Learn more about Search Results BLOOM - Page 7

- You may be interested
- 「最も強力な機械学習モデルの解説(トラ...
- ChatGPTを使ってデータサイエンスの仕事を...
- 「人工的な汎用知能(Artificial General ...
- 「アジャイルを活用したデータサイエンス...
- 「現代の好み引き出しにおける回帰とベイ...
- アナリティクスを台無しにするステークホ...
- 中国の研究者がCogVLMを紹介:パワフルな...
- FMOps / LLMOps:生成型AIの運用化とMLOps...
- 単一のマシンで複数のCUDAバージョンを管...
- この中国のAI研究は、ベートーヴェン、ク...
- 「ODSC West Bootcamp Roadmapのご紹介 &#...
- 「Giskard の紹介 AI モデルのためのオー...
- オーディオデータセットの完全ガイド
- VoAGI ニュース、9月27日:ChatGPT プロジ...
- このAI論文は、大規模な言語モデルを最適...

ラングチェーン101:パート2ab (大規模な言語)モデルについて知っておくべきすべて
(次を見逃さないように、著者をフォローしてください...」

アマゾンセージメーカーでのLlama 2のベンチマーク
大型言語モデル(LLM)や他の生成型AIモデルの展開は、計算要件とレイテンシのニーズのために課題となることがあります。Hugging Face LLM Inference Containerを使用してAmazon SageMaker上でLlama 2を展開する企業に有用な推奨事項を提供するために、Llama 2の60以上の異なる展開設定を分析した包括的なベンチマークを作成しました。 このベンチマークでは、さまざまなサイズのLlama 2をAmazon EC2インスタンスのさまざまなタイプでさまざまな負荷レベルで評価しました。私たちの目標は、レイテンシ(トークンごとのミリ秒)とスループット(秒あたりのトークン数)を測定し、次の3つの一般的なユースケースに最適な展開戦略を見つけることです: 最も費用対効果の高い展開:低コストで良好なパフォーマンスを求めるユーザー向け 最高のレイテンシ展開:リアルタイムサービスのレイテンシを最小限に抑えるための展開 最高のスループット展開:秒あたりの処理トークンを最大化するための展開 このベンチマークを公正かつ透明で再現可能なものにするために、使用したすべてのアセット、コード、データを共有しています: GitHubリポジトリ 生データ 処理済みデータのスプレッドシート 私たちは、顧客がLLMsとLlama 2を効率的かつ最適に自社のユースケースに使用できるようにしたいと考えています。ベンチマークとデータに入る前に、使用した技術と手法を見てみましょう。 Amazon SageMaker上のLlama 2のベンチマーク Hugging…
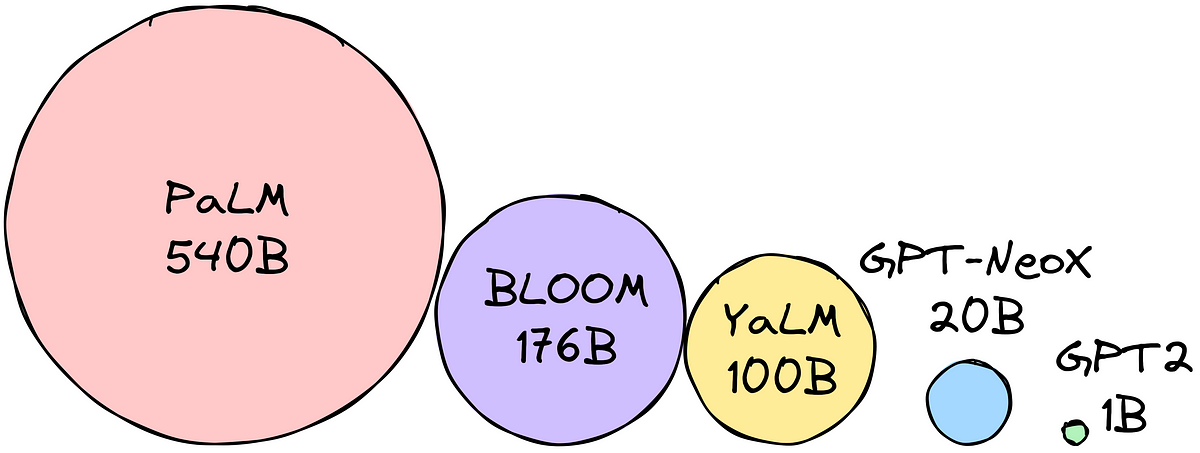
小さなメモリに大きな言語モデルを適合させる方法:量子化
大型言語モデルは、テキスト生成、翻訳、質問応答などのタスクに使用することができますしかし、LLM(大型言語モデル)は非常に大きく、多くのメモリを必要とします…

