Learn more about Search Results 物流 - Page 7

- You may be interested
- 「ESRBは、顔認識技術を使って人々の年齢...
- 「迅速な最適化スタック」
- Python Pandasを使用して、散らかった車の...
- 「OpenAIのGPTストアで稼ぐための11のカス...
- 「CNNによる特徴抽出の探求」
- 原因図:観察データのアキレス腱への立ち...
- 『ChatGPTや他のチャットボットの安全コン...
- 「LG AI Researchが提案するQASA:新しいA...
- 「物理学と流体力学に応用されたディープ...
- このAI論文は、「テキストに基づくローカ...
- 市民データサイエンティストとは誰で、何...
- アリババの研究者たちは、ChatGPTのような...
- 『チャットボットは実際に認識されるより...
- 「LoRAとQLoRAを用いた大規模言語モデルの...
- オッターに会いましょう:大規模データセ...

人工知能における最良優先探索
人工知能は私たちの生活の一部となり、日常の活動を支援しています。コンピュータ、ガジェット、その他の機器に関しても、AIベースのアルゴリズムモデルは私たちのタスクと時間管理を容易にするのに役立ちます。AIの分野で特定のアルゴリズムの1つは、最良優先探索です。これは、各ステップで正しいパスの選択を支援するスマートなエクスプローラのように振る舞います。人工知能の最も優れた探索は、私たちのタスクを簡素化し、取り組みやすく時間を節約し、効率的な意思決定とより速い目標達成を実現します。 最良優先探索とは何ですか? 最良優先探索(BFS)は、特定のルールで機能し、優先度付きキューとヒューリスティック探索を使用する探索アルゴリズムです。これはコンピュータが迷路の可能性の中で適切で最短のパスを評価するのに理想的です。迷路に閉じ込められてどのようにして素早く出口に到達すればよいかわからない場合を想像してみてください。ここで、人工知能の最良優先探索は、システムプログラムがゴールにできるだけ早く到達するために、毎回のステップで正しいパスを評価して選択するのを支援します。 例えば、スーパーマリオや魂斗羅のビデオゲームをプレイしているとしましょう。最良優先探索はコンピュータシステムがマリオや魂斗羅を制御し、最も速いルートや敵を倒す方法を調べるのを支援します。異なるパスを評価し、ゴールに到達し敵をできるだけ早く倒すための他の脅威のない最も近いパスを選択します。 最良優先探索は、数多くの利用可能なノードの中から有望なノードを選択するために評価関数を利用する知識のある探索です。最良優先探索アルゴリズムは、グラフ空間を検索する際にトラバースするノードを監視する2つのリスト、つまりオープンリストとクローズドリストを使用します。オープンリストは現在トラバース可能なノードを監視し、クローズドリストは既に転送されたノードを監視します。 BFSの主要な概念 以下は最良優先探索の主要な特徴です: パスの評価 最良優先探索を使用する場合、システムは常に選択可能なノードまたはパスを探し、最短距離のノードまたはパスをトラバースしてゴールに到達し迷路を脱出するために最も有望なノードまたはパスを選択します。 ヒューリスティック関数の使用 最良優先探索はヒューリスティック関数を使用して知識のある意思決定を行います。これにより、ゴールに向かう正しいかつ迅速なパスが見つかります。迷路内のユーザーの現在の状態がこの関数の入力となり、ユーザーがゴールにどれだけ近いかを推定します。分析に基づいて、最短の時間と最小のステップでゴールに到達するのを支援します。 トラックの保持 最良優先探索アルゴリズムは、コンピュータシステムがトラバースしたりトラバースする予定のパスやノードを追跡するのを支援します。これにより、システムが以前にテストしたパスやノードのループに巻き込まれるのを防ぎ、エラーを回避します。 プロセスの繰り返し コンピュータプログラムは、上記の3つの基準のプロセスを目標に到達し迷路を脱出するまで繰り返します。したがって、最良優先探索はヒューリスティック関数に基づいて最も有望なノードやパスを繰り返し評価します。 ヒューリスティック関数とは何ですか? ヒューリスティック関数は、ゴールに至る最良のパス、ルート、または解を知識のある探索および評価に使用される関数を指します。これにより、最短時間で正しいパスを推定するのに役立ちます。ただし、ヒューリスティック関数は常に正確な結果や最適化された結果を提供するわけではありません。時にはサブオプティマルな結果を生成することもあります。ヒューリスティック関数はh(n)と呼ばれ、状態のペア間の最適ルートまたはパスのコストを計算し、その値は常に正の値です。 アルゴリズムの詳細 探索アルゴリズムには基本的に2つのカテゴリがあります: 非統一アルゴリズム これは盲目的な方法または網羅的な方法とも呼ばれます。追加情報なしで検索が行われるため、問題の記述で既に与えられた情報に基づいています。例えば、深さ優先探索と幅優先探索があります。 情報利用アルゴリズム コンピューターシステムは、追加の情報に基づいて検索を実行し、ソリューションや目標への経路の評価のための次のステップを記述することができます。このような方法はヒューリスティックメソッドまたはヒューリスティック探索として広く知られています。情報利用アルゴリズムは、費用対効果、効率性、総合的なパフォーマンスの面で、盲目的な方法よりも優れています。 情報利用アルゴリズムには、一般的に2つのバリアントがあります。…
「洗練されたアルゴリズムなしで予測指標とプロセスを改善するにはどうすればいいですか?」
記述的な分析を開発することで、需要計画のKPIとプロセスの効率を改善するための重点領域を特定することができます
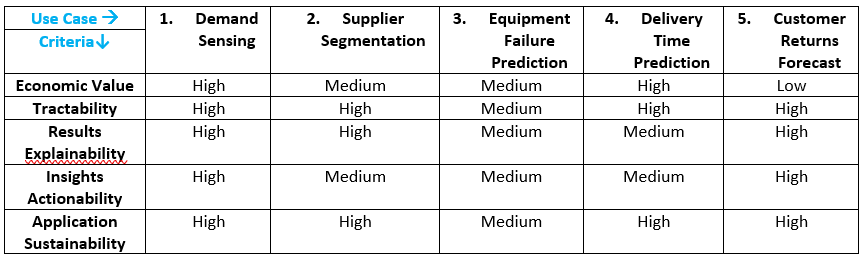
AI/MLを活用してインテリジェントなサプライチェーンを構築するための始め方
「異なる供給チェーンの要素に対するAI/MLの使用事例と価値提案:計画、調達、製造、配送、逆物流」

