Learn more about Search Results Data Science Blogathon - Page 7

- You may be interested
- 「CVPR 2023のメモ」
- 「生成型AI:CHATGPT、Dall-E、Midjourney...
- 「ウェアラブルデバイスは人間の観察より...
- 「Microsoft AIが意図せずに秘密の情報を...
- 「カルマンフィルターのパワーを暴露する」
- 文のトランスフォーマーを使用してプレイ...
- 「Java での AI:Spring Boot と LangChai...
- 人間のフィードバックからの強化学習(RLHF)
- 最大のLLMベンチマーキングスイート:MEGA...
- 「ヨーロッパは新たな産業革命で仮想工場...
- 「Pythonにおける記述統計と推測統計の適用」
- 「Voicemod AIで自分自身のAIボイスを作成...
- データサイエンティストになりたいですか...
- ドックスからコードの生成には、LLMsを使...
- AIがフィンテックを向上させる方法:追跡...

「Snapchatにおける生成AIの力」
イントロダクション Snapchatは、現実と革新がシームレスに融合する時代を先駆け、生成AIによって増幅されています。この変革の力により、普通の写真が素晴らしい驚異に変わり、フィルターを超えた体験を推進します。アルゴリズムは表情を識別し、行動を予測し、美的なスペクタクルを作り出します。生成AIはデジタルな出会いに命を吹き込み、日常を超越します。アバターはユニークなビットモジに進化し、自己表現をデジタルな傑作に高めます。絵文字は感情を捉え、AIの言語で絆を築きます。この非凡なAIは視覚だけでなく、将来のトレンドも予測します。年をとることをシミュレートし、楽しい顔の入れ替えを引き起こし、笑いを引き起こします。Snapchatの生成AIは今日を超越し、無限の未来を垣間見るものです。 イノベーションの風景を慎重に歩み、拡大と倫理のバランスを心に留めて進んでいきましょう。 学習目標 生成AIの基本原則とSnapchatプラットフォーム内での創造的な体験を推進する役割について洞察を得る。 Gen AIはSnapchatのARフィルターとレンズにパワーを与え、現実とデジタルの芸術が融合したダイナミックで没入感のある視覚効果を実現します。 生成AIが拡張現実を通じて個別化されたインタラクティブな体験を可能にすることで、ユーザーエンゲージメントを向上させる方法を発見します。 この記事はData Science Blogathonの一環として公開されました。 SnapchatのARフィルターとレンズ SnapchatのARフィルターとレンズは、現実とデジタルの世界をシームレスに融合することで視覚的な表現を再構築しました。これらの没入型の機能により、ユーザーは顔や周囲をダイナミックなキャンバスに変えることができ、各写真を変換することができます。生成AIとリアルタイムの画像処理の複雑な相互作用がARフィルターとレンズの中心にあります。GANとニューラルネットワークは、ライブビデオフィードから顔の特徴点や環境情報を評価し理解するgeneAIアルゴリズムです。Snapchatは今やユーザーの表情、動き、さらには周囲まで正確にマッピングして追跡できます。SnapchatのARフィルターとレンズは基本的な美的な拡張を超えています。個人的なつながりや創造的なストーリーテリング、関与をもたらします。また、ブランドもこの最先端の技術を使用して、人々との思い出に残るエンカウントを提供するエンターテインメントのマーケティングキャンペーンに活用しています。 フェイスフィルターの作成 PythonとTensorFlowライブラリを使用して、ユーザーの顔に仮想のメガネを追加するシンプルなフェイスフィルターを作成する方法を見てみましょう。 import dlib import cv2 import numpy as np import…

PDFとのチャット | PythonとOpenAIによるテキストの対話力の向上