「修理の闘い」
「修理の権利を巡る闘いが消費者に有利に傾いている方法」

「AIはどれくらい環境に優しいのか?人間の作業と人工知能の二酸化炭素排出量を比較する」
近年、人工知能(AI)は驚異的な進展を遂げ、その応用は医療、銀行業、交通、環境保護などさまざまな産業に広がっています。しかし、AIの利用が広がるにつれて、環境への影響に関する懸念が浮上しています。特に、AIモデルの稼働と訓練に必要なエネルギーとそれによる温室効果ガスの排出についての懸念です。例えば、現在使用されている最も強力なAIシステムの1つであるGPT-3は、トレーニング中において、その寿命の間に5台の車によって生成される排出物と同等の排出物を生成します。 最近の研究では、多数のAIシステムの環境への影響が調査されており、特に文章の作成や絵画制作などのタスクを実行する能力に焦点が当てられています。研究チームは、ChatGPT、BLOOM、DALL-E2、MidjourneyといったさまざまなAIシステムによって生成される排出物と、同じタスクを人間が実行した場合に生じる排出物とを比較しました。文章の作成と画像の制作という2つの一般的なタスクが特に注目されました。 この研究の目的は、人間がこれらのタスクを実行する場合とAIが実行する場合の環境への影響を対比することです。研究チームは、AIに関連する環境費用にもかかわらず、これらのコストが通常人間が同様の活動を行う場合よりも低いことを示すことで、人間とAIの交換可能性を強調しました。結果は、言葉を生成する場合に驚くほどの差があることを示しています。 テキストを作成する際、AIシステムは人間が生成する二酸化炭素換算量(CO2e)の130倍から1500倍少なくなります。この大きな違いは、この状況でのAIの環境上の利点を強調しています。同様に、画像を作成する際、AIシステムは人間が生成するCO2eの310倍から2900倍少なくなります。これらの数字は、AIを使用して画像を作成する際にどれだけ少ない排出物が生成されるかを明確に示しています。 研究チームは、排出物の研究だけでは完全な情報を提供することができないことを理解することが重要であり、以下の重要な社会的な影響や要素が考慮される必要があることを共有しました。 職業的な置き換え:一部の産業では、AIが従来人間が担当してきた仕事を引き受けることによって、雇用の置き換えが生じる可能性があります。