Learn more about Search Results スペイン語 - Page 7

- You may be interested
- 高速なトレーニングと推論 Habana Gaudi®2...
- 「生成AIプロジェクトライフサイクル」
- 「Devartの26周年を祝い、データ接続ツー...
- 「生成AIにおける高度なエンコーダとデコ...
- 偽りの預言者:自家製の時系列回帰モデル
- データウェアハウスとデータレイクとデー...
- 「GoogleのRealLife AIモデルは魔法のよう...
- AIとMLによる株式取引の革命:機会と課題
- AIを活用してホームレスを防ぐ:ロサンゼ...
- 次元の呪いの真の範囲を可視化する
- イネイテンスとは何か?人工知能にとって...
- コグVLM、革命的なマルチモーダルモデルで...
- 『完全な初心者のための量子コンピューテ...
- 「バーチャートを超えて:サンキーダイア...
- 『Amazon SageMaker Clarifyを使用して、...

気候変動との戦いをリードする6人の女性
「私たちは気候科学の先駆者であるユニス・ニュートン・フートと、より持続可能な未来を築く6人の女性主導のGoogle.orgの助成金受給者を祝っています」
チャットGPTからPiへ、そしてなぜそうするのかをお伝えします!
2月にUX/UIデザインの旅が始まって以来、ChatGPT 🤖 を使い始めて以来、私はChatGPTを私のBFFと呼んでいます感情的になるわけではありませんが、それは私の研究のマインドセットの大きな一部でした...
「CHATGPTの内部機能について:AIに関する自分自身の疑問に対するすべての回答」
私たちは皆、ChatGPTが質問に答えたり、命令を実行したりするユーザーフレンドリーなAIチャットボットであることを知っています人間らしい出力を提供してくれますしかし、実際にChatGPTがどのように機能しているかを知っている人はどれくらいいますか?
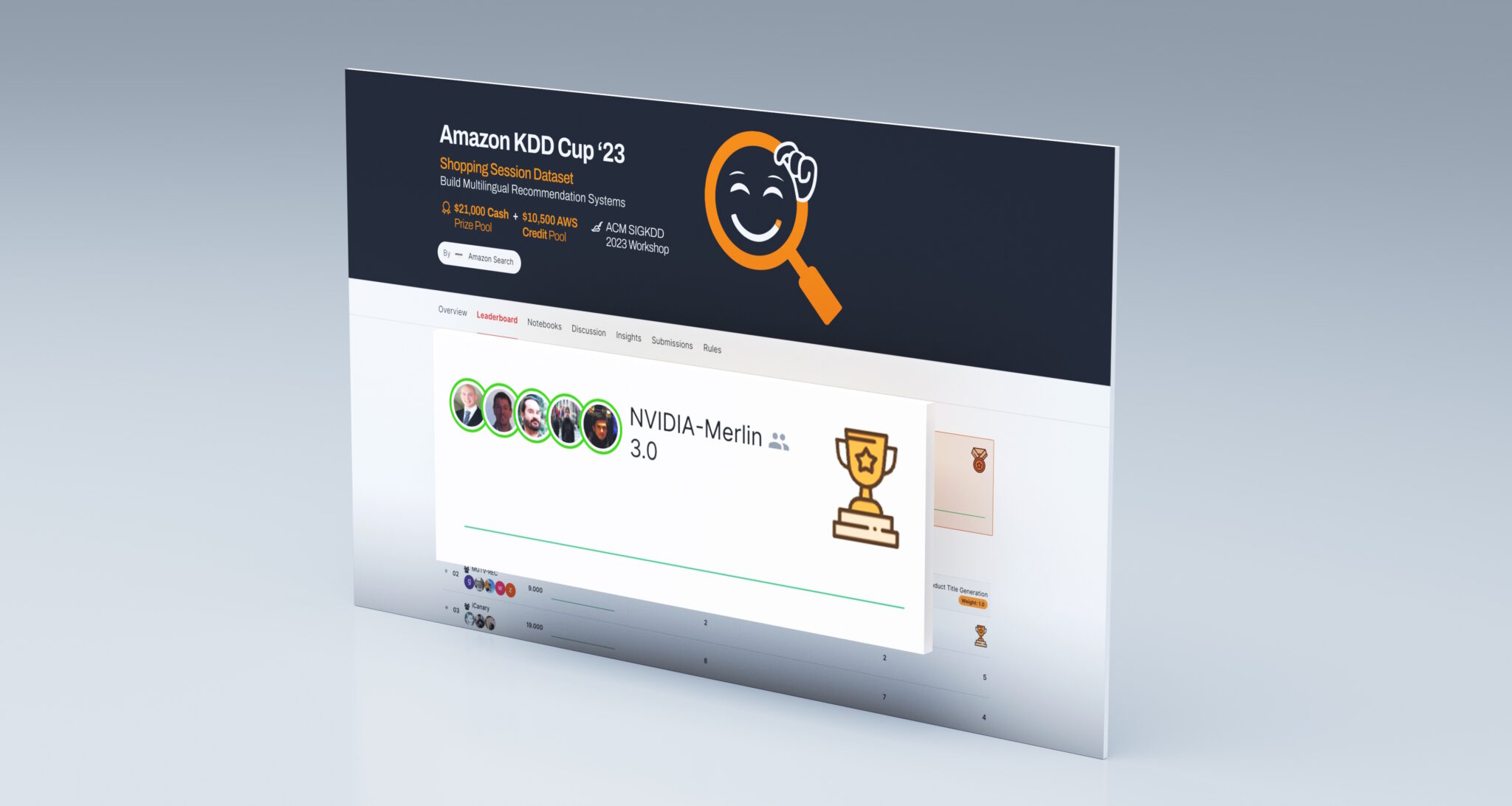
スコア! チームNVIDIAが推薦システムでトロフィーを獲得しました
5人の機械学習の専門家が4つの大陸に分散し、最先端のレコメンデーションシステムを構築するための激しい競争で3つのタスク全てに勝利しました。 この結果は、グループがNVIDIA AIプラットフォームをデジタル経済のエンジンであるこれらのエンジンに適用する際の知識と技術の賜物です。レコメンデーションシステムは、毎日数十兆の検索結果、広告、製品、音楽、ニュースストーリーを数十億人に提供しています。 Amazon KDD Cup ’23には、450以上のデータサイエンティストチームが参加しました。この3ヶ月間のチャレンジには、予測不可能な展開と、緊迫したフィニッシュがありました。 高速ギアへの切り替え コンペティションの最初の10週間、チームは快適なリードを築きました。しかし、最終フェーズでは、主催者が新しいテストデータセットに切り替え、他のチームが急進しました。 NVIDIANsは夜間や週末にも働き、追いつくために最高のパフォーマンスを発揮しました。彼らは、ベルリンから東京まで様々な都市に住むチームメンバーからの24時間体制のSlackメッセージを残しました。 