「アメリカのトップ10データサイエンス企業」
アメリカは先進技術の中心地であり、競争の傾向が増しています。各企業は、データ分析、機械学習、人工知能などに関連するさまざまなアルゴリズムとモデルを扱うために、最高のテックエキスパートを採用しています。デジタル時代において、アメリカのデータサイエンス企業は、技術と分析のリーディングカンパニーです。これらの企業は、データの力を利用して市場に独自のイノベーションをもたらすために重要な役割を果たしています。データサイエンスの力を活用して、重要な問題の解決策を提供し、情報に基づいたビジネスの意思決定を行い、企業の成長と成功率を最適化しています。 トップデータサイエンス企業の売上比較 以下は、これらのトップアメリカのデータサイエンス企業の売上に関する最新情報です: 企業 売上 Amazon 1344億ドル Apple 948億ドル Google 743億ドル Microsoft 527億ドル Facebook 320億ドル IBM 155億ドル Uber 92億ドル Netflix 819億ドル LinkedIn 41億ドル Airbnb…
AIにおけるブロックチェーンの包括的なレビュー
AIとブロックチェーンは、近年最も画期的な技術革新として浮上しています人工知能(AI):機械やコンピュータが人間の思考や意思決定プロセスを模倣することを可能にしますブロックチェーン:分散型で変更不可能な台帳で、データや情報を分散化された信頼性の高い方法で安全に保存します最近、科学者たちは潜在的な探求に没頭しています[…]

「マーケティングにおける人工知能の短いガイド」
「デジタルマーケティングにおける人工知能の役割や、ビジネスにおける他のAIツールがデータに基づく意思決定に与える影響について学びましょう」
「短期予測を改善したいですか?デマンドセンシングを試してみてください」
従来の予測手法の精度が頭打ちになった場合、AI/MLを使用して顧客注文のパターンをモデリングすることで、さらなる予測の改善を推進します

