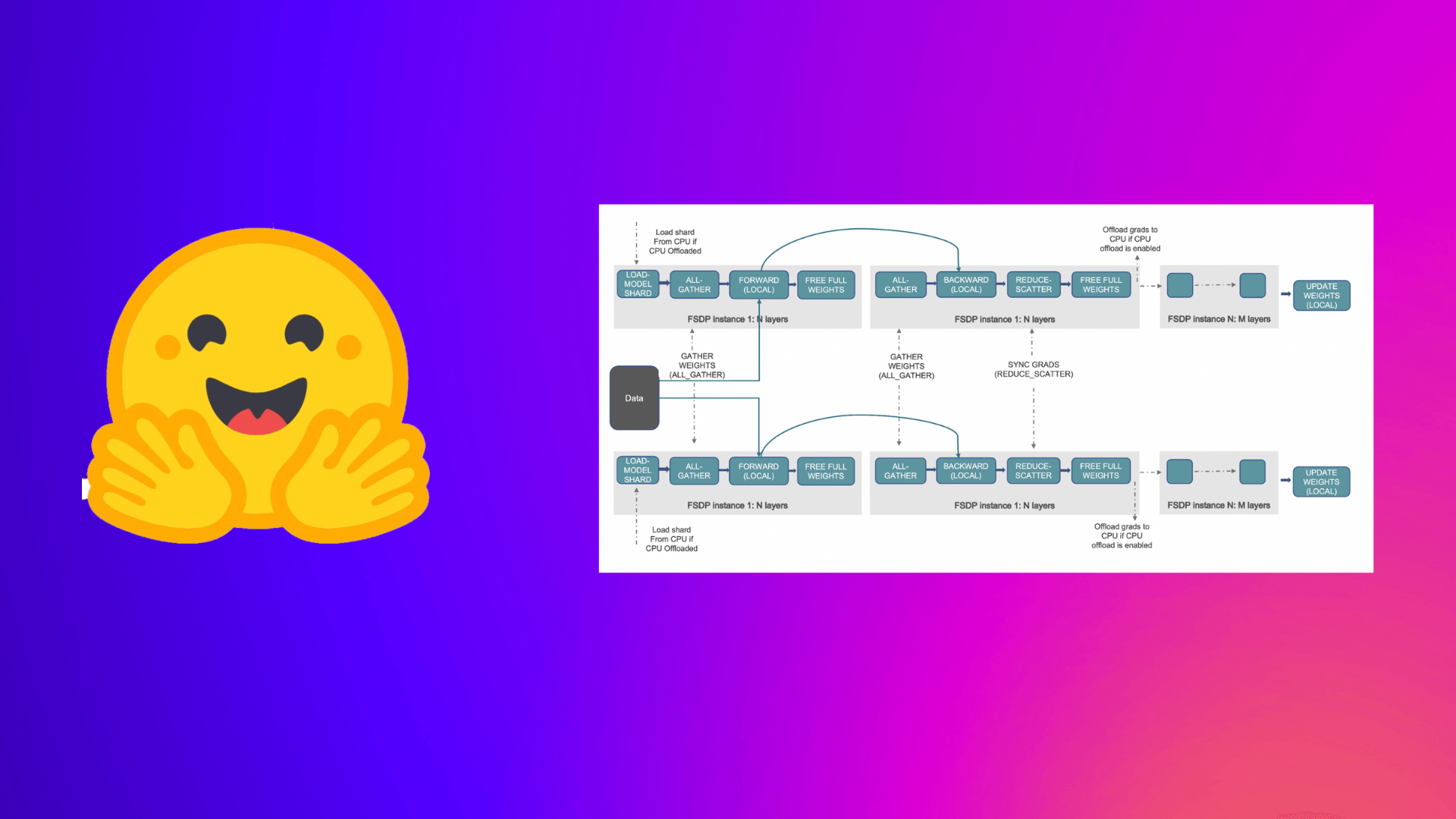
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

DeepSpeedを使用して大規模モデルトレーニングを高速化する
この投稿では、Accelerate ライブラリを活用して、ユーザーが DeeSpeed の ZeRO 機能を利用して大規模なモデルをトレーニングする方法について説明します。 大規模なモデルをトレーニングしようとする際にメモリ不足 (OOM) エラーに悩まされていますか?私たちがサポートします。大規模なモデルは非常に高性能ですが、利用可能なハードウェアでトレーニングするのは困難です。大規模なモデルのトレーニングに利用可能なハードウェアの最大限の性能を引き出すために、ZeRO – Zero Redundancy Optimizer [2] を使用したデータ並列処理を活用することができます。 以下は、このブログ記事からの図を使用した ZeRO を使用したデータ並列処理の短い説明です。 (出典: リンク) a. ステージ 1 :…

プライベートハブのご紹介:機械学習を活用した新しいビルド方法
機械学習は、企業が技術を構築する方法を変えつつあります。革新的な新製品のパワーを供給し、私たちが使い慣れて愛している既知のアプリケーションにスマートな機能を提供することから、MLは開発プロセスの中心にあります。 しかし、すべての技術の変化には新たな課題が伴います。 機械学習モデルの約90%が本番環境に到達しないとされています。馴染みのないツールや非標準的なワークフローがMLの開発を遅くしています。モデルやデータセットが内部で共有されないため、同じような成果物がチーム間で常にゼロから作成されます。データサイエンティストは、ビジネスステークホルダーに技術的な作業を示すのが難しく、正確でタイムリーなフィードバックを共有するのに苦労しています。そして、機械学習チームはDocker/Kubernetesや本番環境向けのモデル最適化に時間を浪費しています。 これらを考慮して、私たちはPrivate Hub(PH)を立ち上げました。機械学習の構築方法を革新する新しい方法です。研究から本番環境まで、セキュアかつコンプライアンスを確保しながら、機械学習ライフサイクルの各ステップを加速するための統合されたツールセットを提供します。PHはさまざまなMLツールを一つにまとめることで、機械学習の協力をよりシンプルで楽しく、生産的にします。 このブログ投稿では、Private Hubとは何か、なぜ役立つのか、そしてどのようにお客様がそれを使用してMLのロードマップを加速しているのかについて詳しく説明します。 