「私たちはぶっ通しで働いていました。非常に興奮していました」とサンディエゴのチームメンバーであるクリス・デオットは語りました。 別の名前の製品 最後の3つのタスクは最も難しかったです。 参加者は、ユーザーのブラウジングセッションのデータに基づいて、ユーザーがどの製品を購入するかを予測する必要がありました。しかし、トレーニングデータには多くの選択肢のブランド名が含まれていませんでした。 「最初から、これは非常に、非常に難しいテストだとわかっていました」とギルベルト「ギバ」ティテリッツは述べました。 KGMONの救世主 ブラジルのクリチバを拠点とするティテリッツは、Kaggleのコンペティションでグランドマスターにランクされた4人のメンバーの一人であり、データサイエンスのオンラインオリンピックであるKaggleのグランドマスターを勝ち抜いた数多くの機械学習のニンジャのチームの一員です。NVIDIAの創設者兼CEOであるジェンセン・ファンは彼らをKGMON(Kaggle Grandmasters of NVIDIA)と呼び、ポケモンにちなんだ遊び心のある名前です。 ティテリッツは、数十の実験で、大規模な言語モデル(LLM)を使用して生成型AIを構築し、製品名を予測しましたが、どれもうまくいきませんでした。 チームは創造的な閃きで回避策を見つけました。新しいハイブリッドランキング/分類モデルを使用した予測が的中しました。 ギリギリの戦い 競争の最後の数時間、チームは最後の提出用にすべてのモデルをまとめるために急いでいました。彼らは最大40台のコンピュータで夜間の実験を実施していました。…
「スコア!チームNVIDIAが推薦システムでトロフィーを獲得」
4つの大陸に広がる5人の機械学習のエキスパートで構成されるクラックチームが、最先端の推薦システムを構築するための激しい競争で、全ての3つのタスクに勝利しました。 その結果は、このデジタル経済のエンジンにおいて、NVIDIAのAIプラットフォームを実世界の課題に効果的に適用するグループの知識を反映しています。推薦システムは、毎日数十億人に対して兆個の検索結果、広告、製品、音楽、ニュースストーリーを提供しています。 Amazon KDD Cup ’23では、450以上のデータサイエンティストチームが競い合いました。この3ヶ月間のチャレンジには多くの曲折と緊迫したフィニッシュがありました。 高速ギアへの切り替え 競争の最初の10週間では、チームはリードを築きました。しかし、最終フェーズでは、主催者が新しいテストデータセットに切り替え、他のチームが追い上げました。 NVIDIANsは夜間や週末にも働き、追いつくために最高のギアに切り替えました。彼らはベルリンから東京までの都市に住むチームメンバーからの24時間対応のSlackメッセージの軌跡を残しました。 サンディエゴのチームメンバーであるクリス・デオットは、「私たちは絶えず働いていました。とてもエキサイティングでした」と語りました。 別の名前の製品 3つ目のタスクは最も難しかったです。 参加者は、ユーザーのブラウジングセッションのデータに基づいて、ユーザーがどの製品を購入するかを予測しなければなりませんでした。