イントロダクション 情報に満ちた世界で、PDFドキュメントは貴重なデータを共有および保存するための必須アイテムとなっています。しかし、PDFから洞察を抽出することは常に簡単ではありませんでした。それが「Chat with PDFs」が登場する理由です。この革新的なプロジェクトは、私たちがPDFと対話する方法を変革します。 この記事では、言語モデルライブラリ(LLM)のパワーとPyPDFのPythonライブラリの多様性を組み合わせた「Chat with PDFs」という魅力的なプロジェクトを紹介します。このユニークな融合により、PDFドキュメントと自然な会話を行うことができ、質問をすることや関連のある回答を得ることが容易になります。 学習目標 言語モデルライブラリ(LLM)についての洞察を得る。これは人間の言語パターンを理解し、意味のある応答を生成する高度なAIモデルです。 PyPDFを探求し、PDFの操作におけるテキスト抽出、マージ、分割などの機能を理解する。 言語モデルライブラリ(LLM)とPyPDFの統合により、PDFとの自然な会話を可能にする対話型チャットボットの作成方法を認識する。 この記事はData Science Blogathonの一環として公開されました。 言語モデルライブラリ(LLM)の理解 「Chat with PDFs」の中心にあるのは、言語モデルライブラリ(LLM)です。これは大量のテキストデータで訓練された高度なAIモデルです。これらは言語の専門家のような存在であり、人間の言語パターンを理解し、意味のある応答を生成することができます。 私たちのプロジェクトでは、LLMは対話型チャットボットの作成において重要な役割を果たしています。このチャットボットは、あなたの質問を処理し、PDFから必要な情報を理解することができます。PDFに隠された知識を活用して、役立つ回答と洞察を提供することができます。 PyPDFs – あなたのPDFスーパーアシスタント PyPDFは、PDFファイルとのやり取りを簡素化する多機能なPythonライブラリです。テキストの抽出、結合、分割など、さまざまな機能を利用できます。このライブラリは、PDFの処理と分析を効率化するために私たちのプロジェクトにおいて重要な役割を果たしています。 PyPDFを使用することで、PDFファイルをロードし、そのテキストを抽出することができます。これにより、効率的な処理と分析の準備が整いました。この強力なアシスタントを使用して、PDFとの対話をスムーズに行うことができます。…

CycleGANによる画像から画像への変換
イントロダクション 人工知能とコンピュータビジョンの領域において、CycleGANは画像の認識と操作方法を再定義した素晴らしいイノベーションです。この先端技術は、馬をシマウマに変換したり、夏の風景を雪景色に変換したりするなど、ドメイン間のシームレスな変換を可能にしました。本記事では、CycleGANの魔法と、さまざまなドメインでの応用について探求します。 学習目標 CycleGANのコンセプトと革新的な双方向画像変換手法。 CycleGANのジェネレータネットワーク(G_ABとG_BA)のアーキテクチャ、ディスクリミネータネットワーク(D_AとD_B)の設計、およびトレーニングにおける役割。 CycleGANの現実世界での応用例には、スタイル変換、ドメイン適応、季節の変遷、都市計画などがあります。 CycleGANの実装時に直面する課題には、変換品質とドメインのシフトがあります。 CycleGANの機能を向上させるための可能な将来の方向。 この記事はData Science Blogathonの一環として公開されました。 CycleGANとは何ですか? CycleGAN(サイクルコンシステントジェネレーティブアドバーサリーネットワーク)は、教師なしの画像変換を容易にする新しいディープラーニングアーキテクチャです。従来のGANは、ジェネレータとディスクリミネータを最小最大ゲームで対決させますが、CycleGANは巧妙な仕掛けを導入しています。一方向の変換を目指すのではなく、CycleGANは対になったトレーニングデータに依存せずに、2つのドメイン間で双方向マッピングを達成することに焦点を当てています。つまり、CycleGANはドメインAからドメインBへの画像変換だけでなく、重要なのはドメインBからドメインAへの逆変換も行い、画像がサイクルを通じて一貫性を保つことを確認します。 CycleGANのアーキテクチャ CycleGANのアーキテクチャは、ドメインAからドメインBへの画像変換とその逆を担当する2つのジェネレータ、G_AとG_B、そしてそれぞれのドメインの実際の画像と変換された画像の本物かどうかを評価する2つのディスクリミネータ、D_AとD_B、という特徴があります。敵対的なトレーニングにより、ジェネレータはターゲットドメインの実際の画像と区別がつかないような画像を生成するように強制されます。また、サイクル一貫性の損失は、双方向変換後に元の画像を再構築できるようにします。 CycleGANを使用した画像から画像への変換の実装 # ライブラリのインポート import tensorflow as tf import tensorflow_datasets…