一緒に読んでいただくか、興味を引くセクションにジャンプしてください 🌟: ハグフェースハブとは何ですか? プライベートハブとは何ですか? 企業はプライベートハブをどのように使用してMLのロードマップを加速しているのでしょうか? さあ、始めましょう! 🚀 1. ハグフェースハブとは何ですか? プライベートハブについて詳しく説明する前に、まずハグフェースハブについて見てみましょう。これはPHの中心的な要素です。 ハグフェースハブは、オープンソースで公開されているオンラインプラットフォームで、人々が簡単に協力してMLを構築できる場所です。ハブは、機械学習と一緒に技術を探求し、実験し、協力し、構築するための中心的な場所として機能します。 ハグフェースハブでは、次のようなMLアセットを作成または発見することができます: モデル:NLP、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などの最新の最先端モデルをホスティング。 データセット:さまざまなドメイン、モダリティ、言語に対応したデータの幅広いバリエーション。 スペース:ブラウザ内で直接MLモデルをショーケースするインタラクティブなアプリ。 ハブにアップロードされた各モデル、データセット、またはスペースは、Gitベースのリポジトリです。これはすべてのファイルを含むバージョン管理された場所で、従来のgitコマンドを使用してファイルをプル、プッシュ、クローン、操作することができます。モデル、データセット、およびスペースのコミット履歴を表示し、誰がいつ何を行ったかを確認することができます。 モデルのコミット履歴…

Hugging FaceのTensorFlowの哲学
はじめに PyTorchやJAXからの競争が増えても、TensorFlowは最も使用されるディープラーニングフレームワークのままです。また、それらの他の2つのライブラリとはいくつか非常に重要な点で異なります。特に、高レベルのAPIであるKerasと、データの読み込みライブラリであるtf.dataとの統合が非常に密接です。 PyTorchのエンジニアの中には(ここでオープンプランオフィスを暗く見つめながら私を想像してください)、これを克服すべき問題だと見なす傾向があります。彼らの目標は、TensorFlowが彼らのやり方に従って低レベルのトレーニングとデータの読み込みコードを使用できるようにする方法を見つけることです。これはTensorFlowに取り組む間違った方法です! Kerasは素晴らしい高レベルのAPIです。プロジェクトが数モジュールよりも大きい場合、それを押しのけると、必要になると気付いたときに、その機能のほとんどを自分で再現することになります。 