しかし、トレーニングデータには多くの選択肢のブランド名が含まれていませんでした。 「最初から、これは非常に非常に困難なテストになると分かっていました」と、ギルベルト・”ギバ”・ティテリックスは述べました。 KGMONの救出 ブラジルのクリチバを拠点とするティテリックスは、Kaggleコンペティションのグランドマスターにランクされる4人のチームメンバーの一人で、データサイエンスのオンラインオリンピックであるKaggleのチャンピオンです。彼らは何十ものコンペティションに勝利した機械学習のニンジャのチームの一部です。NVIDIAの創設者兼CEOであるジェンセン・ファンは、彼らをKGMON(Kaggle Grandmasters of NVIDIA)と呼んでいます。 ティテリックスは、大量の言語モデル(LLM)を使用して生成型AIを構築し、製品名を予測しようとしましたが、どれもうまくいきませんでした。 チームはクリエイティブな方法を見つけました。新しいハイブリッドランキング/分類モデルを使用した予測結果は的確でした。 ギリギリの戦い 競争の最後の数時間、チームは最後の提出のためにすべてのモデルをまとめるために競走しました。彼らは最大40台のコンピュータで一晩中の実験を実施していました。 東京のKGMONである小野寺一樹は、緊張していました。「実際のスコアが私たちの推定値と一致するかどうか本当に分かりませんでした」と彼は語りました。…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…
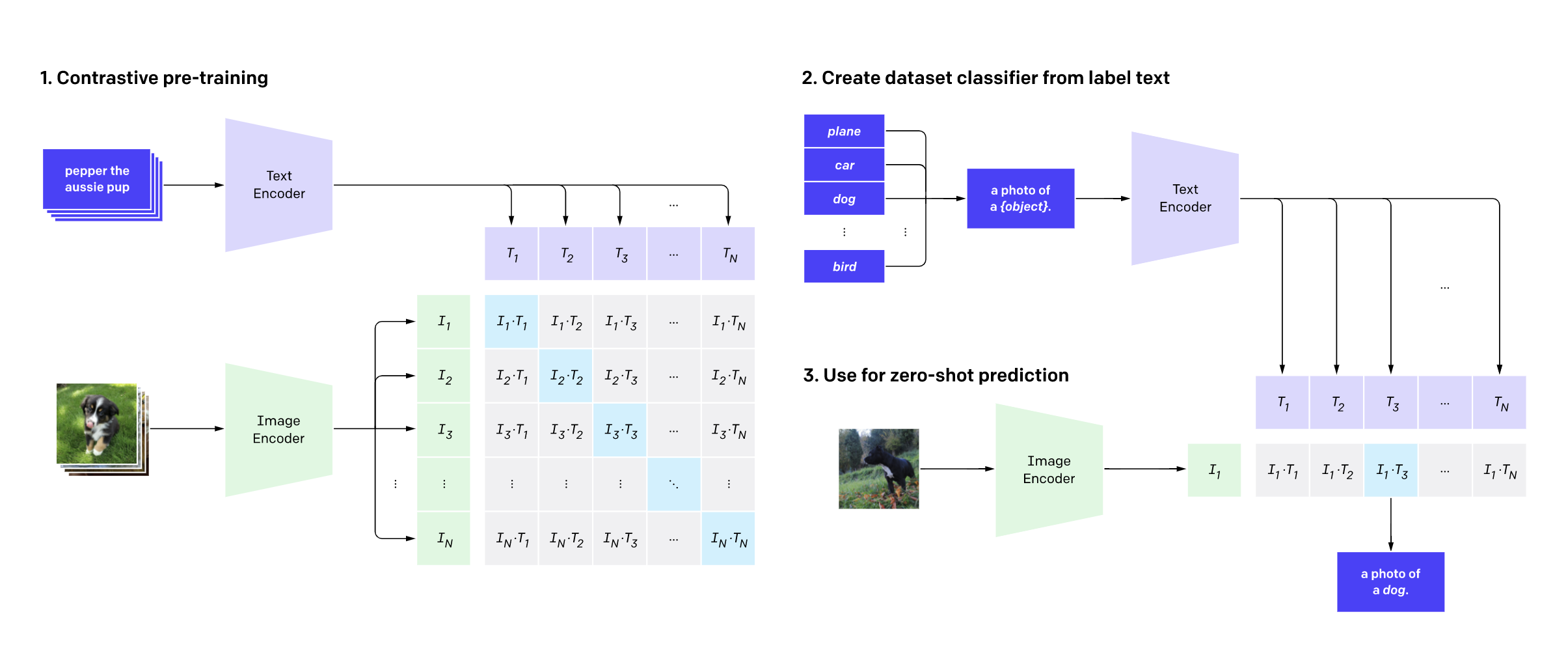
リモートセンシング(衛星)画像とキャプションを使用してCLIPの微調整
リモートセンシング(衛星)画像とキャプションを使用したCLIPの微調整 今年の7月、Hugging FaceはFlax/JAXコミュニティウィークを開催し、自然言語処理(NLP)とコンピュータビジョン(CV)の分野でHugging Faceトランスフォーマーモデルを訓練するプロジェクトの提出をコミュニティに呼びかけました。 参加者はFlaxとJAXを使用したTensor Processing Units(TPUs)を使用しました。JAXは線形代数ライブラリ(numpyのような)で、自動微分(Autograd)を行い、XLAにコンパイルできます。また、FlaxはJAX用のニューラルネットワークライブラリであり、エコシステムです。TPUの計算時間は、共同スポンサーであるGoogle Cloudが無料で提供しました。 その後の2週間で、チームはHugging FaceとGoogleの講義に参加し、JAX/Flaxを使用して1つ以上のモデルを訓練し、それらをコミュニティと共有し、モデルの機能を示すHugging Face Spacesデモを提供しました。約100チームが参加し、170のモデルと36のデモが生まれました。 私たちのチームは、おそらく他の多くのチームと同様に、12のタイムゾーンにまたがる分散型のチームです。私たちの共通点は、TWIML Slackチャンネルに所属していることであり、そこでは人工知能(AI)と機械学習(ML)のトピックに関心を持つメンバーが集まっています。 