「ドメイン特化LLMの潜在能力の解放」
イントロダクション 大規模言語モデル(LLM)は世界を変えました。特にAIコミュニティにおいて、これは大きな進歩です。テキストを理解し、返信することができるシステムを構築することは、数年前には考えられなかったことでした。しかし、これらの機能は深さの欠如と引き換えに得られます。一般的なLLMは何でも屋ですが、どれも専門家ではありません。深さと精度が必要な領域では、幻覚のような欠陥は高価なものになる可能性があります。それは医学、金融、エンジニアリング、法律などのような領域がLLMの恩恵を受けることができないことを意味するのでしょうか?専門家たちは、既に同じ自己教師あり学習とRLHFという基礎的な技術を活用した、これらの領域に特化したLLMの構築を始めています。この記事では、領域特化のLLMとその能力について、より良い結果を生み出すことを探求します。 学習目標 技術的な詳細に入る前に、この記事の学習目標を概説しましょう: 大規模言語モデル(LLM)とその強みと利点について学びます。 一般的なLLMの制限についてさらに詳しく知ります。 領域特化のLLMとは何か、一般的なLLMの制限を解決するためにどのように役立つのかを見つけます。 法律、コード補完、金融、バイオ医学などの分野におけるパフォーマンスにおけるその利点を示すためのさまざまな領域特化言語モデルの構築について、例を交えて探求します。 この記事はData Science Blogathonの一部として公開されました。 LLMとは何ですか? 大規模言語モデル(LLM)とは、数億から数十億のパラメータを持つ人工知能システムであり、テキストを理解し生成するために構築されます。トレーニングでは、モデルにインターネットのテキスト、書籍、記事、ウェブサイトなどからの多数の文を提示し、マスクされた単語または文の続きを予測するように教えます。これにより、モデルはトレーニングされたテキストの統計パターンと言語的関係を学びます。LLMは、言語翻訳、テキスト要約、質問応答、コンテンツ生成など、さまざまなタスクに使用することができます。トランスフォーマーの発明以来、無数のLLMが構築され、公開されてきました。最近人気のあるLLMの例には、Chat GPT、GPT-4、LLAMA、およびStanford Alpacaなどがあり、画期的なパフォーマンスを達成しています。 LLMの強み LLMは、言語理解、エンティティ認識、言語生成の問題など、言語に関するさまざまな課題のためのソリューションとして選ばれるようになりました。GLUE、Super GLUE、SQuAD、BIGベンチマークなどの標準的な評価データセットでの優れたパフォーマンスは、この成果を反映しています。BERT、T5、GPT-3、PALM、GPT-4などが公開された時、それらはすべてこれらの標準テストで最新の結果を示しました。GPT-4は、BARやSATのスコアで平均的な人間よりも高得点を獲得しました。以下の図1は、大規模言語モデルの登場以来、GLUEベンチマークでの大幅な改善を示しています。 大規模言語モデルのもう一つの大きな利点は、改良された多言語対応の能力です。たとえば、104の言語でトレーニングされたマルチリンガルBERTモデルは、さまざまな言語で優れたゼロショットおよびフューショットの結果を示しています。さらに、LLMの活用コストは比較的低くなっています。プロンプトデザインやプロンプトチューニングなどの低コストの方法が登場し、エンジニアはわずかなコストで既存のLLMを簡単に活用することができます。そのため、大規模言語モデルは、言語理解、エンティティ認識、翻訳などの言語に基づくタスクにおけるデフォルトの選択肢となっています。 一般的なLLMの制限 Web、書籍、Wikipediaなどからのさまざまなテキストリソースでトレーニングされた上記のような一般的なLLMは、一般的なLLMと呼ばれています。これらのLLMには、Bing ChatのGPT-4、PALMのBARDなどの検索アシスタント、マーケティングメール、マーケティングコンテンツ、セールスピッチなどのコンテンツ生成タスク、個人チャットボット、カスタマーサービスチャットボットなど、さまざまなアプリケーションがあります。 