Learn more about Search Results リーダーボード - Page 7

- You may be interested
- 「長期のCOVID検査への研究者の前進」
- 「AIは医療現場でどのような役割を果たす...
- 「データサイエンス(2023年)で学ぶべき...
- 「2023年9月のベストデータ抽出ツール10選」
- MITの研究者が、生成プロセスの改善のため...
- NVIDIAリサーチがCVPRで自律走行チャレン...
- 「SPHINXをご紹介します:トレーニングタ...
- In Japanese, the title would be written...
- 南アメリカにおける降水量と気候学的なラ...
- このAIニュースレターは、あなたが必要と...
- 「リトリーバル増強生成(RAG)とファイン...
- 「ダークウェブを照らす」
- 「統計的検定を用いたデータセットの多重...
- 業界固有のAIのナビゲーション:移行期の...
- 『LangChainを使用してテキストから辞書を...

大規模画像モデルのための最新のCNNカーネル
「OpenAIのChatGPTの驚異的な成功が大型言語モデルのブームを引き起こしたため、多くの人々が大型画像モデルにおける次のブレークスルーを予測していますこの領域では、ビジョンモデルは...」

「AI週間ニュース、2023年7月31日:」
「This Week in AI」はVoAGIで提供される人工知能の最新情報のウィークリーラウンドアップです最新のヘッドライン、学術論文、教育リソース、注目の研究など、幅広いトピックをカバーしており、読者を常に最新の情報で更新し、知識を深めることを目的としています

従業員のエンゲージメント向上にゲーミフィケーションソフトウェアを使用する:メリットとデメリット
従業員のエンゲージメントは、高い生産性と全体的なパフォーマンスを真に重視する組織の中心的な焦点の一つですゲーミフィケーションソフトウェアの使用は、従業員のエンゲージメントの観点でゲームチェンジャーとなることがあります従業員をモチベートし、協力を促す素晴らしい方法ですが、実施する前に考慮すべき潜在的な欠点もあります... 従業員エンゲージメントのためのゲーミフィケーションソフトウェアの利点と欠点 続きを読む »
「Llama 2の機能を実世界のアプリケーションに活用する:FastAPI、Celery、Redis、およびDockerを使用したスケーラブルなチャットボットの構築」
「Llama 2を探索し、オープンソースの影響、プロンプトエンジニアリング、そしてスケーラブルなLLMアーキテクチャを探求してください」

「生成AI、基礎モデル、および大規模言語モデルの世界を探求する:概念、ツール、およびトレンド」
最近、人工知能(AI)は大きな進歩を遂げており、主にディープラーニングの進展によって推進されています昨年のChatGPTの登場により、生成型AIの世界の人気が高まりました...

「Llama 2が登場しました – Hugging Faceで手に入れましょう」
はじめに Llama 2は、Metaが本日リリースした最新のオープンアクセスの大規模言語モデルのファミリーです。私たちはHugging Faceとの包括的な統合を完全にサポートすることで、このリリースを支援しています。Llama 2は非常に寛容なコミュニティライセンスでリリースされ、商業利用も可能です。コード、事前学習モデル、ファインチューニングモデルはすべて本日リリースされます🔥 私たちはMetaとの協力により、Hugging Faceエコシステムへのスムーズな統合を実現しています。Hubで12のオープンアクセスモデル(3つのベースモデルと3つのファインチューニングモデル、オリジナルのMetaチェックポイントを含む)を見つけることができます。リリースされる機能と統合の中には、以下のものがあります: モデルカードとライセンスを備えたHub上のモデル。 Transformersの統合 単一のGPUを使用してモデルの小さなバリアントをファインチューニングするための例 高速かつ効率的なプロダクションレディの推論のためのテキスト生成インファレンスとの統合 インファレンスエンドポイントとの統合 目次 Llama 2を選ぶ理由 デモ インファレンス Transformersを使用する場合 インファレンスエンドポイントを使用する場合 PEFTによるファインチューニング 追加リソース 結論 Llama 2を選ぶ理由…
「ファインチューニング中に埋め込みのアニメーションを作成する方法」
「機械学習の分野では、ビジョントランスフォーマー(ViT)は画像分類に使用されるモデルの一種です従来の畳み込みニューラルネットワークとは異なり、ViTはトランスフォーマーアーキテクチャを使用します…」