私たちは、OpenAIのCLIPネットワークをRSICDデータセットの衛星画像とキャプションで微調整しました。CLIPネットワークは、インターネット上で見つかる画像とキャプションのペアを使用して、自己教師ありの方法で視覚的な概念を学習します。推論中、モデルはテキストの説明に基づいて最も関連性の高い画像を予測するか、画像に基づいて最も関連性の高いテキストの説明を予測することができます。CLIPは、普段の画像に対してゼロショットで使用するには十分なパワフルです。しかし、衛星画像は普段の画像とは異なるため、CLIPを微調整することが有益であると考えました。私たちの直感は正しかったようで、評価結果(後述)が示すようになりました。この記事では、私たちのトレーニングと評価プロセスの詳細、およびこのプロジェクトへの今後の取り組みについて説明します。 私たちのプロジェクトの目標は、有用なサービスを提供し、CLIPを実用的なユースケースに使用する方法を示すことでした。私たちのモデルは、テキストクエリを使用して大規模な衛星画像のコレクションを検索するためにアプリケーションによって使用することができます。そのようなクエリは、画像全体を記述することができます(例:ビーチ、山、空港、野球場など)、またはこれらの画像内の特定の地理的または人工的な特徴を検索または言及することができます。CLIPは、他のドメインでも同様に微調整することができます。これは、医療画像のメディカルチームによって示されています。 テキストクエリを使用して大規模な画像コレクションを検索する能力は、非常に強力な機能であり、社会的な善だけでなく、悪意のある目的にも使用することができます。国家防衛や反テロ活動、気候変動の影響を管理可能な状態になる前に発見し対処する能力など、様々な応用が考えられます。ただし、この力は、権威主義的な国家による軍事や警察の監視などの目的で誤用される可能性もあるため、倫理的な問題も提起されます。 プロジェクトについては、プロジェクトページで詳細を読むことができます。また、独自のデータで推論に使用するために、トレーニング済みモデルをダウンロードすることもできます。デモでも実際の動作を確認することができます。 トレーニング データセット 私たちは、主にRSICDデータセットを使用してCLIPモデルを微調整しました。このデータセットは、Google Earth、Baidu Map、MapABC、Tiandituから収集された約10,000枚の画像から構成されています。このデータセットは、Exploring Models…

AutoNLPとProdigyを使用したアクティブラーニング
機械学習の文脈におけるアクティブラーニングは、ラベル付きデータを反復的に追加し、モデルを再トレーニングしてエンドユーザーに提供するプロセスです。これは終わりのないプロセスであり、データのラベリング/作成には人間の介入が必要です。この記事では、AutoNLPとProdigyを使用してアクティブラーニングパイプラインを構築する方法について説明します。 AutoNLP AutoNLPは、Hugging Faceが作成したフレームワークであり、ほとんどコーディングを行わずに独自のデータセット上で最先端のディープラーニングモデルを構築するのに役立ちます。