一般的なAIモデルは、さまざまなトピックにわたるテキストの理解と生成において優れたスキルを示していますが、専門分野にはさらなる深さとニュアンスが必要な場合があります。たとえば、「債券」とは金融業界での借入の形態ですが、一般的な言語モデルはこの独特なフレーズを理解せず、化学や人間同士の債券と混同してしまうかもしれません。一方、領域特化のLLMは、特定のユースケースに関連する専門用語を専門的に理解し、業界固有のアイデアを適切に解釈する能力があります。 また、一般的なLLMには複数のプライバシーの課題があります。たとえば、医療LLMの場合、患者データは非常に重要であり、一般的なLLMに機械学習強化学習(RLHF)などの技術が使用されることで、機密データの公開がプライバシー契約に違反する可能性があります。一方、特定のドメインに特化したLLMは、データの漏洩を防ぐために閉じたフレームワークを確保します。…

「DCGANモデルの作成手順ガイド」
はじめに Deep Convolutional Generative Adversarial Networks(DCGANs)は、Generative Adversarial Networks(GANs)と畳み込みニューラルネットワーク(CNNs)の力を組み合わせることで、画像生成の分野を革新しました。 DCGANモデルは非常にリアルな画像を作成することができ、芸術生成、画像編集、データ拡張など、さまざまなクリエイティブなアプリケーションで重要なツールとなっています。 このステップバイステップガイドでは、PythonとTensorFlowを使用してDCGANモデルを構築するプロセスを詳しく説明します。 DCGANsは、芸術やエンターテイメントなどのさまざまな分野で貴重な存在であり、アーティストが新しいビジュアル体験を作り出すことを可能にしています。 さらに、医療画像では、DCGANsが診断の正確性のための高解像度スキャンを生成するのに役立ちます。 データ拡張における役割は、機械学習モデルを強化し、建築やインテリアデザインにも貢献して、現実的な環境をシミュレートしています。 創造性と技術をシームレスに融合させることで、DCGANsは単なるアルゴリズムを超えて、さまざまな領域で革新的な進歩を促進しています。 このチュートリアルの最後までには、ランダムなノイズから高品質の画像を生成できる、よく構造化されたDCGANの実装ができるようになります。 この記事はData Science Blogathonの一部として公開されました。 前提条件 実装に入る前に、次のライブラリがインストールされていることを確認してください: TensorFlow:pip install tensorflow NumPy:pip…

音楽作曲における創造的なジェネレーティブAIの交響曲
はじめに 生成型AIは、教科書、画像、音楽などの新しいデータを生成できる人工知能です。音楽作曲では、生成型AIは作曲家に新しい鳴き声、チャイム、小節、さらには完全な曲を生成する力を与えます。この技術は、既に一部のアーティストやミュージシャンが新しい革新的な作品を生み出すために使用しており、音楽の創造方法を革命化する可能性があります。音楽作曲における生成型AIの使用方法には、主に2つのアプローチがあります。 1つのアプローチは、大規模な音楽データセットでAIアルゴリズムをトレーニングすることです。アルゴリズムは音楽のパターンと構造を学習し、この知識を活用してトレーニングデータに似た新しい音楽を生成します。もう1つのアプローチは、音楽に基づかない新しい音楽のアイデアをAIを使って生成することです。これは、AIを使って任意の音符のシーケンスを誘導するか、AIを使って可能な音楽の組み合わせの空間を探索することによって行われます。 学習目標 生成型AIについて学び、音楽の作曲方法にどのように変革をもたらしているかを理解する。 音楽の創作における生成型AIの多くの利点について知る。これには音楽のインスピレーションからカスタマイズされた制作までが含まれる。 AIが生成した音楽を芸術の領域に取り入れる際に発生する困難や倫理的な問題について検討する。 現在の音楽制作における生成型AIの使用方法と、将来の可能性について学ぶ。 この記事はData Science Blogathonの一部として公開されました。 生成型AIの理解 人工知能は、現代の機械学習アルゴリズムを使用して独自の音楽作品を作成するため、音楽作曲を根本的に変革します。