「FalconAI、LangChain、およびChainlitを使用してチャットボットを作成する」
イントロダクション ジェネレーティブAI、特にジェネレーティブ大規模言語モデルは、その誕生以来世界を席巻しています。これは、動作可能なプログラムコードを生成することから完全なジェネレーティブAI管理のチャットサポートシステムを作成するまで、さまざまなアプリケーションと統合できたために可能になりました。しかし、ジェネレーティブAIの領域における大規模言語モデルのほとんどは、一般には非公開で、オープンソース化されていませんでした。オープンソースモデルは存在しますが、非公開の大規模言語モデルとは比べものになりません。しかし最近、FalconAIというLLMがリリースされ、OpenLLMのリーダーボードでトップに立ち、オープンソース化されました。このガイドでは、Falcon AI、LangChain、Chainlitを使用してチャットアプリケーションを作成します。 学習目標 ジェネレーティブAIアプリケーションでFalconモデルを活用する Chainlitを使用して大規模言語モデルのUIを構築する ハギングフェイスの事前学習モデルにアクセスするための推論APIで作業する LangChainを使用して大規模言語モデルとプロンプトテンプレートを連鎖させる LangChain ChainsをChainlitと統合してUIアプリケーションを作成する この記事はData Science Blogathonの一部として公開されました。 Falcon AIとは何ですか? ジェネレーティブAIの分野では、Falcon AIは最近導入された大規模言語モデルの一つで、OpenLLMのリーダーボードで第1位を獲得しています。Falcon AIはUAEのテクノロジーイノベーション研究所(TII)によって導入されました。Falcon AIのアーキテクチャは推論に最適化された形で設計されています。最初に導入された時、Falcon AIはLlama、Anthropic、DeepMindなどの最先端のモデルを抜いてOpenLLMのリーダーボードのトップに立ちました。このモデルはAWS Cloud上でトレーニングされ、2ヶ月間連続で384のGPUが接続されました。 現在、Falcon AIにはFalcon 40B(400億パラメータ)とFalcon…