この置き換えの潜在的な経済的および社会的影響を適切に対処することが重要です。 合法性:AIシステムが道徳的および法的な原則に従って開発・利用されることが重要です。AIによって生成されるコンテンツの合法性とその潜在的な悪用に対処する必要があります。 リバウンド効果:AIがさまざまな産業に導入されると、予期せぬ影響が生じる場合があります。これらの結果は、使用量や生産量の増加として現れる可能性があります。 AIによっては代替できない人間の機能もあることを理解することが重要です。AIは、人間の創造性、共感性、意思決定を必要とする一部のタスクやポジションを行うことはできません。ただし、現在の研究は、さまざまなタスクにおいて人間と比較してAIが排出物を劇的に削減する可能性があることを示しています。これらの結果は環境の観点からは励みとなりますが、AIの統合が共有された目標と価値観に一致するように、より広範な倫理的、経済的、社会的要素の文脈で考慮される必要があります。排出物を大幅に減らすためにAIを使用するというアプローチは、現在の環境問題を解決するための有効な手段です。
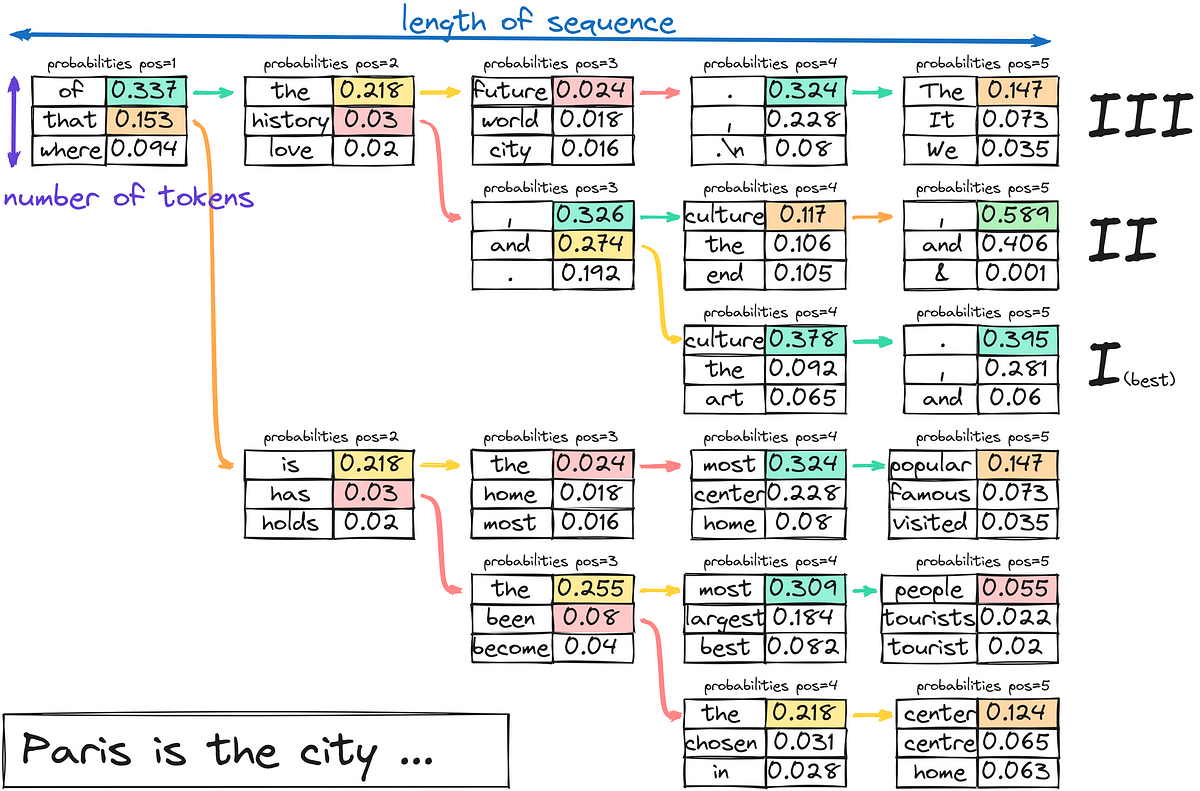
「LLMはどのようにテキストを生成するのか?」
今日は、3つ目のステップに集中します-テキストのデコードと生成最初の2つのステップに興味がある場合は、以下にコメントしてくださいそれらのトピックもカバーすることを検討しますさあ、少し潜りましょう...
「ゼロからLLMを構築する方法」
「これは、大規模言語モデル(LLM)を実践的に使用するシリーズの6番目の記事です以前の記事では、プロンプトエンジニアリングとファインチューニングを通じて事前学習済みのLLMを活用する方法について詳しく調査しましたこれらに対して…」

「MicrosoftのAI研究者が誤って大量のデータを公開」
クラウドセキュリティ企業Wizの科学者たちは、Microsoftの人工知能研究者が誤って大量の個人データを侵害していたことを発見しました

「アマゾン、無人レジ技術を衣料品店に適用」
大手小売り企業AmazonのJust Walk Out無人レジショッピング技術の衣料品向け新バージョンは、アパレルを無線周波数識別(RFID)によって追跡します

