Learn more about Search Results 6 - Page 7

- You may be interested
- スタンフォード大学の研究者が、大規模言...
- 「境界を超える:LLMsの関数呼び出しの探求」
- 「パーソナライズされたパッケージソリュ...
- Hugging Face Datasets での作業
- 「ミット、ハーバード、ノースイースタン...
- このAIツールでデータを即座に視覚化する
- このAIニュースレターは、あなたが必要な...
- 「ハックからハーモニーへ:レコメンデー...
- 「盲目的なキャリブレーションによる無線...
- 「Googleは、ヘルスケアとライフサイエン...
- AIがVRデバイスのユーザーエクスペリエン...
- ChatGPT、GPT-4、Bard、およびClaudeを検...
- 「機械学習のための現実世界のデータ収集...
- 予想外な方法でAIがイスラエル・ハマス戦...
- In Japanese, the title would be written...
このAIニュースレターは、あなたが必要とするすべてです#65
今週のAIでは、AI規制に関する進展がありましたエロン・マスクやマーク・ザッカーバーグなどのテックリーダーが60人以上の上院議員とAIについて話し合いましたが、彼らは皆同意しました-

「PhysObjectsに会いましょう:一般的な家庭用品の36.9K個のクラウドソーシングと417K個の自動物理的概念アノテーションを含むオブジェクト中心のデータセット」
現実世界では、情報はしばしばテキスト、画像、または動画の組み合わせによって伝えられます。この情報を効果的に理解し、対話するためには、AIシステムは両方のモダリティを処理できる必要があります。ビジュアル言語モデルは、自然言語理解とコンピュータビジョンの間のギャップを埋め、より包括的な世界の理解を可能にします。 これらのモデルは、テキストとビジュアル要素を組み込んだ豊かで文脈に即した説明、ストーリー、または説明を生成することができます。これは、マーケティング、エンターテイメント、教育など、さまざまな目的のコンテンツを作成するために役立ちます。 ビジュアル言語モデルの主なタスクには、ビジュアルクエスチョンアンサリングと画像キャプションがあります。ビジュアルクエスチョンアンサリングでは、AIモデルに画像とその画像に関するテキストベースの質問が提示されます。モデルはまずコンピュータビジョンの技術を使用して画像の内容を理解し、NLPを使用してテキストの質問を処理します。回答は理想的には画像の内容を反映し、質問に含まれる特定のクエリに対応する必要があります。一方、画像キャプションでは、画像の内容を説明する記述的なテキストキャプションや文を自動生成することが含まれます。 現在のビジュアル言語モデルは、一般的なオブジェクトの物質の種類や壊れやすさなどの物理的な概念を捉えることを改善する必要があります。これにより、物体の物理的な推論を必要とするロボットの識別タスクが非常に困難になります。この問題を解決するために、スタンフォード大学、プリンストン大学、Google DeepMindの研究者らはPhysObjectsを提案しています。これは、一般的な家庭用品の36.9Kのクラウドソースおよび417Kの自動物理的概念アノテーションのオブジェクト中心のデータセットです。クラウドソースのアノテーションは、分散グループの個人を使用して大量のデータを収集し、ラベル付けする方法です。 彼らは、PhysObjectsでファインチューンされたVLMが物理的な推論能力を大幅に向上させることを示しました。物理的に基礎づけられたVLMは、保持データセットの例において予測精度が向上しています。彼らはこの物理的に基礎づけられたVLMをLLMベースのロボットプランナーと組み合わせてその利点をテストしました。LLMはシーン内のオブジェクトの物理的な概念についてVLMにクエリを行います。 研究者は、EgoObjectsデータセットを画像ソースとして使用しました。これは、PhysObjectsを構築する際に公開された最大の実オブジェクト中心のデータセットでした。リアルな家庭の配置のビデオで構成されているため、家庭用ロボティクスのトレーニングに関連しています。平均して、117,424枚の画像、225,466個のオブジェクト、4,203個のオブジェクトインスタンスIDが含まれています。 彼らの結果は、物理的に基礎づけられたVLMを使用しないベースラインと比較して、物理的な推論を必要とするタスクの計画パフォーマンスが向上したことを示しています。彼らの今後の研究では、幾何学的な推論や社会的な推論など、物理的な推論を超えて拡大する予定です。彼らの手法とデータセットは、VLMを用いたより洗練された推論のための第一歩です。