高性能意思決定のためのRLHF:戦略と最適化
はじめに 人間の要因/フィードバックからの強化学習(RLHF)は、RLの原則と人間のフィードバックを組み合わせた新興の分野です。これは、現実世界の複雑なシステムにおいて意思決定を最適化し、パフォーマンスを向上させるように設計されます。高性能のRLHFは、さまざまなドメインの設計、使いやすさ、安全性を向上させるために、人間の行動、認知、文脈、知識、相互作用を理解することに焦点を当てています。 RLHFは、機械中心の最適化と人間中心の設計のギャップを埋めるために、RLアルゴリズムと人間要因の原則を統合することを目指しています。研究者は、人間のニーズ、好み、能力に適応するインテリジェントシステムを作成し、ユーザーエクスペリエンスを最適化することを目指しています。RLHFでは、計算モデルが人間の反応をシミュレート、予測、予測し、個人が情報に基づいた意思決定を行い、複雑な環境との相互作用をどのように行うのかについての洞察を得ることができます。これらのモデルを強化学習アルゴリズムと組み合わせることを想像してみてください! RLHFは、意思決定プロセスを最適化し、システムのパフォーマンスを向上させ、今後数年間で人間と機械の協力を向上させることを目指しています。 学習目標 RLHFの基礎と人間中心の設計における重要性を理解することが最初で最も重要なステップです。 さまざまなドメインでの意思決定の最適化とパフォーマンスを向上させるためのRLHFの応用を探求します。 強化学習、人間要因工学、適応インターフェースなど、RLHFに関連する主要なトピックを特定します。 知識グラフがデータ統合とRLHFの研究および応用における洞察を促進する役割を認識します。 RLHF:人間中心のドメインを革新する 人間要因を活用した強化学習(RLHF)は、人間要因が重要なさまざまな分野を変革する可能性があります。人間の認知的制約、行動、相互作用の理解を活かして、個別のニーズに合わせた適応的なインターフェース、意思決定支援システム、支援技術を作成します。これにより、効率性、安全性、ユーザー満足度が向上し、業界全体での採用が促進されます。 RLHFの進化の中で、研究者は新しい応用を探求し、人間要因を強化学習アルゴリズムに統合する課題に取り組んでいます。計算モデル、データ駆動型アプローチ、人間中心の設計を組み合わせることで、RLHFは高度な人間と機械の協力、意思決定の最適化、パフォーマンスの向上を可能にしています。 なぜRLHFが重要なのか? RLHFは、ヘルスケア、金融、交通、ゲーム、ロボティクス、サプライチェーン、顧客サービスなど、さまざまな産業にとって非常に価値があります。 RLHFにより、AIシステムは人間の意図とニーズにより合わせて学習できるため、広範なアプリケーションでの快適で安全かつ効果的な使用が可能になります。 なぜRLHFが価値があるのか? 複雑な環境でのAIの活用はRLHFの得意とするところです。多くの産業では、AIシステムが運用する環境は通常複雑でモデル化が難しいです。一方、RLHFではAIシステムが人間の要因から学び、効率と精度の面で従来のアプローチが失敗する複雑なシナリオに適応することができます。 RLHFは責任あるAIの行動を促進し、人間の価値観、倫理、安全性に合わせることができます。これらのシステムへの継続的な人間のフィードバックは、望ましくない行動を防ぐのに役立ちます。一方、RLHFは人間の要因、判断、優先順位、好みを組み込むことで、エージェントの学習の旅をガイドする別の方法を提供します。 効率の向上とコストの削減知識グラフやAIシステムのトレーニングによる試行錯誤の必要性があります。特定のシナリオでは、両方ともダイナミックな状況で迅速に採用できます。 リアルタイム適応のためのRPAと自動化を可能にするほとんどの産業は既にRPAまたは一部の自動化システムを使用しており、AIエージェントが迅速に状況の変化に適応する必要があります。 RLHFはこれらのエージェントが人間のフィードバックを受けて即座に学習し、不確実な状況でもパフォーマンスと精度を向上させるのに役立ちます。私たちはこれを「意思決定インテリジェンスシステム」と呼んでいます。RDF(リソース開発フレームワーク)は同じシステムにセマンティックウェブ情報をもたらすことさえでき、情報に基づいた意思決定に役立ちます。 専門知識のデジタル化:すべての産業領域で専門知識は重要です。RLHFの助けを借りて、AIシステムは専門家の知識から学ぶことができます。同様に、知識グラフとRDFを使用すると、専門家のデモンストレーション、プロセス、問題解決の事実、判断能力からこの知識をデジタル化することができます。 RLHFは知識をエージェントに効果的に伝達することもできます。 ニーズに合わせたカスタマイズ:AIシステムは通常、ユーザーや専門家からのフィードバックを収集し、現実世界のシナリオで運用されるため、継続的な改善が必要です。フィードバックと意思決定に基づいてAIを継続的に改善することができます。…