大規模なデータセットを学習し、音楽の重要な要素を文書化することによって、これらのモデルは芸術的な表現と一貫性を持つメロディ、リズム、ハーモニーを作成することができます。これにより、作曲家は新しい可能性を研究し、音楽の分野で創造力を発揮するための新しいアイデアを得ることができます。 このGenAIモデルを音楽作曲に適用するには、RNN、Variational Autoencoders(VAEs)、またはTransformersなどの高度な機械学習アルゴリズムが必要です。これらのアルゴリズムはこのモデルの基盤となります。モデルが学習したデータに基づいて音楽を認識し、作成するために、音楽作曲家や開発者はPyTorchやTensorFlowなどの機械学習のサブストラクチャを利用して構築し、教えます。さまざまなネットワークアーキテクチャ、トレーニング技術、ハイパーパラメータを試し、作成される音楽の品質と革新を最大化するためにテストします。 音楽作曲のためのAIモデルのトレーニングには、さまざまな音楽ジャンルやスタイルなど、幅広いデータの提示が含まれます。モデルは入力データから学習したパターンから必要なデータを選択して自身の作品を作成します。これにより、オリジナルでユニークな出力が得られ、観客を魅了することができます。 音楽作曲における生成型AIの利点 生成型AIモデルは、高度な機械学習アルゴリズムと豊富な音楽ノートのデータセットを使用して音楽作品の増加とモチベーションを提供します。 以下は、このモデルのいくつかの利点です: インスピレーションと革新 このAIモデルは、音楽作曲家に新しいアイデアの源を提供し、音楽の創作において広範で新しいアイデアを提供します。さまざまな音楽の種類やスタイルを理解することにより、生成型AIモデルは将来の音楽作曲家に脅威となるユニークなバリエーションや組み合わせを作成することができます。この革新とインスピレーションにより、創造プロセスが活性化され、新しいコンセプトと音楽の領域の開発が促進されます。作曲家は新しい音楽の領域を学び、以前に考えたことのない遊び心のある音楽、ハーモニー、曲の試行錯誤を行うことができます。 このモデルが新しい音楽の作成のための新しいアイデアを生み出す能力により、創造力の大きな障壁が取り除かれ、音楽作曲家が助けられます。このインスピレーションと革新は、作曲家の創造性を高めるだけでなく、作曲家が自身の創造的な限界を探求し、音楽業界や世界の向上に貢献する機会を提供します。 効率と時間の節約 このモデルの使用により、時間の節約能力によって音楽の作曲の視点が変わりました。高度な機械学習アルゴリズムと豊富な音楽データセットを使用することで、このモデルは短時間で多くの音符、曲、バリエーションを素早く生成することができます。これにより、音楽作曲家は最初から始める必要がなくなり、新しい音楽の創造を加速するのに役立ちます。…

キャッシング生成的LLMs | APIコストの節約
はじめに 生成AIは非常に広まっており、私たちのほとんどは、画像生成器または有名な大規模言語モデルなど、生成AIモデルを使用したアプリケーションの開発に取り組んでいるか、既に取り組んでいます。私たちの多くは、特にOpenAIなどのクローズドソースの大規模言語モデルを使用して、彼らが開発したモデルの使用に対して支払いをする必要があります。もし私たちが十分注意を払えば、これらのモデルを使用する際のコストを最小限に抑えることができますが、どういうわけか、価格はかなり上昇してしまいます。そして、この記事では、つまり大規模言語モデルに送信される応答/ API呼び出しをキャッチすることについて見ていきます。Caching Generative LLMsについて学ぶのが楽しみですか? 学習目標 Cachingとは何か、そしてそれがどのように機能するかを理解する 大規模言語モデルをキャッシュする方法を学ぶ LangChainでLLMをキャッシュするための異なる方法を学ぶ Cachingの潜在的な利点とAPIコストの削減方法を理解する この記事は、Data Science Blogathonの一部として公開されました。 Cachingとは何か?なぜ必要なのか? キャッシュとは、データを一時的に保存する場所であり、このデータの保存プロセスをキャッシングと呼びます。ここでは、最も頻繁にアクセスされるデータがより速くアクセスできるように保存されます。これはプロセッサのパフォーマンスに劇的な影響を与えます。