「ベイチュアン2に会おう:7Bおよび13Bのパラメータを持つ大規模な多言語言語モデルのシリーズ、2.6Tトークンでゼロからトレーニングされました」
大規模言語モデルは近年、大きな進展を遂げています。GPT3、PaLM、Switch Transformersなどの言語モデルは、以前のELMoやGPT-1のようなモデルの数百万から、数十億、あるいは数兆のパラメータを持つようになりました。人間に似た流暢さを持ち、様々な自然言語の活動を行う能力は、モデルのサイズの成長により大幅に向上しました。OpenAIのChatGPTのリリースにより、これらのモデルが人間の話し言葉に似たテキストを生成する能力が大いに注目されました。ChatGPTは、カジュアルな会話から難しいアイデアの明確化まで、さまざまな文脈で優れた言語スキルを持っています。 この革新は、自然言語の生成と理解を必要とするプロセスを自動化するために、巨大な言語モデルがどのように使用されるかを示しています。LLMの革新的な開発と使用が進んでいるにもかかわらず、GPT-4、PaLM-2、ClaudeなどのトップのLLMのほとんどはまだクローズドソースです。モデルのパラメータについて開発者や研究者が部分的なアクセスしか持てないため、このコミュニティがこれらのシステムを徹底的に分析や最適化することは困難です。LLMの透明性とオープンさがさらに向上することで、この急速に発展している分野での研究と責任ある進歩が加速される可能性があります。Metaが作成した巨大な言語モデルのコレクションであるLLaMAは、完全にオープンソースであることにより、LLMの研究コミュニティに大いに役立っています。 OPT、Bloom、MPT、Falconなどの他のオープンソースLLMとともに、LLaMAのオープンな設計により、研究者はモデルに自由にアクセスし、分析、テスト、将来の開発を行うことができます。このアクセシビリティとオープンさにより、LLaMAは他のプライベートLLMとは一線を画しています。Alpaca、Vicunaなどの新しいモデルは、オープンソースLLMの研究と開発のスピードアップによって可能になりました。しかし、英語はほとんどのオープンソースの大規模言語モデルの主な焦点となっています。たとえば、LLaMAの主なデータソースであるCommon Crawl1は、67%の事前学習データを含んでいますが、英語の資料しか含むことが許可されていません。MPTやFalconなど、異なる言語の能力に制約のあるフリーソースLLMも主に英語に焦点を当てています。 そのため、中国語などの特定の言語でのLLMの開発と使用は困難です。Baichuan Inc.の研究者は、この技術的な研究で、広範な多言語言語モデルのグループであるBaichuan 2を紹介しています。Baichuan 2には、13兆パラメータを持つBaichuan 2-13Bと7兆パラメータを持つBaichuan 2-7Bの2つの異なるモデルがあります。両モデルは、Baichuan 1よりも2.6兆トークン以上のデータを使用してテストされました。Baichuan 2は、大量のトレーニングデータにより、Baichuan 1を大幅に上回るパフォーマンスを発揮します。Baichuan 2-7Bは、MMLU、CMMLU、C-Evalなどの一般的なベンチマークで、Baichuan 1-7Bよりも約30%優れたパフォーマンスを示します。Baichuan 2は特に数学とコーディングの問題のパフォーマンスを向上させるように最適化されています。 Baichuan 2は、GSM8KとHumanEvalのテストでBaichuan 1の結果をほぼ2倍に向上させます。また、Baichuan 2は医療および法律の領域の仕事でも優れた成績を収めています。MedQAやJEC-QAなどのベンチマークで他のオープンソースモデルを上回り、ドメイン特化の最適化のための良い基礎モデルとなっています。彼らはまた、人間の指示に従う2つのチャットモデル、Baichuan 2-7B-ChatとBaichuan 2-13B-Chatを作成しました。これらのモデルは、対話や文脈を理解するのに優れています。彼らはBaichuan 2の安全性を向上させるための戦略についてさらに詳しく説明します。これらのモデルをオープンソース化することで、大規模言語モデルのセキュリティをさらに向上させながら、LLMの責任ある作成に関する研究を促進することができます。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.