洗練された、尊敬され、非常に魅力的なTensorFlowエンジニアとして、私たちは最先端のモデルの驚異的なパワーと柔軟性を使用したいと思っていますが、私たちが使い慣れたツールとAPIでそれらを扱いたいのです。このブログポストでは、Hugging Faceでそれを実現するために行う選択と、TensorFlowプログラマーとしてフレームワークから期待できることについて説明します。 インタールード:30秒で🤗 経験豊富なユーザーは、このセクションをざっと読んだりスキップしたりして構いませんが、Hugging Faceとtransformersに初めて出会う方には、ライブラリのコアアイデアについて概要を説明する必要があります。モデルを事前学習済みモデルとして名前でリクエストするだけで、1行のコードで取得できます。最も簡単な方法は、TFAutoModelクラスを使用するだけです。 from transformers import TFAutoModel model = TFAutoModel.from_pretrained("bert-base-cased") この1行でモデルのアーキテクチャがインスタンス化され、重みが読み込まれます。これにより、元の有名なBERTモデルの正確なレプリカが得られます。ただし、このモデル自体ではあまり役に立ちません – 出力ヘッドや損失関数がありません。実際には、これは最後の隠れ層の直後で終了するニューラルネットワークの「ステム」です。では、どのようにして出力ヘッドを追加するのでしょうか?簡単です、異なるAutoModelクラスを使用するだけです。ここでは、Vision Transformer(ViT)モデルを読み込み、画像分類ヘッドを追加しています。 from transformers import TFAutoModelForImageClassification…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…
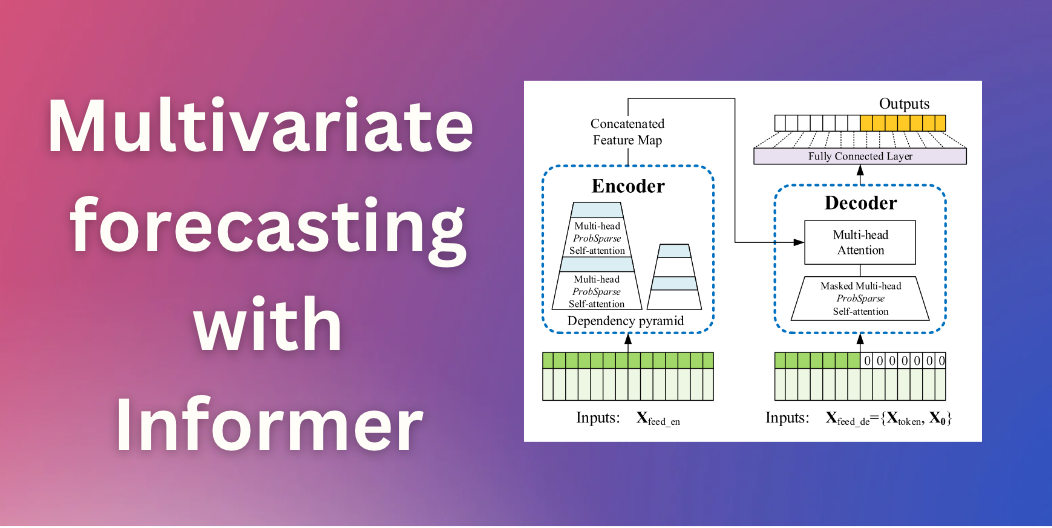
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

MLにおけるETLデータパイプラインの構築方法
データ処理から迅速な洞察まで、頑強なパイプラインはどんなMLシステムにとっても必須ですデータチーム(データとMLエンジニアで構成される)はしばしばこのインフラを構築する必要があり、この経験は苦痛となることがありますしかし、MLでETLパイプラインを効率的に使用することで、彼らの生活をはるかに楽にすることができます本記事では、その重要性について探求します...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.