プロセッサが計算時間がかかる集中的なタスクを実行する場合を想像してみてください。今度は、プロセッサが同じ計算を再度実行する状況を想像してみてください。このシナリオでは、前回の結果をキャッシュしておくと非常に役立ちます。タスクが実行された時に結果がキャッシュされていたため、計算時間が短縮されます。 上記のタイプのキャッシュでは、データはプロセッサのキャッシュに保存され、ほとんどのプロセスは組み込みのキャッシュメモリ内にあります。しかし、これらは他のアプリケーションには十分ではない場合があります。そのため、これらの場合はキャッシュをRAMに保存します。RAMからのデータアクセスはハードディスクやSSDからのアクセスよりもはるかに高速です。キャッシュはAPI呼び出しのコストも節約することができます。例えば、Open AIモデルに類似のリクエストを送信した場合、各リクエストに対して請求がされ、応答時間も長くなります。しかし、これらの呼び出しをキャッシュしておくと、モデルに類似のリクエストをキャッシュ内で検索し、キャッシュ内に類似のリクエストがある場合は、APIを呼び出す代わりにデータ、つまりキャッシュから応答を取得することができます。 大規模言語モデルのキャッシュ 私たちは、GPT 3.5などのクローズドソースのモデル(OpenAIなど)が、ユーザーにAPI呼び出しの料金を請求していることを知っています。請求額または関連する費用は、渡されるトークンの数に大きく依存します。トークンの数が多いほど、関連するコストも高くなります。これは大金を支払うことを避けるために慎重に扱う必要があります。 さて、APIを呼び出すコストを解決する/削減する方法の一つは、プロンプトとそれに対応する応答をキャッシュすることです。最初にモデルにプロンプトを送信し、それに対応する応答を取得したら、それをキャッシュに保存します。次に、別のプロンプトが送信される際には、モデルに送信する前に、つまりAPI呼び出しを行う前に、キャッシュ内の保存されたプロンプトのいずれかと類似しているかどうかをチェックします。もし類似している場合は、モデルにプロンプトを送信せずに(つまりAPI呼び出しを行わずに)キャッシュから応答を取得します。 これにより、モデルに類似のプロンプトを要求するたびにコストを節約することができ、さらに、応答時間も短縮されます。なぜなら、キャッシュから直接データを取得するため、モデルにリクエストを送信してから応答を取得する必要がないからです。この記事では、モデルからの応答をキャッシュするための異なる方法を見ていきます。 LangChainのInMemoryCacheを使用したキャッシュ はい、正しく読みました。LangChainライブラリを使用して、応答とモデルへの呼び出しをキャッシュすることができます。このセクションでは、キャッシュメカニズムの設定方法と、結果がキャッシュされており、類似のクエリに対する応答がキャッシュから取得されていることを確認するための例を見ていきます。必要なライブラリをダウンロードして開始しましょう。…

「医療分野における生成型AI」
はじめに 生成型人工知能は、ここ数年で急速に注目を集めています。医療と生成型人工知能の間に強い関係性が生まれていることは驚くことではありません。人工知能(AI)はさまざまな産業を急速に変革しており、医療分野も例外ではありません。AIの特定のサブセットである生成型人工知能は、医療分野において画期的な存在となっています。 生成型AIシステムは、新しいデータ、画像、さらには完全な芸術作品を生成することができます。医療分野では、この技術は診断、新薬の発見、患者ケア、医学研究の向上において非常に有望です。本記事では、医療分野における生成型人工知能の潜在的な応用と利点、実装上の課題、倫理的な考慮事項について探究します。 学習目標 GenAIとその医療分野への応用 GenAIの医療分野における潜在的な利点 医療分野における生成型AIの実装上の課題と制約 医療分野における生成型AIの将来的な展望 本記事は、Data Science Blogathonの一環として公開されました。 医療分野における生成型人工知能の潜在的な応用 医療分野において、GenAIをどのように活用できるかについて、いくつかの研究が行われています。GenAIは、新薬のための分子構造や化合物の生成に影響を与え、有望な薬剤候補の同定と発見を促進しています。これにより、先端技術を活用しながら時間とコストを節約することが可能です。以下は、これらの潜在的な応用の一部です: 医療画像および診断の向上 医療画像は、診断と治療計画において重要な役割を果たしています。