AutoNLPは、Hugging Faceのtransformers、datasets、inference-apiなどのツールに基づいて構築されています。 AutoNLPを使用すると、独自のカスタムデータセットでSOTAトランスフォーマーモデルをトレーニングし、それらを微調整(自動的に)してエンドユーザーに提供することができます。AutoNLPでトレーニングされたすべてのモデルは最先端でプロダクションに対応しています。 この記事の執筆時点では、AutoNLPはバイナリ分類、回帰、マルチクラス分類、トークン分類(固有表現認識や品詞など)、質問応答、要約などのタスクをサポートしています。すべてのサポートされているタスクのリストはこちらで確認できます。AutoNLPは、英語、フランス語、ドイツ語、スペイン語、ヒンディー語、オランダ語、スウェーデン語などの言語をサポートしています。AutoNLPでは、カスタムトークナイザーを使用したカスタムモデルもサポートされています(AutoNLPでサポートされていない場合)。 Prodigy Prodigyは、spaCyの開発元であるExplosionによって開発された注釈ツールです。これはリアルタイムでデータを注釈付けするためのWebベースのツールです。Prodigyは、固有表現認識(NER)やテキスト分類などのNLPタスクをサポートしていますが、NLPに限定されません!コンピュータビジョンのタスクや独自のタスクの作成もサポートしています!Prodigyのデモはこちらでお試しいただけます。 Prodigyは商用ツールですので、詳細についてはこちらでご確認ください。 私たちは、データのラベリングに最も人気のあるツールの1つであり、無限にカスタマイズ可能なProdigyを選びました。また、セットアップや使用も非常に簡単です。 データセット さあ、この記事の最も興味深い部分が始まります。さまざまなデータセットや問題の種類を調査した後、私たちはKaggleのBBCニュース分類データセットに出くわしました。このデータセットは、クラス内競技で使用され、こちらでアクセスできます。 このデータセットを見てみましょう: このデータセットは分類データセットです。ニュース記事のテキストであるText列と、記事のクラスであるCategory列があります。全体として、5つの異なるクラスがあります:business、entertainment、politics、sport、tech。 AutoNLPを使用してこのデータセットでマルチクラス分類モデルをトレーニングするのは簡単です。 ステップ1:データセットをダウンロードします。 ステップ2:AutoNLPを開き、新しいプロジェクトを作成します。 ステップ3:トレーニングデータセットをアップロードし、自動分割を選択します。 ステップ4:価格を承認し、モデルをトレーニングします。 上記の例では、15種類の異なるマルチクラス分類モデルをトレーニングしています。AutoNLPの価格は1つあたり10ドル以下になることもあります。AutoNLPは最適なモデルを選択し、ハイパーパラメータの調整を自動で行います。したがって、今すぐ座って結果を待つだけです。 約15分後、すべてのモデルのトレーニングが完了し、結果が利用可能になりました。