「LLM製品を開発するのは難しい – これが6つの主要な課題です」
∘ 紹介 ∘ チャレンジ1:「AI戦略」の不足 ∘ チャレンジ2:データの制約 ∘ チャレンジ3:プライバシー/セキュリティの懸念 ∘ チャレンジ4:コンテキストウィンドウ ∘ チャレンジ5:プロンプトエンジニアリング ∘…
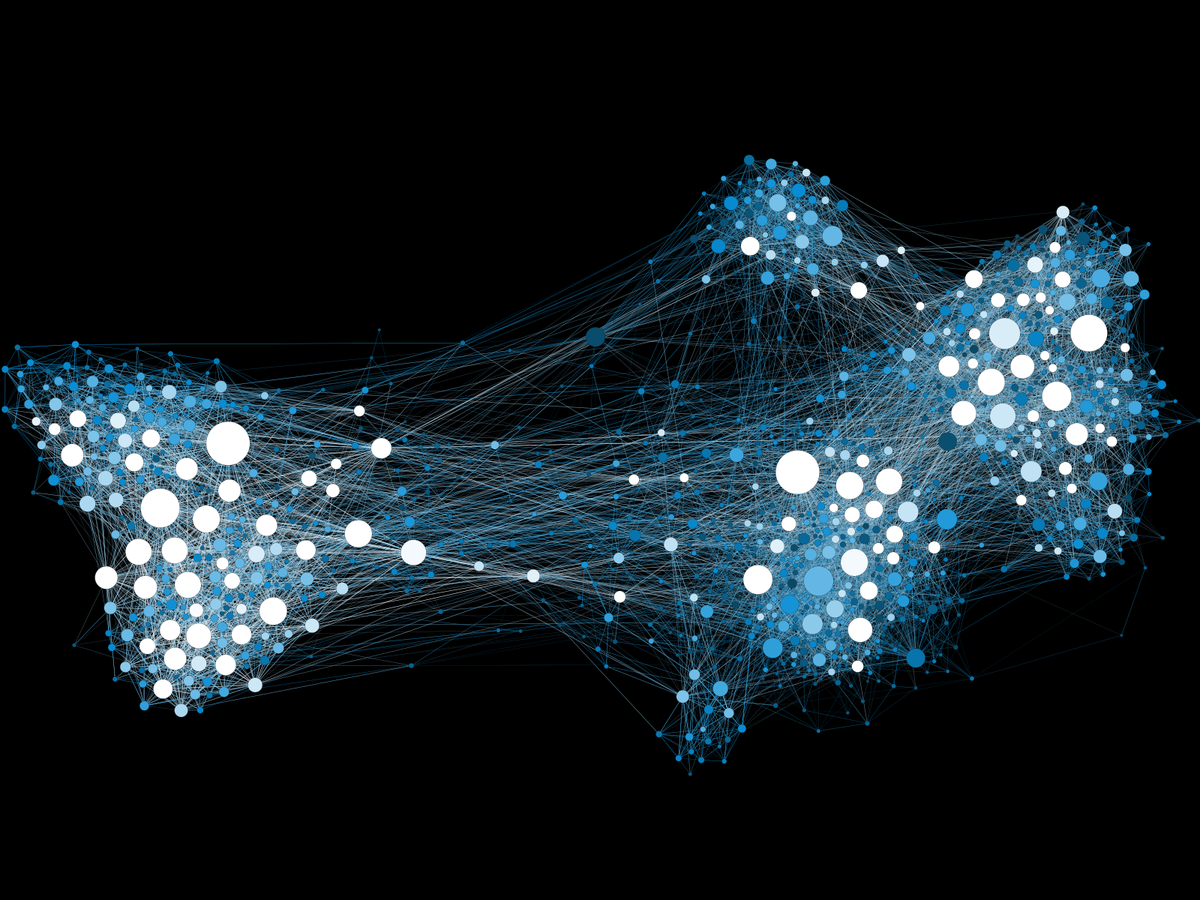
シミュレーション106:ネットワークを用いた情報拡散と社会伝染のモデリング
「ソーシャルメディアは情報の風景を完全に変革しました人類史上でこれほどお互いにつながっていることはありませんニュース記事は瞬時に私たちに届き、アイデア...」

「AIとMLが高い需要になる10の理由」 1. ビッグデータの増加による需要の増加:ビッグデータの処理と分析にはAIとMLが必要です 2. 自動化の需要の増加:AIとMLは、自動化されたプロセスとタスクの実行に不可欠です 3. 予測能力の向上:AIとMLは、予測分析において非常に効果的です 4. パーソナライズされたエクスペリエンスの需要:AIとMLは、ユーザーの行動と嗜好を理解し、パーソナライズされたエクスペリエンスを提供するのに役立ちます 5. 自動運転技術の需要の増加:自動運転技術の発展にはAIとMLが不可欠です 6. セキュリティの需要の増加:AIとMLは、セキュリティ分野で新たな挑戦に対処するために使用されます 7. ヘルスケアの需要の増加:AIとMLは、病気の早期検出や治療計画の最適化など、医療分野で重要な役割を果たします 8. クラウドコンピューティングの需要の増加:AIとMLは、クラウドコンピューティングのパフォーマンスと効率を向上させるのに役立ちます 9. ロボティクスの需要の増加:AIとMLは、ロボットの自律性と学習能力を高めるのに使用されます 10. インターネットオブシングス(IoT)の需要の増加:AIとMLは、IoTデバイスのデータ分析と制御に重要な役割を果たします
「2024年におけるAIとMLの需要急増を促している10の主要な要因を発見し、さまざまな産業で探求しましょう技術の未来を探索しましょう」

VoAGIニュース、9月6日:VoAGIの30周年おめでとうございます! • 5つのステップでPythonデータ構造を始めよう
「VoAGI設立30周年おめでとうございます!• 5つのステップでPythonデータ構造を始めよう • VoAGI設立30周年記念 グレゴリー・ピアテツキー・シャピロ創設者インタビュー」
このAIニュースレターは、あなたが必要なすべてです#63
「AIの今週のハイライトでは、Large Language Models(LLM)の採用による西洋市場での収益成長のさらなる証拠と、新しいAIモデルの導入を紹介しています...」

オラクルと一緒にXRを開発しよう、エピソード6 AIサマライザー+ジェネレーター
このチュートリアルでは、ユーザーの周囲からのさまざまな入力を使用し、それをAIで処理し、要約/生成AIを返すミックスドリアリティアプリの完全なソースを提供します

「初心者であることを知られずに伝える、6つのパンダの間違い」
私たちはみな、コードを書いている最中に頻繁に現れる大きくて太くて赤いエラーメッセージに慣れています幸いなことに、私たちは常にそれらのエラーを修正するため、人々はそれに気づきませんしかし、見逃されるミスはどうでしょうか...
このAIニュースレターは、あなたが必要とするすべてです#62
今週は、METAのコーディングモデルの開発とOpenAIの新しいファインチューニング機能の進展を見てきましたMetaは、Code LLaMAという大規模な言語モデルを導入しましたこのモデルは…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.