生成型AIアルゴリズム(生成対抗的ネットワーク(GAN)や変分オートエンコーダー(VAE)など)は、医療画像解析を大幅に改善しています。これらのアルゴリズムは、実際の患者データに似た合成医療画像を生成することができ、機械学習モデルのトレーニングと検証に役立ちます。また、限られたデータセットを補完するために追加のサンプルを生成することで、画像に基づく診断の正確性と信頼性を向上させることもできます。 薬剤の発見と開発の促進 新薬の発見と開発は、複雑で時間がかかり、費用がかかる作業です。生成型AIは、所望の特性を持つ仮想化合物や分子を生成することで、このプロセスを大幅に加速することができます。研究者は、生成モデルを用いて広大な化学空間を探索し、新たな薬剤候補を同定することができます。これらのモデルは既存のデータセット(既知の薬剤構造と関連する特性を含む)から学習し、望ましい特性を持つ新しい分子を生成します。 個別化医療と治療 生成型AIは、患者データを活用して個別化された治療計画を作成することで、個別化医療を革新する潜在能力を持っています。電子健康記録、遺伝子プロファイル、臨床結果などの大量の患者情報を分析することにより、生成型AIモデルは個別化された治療の推奨を生成することができます。これらのモデルはパターンを特定し、病気の進行を予測し、介入に対する患者の反応を推定することができるため、医療提供者は情報に基づいた意思決定を行うことができます。 医学研究と知識生成 生成型AIモデルは、特定の特性と制約を満たす合成データを生成することで、医学研究を支援することができます。合成データは、機密性の高い患者情報の共有に関連するプライバシーの問題を解決しながら、研究者が有益な洞察を抽出し、新たな仮説を開発することができます。 また、生成型AIは臨床試験のための合成患者コホートを生成することもできます。これにより、研究者はさまざまなシナリオをシミュレートし、実際の患者に対する高価で時間のかかる試験を実施する前に治療の効果を評価することができます。この技術は、医学研究を加速し、イノベーションを推進し、複雑な疾患に対する理解を広げる可能性があります。 事例研究: CPPE-5…

「マルチスレッディングの探求:Pythonにおける並行性と並列実行」
イントロダクション 並行性は、アプリケーションの速度と応答性を向上させるのに役立つ、コンピュータプログラミングの重要な要素です。Pythonでは、マルチスレッドを使用して並行性を作り出す強力な方法があります。マルチスレッドを使用すると、複数のスレッドが単一のプロセス内で同時に実行され、並行実行とシステムリソースの効果的な利用が可能になります。このチュートリアルでは、Pythonのマルチスレッドについて詳しく説明します。アイデア、利点、困難について説明します。スレッドの設定と制御、スレッド間でのデータ共有、スレッドの安全性の確保などを学びます。 また、共有リソースの管理や競合状態の回避のための典型的な罠や、マルチスレッドのプログラムの開発と実装のための推奨事項も学びます。マルチスレッドの理解は、ネットワークアクティビティ、I/Oバウンドタスクを含むアプリケーションの開発、またはプログラムをより応答性のあるものにする試みなど、どのような場面でも有利です。並行実行の潜在能力を最大限に活用することで、パフォーマンスの向上とシームレスなユーザーエクスペリエンスを実現できます。Pythonのマルチスレッドの奥深さに迫り、並行かつ効果的なアプリケーションを作成するためのポテンシャルを引き出す方法を発見するために、私たちと一緒にこの航海に参加してください。 学習目標 このトピックからのいくつかの学習目標は以下の通りです: 1. スレッドとは何か、単一プロセス内でどのように動作し、並行性をどのように実現するかを含め、マルチスレッドの基礎を学びます。Pythonでのマルチスレッドの利点と制限、特にCPUバウンドタスクへのGlobal Interpreter Lock(GIL)の影響について理解します。 2. ロック、セマフォ、条件変数などのスレッド同期技術を探索し、共有リソースの管理と競合状態の回避方法を学びます。スレッドの安全性を確保し、共有データを効率的かつ安全に処理する並行プログラムの設計方法を学びます。 3. Pythonのスレッディングモジュールを使用してスレッドを作成・管理するハンズオンの経験を積みます。