最も優れたモデルの精度は98.67%のようです! したがって、このデータセットの記事を98.67%の精度で分類することができます!しかし、アクティブラーニングとProdigyについて話していましたが、それらはどうなったのでしょうか?🤔 すでにProdigyを使用したことを確認します。私たちは、このデータセットを固有表現認識のタスクのためにラベル付けするためにProdigyを使用しました。ラベリングの部分を始める前に、ニュース記事のエンティティを検出するだけでなく、それらを分類するプロジェクトを持つことがクールだと思いました。そのため、既存のラベルでこの分類モデルを構築しました。…

Pythonを使用した感情分析の始め方
感情分析は、データを感情に基づいてタグ付けする自動化されたプロセスです。感情分析により、企業はデータをスケールで分析し、洞察を検出し、プロセスを自動化することができます。 過去には、感情分析は研究者、機械学習エンジニア、または自然言語処理の経験を持つデータサイエンティストに限定されていました。しかし、AIコミュニティは最近、機械学習へのアクセスを民主化するための素晴らしいツールを開発しました。今では、わずか数行のコードを使って感情分析を行い、機械学習の経験が全くなくても利用することができます!🤯 このガイドでは、Pythonを使用した感情分析の始め方についてすべてを学びます。具体的には以下の内容です: 感情分析とは何か? Pythonで事前学習済みの感情分析モデルを使用する方法 独自の感情分析モデルを構築する方法 感情分析でツイートを分析する方法 さあ、始めましょう!🚀 1. 感情分析とは何ですか? 感情分析は、与えられたテキストの極性を特定する自然言語処理の技術です。感情分析にはさまざまなバリエーションがありますが、最も広く使用されている技術の1つは、データを「ポジティブ」、「ネガティブ」、または「ニュートラル」のいずれかにラベル付けするものです。たとえば、次のようなツイートを見てみましょう。@VerizonSupportをメンションしているものです: “dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over…

KiliとHuggingFace AutoTrainを使用した意見分類
イントロダクション ユーザーのニーズを理解することは、ユーザーに関連するビジネスにおいて重要です。しかし、それには多くの労力と分析が必要であり、非常に高価です。ならば、Machine Learningを活用しませんか?Auto MLを使用することでコーディングを大幅に削減できます。 この記事では、HuggingFace AutoTrainとKiliを活用して、テキスト分類のためのアクティブラーニングパイプラインを構築します。Kiliは、品質の高いトレーニングデータ作成を通じて、データ中心のアプローチを強力にサポートするプラットフォームです。協力的なデータ注釈ツールとAPIを提供し、信頼性のあるデータセット構築とモデルトレーニングの素早い反復を可能にします。アクティブラーニングとは、データセットにラベル付けされたデータを追加し、モデルを反復的に再トレーニングするプロセスです。そのため、終わりのない作業であり、人間がデータにラベルを付ける必要があります。 