「Hugging Faceにおけるオープンソースのテキスト生成とLLMエコシステム」
テキスト生成と対話技術は古くから存在しています。これらの技術に取り組む上での以前の課題は、推論パラメータと識別的なバイアスを通じてテキストの一貫性と多様性を制御することでした。より一貫性のある出力は創造性が低く、元のトレーニングデータに近く、人間らしさに欠けるものでした。最近の開発により、これらの課題が克服され、使いやすいUIにより、誰もがこれらのモデルを試すことができるようになりました。ChatGPTのようなサービスは、最近GPT-4のような強力なモデルや、LLaMAのようなオープンソースの代替品が一般化するきっかけとなりました。私たちはこれらの技術が長い間存在し、ますます日常の製品に統合されていくと考えています。 この投稿は以下のセクションに分かれています: テキスト生成の概要 ライセンス Hugging FaceエコシステムのLLMサービス用ツール パラメータ効率の良いファインチューニング(PEFT) テキスト生成の概要 テキスト生成モデルは、不完全なテキストを完成させるための目的で訓練されるか、与えられた指示や質問に応じてテキストを生成するために訓練されます。不完全なテキストを完成させるモデルは因果関係言語モデルと呼ばれ、有名な例としてOpenAIのGPT-3やMeta AIのLLaMAがあります。 次に進む前に知っておく必要がある概念はファインチューニングです。これは非常に大きなモデルを取り、このベースモデルに含まれる知識を別のユースケース(下流タスクと呼ばれます)に転送するプロセスです。これらのタスクは指示の形で提供されることがあります。モデルのサイズが大きくなると、事前トレーニングデータに存在しない指示にも一般化できるようになりますが、ファインチューニング中に学習されたものです。 因果関係言語モデルは、人間のフィードバックに基づいた強化学習(RLHF)と呼ばれるプロセスを使って適応されます。この最適化は、テキストの自然さと一貫性に関して行われますが、回答の妥当性に関しては行われません。RLHFの仕組みの詳細については、このブログ投稿の範囲外ですが、こちらでより詳しい情報を見つけることができます。 例えば、GPT-3は因果関係言語のベースモデルですが、ChatGPTのバックエンドのモデル(GPTシリーズのモデルのUI)は、会話や指示から成るプロンプトでRLHFを用いてファインチューニングされます。これらのモデル間には重要な違いがあります。 Hugging Face Hubでは、因果関係言語モデルと指示にファインチューニングされた因果関係言語モデルの両方を見つけることができます(このブログ投稿で後でリンクを提供します)。LLaMAは最初のオープンソースLLMの1つであり、クローズドソースのモデルと同等以上の性能を発揮しました。Togetherに率いられた研究グループがLLaMAのデータセットの再現であるRed Pajamaを作成し、LLMおよび指示にファインチューニングされたモデルを訓練しました。詳細についてはこちらをご覧ください。また、Hugging Face Hubでモデルのチェックポイントを見つけることができます。このブログ投稿が書かれた時点では、オープンソースのライセンスを持つ最大の因果関係言語モデルは、MosaicMLのMPT-30B、SalesforceのXGen、TII UAEのFalconの3つです。 テキスト生成モデルの2番目のタイプは、一般的にテキスト対テキスト生成モデルと呼ばれます。これらのモデルは、質問と回答または指示と応答などのテキストのペアで訓練されます。最も人気のあるものはT5とBARTです(ただし、現時点では最先端ではありません)。Googleは最近、FLAN-T5シリーズのモデルをリリースしました。