「AIとMLが高い需要になる10の理由」 1. ビッグデータの増加による需要の増加:ビッグデータの処理と分析にはAIとMLが必要です 2. 自動化の需要の増加:AIとMLは、自動化されたプロセスとタスクの実行に不可欠です 3. 予測能力の向上:AIとMLは、予測分析において非常に効果的です 4. パーソナライズされたエクスペリエンスの需要:AIとMLは、ユーザーの行動と嗜好を理解し、パーソナライズされたエクスペリエンスを提供するのに役立ちます 5. 自動運転技術の需要の増加:自動運転技術の発展にはAIとMLが不可欠です 6. セキュリティの需要の増加:AIとMLは、セキュリティ分野で新たな挑戦に対処するために使用されます 7. ヘルスケアの需要の増加:AIとMLは、病気の早期検出や治療計画の最適化など、医療分野で重要な役割を果たします 8. クラウドコンピューティングの需要の増加:AIとMLは、クラウドコンピューティングのパフォーマンスと効率を向上させるのに役立ちます 9. ロボティクスの需要の増加:AIとMLは、ロボットの自律性と学習能力を高めるのに使用されます 10. インターネットオブシングス(IoT)の需要の増加:AIとMLは、IoTデバイスのデータ分析と制御に重要な役割を果たします
「2024年におけるAIとMLの需要急増を促している10の主要な要因を発見し、さまざまな産業で探求しましょう技術の未来を探索しましょう」

自動小売りチェックアウトは、ラベルのない農産物をどのように認識するのか? PseudoAugmentコンピュータビジョンアプローチとの出会い
機械学習とディープラーニングの技術の進歩により、さまざまな次元の自動化が増えています。自動化により、特に小売業において、日常生活の様々なルーチン的な側面での人間の介入の必要性が徐々に減少しています。 これらは、自然資源の追跡や環境の持続可能性にも貢献しています。自動化システムは、在庫管理、需要予測、物流調整の向上により、サプライチェーンを最適化するのに役立ちます。しかし、自動化が困難で複雑な場合もあります。バーコードのない製品の識別はその一例です。 自動精算ステーションで消費者に適切に請求するためには、重さのあるオブジェクトを識別する能力が必要です。このようなシステムは、様々な種類の包装されていない生鮮食品、穀物、その他の商品を識別できなければなりません。一般的に、多くの小売店では、顧客は製品コードを覚え、部門で商品を計量して果物や野菜の種類を識別する必要があります。 この問題を解決するために、Skoltechと他の機関の研究者がスーパーマーケットで重量物を識別する新しい方法を考案しました。研究者たちは、このプロセスを支援するためにコンピュータビジョンを使用しました。このアプローチにより、新しい品種が導入されてもニューラルネットワークのトレーニングを高速化することができます。 研究者たちは、この研究を支援するためにさまざまなタイプの画像を収集しました。収集した画像は、庭園、地元の食料品店、研究室の設定で撮影されました。クラスごとに1000枚の自然画像を撮り、合計で5000枚の自然画像を使用しました。彼らはさらに、多くのオブジェクトがトップビューで表示されたトップビューコンテナ画像のタイプの画像を使用しました。クラスごとに70個のトップビュー画像を使用し、平均して1枚の画像あたり7.1個のオブジェクトが含まれていました。さまざまな画像や背景を組み合わせ、さまざまな変換を適用し、トレーニング画像の数よりも多くのトリミングオブジェクトを生成しました。 研究者たちはまた、画像を増強することで、検出品質の劣化がPseudoAugmentを使用しない場合よりも低くなるようにしました。 研究チームは、以前のプロセスにはいくつかの制限があると述べました。スーパーマーケットには視覚的に似ている果物や野菜が多くあり、新しい種類が頻繁に出現するため、クラシックなコンピュータビジョンシステムは新しい品種が納品されるたびに再トレーニングする必要があります。また、多くのデータを収集して手動でラベル付けする必要があるため、時間がかかります。 このアプローチの正確性とパフォーマンスをチェックするために、研究者は5つの異なる種類の果物を分類し、自然なトレーニング写真の数が50未満の場合、デフォルトのパイプラインの出力は基本的に推測に過ぎなかったことがわかりました。彼らはこのアプローチの利点は、元のトレーニング画像が250以下の場合に見られると強調しました。研究者たちはさらに、このアプローチの正確性を果物の分類問題でテストし、自然なトレーニング画像がない場合でも98.3%の正確性に達することができることを観察しました。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.