この記事の具体的なユースケースとして、Google PlayストアのVoAGIのユーザーレビューを使用してパイプラインを構築します。その後、構築したパイプラインでレビューをカテゴリ分類します。最後に、分類されたレビューに感情分析を適用します。その結果を分析することで、ユーザーのニーズと満足度を理解することが容易になります。 HuggingFaceを使用したAutoTrain 自動化されたMachine Learningは、Machine Learningパイプラインの自動化を指す用語です。データクリーニング、モデル選択、ハイパーパラメータの最適化も含まれます。🤗 transformersを使用して自動的にハイパーパラメータの検索を行うことができます。ハイパーパラメータの最適化は困難で時間のかかるプロセスです。 transformersや他の強力なAPIを使用してパイプラインを自分自身で構築することもできますが、AutoTrainを完全に自動化することも可能です。AutoTrainは、transformers、datasets、inference-apiなどの多くの強力なAPIを基に構築されています。 データのクリーニング、モデルの選択、ハイパーパラメータの最適化のステップは、すべてAutoTrainで完全に自動化されています。このフレームワークをフルに活用することで、特定のタスクに対してプロダクションレディのSOTAトランスフォーマーモデルを構築することができます。現在、AutoTrainはバイナリとマルチラベルのテキスト分類、トークン分類、抽出型質問応答、テキスト要約、テキストスコアリングをサポートしています。また、英語、ドイツ語、フランス語、スペイン語、フィンランド語、スウェーデン語、ヒンディー語、オランダ語など、多くの言語もサポートしています。AutoTrainでサポートされていない言語の場合、カスタムモデルとカスタムトークナイザを使用することも可能です。 Kili Kiliは、データ中心のビジネス向けのエンドツーエンドのAIトレーニングプラットフォームです。Kiliは、最適化されたラベリング機能と品質管理ツールを提供し、データを管理するための便利な手段を提供します。画像、ビデオ、テキスト、PDF、音声データを素早く注釈付けできます。GraphQLとPythonの強力なAPIも備えており、データ管理を容易にします。 オンラインまたはオンプレミスで利用可能であり、コンピュータビジョンやNLP、OCRにおいてモダンなMachine Learning技術を実現することができます。テキスト分類、固有表現認識(NER)、関係抽出などのNLP / OCRタスクをサポートしています。また、オブジェクト検出、画像転写、ビデオ分類、セマンティックセグメンテーションなどのコンピュータビジョンタスクもサポートしています。 Kiliは商用ツールですが、Kiliのツールを試すために無料のデベロッパーアカウントを作成することもできます。料金については、価格ページから詳細を確認できます。 プロジェクト モバイルアプリケーションについての洞察を得るために、レビューの分類と感情分析の例を取り上げます。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.