スレッドの開始、結合、終了方法を学び、スレッドプールやプロデューサー・コンシューマーモデルなどのマルチスレッドの一般的なパターンを探索します。 この記事はData Science Blogathonの一環として公開されました。 並行性の基本 コンピュータサイエンスの重要な考え方の1つは、並行性と呼ばれ、複数のタスクやプロセスを同時に実行することを指します。これにより、プログラムは複数のタスクを同時に処理することができ、応答性と全体的なパフォーマンスが向上します。並行性は、CPUコア、I/Oデバイス、ネットワーク接続などのシステムリソースを効果的に活用するため、プログラムのパフォーマンス向上に重要です。プログラムは、多くの活動を同時に実行することで、これらのリソースを効率的に使用し、アイドル時間を減らすことができます。これにより、実行が高速化し、効率が向上します。 並行性と並列性の違い 並行性と並列性は関連する概念ですが、明確な違いがあります: 並行性:「並行性」は、システムが多くの活動を同時に実行する能力を指します。並行システムでは、タスクが同時に実行されないかもしれませんが、交互に進むことができます。複数のタスクを同時に調整することが主な目標です。 並列性:一方、並列性は、異なる処理ユニットやコアに割り当てられた複数のタスクを同時に実行することを意味します。並列システムでは、タスクは同時にかつ並列に実行されます。困難をより管理しやすいアクションに分割し、それらを同時に実行してより速い結果を得ることに重点が置かれています。 多くのタスクを同時に実行して、それらが重なり合い、同時に進行するように管理することを並行性と呼びます。一方、並列性は、異なる処理ユニットを使用して多くのタスクを同時に実行することを意味します。Pythonでは、マルチスレッドとマルチプロセスを使用することで、並行性と並列プログラミングを実現することができます。マルチプロセスを使用して多くのプロセスを同時に実行することで並列性を実現し、マルチスレッドを使用して単一のプロセス内で多くのスレッドを実行することで並行性を実現します。 マルチスレッドによる並行性 import threading import…
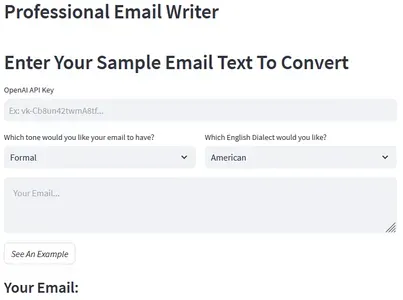
「OpenAIとLangchainを使用した言語的なメール作成Webアプリケーション」
はじめに この記事では、Langchainの助けを借りてOpenAIを使用してウェブアプリケーションを構築する方法について説明します。このウェブアプリは、ユーザーが非構造化のメールを正しくフォーマットされた英語に変換することができます。ユーザーはメールのテキストを入力し、希望するトーンと方言(フォーマル/インフォーマルおよびアメリカン/ブリティッシュイングリッシュ)を指定することができます。アプリは選択したスタイルで美しくフォーマットされたメールを提供します。私たちは毎回スケールアプリケーションを構築することはできません。クエリとともにプロンプトをコピーして貼り付けるだけではありません。代わりに、さあ始めましょう、そしてこの素晴らしい「Professional Email Writer」ツールを構築しましょう。 学習目標 Streamlitを使用して美しいウェブアプリケーションを構築する方法を学ぶ。 プロンプトエンジニアリングとは何か、メールの生成に効果的なプロンプトを作成する方法を理解する。 LangchainのPromptTemplateを使用してOpenAI LLMをクエリする方法を学ぶ。 Streamlitを使用してPythonアプリケーションをデプロイする方法を学ぶ。 この記事はData Science Blogathonの一部として公開されました。 Streamlitのセットアップ まず、Streamlitが何であるか、どのように機能するか、そしてユースケースに設定する方法を理解する必要があります。Streamlitを使用すると、Pythonでウェブアプリケーションを作成し、ローカルおよびWeb上でホストすることができます。まず、ターミナルに移動し、以下のコマンドを使用してStreamlitをインストールします。 pip install streamlit スクリプト用の空のPythonファイルを作成し、以下のコマンドを使用してファイルを実行します。 python -m streamlit run [your_file_name.py]…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.