FLANは指示にファインチューニングするために開発された最新の技術であり、FLAN-T5はFLANを使用してファインチューニングされたT5です。現時点では、FLAN-T5シリーズのモデルが最先端であり、オープンソースでHugging Face Hubで利用可能です。入力と出力の形式は似ているかもしれませんが、これらは指示にファインチューニングされた因果関係言語モデルとは異なります。以下は、これらのモデルがどのように機能するかのイラストです。 より多様なオープンソースのテキスト生成モデルを持つことで、企業はデータをプライベートに保ち、ドメインに応じてモデルを適応させ、有料のクローズドAPIに頼る代わりに推論のコストを削減することができます。Hugging…
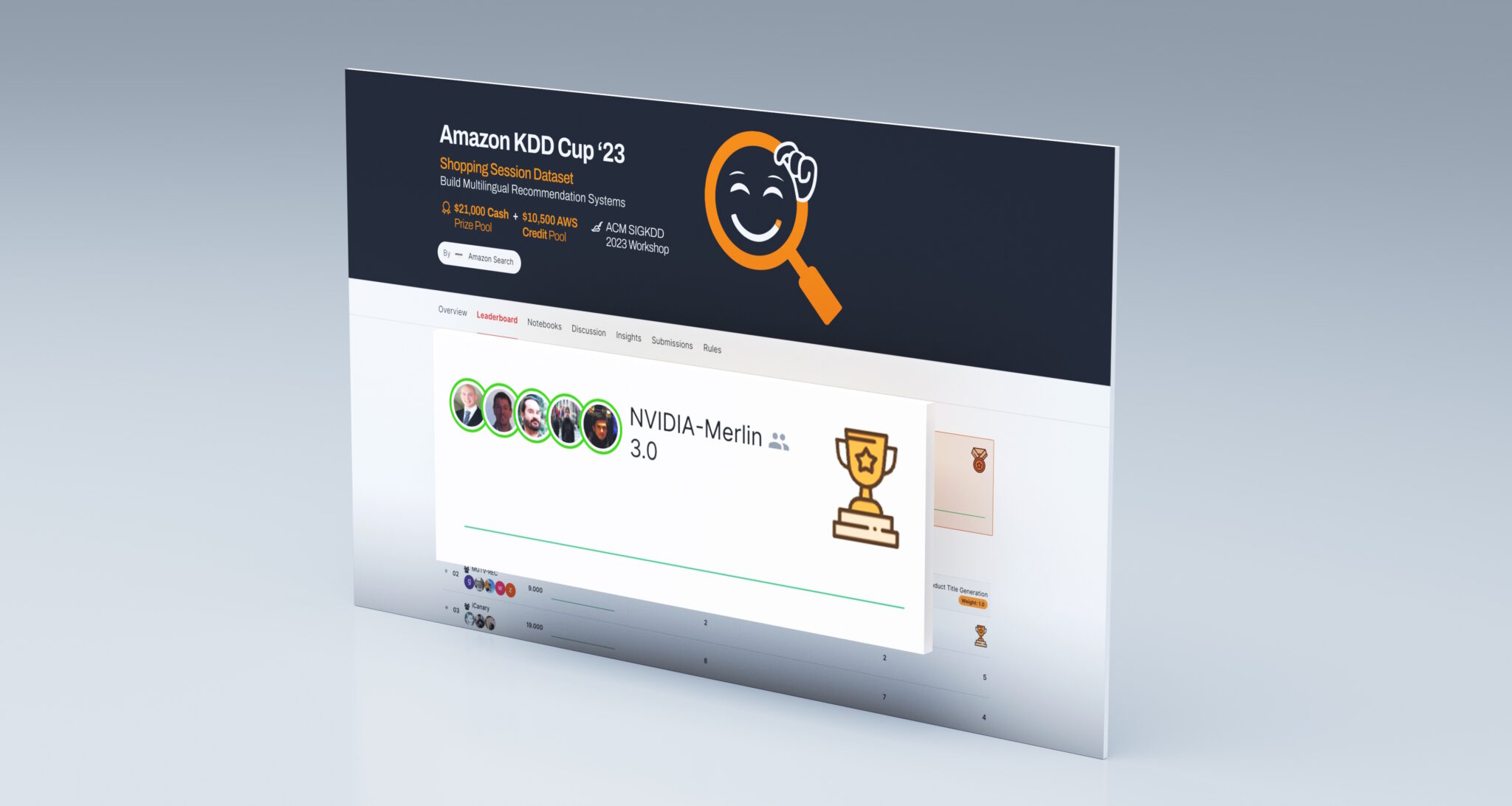
スコア! チームNVIDIAが推薦システムでトロフィーを獲得しました
5人の機械学習の専門家が4つの大陸に分散し、最先端のレコメンデーションシステムを構築するための激しい競争で3つのタスク全てに勝利しました。 この結果は、グループがNVIDIA AIプラットフォームをデジタル経済のエンジンであるこれらのエンジンに適用する際の知識と技術の賜物です。レコメンデーションシステムは、毎日数十兆の検索結果、広告、製品、音楽、ニュースストーリーを数十億人に提供しています。 Amazon KDD Cup ’23には、450以上のデータサイエンティストチームが参加しました。この3ヶ月間のチャレンジには、予測不可能な展開と、緊迫したフィニッシュがありました。 高速ギアへの切り替え コンペティションの最初の10週間、チームは快適なリードを築きました。しかし、最終フェーズでは、主催者が新しいテストデータセットに切り替え、他のチームが急進しました。 NVIDIANsは夜間や週末にも働き、追いつくために最高のパフォーマンスを発揮しました。彼らは、ベルリンから東京まで様々な都市に住むチームメンバーからの24時間体制のSlackメッセージを残しました。 「私たちはぶっ通しで働いていました。非常に興奮していました」とサンディエゴのチームメンバーであるクリス・デオットは語りました。 別の名前の製品 最後の3つのタスクは最も難しかったです。 参加者は、ユーザーのブラウジングセッションのデータに基づいて、ユーザーがどの製品を購入するかを予測する必要がありました。しかし、トレーニングデータには多くの選択肢のブランド名が含まれていませんでした。 「最初から、これは非常に、非常に難しいテストだとわかっていました」とギルベルト「ギバ」ティテリッツは述べました。 KGMONの救世主 ブラジルのクリチバを拠点とするティテリッツは、Kaggleのコンペティションでグランドマスターにランクされた4人のメンバーの一人であり、データサイエンスのオンラインオリンピックであるKaggleのグランドマスターを勝ち抜いた数多くの機械学習のニンジャのチームの一員です。NVIDIAの創設者兼CEOであるジェンセン・ファンは彼らをKGMON(Kaggle Grandmasters of NVIDIA)と呼び、ポケモンにちなんだ遊び心のある名前です。 ティテリッツは、数十の実験で、大規模な言語モデル(LLM)を使用して生成型AIを構築し、製品名を予測しましたが、どれもうまくいきませんでした。 チームは創造的な閃きで回避策を見つけました。新しいハイブリッドランキング/分類モデルを使用した予測が的中しました。 ギリギリの戦い 競争の最後の数時間、チームは最後の提出用にすべてのモデルをまとめるために急いでいました。彼らは最大40台のコンピュータで夜間の実験を実施していました。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.